
干貨 | 萬(wàn)字長(zhǎng)文詳解到底什么是特征工程?

首先,大多數(shù)機(jī)器學(xué)習(xí)從業(yè)者主要在公司做什么呢?不是做數(shù)學(xué)推導(dǎo),也不是發(fā)明多高大上的算法,而是做特征工程,如下圖所示(圖來(lái)自集訓(xùn)營(yíng)的預(yù)習(xí)課之一:機(jī)器學(xué)習(xí) 第九期)

那到底什么是特征工程呢?
下文是july針對(duì)七月在線機(jī)器學(xué)習(xí)第九期第五次課 特征工程的課程筆記。
前言
我所在公司七月在線每個(gè)月都是各種機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、人工智能課程,通過(guò)三年半的打磨,內(nèi)容質(zhì)量已經(jīng)足夠精良,我也在這耳聞目染中不斷被各種從傳統(tǒng)IT成功轉(zhuǎn)行轉(zhuǎn)型轉(zhuǎn)崗AI,然后拿到年薪30~50萬(wàn)的消息刷屏。
數(shù)學(xué)推導(dǎo),也不是發(fā)明多高大上的算法,而是做特征工程,如下圖所示(圖來(lái)自集訓(xùn)營(yíng)的預(yù)
被刷的心癢癢不說(shuō),加上自己喜歡研究,擅長(zhǎng)把艱深晦澀的東西通俗易懂的闡述出來(lái),所以準(zhǔn)備未來(lái)一個(gè)月三十篇ML課程筆記,平均每天一篇,類似之前的KMP SVM CNN 目標(biāo)檢測(cè),發(fā)博客、公號(hào)、題庫(kù)、社區(qū)。且聯(lián)合公司的講師團(tuán)隊(duì)確保專業(yè),爭(zhēng)取每個(gè)專題/模型 都成為每一個(gè)ML初學(xué)者必看的第一篇 。
另外,每一篇筆記基本都將是帶著beats耳機(jī)邊用七月在線APP聽(tīng)課程邊做筆記(恩,APP支持倍速1.5倍或2倍播放),為的是我確保通俗,講授課程的講師確保專業(yè)。還是那句老話,有何問(wèn)題,歡迎在評(píng)論里留言指正,thanks。
1、什么是特征工程
有這么一句話在業(yè)界廣泛流傳:數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個(gè)上限而已。
但特征工程很少在機(jī)器學(xué)習(xí)相關(guān)的書(shū)中闡述,包括很多網(wǎng)絡(luò)課程,七月在線還是第一個(gè)在機(jī)器學(xué)習(xí)課程里講特征工程的課。但直到現(xiàn)在,很多機(jī)器學(xué)習(xí)課程還是不講特征工程,在我眼里,講機(jī)器學(xué)習(xí)但不講特征工程是不專業(yè)的(相信此文一出,會(huì)改進(jìn)他們)。
那特征工程到底是什么,它真的有那么重要么?
顧名思義,特征工程其本質(zhì)是一項(xiàng)工程活動(dòng),目的是最大限度地從原始數(shù)據(jù)中提取特征以供算法和模型使用。
而在公司做機(jī)器學(xué)習(xí),大部分時(shí)間不是研究各種算法、設(shè)計(jì)高大上模型,也不是各種研究深度學(xué)習(xí)的應(yīng)用,或設(shè)計(jì)N層神經(jīng)網(wǎng)絡(luò),實(shí)際上,70~80%的時(shí)間都是在跟數(shù)據(jù)、特征打交道。
因?yàn)榇蟛糠謴?fù)雜模型的算法精進(jìn)都是數(shù)據(jù)科學(xué)家在做。而大多數(shù)同學(xué)在干嘛呢?在跑數(shù)據(jù),或各種map-reduce,hive SQL,數(shù)據(jù)倉(cāng)庫(kù)搬磚,然后做數(shù)據(jù)清洗、分析業(yè)務(wù)和case,以及找特征。包括很多大公司不會(huì)首選用復(fù)雜的模型,有時(shí)就是一招LR打天下。
在某kaggle數(shù)據(jù)科學(xué)二分類比賽,通過(guò)有效特征的抽取,auc能提升2%(auc是評(píng)價(jià)模型好壞的常見(jiàn)指標(biāo)之一),而通過(guò)看起來(lái)高大上的模型調(diào)參優(yōu)化,auc提升只能約5‰。包括在一個(gè)電商商品推薦比賽,推薦大賽第一名的組,基于特征工程,比工程師的推薦準(zhǔn)確 度提升16%。
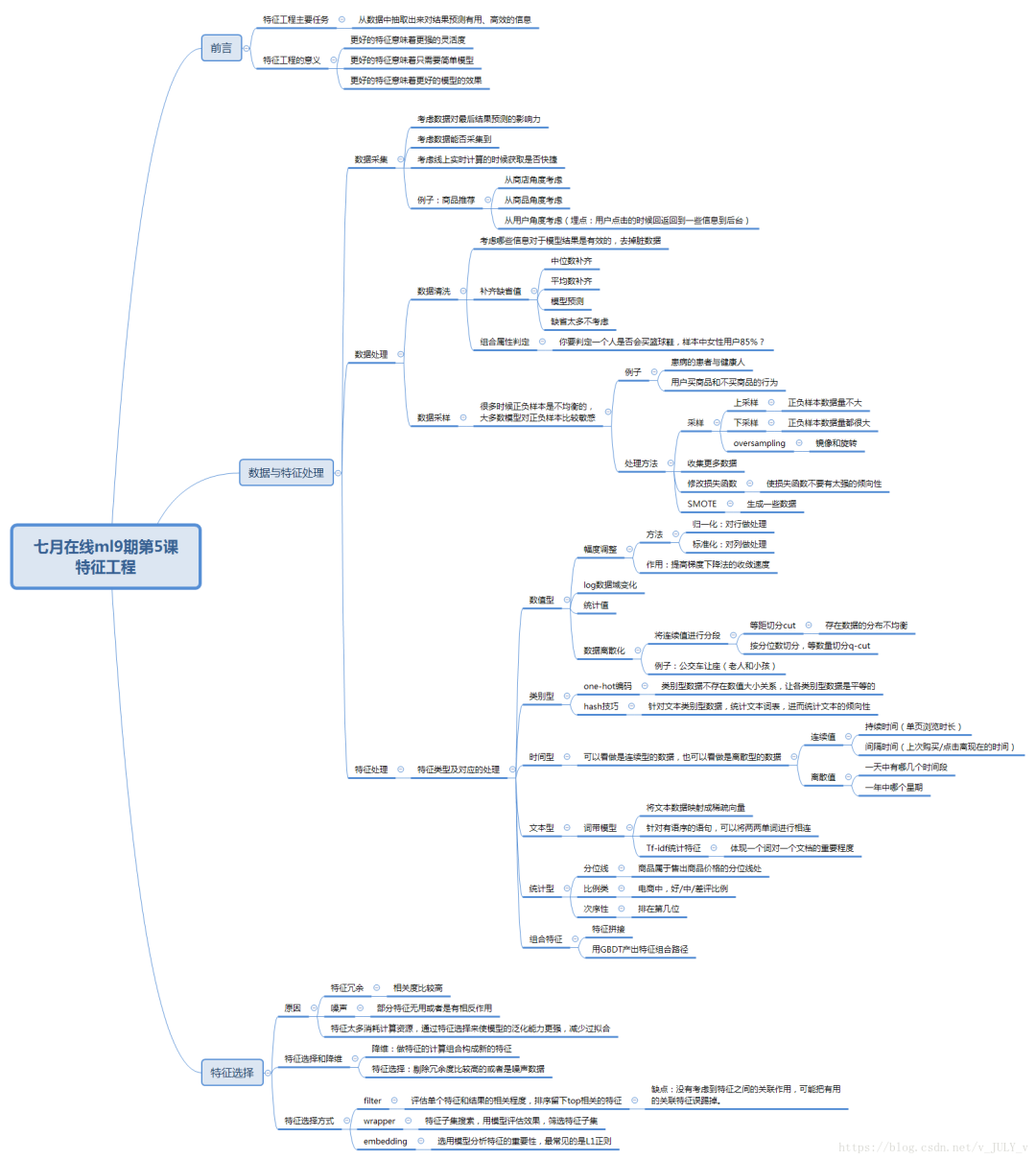
通過(guò)總結(jié)和歸納,一般認(rèn)為特征工程包括以下方面(下圖來(lái)源于ml9學(xué)員海闊天空對(duì)特征工程一課的總結(jié)):
今天給大家一個(gè)超棒的課程福利——【特征工程于模型優(yōu)化特訓(xùn)】課程!8月23日開(kāi)課,限時(shí)1分拼團(tuán)秒殺!
秒殺鏈接:https://www.julyedu.com/course/getDetail/379

課程通過(guò)兩大實(shí)戰(zhàn)項(xiàng)目學(xué)習(xí)多種優(yōu)化方法,掌握比賽上分利器,且包含共享社群答疑 ??免費(fèi)CPU云平臺(tái)等課程配套服務(wù),理論和實(shí)踐完美結(jié)合;從數(shù)據(jù)采集到數(shù)據(jù)處理、到特征選擇、再到模型調(diào)優(yōu),帶你掌握一套完整的機(jī)器學(xué)習(xí)流程。
課程配備優(yōu)秀講師、專業(yè)職業(yè)規(guī)劃老師和助教團(tuán)隊(duì)跟蹤輔導(dǎo)、答疑,班主任督促學(xué)習(xí),群內(nèi)學(xué)員一起學(xué)習(xí),對(duì)抗惰性。


2 數(shù)據(jù)與特征處理
2.1 數(shù)據(jù)采集
2.2 數(shù)據(jù)格式化
2.3 數(shù)據(jù)清洗
當(dāng)然,算法大多數(shù)時(shí)候就是一個(gè)加工機(jī)器,至于最后的產(chǎn)品/成品如何,很大程度上取決于原材料的好壞。而選取或改進(jìn)原材料的過(guò)程會(huì)花掉一大部分時(shí)間,而效率高低取決于你對(duì)于業(yè)務(wù)的理解程度。
2.4 數(shù)據(jù)采樣
那怎么處理正負(fù)樣本不平衡的問(wèn)題呢?為了讓樣本是比較均衡,一般用隨機(jī)采樣,和分層采樣的辦法。
比如如果正樣本多于負(fù)樣本,且量都挺大,則可以采用下采樣。如果正樣本大于負(fù)樣本,但量不大,則可以采集更多的數(shù)據(jù),或者oversampling(比如圖像識(shí)別中的鏡像和旋轉(zhuǎn)),以及修改損失函數(shù)/loss function的辦法來(lái)處理正負(fù)樣本不平衡的問(wèn)題。
2.5 特征處理
在特征處理的過(guò)程中,我們會(huì)面對(duì)各種類型的數(shù)據(jù),比如數(shù)值型(比如年齡的大小)、類別型(比如某個(gè)品牌的口紅可能有十八種色號(hào),比如衣服大小L XL XLL,比如星期幾)、時(shí)間類、文本型、統(tǒng)計(jì)型、組合特征等等。
2.5.1 數(shù)值型數(shù)據(jù)
接下來(lái),重點(diǎn)闡述下其中幾種方法。比如,把數(shù)據(jù)幅度調(diào)整到[0,1]范圍內(nèi),如下代碼所示

這個(gè)操作有一個(gè)專有名詞,即叫歸一化。
為什么要?dú)w一化呢?很多同學(xué)并未搞清楚,維基百科給出的解釋:1)歸一化后加快了梯度下降求最優(yōu)解的速度;2)歸一化有可能提高精度。
下面再簡(jiǎn)單擴(kuò)展解釋下這兩點(diǎn)。
1 歸一化為什么能提高梯度下降法求解最優(yōu)解的速度?
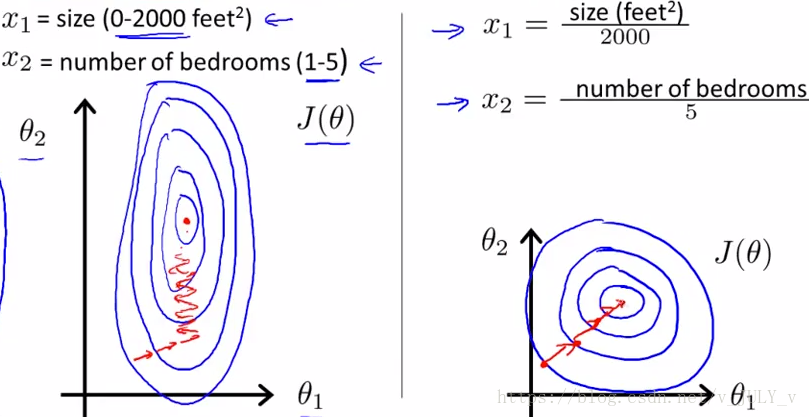
藍(lán)色的圈圈圖代表的是兩個(gè)特征的等高線。其中左圖兩個(gè)特征X1和X2的區(qū)間相差非常大,X1區(qū)間是[0,2000],X2區(qū)間是[1,5],像這種有的數(shù)據(jù)那么大,有的數(shù)據(jù)那么小,兩類之間的幅度相差這么大,其所形成的等高線非常尖。
當(dāng)使用梯度下降法尋求最優(yōu)解時(shí),很有可能走“之字型”路線(垂直等高線走),從而導(dǎo)致需要迭代很多次才能收斂;而右圖對(duì)兩個(gè)原始特征進(jìn)行了歸一化,其對(duì)應(yīng)的等高線顯得很圓,在梯度下降進(jìn)行求解時(shí)能較快的收斂。
因此如果機(jī)器學(xué)習(xí)模型使用梯度下降法求最優(yōu)解時(shí),歸一化往往非常有必要,否則很難收斂甚至不能收斂。
2 歸一化有可能提高精度
3 歸一化的類型
1)線性歸一化
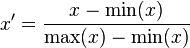
這種歸一化方法比較適用在數(shù)值比較集中的情況。這種方法有個(gè)缺陷,如果max和min不穩(wěn)定,很容易使得歸一化結(jié)果不穩(wěn)定,使得后續(xù)使用效果也不穩(wěn)定。實(shí)際使用中可以用經(jīng)驗(yàn)常量值來(lái)替代max和min。
2)標(biāo)準(zhǔn)差標(biāo)準(zhǔn)化
經(jīng)過(guò)處理的數(shù)據(jù)符合標(biāo)準(zhǔn)正態(tài)分布,即均值為0,標(biāo)準(zhǔn)差為1,其轉(zhuǎn)化函數(shù)為:
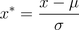
3)非線性歸一化
在實(shí)際應(yīng)用中,通過(guò)梯度下降法求解的模型一般都是需要?dú)w一化的,比如線性回歸、logistic回歸、KNN、SVM、神經(jīng)網(wǎng)絡(luò)等模型。
但樹(shù)形模型不需要?dú)w一化,因?yàn)樗鼈儾魂P(guān)心變量的值,而是關(guān)心變量的分布和變量之間的條件概率,如決策樹(shù)、隨機(jī)森林(Random Forest)。
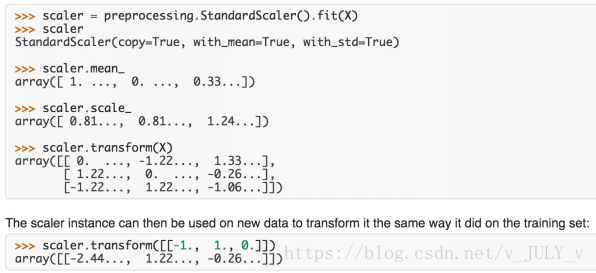
接下來(lái),我們?cè)倏聪聦?duì)數(shù)據(jù)做標(biāo)準(zhǔn)化的操作

再比如,對(duì)數(shù)據(jù)做統(tǒng)計(jì)值

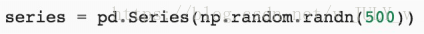
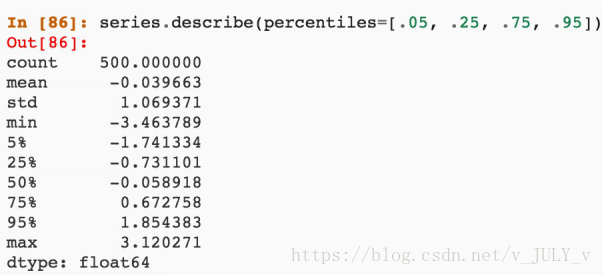
或者,對(duì)數(shù)據(jù)做離散化。比如說(shuō)一個(gè)人的年齡是一個(gè)連續(xù)值,但連續(xù)值放進(jìn)一些模型里比如Logistic Regression則不太好使,這個(gè)時(shí)候便要對(duì)數(shù)據(jù)進(jìn)行離散化,通俗理解就是把連續(xù)的值分成不同的段,每一段列成特征,從而分段處理。

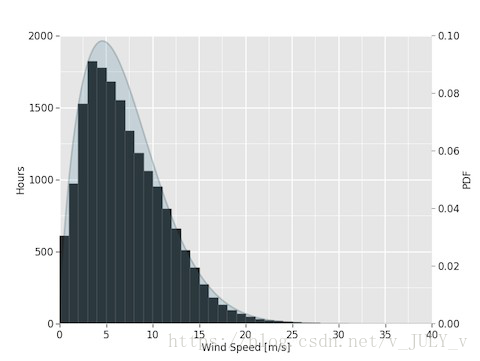
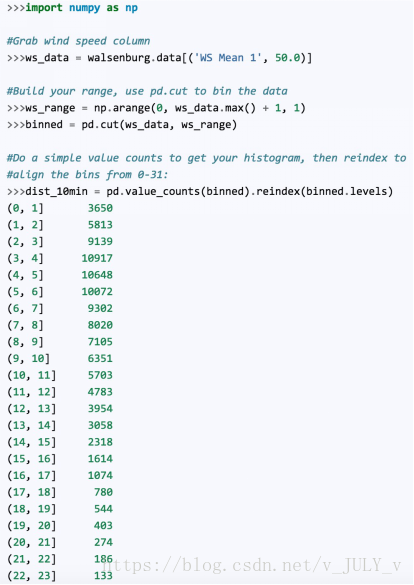
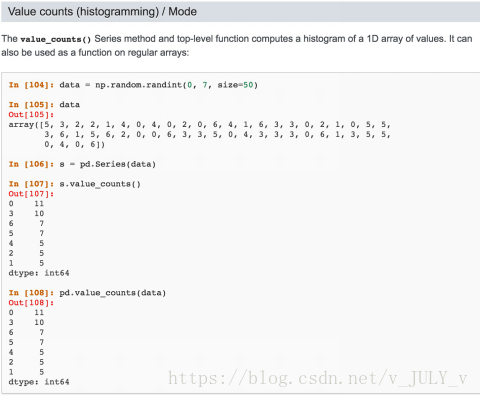
以及對(duì)數(shù)據(jù)做柱狀分布(比例)
2.5.2 類型型數(shù)據(jù)
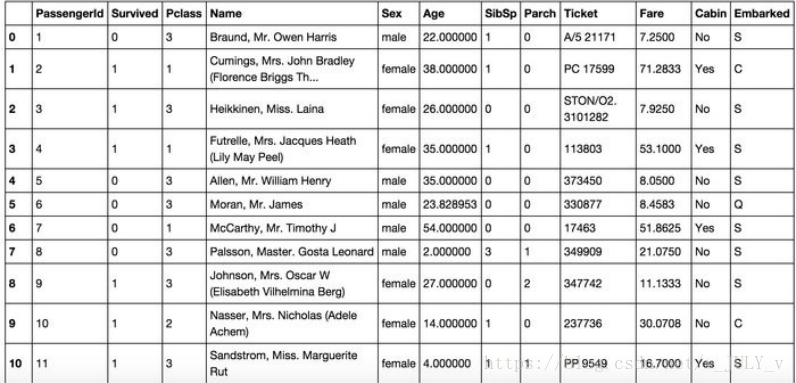
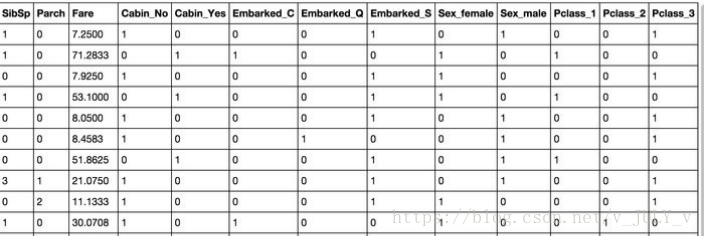
針對(duì)口紅色號(hào)這種類別型數(shù)據(jù)的特征,可以使用One-hot編碼/啞變量。
One-hot編碼一般使用稀疏向量來(lái)節(jié)省空間,比如只有某一維取值為1,其他位置取值均為0。且需要配合特征選擇來(lái)降低維度,畢竟高維度會(huì)帶來(lái)一些問(wèn)題
比如K近鄰算法中,高維空間下兩點(diǎn)之間的距離不好測(cè)量;
又比如某些分類場(chǎng)景下,只有部分維度有用。

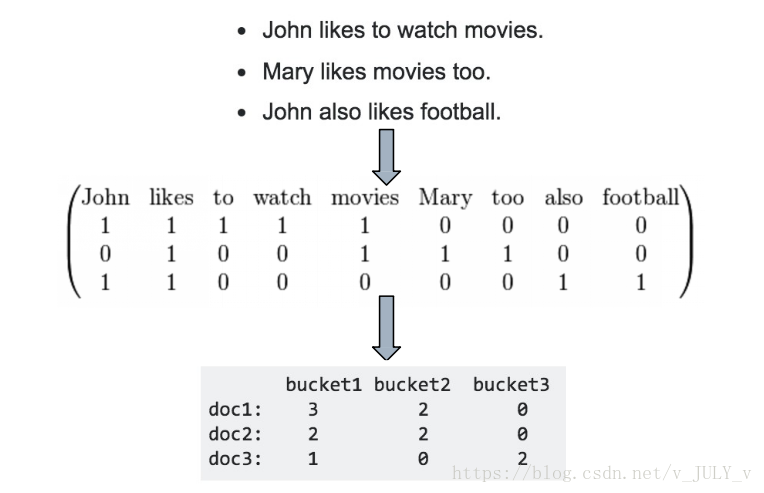
而針對(duì)一些文本形式的類別型數(shù)據(jù)時(shí),也可以使用Hash技巧做一些詞頻統(tǒng)計(jì)
最后,還有一種類別型的數(shù)據(jù),比如男性女性在很多行為上會(huì)有差別,對(duì)此,可以使用Histogram映射方法統(tǒng)計(jì)男女生的愛(ài)好。
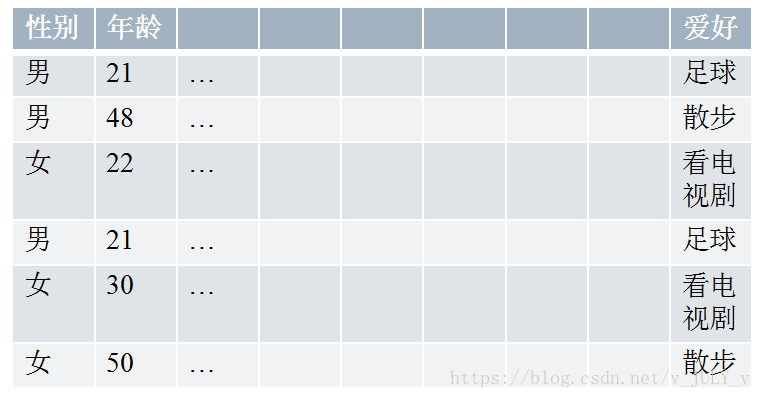
男:[1/3,2/3,0]; 女:[0,1/3,2/3]; 21:[1,0,0];22:[0,0,1]…
2.5.3 時(shí)間型數(shù)據(jù)
這些時(shí)間型數(shù)據(jù)可以看做是連續(xù)值:持續(xù)時(shí)間(用戶單頁(yè)的瀏覽時(shí)長(zhǎng))、間隔時(shí)間(用戶上次購(gòu)買(mǎi)/點(diǎn)擊離現(xiàn)在的時(shí)間)。
這些時(shí)間型數(shù)據(jù)可以看做是離散值:一天中哪個(gè)時(shí)間段(hour_0-23)、一周中星期幾(week_monday...)、一年中哪個(gè)星期、一年中哪個(gè)季度、工作日/周末等方面的數(shù)據(jù)。
2.5.4 文本型數(shù)據(jù)
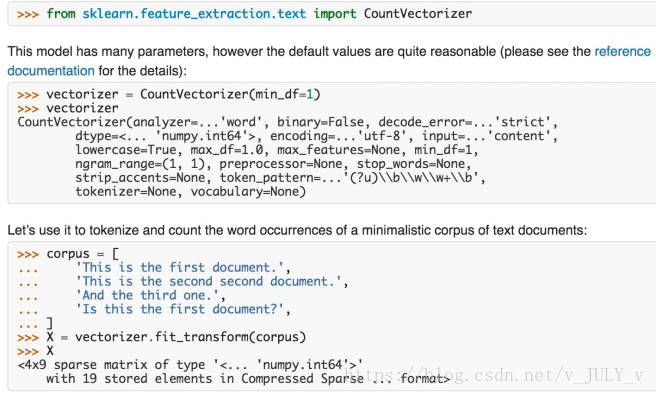
如果是文本類型的數(shù)據(jù),比如詞袋,則可以在文本數(shù)據(jù)預(yù)處理后,去掉停用詞,剩下的詞組成的list, 在詞庫(kù)中的映射稀疏向量。

下圖所示的操作是詞袋的Python處理方法
這個(gè)時(shí)候會(huì)遇到一個(gè)問(wèn)題,比如李雷喜歡韓梅梅,跟韓梅梅喜歡李雷這兩句話的含義是不一樣的,但用上面那種詞袋模型無(wú)法區(qū)分男追女還是女追男這種順序。
為處理這個(gè)問(wèn)題,可以把詞袋中的詞擴(kuò)充到n-gram

2.5.5 文本型數(shù)據(jù)
為了更準(zhǔn)確的評(píng)估一字詞對(duì)于一個(gè)文件集或一個(gè)語(yǔ) 料庫(kù)中的其中一份文件的重要程度,我們會(huì)用到TF-IDF這種統(tǒng)計(jì)方法。字詞的重要性隨著它在文件中 出現(xiàn)的次數(shù)成正比增加,但同時(shí)會(huì)隨著它在語(yǔ)料庫(kù)中出現(xiàn)的頻率成 反比下降。
TF: Term Frequency
TF(t) = (詞t在當(dāng)前文中出現(xiàn)次數(shù)) / (t在全部文檔中出現(xiàn)次數(shù))
IDF:IDF(t) = ln(總文檔數(shù)/ 含t的文檔數(shù))
實(shí)際使用中,我們便經(jīng)常用TF-IDF來(lái)計(jì)算權(quán)重,即TF-IDF = TF(t) * IDF(t)
對(duì)于詞袋,Google于2013年提出了Word2Vec這個(gè)模型,成為目前最常用的詞嵌入模型之一。??

對(duì)于這個(gè)模型,現(xiàn)在有各種開(kāi)源工具,比如:google word2vec、gensim、facebook fasttext
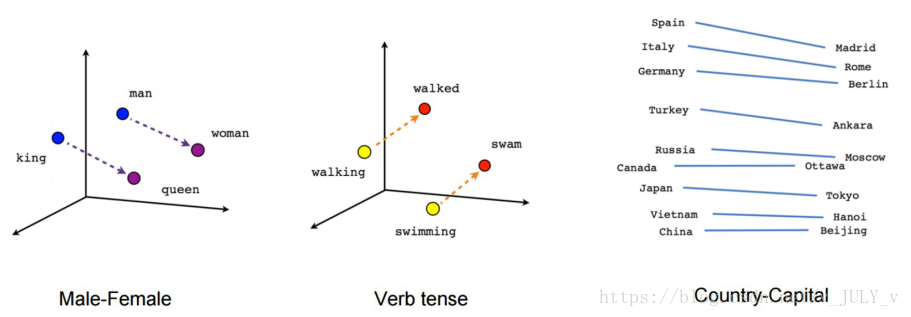
2.5.6 統(tǒng)計(jì)型數(shù)據(jù)
對(duì)于統(tǒng)計(jì)特征而言,歷屆的Kaggle/天池比賽,天貓/京東排序和推薦業(yè)務(wù)線里 模型用到的特征,比如
分位線:商品屬于售出商品價(jià)格的多少分位線處
次序型:排在第幾位
比例類:電商中,好/中/差評(píng)比例
你已超過(guò)全國(guó)百分之…的同學(xué)
2.5.7 組合特征
之前阿里云天池(目前是七月在線的長(zhǎng)期合作方)上有一個(gè)移動(dòng)推薦算法大賽,比賽的目標(biāo)是為了給移動(dòng)用戶在合適的時(shí)間地點(diǎn)下精準(zhǔn)推薦合適的商品/內(nèi)容,以提升移動(dòng)用戶的瀏覽或購(gòu)買(mǎi)體驗(yàn)。
競(jìng)賽題目
定義如下的符號(hào):
U——用戶集合I——商品全集
P——商品子集,P ? I
D——用戶對(duì)商品全集的行為數(shù)據(jù)集合
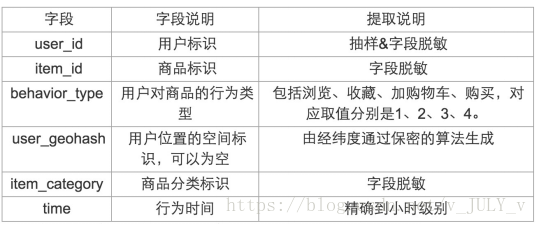
數(shù)據(jù)說(shuō)明
第一部分是用戶在商品全集上的移動(dòng)端行為數(shù)據(jù)(D),表名為tianchi_mobile_recommend_train_user,包含如下字段:

對(duì)于這個(gè)問(wèn)題,我們要做大量的數(shù)據(jù)處理,比如:
2、剔除掉在30天里從來(lái)不買(mǎi)東西的人 => 數(shù)據(jù)清洗
3、加車N件,只買(mǎi)了一件的,剩余的不會(huì)買(mǎi)=> 規(guī)則
4、購(gòu)物車購(gòu)買(mǎi)轉(zhuǎn)化率 =>用戶維度統(tǒng)計(jì)特征
5、商品熱度 =>商品維度統(tǒng)計(jì)特征
6、對(duì)不同item點(diǎn)擊/收藏/購(gòu)物車/購(gòu)買(mǎi)的總計(jì) =>商品維度統(tǒng)計(jì)特征
7、變熱門(mén)的品牌/商品 =>商品維度統(tǒng)計(jì)特征(差值型)
8、對(duì)不同item點(diǎn)擊/收藏/購(gòu)物車/購(gòu)買(mǎi)平均每個(gè)user的計(jì)數(shù)=>用戶維 度統(tǒng)計(jì)特征
9、最近第1/2/3/7天的行為數(shù)與平均行為數(shù)的比值 =>用戶維度統(tǒng)計(jì) 特征(比例型)
10、商品在類別中的排序 =>商品維度統(tǒng)計(jì)特征(次序型)
11、商品交互的總?cè)藬?shù) =>商品維度統(tǒng)計(jì)特征(求和型)
12、商品的購(gòu)買(mǎi)轉(zhuǎn)化率及轉(zhuǎn)化率與類別平均轉(zhuǎn)化率的比值=>商品維度統(tǒng) 計(jì)特征(比例型)
13、商品行為/同類同行為均值=>商品維度統(tǒng)計(jì)特征(比例型)
14、最近1/2/3天的行為(按4類統(tǒng)計(jì))=>時(shí)間型+用戶維度統(tǒng)計(jì)特征
15、最近的交互離現(xiàn)在的時(shí)間=>時(shí)間型
16、總交互的天數(shù)=>時(shí)間型
17、用戶A對(duì)品牌B的總購(gòu)買(mǎi)數(shù)/收藏?cái)?shù)/購(gòu)物車數(shù)=>用戶維度統(tǒng)計(jì)特征
18、用戶A對(duì)品牌B的點(diǎn)擊數(shù)的平方 =>用戶維度統(tǒng)計(jì)特征
19、用戶A對(duì)品牌B的購(gòu)買(mǎi)數(shù)的平方=>用戶維度統(tǒng)計(jì)特征
20、用戶A對(duì)品牌B的點(diǎn)擊購(gòu)買(mǎi)比=>用戶維度統(tǒng)計(jì)特征(比例型)
21、用戶交互本商品前/后,交互的商品數(shù)=>時(shí)間型+用戶維度統(tǒng)計(jì)特征
22、用戶前一天最晚的交互行為時(shí)間=>時(shí)間型
23、用戶購(gòu)買(mǎi)商品的時(shí)間(平均,最早,最晚)=>時(shí)間型
而有些特征也可以做一下組合,比如以下一些拼接型的簡(jiǎn)單組合特征
簡(jiǎn)單組合特征:拼接型
user_id&&style: 10001&&蕾絲 10002&&全棉
包括實(shí)際電商點(diǎn)擊率預(yù)估中:正負(fù)權(quán)重,喜歡&&不喜歡某種類型
以及一些模型特征組合
用GBDT產(chǎn)出特征組合路徑
組合特征和原始特征一起放進(jìn)LR訓(xùn)練
最早Facebook使用的方式,多家互聯(lián)網(wǎng)公司在用
包括另一種基于樹(shù)模型的組合特征:GBDT+LR,每一條分支都可以是一個(gè)特征,從而學(xué)習(xí)出來(lái)一系列組合特征。
3 特征選擇
冗余:部分特征的相關(guān)度太高了,消耗計(jì)算性能
噪聲:部分特征是對(duì)預(yù)測(cè)結(jié)果有負(fù)影響
針對(duì)這兩個(gè)問(wèn)題,咱們便得做下特征選擇,包括降維
特征選擇是指踢掉原本特征里和結(jié)果預(yù)測(cè)關(guān)系不大的
SVD或者PCA確實(shí)也能解決一定的高維度問(wèn)題
接下來(lái),咱們了解下各種特征選擇的方式。
3.1 過(guò)濾型
這種方法的缺點(diǎn)是:沒(méi)有考慮到特征之間的關(guān)聯(lián)作用,可能把有用的關(guān)聯(lián)特征誤踢掉。

過(guò)濾型特征選擇Python包

3.2 包裹型
比如用邏輯回歸,怎么做這個(gè)事情呢?
用全量特征跑一個(gè)模型
根據(jù)線性模型的系數(shù)(體現(xiàn)相關(guān)性),刪掉5-10%的弱特征,觀察準(zhǔn)確率/auc的變化
逐步進(jìn)行,直至準(zhǔn)確率/auc出現(xiàn)大的下滑停止
包裹型特征選擇Python包



3.3 嵌入型
且慢,什么是正則化?正則化一般分為兩種:L1正則化和L2正則化。
L1正則化是指權(quán)值向量w中各個(gè)元素的絕對(duì)值之和,通常表示為||w||1
L2正則化是指權(quán)值向量w中各個(gè)元素的平方和然后再求平方根(可以看到Ridge回歸的L2正則化項(xiàng)有平方符號(hào)),通常表示為||w||2
一般都會(huì)在正則化項(xiàng)之前添加一個(gè)系數(shù),Python中用α表示,一些文章也用λ表示。這個(gè)系數(shù)需要用戶指定。
那添加L1和L2正則化有什么用?
L2正則化可以防止模型過(guò)擬合(overfitting)。當(dāng)然,一定程度上,L1也可以防止過(guò)擬合
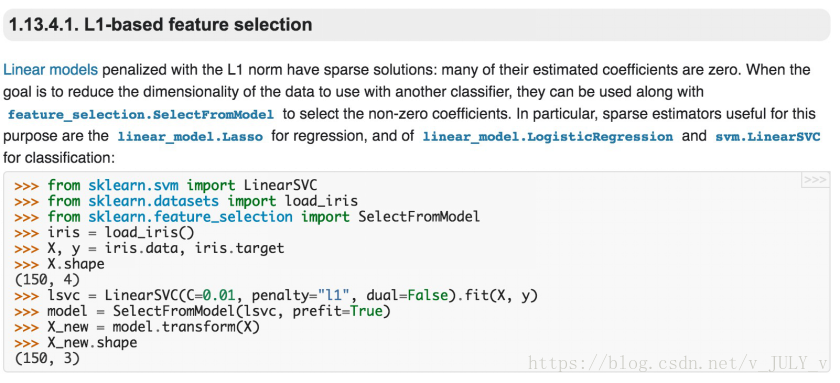
稀疏模型與特征選擇
稀疏矩陣指的是很多元素為0,只有少數(shù)元素是非零值的矩陣,即得到的線性回歸模型的大部分系數(shù)都是0. 通常機(jī)器學(xué)習(xí)中特征數(shù)量很多,例如文本處理時(shí),如果將一個(gè)詞組(term)作為一個(gè)特征,那么特征數(shù)量會(huì)達(dá)到上萬(wàn)個(gè)(bigram)。
在預(yù)測(cè)或分類時(shí),那么多特征顯然難以選擇,但是如果代入這些特征得到的模型是一個(gè)稀疏模型,表示只有少數(shù)特征對(duì)這個(gè)模型有貢獻(xiàn),絕大部分特征是沒(méi)有貢獻(xiàn)的,或者貢獻(xiàn)微小(因?yàn)樗鼈兦懊娴南禂?shù)是0或者是很小的值,即使去掉對(duì)模型也沒(méi)有什么影響),此時(shí)我們就可以只關(guān)注系數(shù)是非零值的特征。這就是稀疏模型與特征選擇的關(guān)系。
舉個(gè)例子,最早在電商用LR做CTR預(yù)估,在3-5億維的系數(shù) 特征上用L1正則化的LR模型。剩余2-3千萬(wàn)的feature,意 味著其他的feature重要度不夠。
嵌入型特征選擇Python包
至于課程上的兩個(gè)實(shí)踐案例,比如kaggle自行車租賃預(yù)測(cè)比賽暫不更。有興趣的可以先自行查看「特征工程與模型優(yōu)化特訓(xùn)」課程的視頻內(nèi)容,本文基本就是這次課的課程筆記。
今日學(xué)習(xí)推薦
想要逃避總有借口,想要成功總有辦法!今天給大家一個(gè)超棒的課程福利——【特征工程于模型優(yōu)化特訓(xùn)】課程!8月23日開(kāi)課,限時(shí)1分拼團(tuán)秒殺!
課程通過(guò)兩大實(shí)戰(zhàn)項(xiàng)目學(xué)習(xí)多種優(yōu)化方法,掌握比賽上分利器,且包含共享社群答疑 ??免費(fèi)CPU云平臺(tái)等課程配套服務(wù),理論和實(shí)踐完美結(jié)合;從數(shù)據(jù)采集到數(shù)據(jù)處理、到特征選擇、再到模型調(diào)優(yōu),帶你掌握一套完整的機(jī)器學(xué)習(xí)流程。
課程配備優(yōu)秀講師、專業(yè)職業(yè)規(guī)劃老師和助教團(tuán)隊(duì)跟蹤輔導(dǎo)、答疑,班主任督促學(xué)習(xí),群內(nèi)學(xué)員一起學(xué)習(xí),對(duì)抗惰性。
戳↓↓“閱讀原文”立即1分秒殺【特征工程與模型優(yōu)化特訓(xùn)】課程!