
【計(jì)算機(jī)視覺】檢測與分割詳解
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號
重磅干貨,第一時(shí)間送達(dá)
【導(dǎo)讀】神經(jīng)網(wǎng)絡(luò)在計(jì)算機(jī)視覺領(lǐng)域有著廣泛的應(yīng)用。只要稍加變形,同樣的工具和技術(shù)就可以有效地應(yīng)用于廣泛的任務(wù)。在本文中,我們將介紹其中的幾個(gè)應(yīng)用程序和方法,包括語義分割、分類與定位、目標(biāo)檢測、實(shí)例分割。
作者 | Ravindra Parmar
編譯 | Xiaowen
? ? ? ? ? ? ? ? ? ? ? ? ? ?
Detection andSegmentation through ConvNets
——計(jì)算機(jī)視覺-目標(biāo)檢測與分割
?
神經(jīng)網(wǎng)絡(luò)在計(jì)算機(jī)視覺領(lǐng)域有著廣泛的應(yīng)用。只要稍加變形,同樣的工具和技術(shù)就可以有效地應(yīng)用于廣泛的任務(wù)。在本文中,我們將介紹其中的幾個(gè)應(yīng)用程序和方法。最常見的四個(gè)是:
語義分割(Semantic segmentation)
分類與定位(Classification and localization)
目標(biāo)檢測(Object detection)
實(shí)例分割(Instance segmentation)
?
語義分割
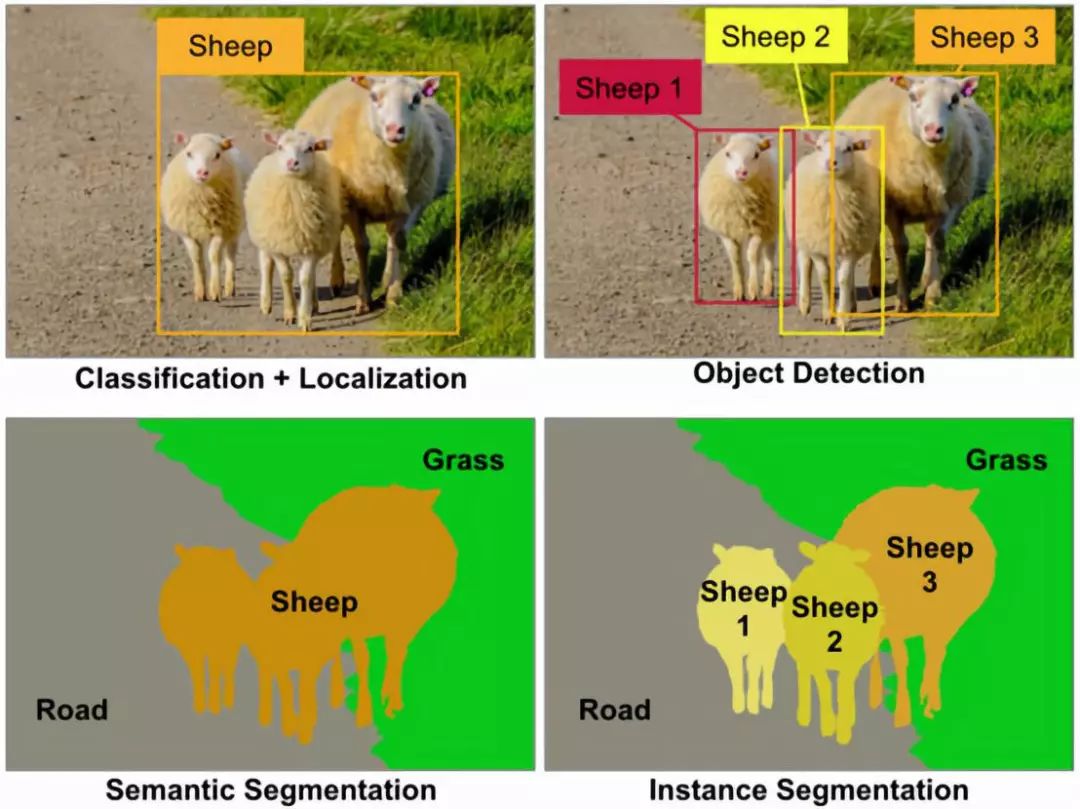
我們輸入圖像并輸出每個(gè)像素的類別決策。換句話說,我們希望將每個(gè)像素劃分為幾個(gè)可能的類別之一。這意味著,所有攜帶綿羊的像素都會被分類為一個(gè)類別,有草和道路的像素也會被分類。更重要的是,輸出不會區(qū)分兩種不同的綿羊。
?
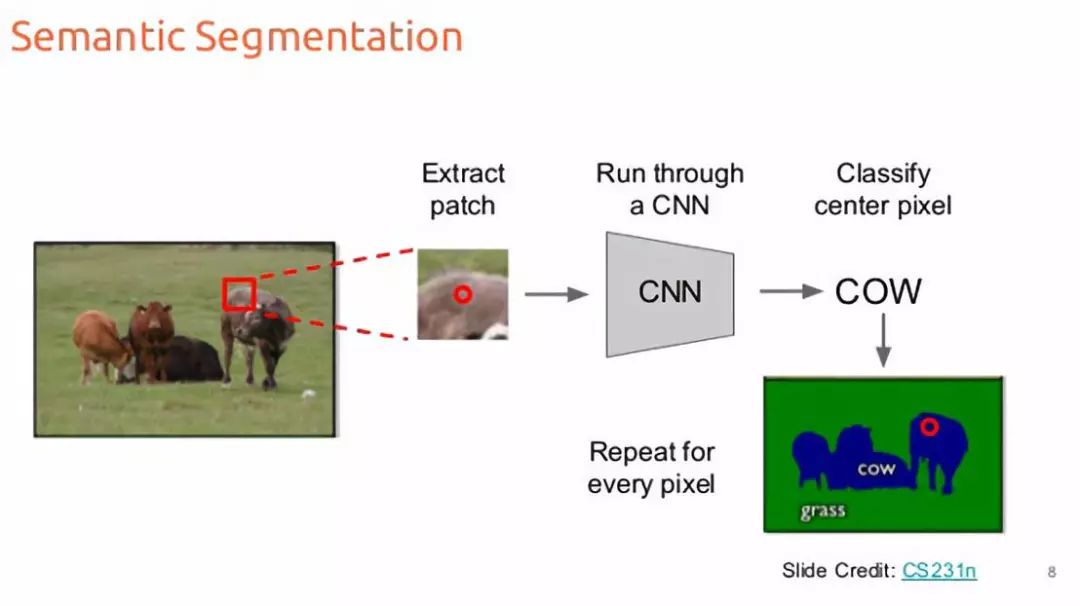
解決這個(gè)問題的一個(gè)可能的方法是把它當(dāng)作一個(gè)滑動(dòng)窗口的分類問題[1]。這樣我們就把輸入圖像分解成幾個(gè)大小相同的crop。然后每一種crop都會被傳送給CNN,作為輸出得到該crop的分類類別。像素級的crop會對每一個(gè)像素進(jìn)行分類。這是非常容易的,不是嗎?
滑動(dòng)窗口的語義分割
嗯,甚至不需要研究生學(xué)位就能看出這種方法在實(shí)際中的計(jì)算效率有多低。我們需要的是一種盡量將圖像的傳送次數(shù)減少到單道的方法。幸運(yùn)的是,有一些技術(shù)可以用所有卷積層來同時(shí)對所有像素進(jìn)行預(yù)測。
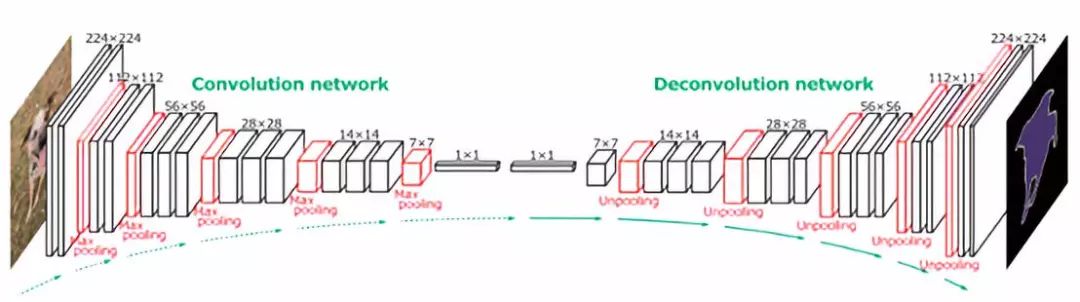
語義分割的全卷積層
如你所見,這樣的網(wǎng)絡(luò)將是下采樣和上采樣層的混合,以保持輸入圖像的空間大小(在像素級進(jìn)行預(yù)測)。下采樣是通過使用strides或max/avg pooling來實(shí)現(xiàn)的。另一方面,上采樣需要使用一些巧妙的技術(shù),其中兩個(gè)是-最近鄰[2]和轉(zhuǎn)置卷積[3]。
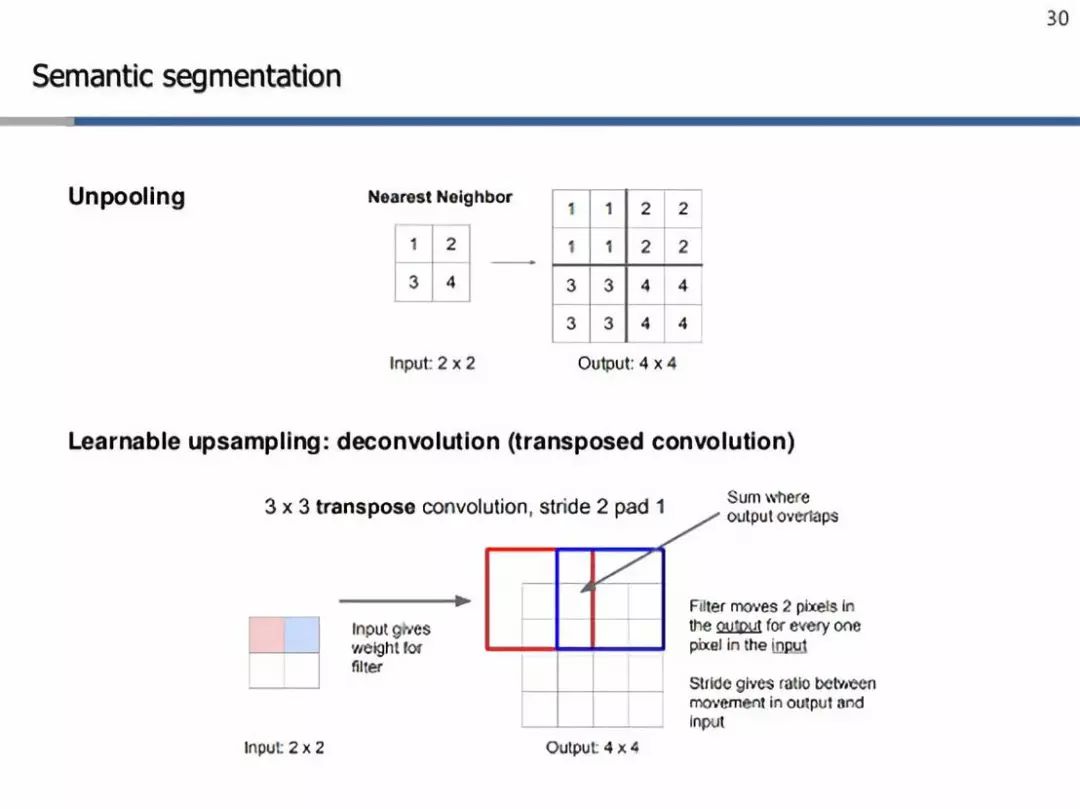
上采樣技術(shù)
簡而言之,最近鄰只是在它的接受域中復(fù)制特定元素(在上面的例子中是2x2)。另一方面,轉(zhuǎn)置卷積努力學(xué)習(xí)適當(dāng)?shù)臋?quán)重,為濾波器執(zhí)行上采樣。在這里,我們從左上角值開始,這是一個(gè)標(biāo)量,與過濾器相乘,并將這些值復(fù)制到輸出單元格中。然后,我們將濾波器中的一些特定像素與輸入中的一個(gè)像素成比例地移動(dòng)。這就是輸出和輸入之間的比率,這將給我們提供我們想要使用的步幅。在有重疊的情況下,我們只對數(shù)值進(jìn)行匯總。這樣,這些過濾器也構(gòu)成了這些網(wǎng)絡(luò)的可學(xué)習(xí)參數(shù),而不是一些固定的值集,就像最近的鄰居一樣。最后,利用像素級的交叉熵?fù)p失[4]對整個(gè)網(wǎng)絡(luò)進(jìn)行反向傳播訓(xùn)練[5]。
?
分類和定位
圖像分類[6]處理的是將類別標(biāo)簽分配給圖像。但是有時(shí),除了預(yù)測類別之外,我們還感興趣的是該對象在圖像中的位置。從數(shù)學(xué)的角度來說,我們可能希望在圖像的頂部畫一個(gè)包圍框。幸運(yùn)的是,我們可以重用圖像分類學(xué)到的所有工具和技術(shù)。
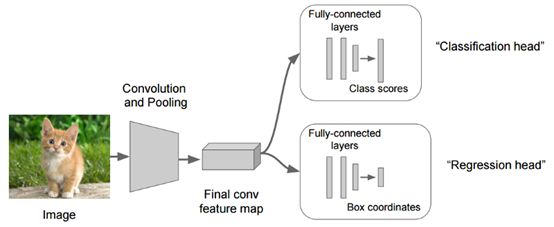
用于分類定位的卷積網(wǎng)絡(luò)
?
我們首先將輸入圖像輸入到某個(gè)巨大的ConvNet中,這將給出每個(gè)類別的分?jǐn)?shù)。但是現(xiàn)在我們有了另一個(gè)完全連接的層,它從先前層次生成的特征Map中預(yù)測對象的邊界框坐標(biāo)(x,y坐標(biāo)以及高度和寬度)。因此,我們的網(wǎng)絡(luò)將產(chǎn)生兩個(gè)輸出,一個(gè)對應(yīng)于圖像類,另一個(gè)對應(yīng)于邊界。為了訓(xùn)練這個(gè)網(wǎng)絡(luò),我們必須考慮兩個(gè)損失:分類的交叉熵?fù)p失和邊界預(yù)測的L1/L2損失[7](某種回歸損失)。
?
廣義上,這種預(yù)測固定數(shù)目集的思想可以應(yīng)用于除定位以外的各種計(jì)算機(jī)視覺任務(wù),如人體姿態(tài)估計(jì)。
?

人體姿態(tài)估計(jì)
在這里,我們可以定義人體姿勢的固定點(diǎn)集上的身體,例如關(guān)節(jié)。然后將我們的圖像輸入到ConvNet并輸出相同的固定點(diǎn)集(x,y)坐標(biāo)。然后我們可以在每一點(diǎn)上應(yīng)用某種回歸損失來通過反向訓(xùn)練來訓(xùn)練網(wǎng)絡(luò).
?
目標(biāo)檢測
目標(biāo)檢測的思想是從我們感興趣的一組固定類別開始,每當(dāng)這些類別中的任何一種出現(xiàn)在輸入圖像中時(shí),我們就會在圖像周圍畫出包圍框,并預(yù)測它的類標(biāo)簽。這與圖像分類和定位的不同之處在于,在前一種意義上,我們只對單個(gè)對象進(jìn)行分類和繪制邊框。而在后一種情況下,我們無法提前知道圖像中期望的對象數(shù)量。同樣,我們也可以采用蠻力滑動(dòng)窗口方法[8]來解決這個(gè)問題。然而,這又是一種計(jì)算效率低下的問題,很少有算法能有效地解決這一問題,比如基于Region proposal的算法,及基于yolo目標(biāo)檢測的算法[9]。
?
基于Region proposal的算法
給定一個(gè)輸入圖像,一個(gè)Regionproposal算法會給出成千上萬個(gè)可能出現(xiàn)對象的框。當(dāng)然,在沒有對象的情況下,輸出框中存在噪聲的可能性。但是,如果圖像中有任何對象,該算法就會選擇它作為候選框。
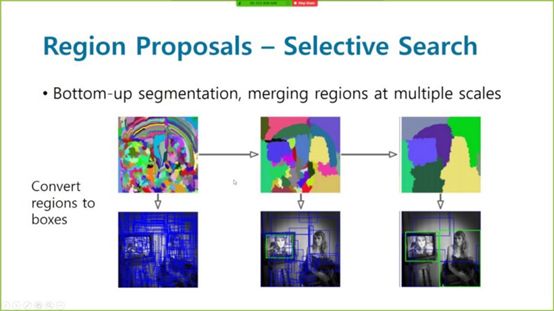
區(qū)域搜索的選擇性搜索
?
為了使所有的候選框都是一樣大小的,我們需要把它們變形到固定的方格大小,這樣我們最終就可以給網(wǎng)絡(luò)輸入了。然后,我們可以將一個(gè)巨大的ConvNets應(yīng)用到從region proposal輸出的每個(gè)候選框中以獲得最終類別。當(dāng)然,與蠻力滑動(dòng)窗口算法相比,它最終的計(jì)算效率要高得多。這就是R-CNN背后的整個(gè)想法。為了進(jìn)一步降低復(fù)雜度,采用Fast R-CNN的方法,F(xiàn)ast R-CNN的思想首先是通過ConvNet傳遞輸入圖像,得到高分辨率的特征圖,然后將這些region proposals強(qiáng)加到這個(gè)特征圖上,而不是實(shí)際的圖像上。這使得我們可以在有大量crops的情況下,在整個(gè)圖像中重用大量代價(jià)昂貴的卷積運(yùn)算。
?
YOLO(You only look once)
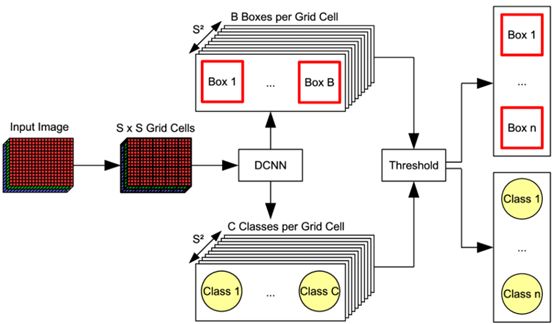
YOLO目標(biāo)檢測
Yolo背后的想法是,不要在所有提議的區(qū)域進(jìn)行獨(dú)立的處理,而是將所有的預(yù)測都重組為一個(gè)單一的回歸問題,從圖像像素到包圍框坐標(biāo)和分類概率。
?
我們首先將整個(gè)輸入圖像劃分為SXS網(wǎng)格,每個(gè)網(wǎng)格單元與b邊界(x,y,w,h)一起預(yù)測c條件的類概率(Pr(Class | Object)),每個(gè)邊界盒(x,y,w,h)都有一個(gè)置信度分?jǐn)?shù)。(x,y)坐標(biāo)表示邊框的中心相對于網(wǎng)格單元格的邊界,而寬度和高度則是相對于整個(gè)圖像預(yù)測。概率是以包含對象的網(wǎng)格單元為條件的。我們只預(yù)測每個(gè)網(wǎng)格單元格的一組類概率,而不管方框B的數(shù)量。置信度分?jǐn)?shù)反映了模型對框中包含對象的信心程度,如果框中沒有對象,則置信度必須為零。在另一個(gè)極端,置信度應(yīng)與預(yù)測框與ground truth標(biāo)簽之間的交集(IOU)相同。
?
Confidence score =Pr(Object) * IOU
?
在測試時(shí),我們將條件類概率和單個(gè)邊框置信度預(yù)測相乘,這給出了每個(gè)框的特定類別的置信度分?jǐn)?shù)。這些分?jǐn)?shù)既編碼了該類出現(xiàn)在盒子中的概率,也表示了預(yù)測的盒適合對象的程度。
?
Pr(Class | Object) ?(Pr(Object) ? IOU) = Pr(Class) ? IOU
?
實(shí)例分割
實(shí)例分割采用語義分割和目標(biāo)檢測相結(jié)合的技術(shù)。給定一幅圖像,我們希望預(yù)測該圖像中目標(biāo)的位置和身份(類似于目標(biāo)檢測),但是,與其預(yù)測這些目標(biāo)的邊界框,不如預(yù)測這些目標(biāo)的整個(gè)分割掩碼,即輸入圖像中的哪個(gè)像素對應(yīng)于哪個(gè)目標(biāo)實(shí)例。在此基礎(chǔ)上,我們對圖像中的每一只綿羊分別得到了分割掩碼,而語義分割中所有的綿羊都得到了相同的分割掩碼。
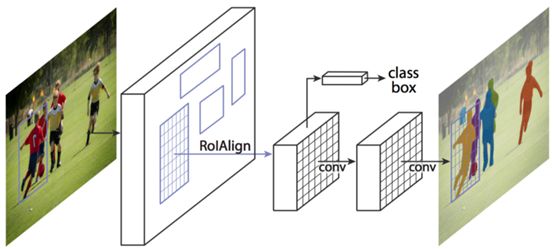
基于Mask R-CNN的實(shí)例分割
?
Mask R-CNN是這類任務(wù)的首選網(wǎng)絡(luò)。在這個(gè)多階段的處理任務(wù)中,我們通過一個(gè)ConvNet和一些學(xué)習(xí)region proposal網(wǎng)絡(luò)傳遞輸入圖像。一旦我們有了這些region proposal,我們就把這些proposals投影到卷積特征圖上,就像我們在R-CNN的情況下所做的那樣。然而現(xiàn)在,除了進(jìn)行分類和邊界框預(yù)測之外,我們還預(yù)測了每個(gè)region proposal的分割掩碼。
?
?
參考鏈接:
1.https://www.pyimagesearch.com/2015/03/23/sliding-windows-for-object-detection-with-python-and-opencv/
2. https://groups.google.com/d/topic/neon-users/I-x9ooJO5PA
3.https://towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
4. https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/
5. http://neuralnetworksanddeeplearning.com/chap2.html
6.https://medium.com/@tifa2up/image-classification-using-deep-neural-networks-a-beginner-friendly-approach-using-tensorflow-94b0a090ccd4
7.https://letslearnai.com/2018/03/10/what-are-l1-and-l2-loss-functions.html
8.https://www.pyimagesearch.com/2015/03/23/sliding-windows-for-object-detection-with-python-and-opencv/
9. https://pjreddie.com/darknet/yolo/
?
原文鏈接:
https://towardsdatascience.com/detection-and-segmentation-through-convnets-47aa42de27ea
本文僅做學(xué)術(shù)分享,如有侵權(quán),請聯(lián)系刪文。