
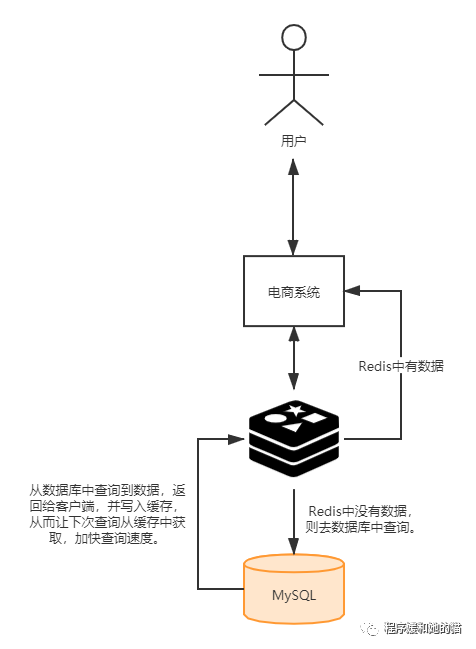
Redis緩存問題-緩存雪崩、緩存擊穿、緩存穿透
一、緩存雪崩
1、什么是緩存雪崩?
緩存雪崩是指緩存中大批量數(shù)據(jù)在同一時間過期,這一瞬間Redis跟沒有一樣,所有的請求都打到數(shù)據(jù)庫上,會導(dǎo)致數(shù)據(jù)庫壓力過大甚至宕機(jī)。
2、舉例說明
以淘寶平臺為例,假設(shè)某位研發(fā)同學(xué)將淘寶首頁所有商品在緩存中的過期時間設(shè)置為同一時間,雙十一零點搶購,大量用戶涌入,訪問淘寶(見緩存雪崩示意圖,此時M大概有幾千萬),倒霉的是此時首頁所有商品的緩存在這一刻都過期了,那么這幾千萬的訪問請求都落到了數(shù)據(jù)庫上,在如此高的并發(fā)量下,數(shù)據(jù)庫必然扛不住,可能會掛掉。
3、如何避免緩存雪崩?
(1)、事發(fā)前:保證Redis的高可用,主從架構(gòu)+Sentinel(哨兵),或者Redis Cluster(Redis集群),一旦主節(jié)點掛掉,其他節(jié)點可以繼續(xù)提供服務(wù)。如果Redis是集群部署,將熱點數(shù)據(jù)均勻分布在不同的Redis庫中,也可避免全部失效的問題。
(2)、事發(fā)中:限流降級組件,如果服務(wù)和接口都有限流機(jī)制,就算緩存全部失效了,但是請求的總量是有限制的,可以在承受范圍之內(nèi),這樣短時間內(nèi)系統(tǒng)響應(yīng)慢點,但不至于掛掉,影響整個系統(tǒng)。
常見的限流降級組件有Hystrix(SpringCloud斷路器)和Sentinel(阿里巴巴開源的限流降級組件)。
(3)、事發(fā)后:Redis持久化(RDB + AOF組合策略),萬一Redis真的掛了,重啟Redis從磁盤加載數(shù)據(jù)到內(nèi)存,快速恢復(fù)緩存數(shù)據(jù)。
(4)、優(yōu)化緩存過期時間:設(shè)計緩存時,為每一個 key 設(shè)置不同的過期時間(一般是給每個Key的失效時間都加個隨機(jī)值),避免大量的 key 在同一時刻集中失效。
setRedis(Key,value,time + Math.random() * 10000);
(5)、熱點數(shù)據(jù)設(shè)置永不過期,有更新操作則更新緩存即可。
二、緩存擊穿
1、什么是緩存擊穿?
緩存擊穿是指一個Key非常熱點,在不停的扛著大并發(fā),大并發(fā)集中對這一個點進(jìn)行訪問,當(dāng)這個Key在失效的瞬間,持續(xù)的大并發(fā)就穿破緩存,直接請求數(shù)據(jù)庫,會導(dǎo)致數(shù)據(jù)庫壓力過大甚至宕機(jī)。
2、緩存擊穿和緩存雪崩
緩存擊穿和緩存雪崩有點像,二者的區(qū)別如下:
緩存雪崩:大量的數(shù)據(jù)在同一時間過期,所有的請求打到數(shù)據(jù)庫,導(dǎo)致數(shù)據(jù)庫壓力過大。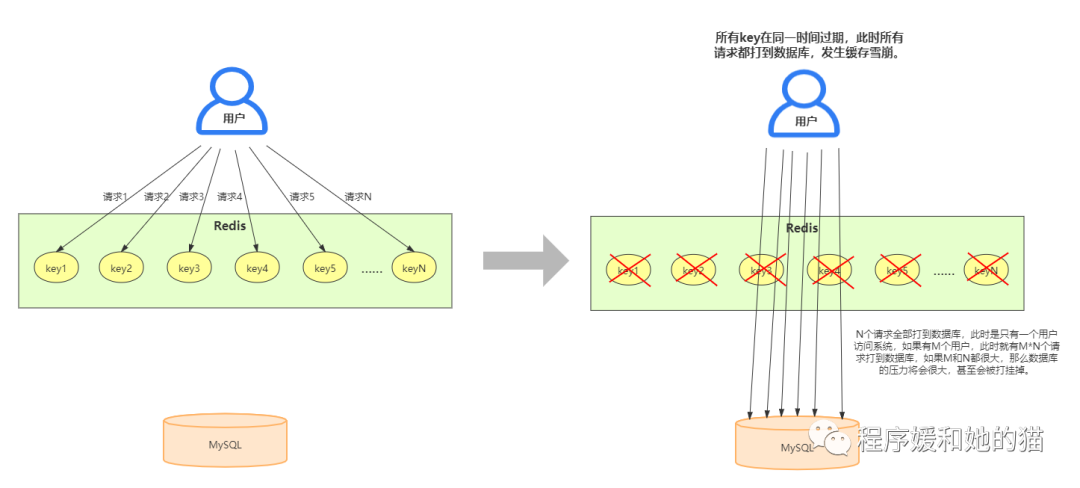 緩存雪崩示意圖
緩存雪崩示意圖
緩存擊穿:并發(fā)請求同一個數(shù)據(jù)(熱點數(shù)據(jù)),這個數(shù)據(jù)在某一瞬間失效,所有的并發(fā)請求打到數(shù)據(jù)庫,導(dǎo)致數(shù)據(jù)庫壓力過大。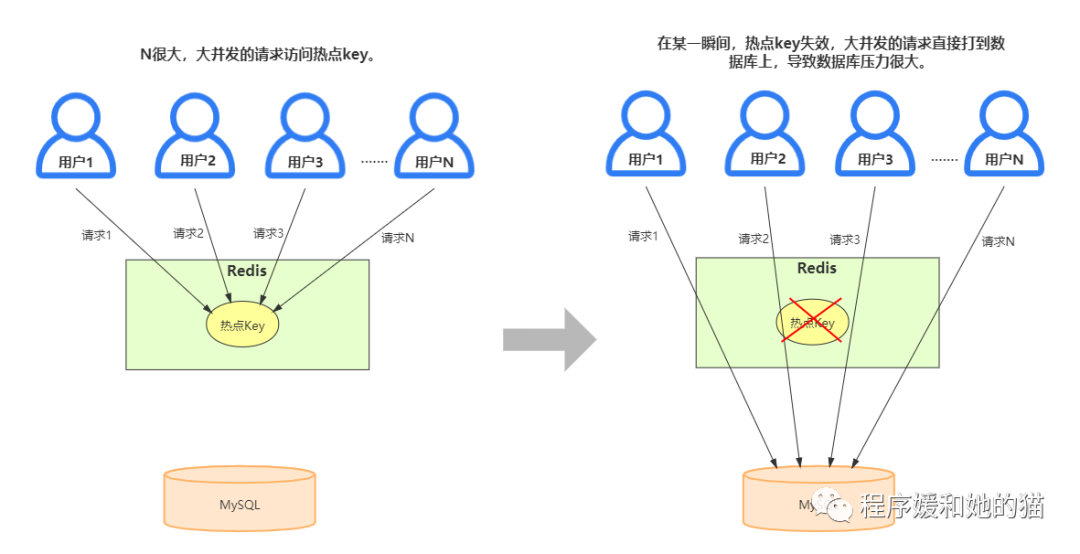
緩存擊穿示意圖
3、舉例說明
李佳琪今晚24點抖音直播,Lamer面霜做活動,前500名打3折,這么便宜,想必很多小仙女都會去搶購,24點到了,大家都涌進(jìn)直播間搶購商品,如果這個時候,該商品在緩存中過期了,那么這么高的請求全部都打到數(shù)據(jù)庫上了,數(shù)據(jù)庫可能承受不了壓力,一下子就崩了,完了,一件也沒賣出去,用戶對平臺的印象分也大大降低。
4、如何避免緩存擊穿?
(1)、可以將熱點數(shù)據(jù)的過期時間設(shè)置為永久有效(有人可能會問,萬一這個熱點商品下架了,這個緩存不就成了了臟數(shù)據(jù)嗎?其實會有這種場景存在,主要還是具體情況具體分析,看業(yè)務(wù)場景吧)。
(2)、使用互斥鎖:當(dāng)在緩存中拿不到數(shù)據(jù)時,只讓一個線程去查詢數(shù)據(jù)庫,拿到數(shù)據(jù)后,重新設(shè)置到緩存中,其他線程等到緩存重建完,直接從緩存中讀取數(shù)據(jù)即可。
如果是單機(jī),可以用synchronized或者Lock來處理,如果是分布式環(huán)境可以用分布式鎖。
// 單機(jī)鎖
public synchronized String getValue(String key) {
String value = redis.get(key);
if (value == null) {
value = db.get(key);
redis.set(key, value);
}
return value;
}
// 分布式鎖
public String getValue(key) {
String value = redis.get(key);
if (value == null) {
// 使用setnx做分布式鎖
// 設(shè)置3分鐘的超時,是為了防止由于del操作失敗,后續(xù)線程一直操作數(shù)據(jù)庫而降低效率。
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) {// 加鎖成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else {
// 獲取到分布式鎖的線程已經(jīng)重建好緩存了,其他線程直接從緩存中獲取即可。
sleep(50);
value = get(key);
}
} else {
return value;
}
}
三、緩存穿透
1、什么是緩存穿透?
緩存穿透是指訪問緩存和數(shù)據(jù)庫中都沒有的數(shù)據(jù),這樣的話,每次請求都會打到數(shù)據(jù)庫上,如果是高并發(fā)的請求(一般是黑客故意攻擊),就會導(dǎo)致數(shù)據(jù)庫壓力過大甚至宕機(jī)。

2、舉例說明
還是拿淘寶平臺舉例,假設(shè)某位研發(fā)同學(xué)在開發(fā)一個接口的時候,默認(rèn)當(dāng)在緩存中查詢不到數(shù)據(jù),就從數(shù)據(jù)庫中查詢。
我們數(shù)據(jù)庫的 id 都是1開始自增上去的,黑客抓住這個漏洞,如果他想惡意攻擊,寫一個腳本,將查詢 id 為 -1 的請求循環(huán)發(fā)送100w次,那么由于緩存和數(shù)據(jù)庫不會存在這條數(shù)據(jù),那么這100w請求都會打到數(shù)據(jù)庫,數(shù)據(jù)庫承受不住壓力,可能就掛掉了。
3、如何避免緩存穿透?
(1)、使用布隆過濾器(Bloom Filter)在緩存前進(jìn)行攔截,過濾一些異常的請求,將數(shù)據(jù)庫中存在的數(shù)據(jù)寫入布隆過濾器,那么當(dāng)用戶訪問一個數(shù)據(jù)庫中不存在的數(shù)據(jù),在布隆過濾器那塊就被攔截了。
(2)、針對在數(shù)據(jù)庫中找不到記錄的,我們?nèi)匀?strong>將該空數(shù)據(jù)存入緩存中(key對應(yīng)的value設(shè)置成null、“稍后重試”等),當(dāng)然一般會設(shè)置一個較短的過期時間。
(3)、對請求參數(shù)做校驗,例如可以用正則,比如上面的那個例子,id <=0 的請求直接返回。