
導(dǎo)語 | Elasticsearch于7.10版本推出可搜索快照功能,但是7.10版本的可搜索快照技術(shù)還不夠成熟,隨著7.14版本的發(fā)布,可搜索快照技術(shù)才真正能夠大規(guī)模用于生產(chǎn)實(shí)踐中。本文將基于ES 7.14.2版本,繼續(xù)從原理和實(shí)踐兩個(gè)角度向大家介紹可搜索快照技術(shù)。
可搜索快照特性向我們展現(xiàn)一種能夠直接搜索快照中數(shù)據(jù)的魔力,通常我們會(huì)將快照備份到非常廉價(jià)的存儲(chǔ)介質(zhì)中,如騰訊云對象存儲(chǔ)COS中。這樣我們就可以將集群的使用成本降到最低。
(一)DataTier模型
要了解可搜索快照的工作機(jī)制,首先我們需要了解從7.10版本開始ES對節(jié)點(diǎn)的分層規(guī)劃,即DataTier概念。
(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/data-tiers.html#frozen-tier)
ES對不同的節(jié)點(diǎn)類型做了如下分層,分別是Content tier、Hot tier、Warm tier、Cold tier和Frozen tier。
(二)節(jié)點(diǎn)屬性優(yōu)化
另外7.10版本之后的集群不再通過node.master,node.data來區(qū)分是何種角色的節(jié)點(diǎn),而是通過node.roles數(shù)組來定義一個(gè)節(jié)點(diǎn)的角色。如我們的測試集群中,Hot tier節(jié)點(diǎn)的node.roles如下:
node.roles: ["data_hot", "data_content", "ingest", "ml", "remote_cluster_client", "transform"]
專用主節(jié)點(diǎn)的node.roles則是:
如果集群中有Frozen tier的節(jié)點(diǎn),我們通過是將該節(jié)點(diǎn)設(shè)置為專用Frozen節(jié)點(diǎn),不和任何角色混用,如設(shè)置node.roles如下:
node.roles: ["data_frozen"]
除了對節(jié)點(diǎn)角色的優(yōu)化,還對索引的allocation做了優(yōu)化,原先我們是通過include.{attribute}、require.{attribute}、exclude.{attribute}來設(shè)置索引的allocation settings;而升級到DataTier模式后,則是通過index.routing.allocation.include._tier_preference
(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/data-tier-shard-filtering.html#tier-preference-allocation-filter)屬性決定索引分片應(yīng)該分配在哪一Tier節(jié)點(diǎn)上。
index.routing.allocation.include._tier_preference的屬性值是一個(gè)字符串,多個(gè)tier_preference之間通過逗號“,”隔開,分片分配的優(yōu)先級是從前往后依次降低。例如集群中的系統(tǒng)索引.kibana_7.14.2_001在創(chuàng)建時(shí),其index.routing.allocation.include._tier_preference屬性值為:“data_hot,data_warm,data_cold”,如下圖1所示:
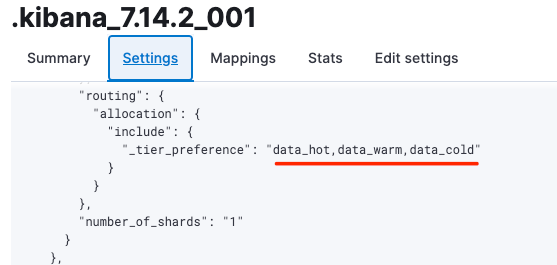
圖1 索引創(chuàng)建時(shí)的_tier_preference屬性
該屬性的具體分配邏輯為:當(dāng)集群中有data_hot節(jié)點(diǎn)時(shí),則直接將分片分配在data_hot節(jié)點(diǎn)上,當(dāng)沒有data_hot節(jié)點(diǎn)時(shí),則檢查是否有data_warm節(jié)點(diǎn),如果有,則在data_warm節(jié)點(diǎn)上分配,沒有則在data_cold節(jié)點(diǎn)上分配。因此如果我們希望對集群中的數(shù)據(jù)進(jìn)行降冷時(shí),只需要將待降冷的索引settings設(shè)置為如下即可:
PUT {index_name}/_settings{ "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_warm,data_cold,data_hot" } } } }}
(三)工作原理
上面我們介紹了下7.10版本中引入的DataTier和_tier_preference概念,之所以先了解DataTier,是因?yàn)榭伤阉骺煺沼袃煞N掛載模式,分別對應(yīng)的是兩類不同的節(jié)點(diǎn)角色,即我們通過使用Cold或者Frozen數(shù)據(jù)節(jié)點(diǎn)來掛載可搜索快照數(shù)據(jù),從而大大降低我們的集群成本。
若要對快照中數(shù)據(jù)進(jìn)行查詢,首先我們需要將快照中的數(shù)據(jù)Mount(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/searchable-snapshots-api-mount-snapshot.html)到集群中,而不是直接通過API去Search快照中的數(shù)據(jù)。
全量掛載的意思就是將快照中索引的數(shù)據(jù)在ES集群節(jié)點(diǎn)上全量保留一份,當(dāng)搜索全量掛載的可搜索快照索引時(shí),搜索原理和性能和普通索引相差不大。相比普通索引的優(yōu)勢在于,當(dāng)其中一個(gè)分片出現(xiàn)損壞時(shí),可搜索快照索引會(huì)自動(dòng)從快照中拉取數(shù)據(jù)在其他節(jié)點(diǎn)上進(jìn)行恢復(fù),尤其是在集群中沒有副本的情況下,普通模式是集群直接red,如果需要恢復(fù),則必須手動(dòng)從快照中進(jìn)行恢復(fù),在恢復(fù)前還需要先將該red的索引刪除,而通過mount掛載下來的索引,則自動(dòng)從快照中恢復(fù)損壞的分片。
部分掛載的意思就是并不將快照中的索引數(shù)據(jù)mount到集群節(jié)點(diǎn)上,而是只將索引的元數(shù)據(jù)信息保存以索引和分片的形式保留在節(jié)點(diǎn)上。部分掛載的分片只會(huì)分配在Frozen層。因此集群中Frozen層節(jié)點(diǎn)不存儲(chǔ)快照數(shù)據(jù),只存儲(chǔ)索引分片的元數(shù)據(jù)信息,原始數(shù)據(jù)存儲(chǔ)在COS的快照倉庫中。如下API樣例所示,其中storage就是索引的掛載類型:full_copy是全量掛載,而shared_cache則為部分掛載。
POST /_snapshot/default_searchable_snapshot_repository/my_cos_snapshot/_mount?wait_for_completion=true&storage=shared_cache{ "index": "wurong-test-2021.11.26-000001", "renamed_index": "wurong-test-2021.11.26-000001_from_cos", "index_settings": { "index.number_of_replicas": 0 }, "ignore_index_settings": [ "index.refresh_interval" ] }
當(dāng)查詢部分掛載的可搜索快照索引時(shí),會(huì)從快照中進(jìn)行拉取并加載在Frozen層節(jié)點(diǎn)本地緩存中,下次查詢類似數(shù)據(jù)時(shí)則可以直接從本地進(jìn)行返回,另外ES也有緩存淘汰策略,會(huì)定期清理不再經(jīng)常查詢的緩存數(shù)據(jù)以釋放空間。通常需要配置一個(gè)或多個(gè)專用Frozen節(jié)點(diǎn),這些專用Frozen節(jié)點(diǎn)之間共享緩存。如果集群中沒有配置專用Frozen節(jié)點(diǎn),則必須在節(jié)點(diǎn)的配置文件中配置如下參數(shù)xpack.searchable.snapshot.shared_cache.size來設(shè)置每個(gè)節(jié)點(diǎn)中需要為共享緩存保留的存儲(chǔ)空間。因?yàn)椴糠謷燧d的可搜索快照索引只會(huì)在分配在具有共享緩存的節(jié)點(diǎn)上。
另外由于Frozen節(jié)點(diǎn)上存儲(chǔ)的是索引的元數(shù)據(jù)信息,以及查詢的緩存數(shù)據(jù)。因此在配置Frozen節(jié)點(diǎn)時(shí),需要給共享緩存預(yù)留一定的硬盤空間,默認(rèn)需要保留至少90%的磁盤總?cè)萘浚鐖D2所示,通過xpack.searchable.snapshot.shared_cache.size參數(shù)進(jìn)行調(diào)整。
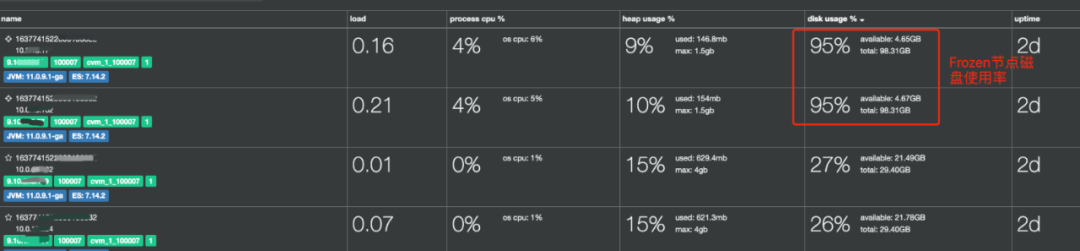
圖2 Frozen節(jié)點(diǎn)磁盤使用率
由于該參數(shù)是一個(gè)static類型,因此當(dāng)我們給Frozen節(jié)點(diǎn)的硬盤進(jìn)行擴(kuò)容時(shí),如采用騰訊云CBS的彈性拉伸時(shí)擴(kuò)容時(shí),則需要重啟Frozen節(jié)點(diǎn)才能使得xpack.searchable.snapshot.shared_cache.size參數(shù)生效。
查詢Frozen節(jié)點(diǎn)上的數(shù)據(jù)需要先將索引數(shù)據(jù)下拉到本地節(jié)點(diǎn)上才開始執(zhí)行Search查詢。因此查詢時(shí)間上必然是比全量掛載或者查詢普通的索引慢很多的,為了解決這個(gè)問題,ES提供了一種Async Search(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/async-search.html)異步搜索的API。當(dāng)執(zhí)行該API時(shí)候,并不會(huì)立即獲取到查詢結(jié)果,而是返回一個(gè)requestId,隨后異步準(zhǔn)備數(shù)據(jù),當(dāng)數(shù)據(jù)準(zhǔn)備好后,只需要通過該requestId即可獲取到想要的數(shù)據(jù)了(以下樣例來源官網(wǎng))。
POST /sale*/_async_search?size=0{ "sort": [ { "date": { "order": "asc" } } ], "aggs": { "sale_date": { "date_histogram": { "field": "date", "calendar_interval": "1d" } } }}
由此我們可以看出Frozen層的部分掛載模式才是可搜索快照技術(shù)的真正亮點(diǎn),因?yàn)樗恍枰狥rozen節(jié)點(diǎn)很少的硬盤空間,即可Search過去無限規(guī)模的數(shù)據(jù)。達(dá)到了真正降低成本的目的。
下面我們基于騰訊云COS來逐步演示如何一步步搭建可搜索快照集群,我們要實(shí)現(xiàn)的效果是通過壓測程序持續(xù)向集群中寫入數(shù)據(jù),索引在10分鐘或者達(dá)到10mb后開始滾動(dòng),滾動(dòng)完成后1小時(shí)開始遷移到冷節(jié)點(diǎn)上,并且執(zhí)行COS備份,備份完成后全量掛載到集群中,刪除集群中原來的索引數(shù)據(jù),2小時(shí)后將索引部分掛載到集群中,此時(shí)索引分片分配在凍結(jié)層。其數(shù)據(jù)流轉(zhuǎn)架構(gòu)如下圖3所示:
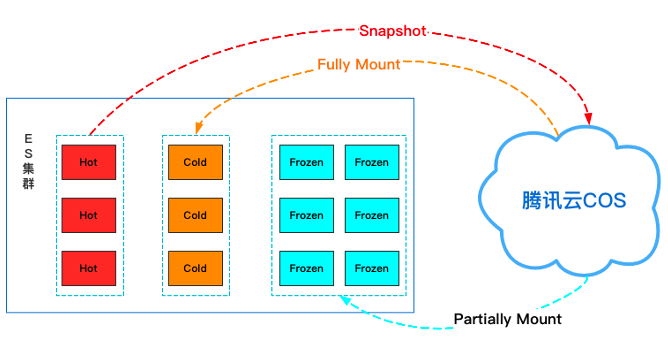
圖3 可搜索快照演練數(shù)據(jù)流轉(zhuǎn)示意圖
(一)集群環(huán)境準(zhǔn)備
我們搭建的集群是7.14.2版本,由于可搜索快照技術(shù)只能在企業(yè)版本使用,因此我們在創(chuàng)建出7.14集群后需要手動(dòng)調(diào)下如下API來免費(fèi)試用企業(yè)版:
POST /_license/start_trial?acknowledge=true
調(diào)用API后如圖4所示,說明當(dāng)前集群已經(jīng)是企業(yè)版集群了。

(二)創(chuàng)建快照倉庫
本文測試集群使用的是騰訊云COS,因此我們需要在集群中創(chuàng)建一個(gè)COS倉庫,用于可搜索快照的存放,倉庫名稱為default_searchable_snapshot_repository。
PUT _snapshot/default_searchable_snapshot_repository{ "type": "cos", "settings": { "app_id": "1254139681", "access_key_id": "xxxx", "access_key_secret": "xxxx", "bucket": "wurong-es-snapshpt", "region": “ap-guangzhou", "compress": true, "chunk_size": "500mb", "base_path": "/searchable-snapshot" }}
(三)配置索引生命周期管理
首先我們在Kibana上配置索引生命周期管理的Policy,路徑為:Management-Stack Management-Data-Index Lifecycle Polices。主要是設(shè)置ILM的策略名稱,每個(gè)Phase的觸發(fā)Condition。
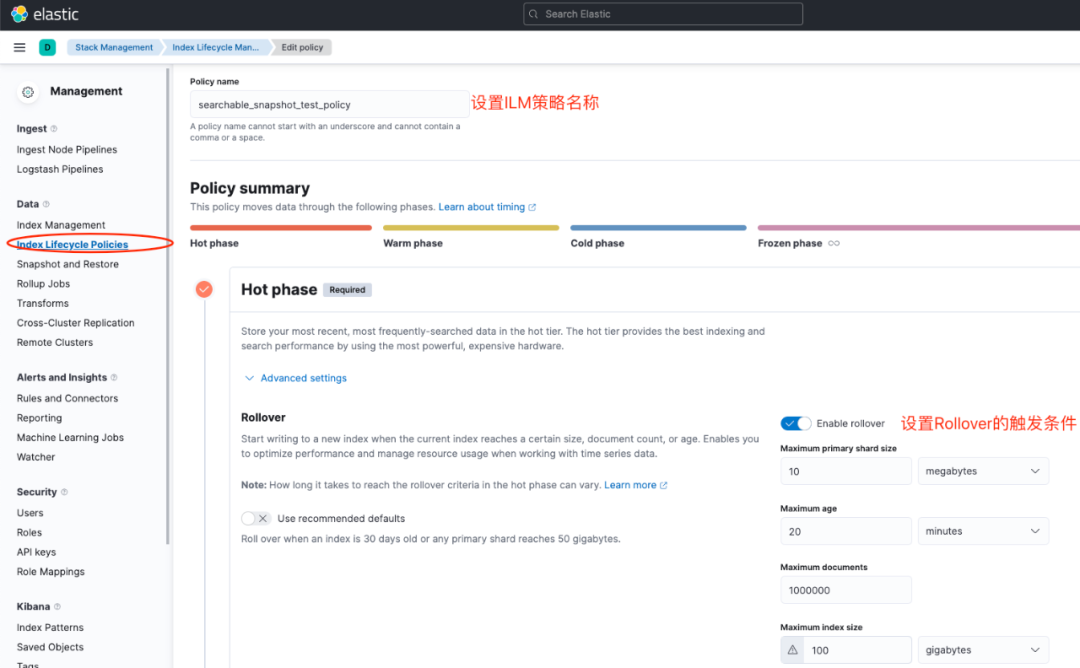
圖5 配置ILM的Policy-Hot phase
上面我們設(shè)置好了Hot phase,主要是設(shè)置Rollover的觸發(fā)條件,我們希望索引在創(chuàng)建后20分鐘,或者主分片容量達(dá)到10mb后觸發(fā)滾動(dòng),寫入下一個(gè)索引。
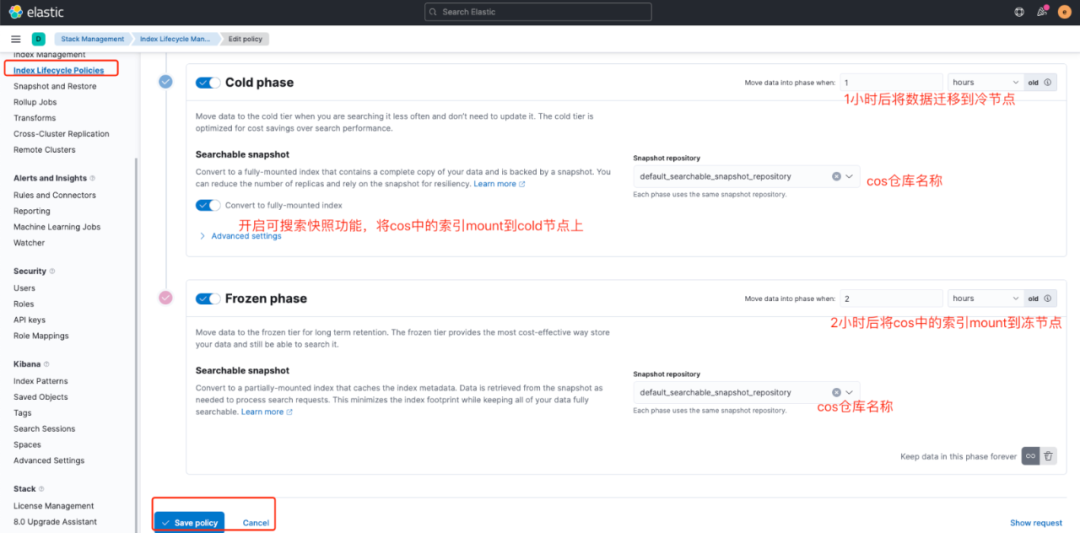
圖6 配置ILM的Policy-Cold/Frozen phase
圖6我們配置了Cold/Frozen phase的信息。我們想要達(dá)到的效果是索引在觸發(fā)Rollover后的1小時(shí)開始降冷,將數(shù)據(jù)遷移到Cold tier上來,并且將數(shù)據(jù)備份到COS倉庫,然后再全量Mount到集群中,在然后2小時(shí)后將cos中的索引部分mount到集群中。
上面我們是通過Kibana進(jìn)行配置的,我們也可以直接通過API進(jìn)行配置,效果是一樣的:
PUT _ilm/policy/searchable_snapshot_test_policy { "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max_size": "100mb", "max_primary_shard_size": "10mb", "max_age": "20m", "max_docs": 1000000 }, "set_priority": { "priority": 100 } } }, "cold": { "min_age": "1h", "actions": { "searchable_snapshot": { "snapshot_repository": "default_searchable_snapshot_repository", "force_merge_index": true }, "set_priority": { "priority": 0 }, "allocate": { "number_of_replicas": 0 } } }, "frozen": { "min_age": "2h", "actions": { "searchable_snapshot": { "snapshot_repository": "default_searchable_snapshot_repository", "force_merge_index": true } } } } }}
在索引模版中指定創(chuàng)建的ILM policy和Rollover別名,模版名稱為searchable_snapshot_test_template,policy名稱為searchable_snapshot_test_policy,別名為wurong-test,_tier_preference為“data_hot,data_warm,data_cold”。
PUT _template/searchable_snapshot_test_template{ "order": 100, "index_patterns": [ "wurong-test*" ], "settings": { "index": { "lifecycle": { "name": "searchable_snapshot_test_policy", "rollover_alias": "wurong-test" }, "routing": { "allocation": { "include": { "_tier_preference": "data_hot,data_warm,data_cold" } } }, "refresh_interval": "30s", "number_of_shards": "5", "translog": { "sync_interval": "5s", "durability": "async" }, "max_result_window": "65536", "unassigned": { "node_left": { "delayed_timeout": "5m" } }, "number_of_replicas": "1" } }}
我們期望在索引名稱上加上日期,因此使用如下的方式進(jìn)行創(chuàng)建。
PUT %3Cwurong-test-%7Bnow%2Fd%7D-000001%3E{"aliases": { "wurong-test":{ "is_write_index": true } }}
創(chuàng)建完成后可以看出索引名稱上包含了當(dāng)前的日期,且后綴從000001開始。
然后通過壓測程序開始向集群中寫入數(shù)據(jù),并且通過別名進(jìn)行寫入。
當(dāng)我們持續(xù)往集群中寫入半天的數(shù)據(jù)后,可以看到部分名稱是restored-*開頭的索引,這些索引就是從COS快照中Mount到本地的,如圖8所示。
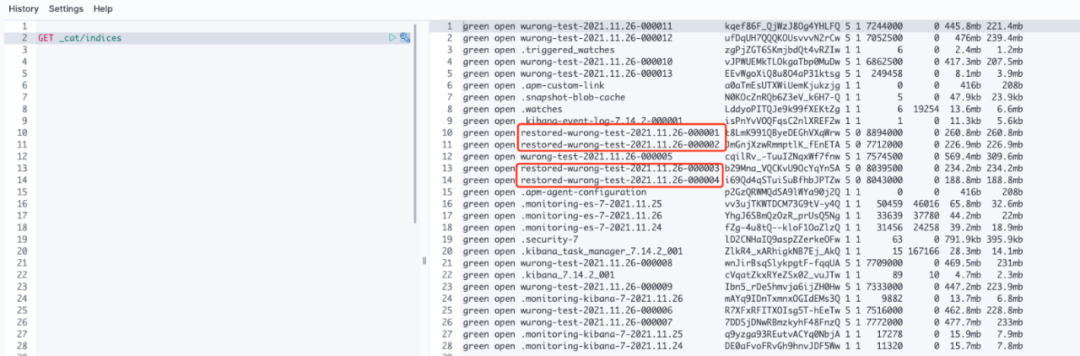
我們以restored-wurong-test-2021.11.26-000001為例子,查看該索引的settings信息,如下圖9所示:
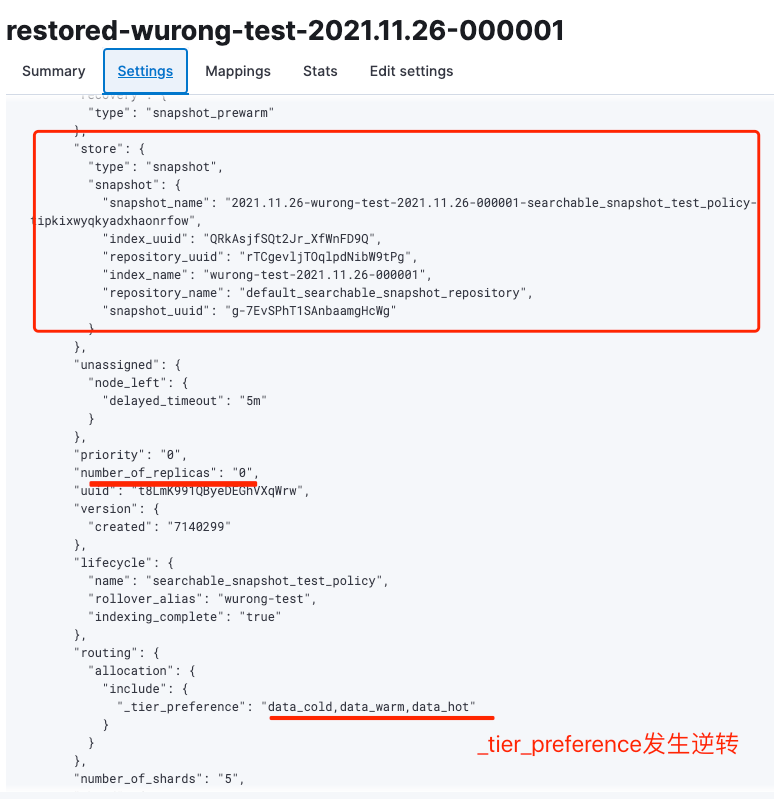
從restored-wurong-test-2021.11.26-000001索引的settings信息中可以看出分片副本被設(shè)置為了0,_tier_preference也從原先的“_tier_preference”:“data_hot,data_warm,data_cold”,調(diào)整成了“_tier_preference”:“data_cold,data_warm,data_hot”,由此也可以看出這個(gè)索引是通過全量掛載模式mount到集群中的。并且在store對象中詳細(xì)列出了mount快照的信息,如倉庫名稱,快照名稱,快照Id和索引Id等。
當(dāng)觸發(fā)了Frozen phase的條件后,索引分片會(huì)被分配到Frozen tier節(jié)點(diǎn)上,且該索引是按照我們在ILM policy中定義的那樣,通過部分掛載,即Partially mount模式掛載在Frozen tier節(jié)點(diǎn)上的。從Kibana上我們可以看到,該類索引名稱是以partial-*開頭,其Docs數(shù)量是7413000,但是Storage size大小為0,這說明該索引在集群上是不占用存儲(chǔ)空間的,只有索引的元數(shù)據(jù)信息。如圖10所示:
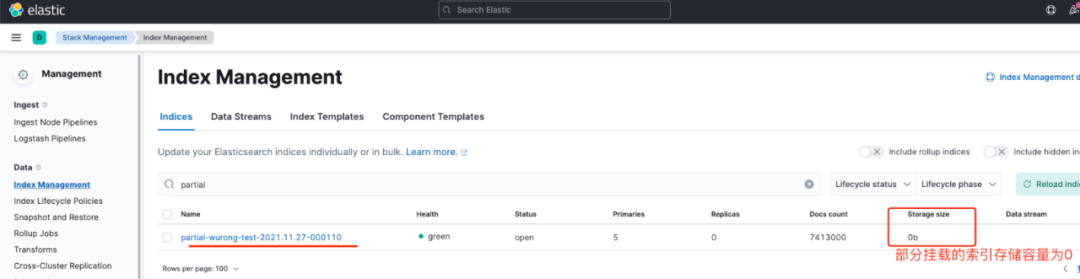
查看該索引的settings信息,可以看到_tier_preference被設(shè)置為了:data_frozen。
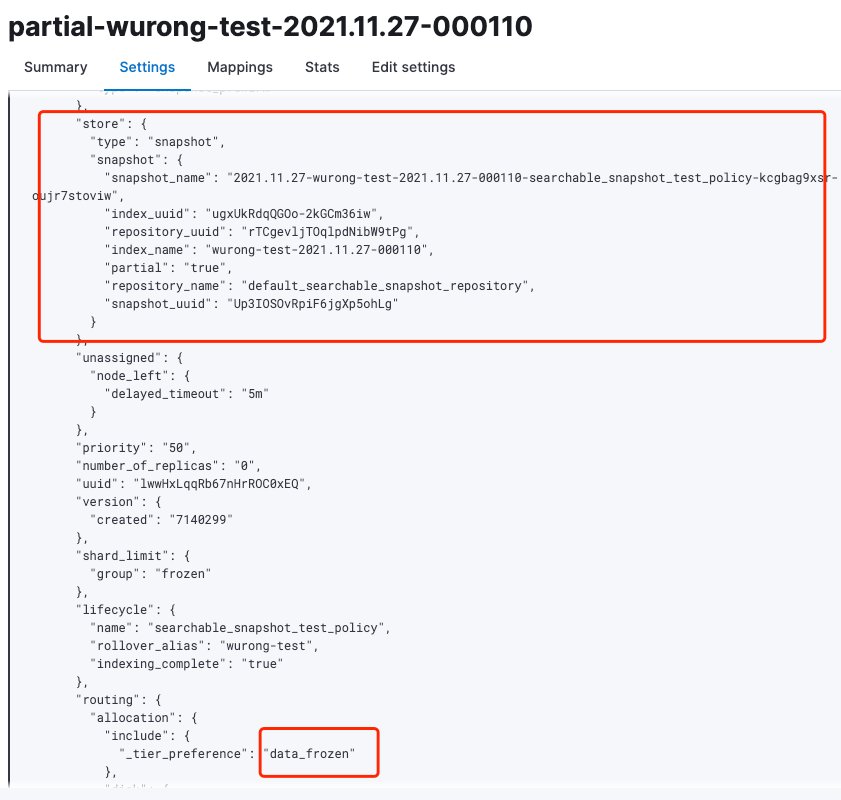
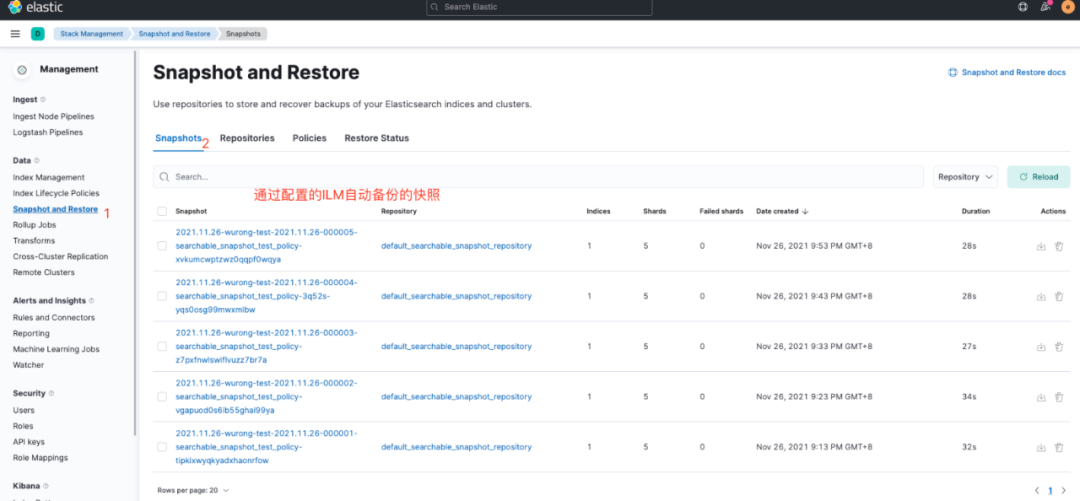
另外ILM自動(dòng)備份的快照信息也可以直接在Kibana上查看,路徑為:Management-Stack Management-Data-Snapshot and Restore,如圖12所示。
本文介紹了可搜索快照的技術(shù)原理,以及基于騰訊云COS對象存儲(chǔ)完整演示了可搜索快照的配置過程和可搜索快照的轉(zhuǎn)換流程。希望對大家有所幫助,也讓我們共同期待騰訊云ES的可搜索快照方案的發(fā)布。
(作者:吳容——騰訊云Elasticsearch高級開發(fā)工程師)

??戳「閱讀原文」一鍵了解騰訊云Elasticsearch Service更多信息~
