
Pandas可以直接讀取網(wǎng)頁html(表格)、json、csv等格式
回復(fù)“書籍”即可獲贈Python從入門到進階共10本電子書
大家好,我是Python進階者。
一、前言
前幾天在Python白銀交流群【Ming】問了一道Pandas處理html的問題,如下圖所示。
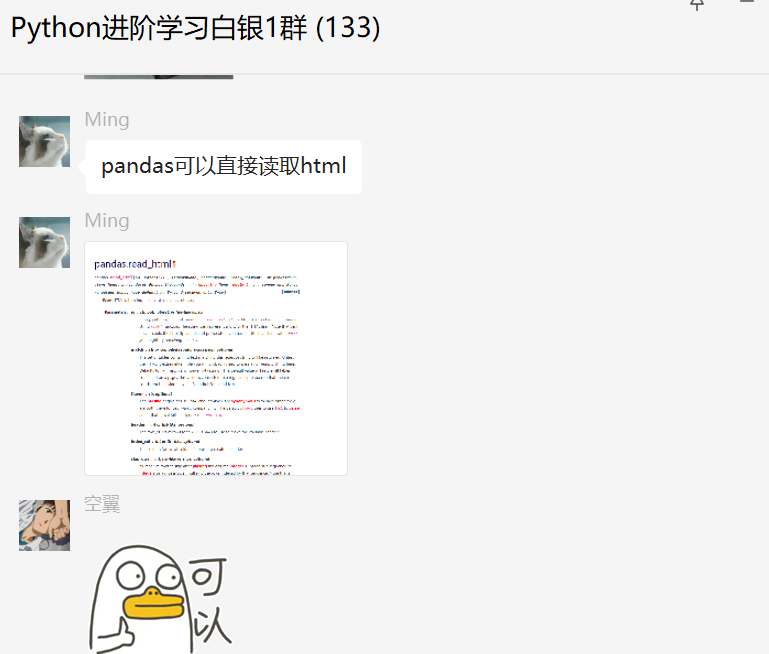
其實也不是問,算交流。
 確實,
確實,Pandas可以直接讀取html,而且在網(wǎng)頁讀取的時候更加方便。
二、實現(xiàn)過程
這里大家一起討論,學(xué)習(xí)了Pandas直接讀取html的方法。
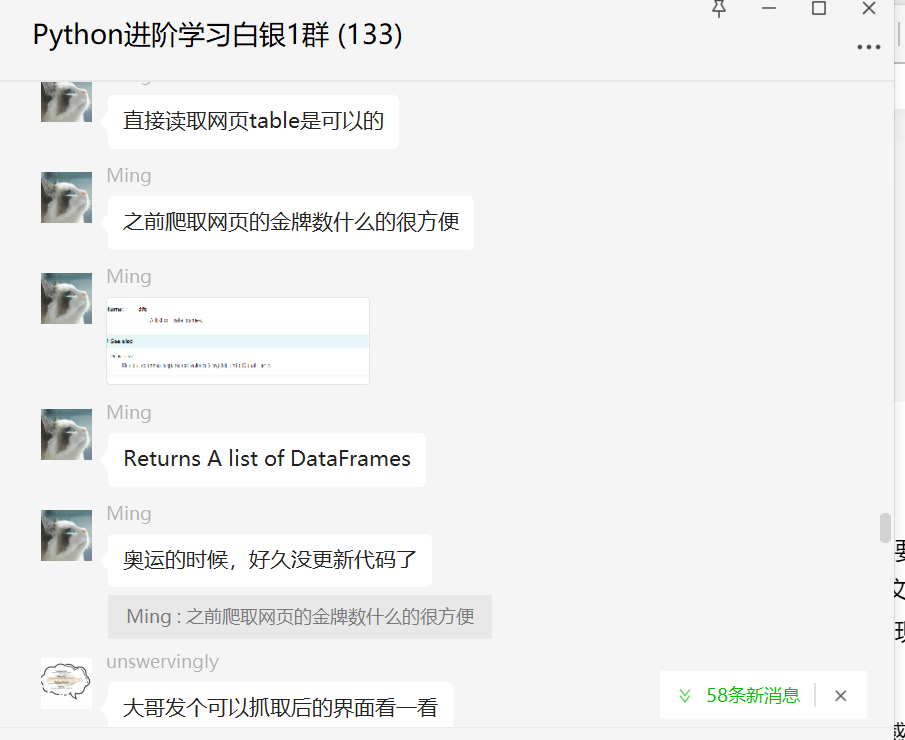
后來【null】給了一個示例代碼,及時雨。
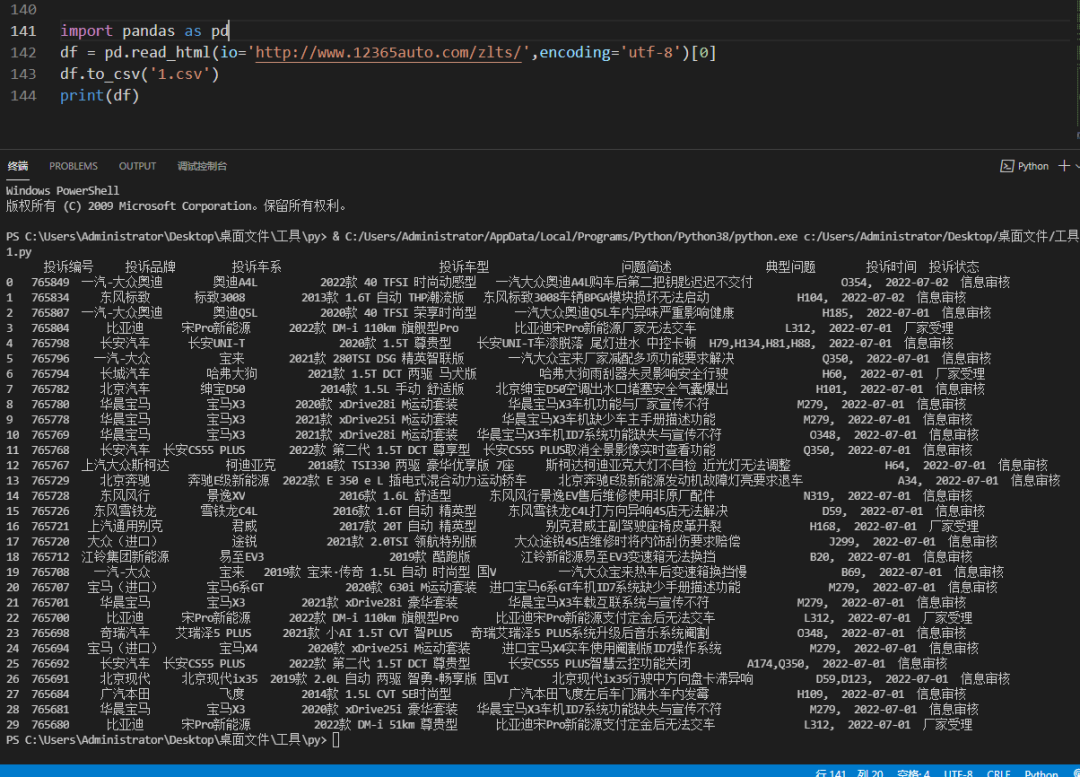 簡單的三句代碼就扒下來網(wǎng)頁數(shù)據(jù)了,并且存表格,針對表格形式的網(wǎng)頁,再也不用挨個
簡單的三句代碼就扒下來網(wǎng)頁數(shù)據(jù)了,并且存表格,針對表格形式的網(wǎng)頁,再也不用挨個tr、td標簽去取了,直接Pandas梭哈。

后來發(fā)現(xiàn)哥幾個竟然是湖北公安老鄉(xiāng),彼此聊得火熱。老鄉(xiāng)見老鄉(xiāng),一起學(xué)習(xí)更香!后來【null】多做了拓展,爬ajax加載的json格式,也可以用Pandas來實現(xiàn),這里也給出了示例。
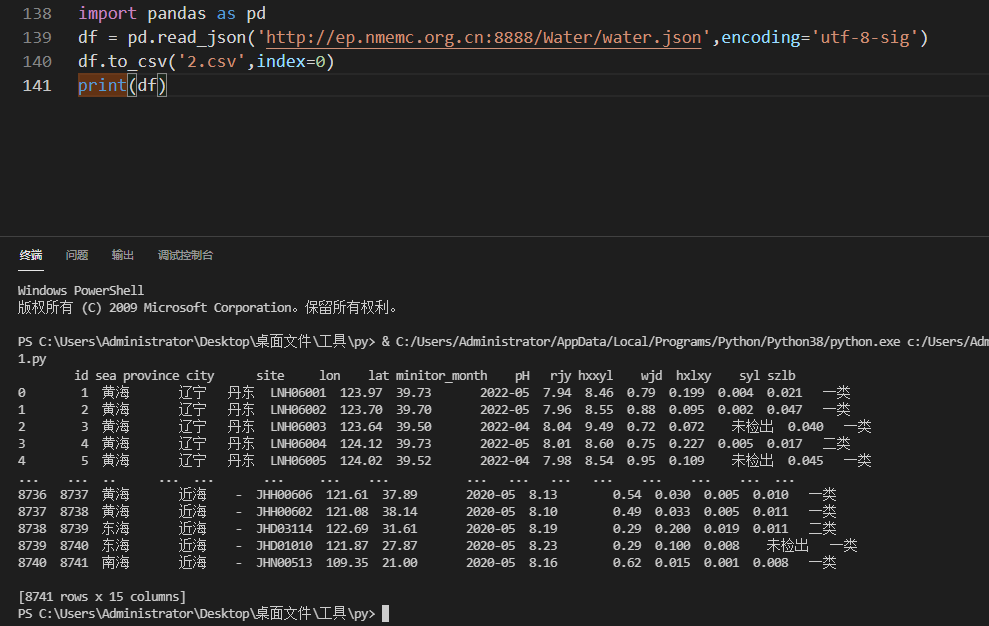 得到的結(jié)果如下圖所示:
得到的結(jié)果如下圖所示:
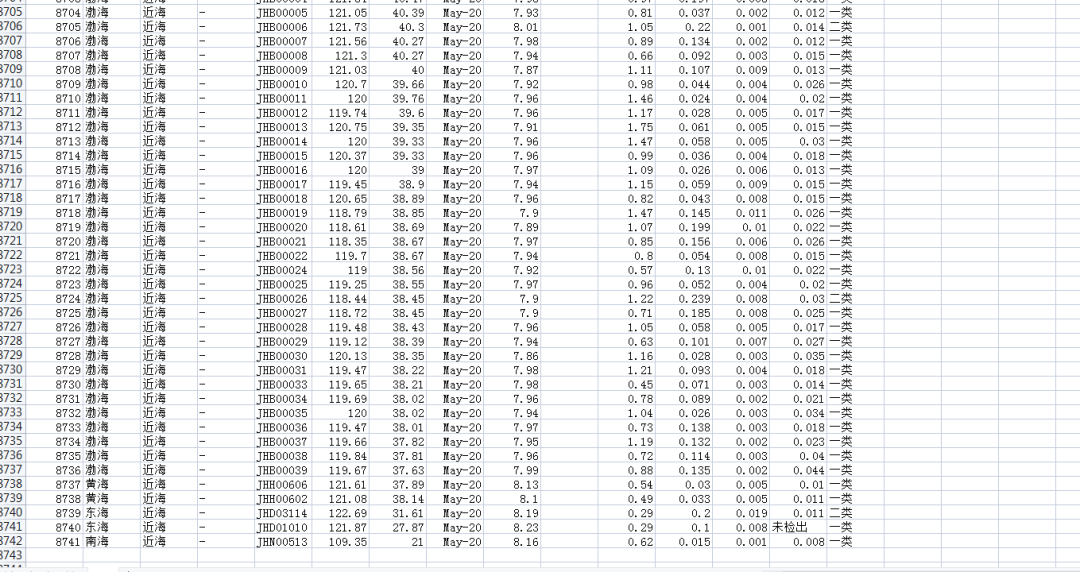
后來【月神】也給出了拓展,抓取csv格式也是可以的。
 不得不承認,
不得不承認,Pandas實在是太強大了!
三、總結(jié)
大家好,我是皮皮。這篇文章主要盤點了一道Pandas處理網(wǎng)絡(luò)爬蟲的問題,文中針對該問題給出了具體的解析和代碼實現(xiàn),幫助粉絲順利解決了問題。
最后感謝粉絲【Ming】提問,感謝【null】、【月神】給出的思路和代碼解析,感謝【空翼】、【dcpeng】、【此類生物】、【unswervingly】、【瑜亮老師】、【×_×】、【貓藥師Kelly】、【冫馬讠成】等人參與學(xué)習(xí)交流。
小伙伴們,快快用實踐一下吧!如果在學(xué)習(xí)過程中,有遇到任何問題,歡迎加我好友,我拉你進Python學(xué)習(xí)交流群共同探討學(xué)習(xí)。
------------------- End -------------------
往期精彩文章推薦:

歡迎大家點贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請在后臺回復(fù)【入群】
萬水千山總是情,點個【在看】行不行
/今日留言主題/
隨便說一兩句吧~~