
祖?zhèn)鞔a如何優(yōu)化性能?
今天又帶來一次性能優(yōu)化的分享,這是我剛進(jìn)公司時接手的祖?zhèn)鳎▔男Γ╉椖浚@個項目在我的文章中屢次被提及,我在它上面做了很多的性能優(yōu)化,本文更偏向宏觀上的性能優(yōu)化,可以說是個老演員了。

背景
為了新朋友能快速進(jìn)入場景,再描述一遍這個項目的背景,這個項目是一個自研的Dubbo注冊中心,上一張架構(gòu)圖
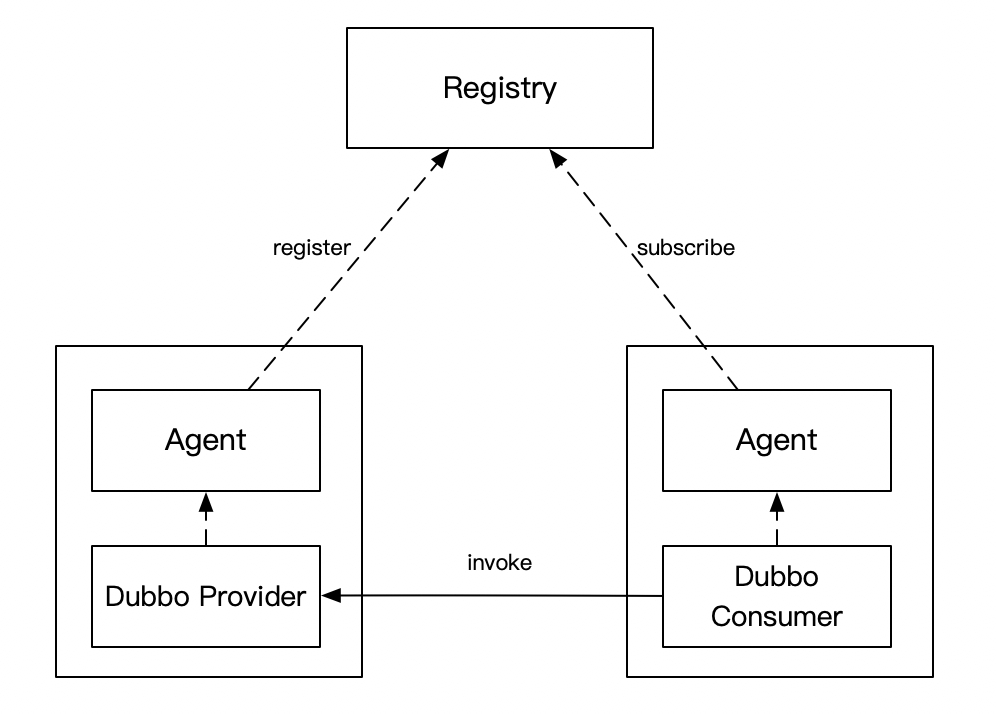
Consumer 和 Provider 的服務(wù)發(fā)現(xiàn)請求(注冊、注銷、訂閱)都發(fā)給 Agent,由它全權(quán)代理 Registry 和 Agent 保持 Grpc 長鏈接,長鏈接的目的主要是 Provider 方有變更時,能及時推送給相應(yīng)的 Consumer。為了保證數(shù)據(jù)的正確性,做了推拉結(jié)合的機(jī)制,Agent 會每隔一段時間去 Registry 拉取訂閱的服務(wù)列表 Agent 和業(yè)務(wù)服務(wù)部署在同一臺機(jī)器上,類似 Service Mesh 的思路,盡量減少對業(yè)務(wù)的入侵,這樣就能快速的迭代了
這里的Registry就是今天的主角,熟悉Dubbo的朋友可以把它當(dāng)做是一個zookeeper,不熟悉的朋友可以就把它當(dāng)做是一個Web應(yīng)用,提供了注冊、注銷、訂閱接口,雖然它是用Go寫的,但本文和Go本身關(guān)系不大,也會用一些偽代碼來示意,所以也可以放心大膽地看下去。
一定要做性能優(yōu)化嗎
在做性能優(yōu)化之前,我們得回答幾個問題,性能優(yōu)化帶來的收益是什么?為什么一定要做優(yōu)化性能?不優(yōu)化行不行?
性能優(yōu)化無非有兩個目的:
減少資源消耗,降低成本 提高系統(tǒng)穩(wěn)定性
如果只是為了降低成本,最好做之前估算一下大概能降低多少成本,如果吭哧吭哧干了大半個月,結(jié)果只省下了一丁點的資源,那是得不償失的。
回到這個注冊中心,為什么要做性能優(yōu)化呢?
Dubbo應(yīng)用啟動時,會向注冊中心發(fā)起注冊,如果注冊失敗,則會阻塞應(yīng)用的啟動。
起初這個項目問題并不大,因為接入的應(yīng)用并不多,而當(dāng)我接手項目時,接入的應(yīng)用越來越多。
話分兩頭,另一邊集團(tuán)也在逐漸使用容器替代虛擬機(jī)和物理機(jī),在高峰期會用擴(kuò)容的方式來抗住流量高峰,快速擴(kuò)容就要求服務(wù)能在短時間內(nèi)大量啟動,無疑對注冊中心是一個大的考驗。
而導(dǎo)致這次優(yōu)化的直接導(dǎo)火索是集團(tuán)內(nèi)的一次演練,他們發(fā)現(xiàn)一個配置中心的啟動依賴,性能達(dá)不到標(biāo)準(zhǔn)而導(dǎo)致擴(kuò)容失敗,于是復(fù)盤下來,所有的啟動依賴必須達(dá)到一定的性能要求,而這個標(biāo)準(zhǔn)被定為1000qps。
于是就有了本文。
指標(biāo)度量
如果不能度量,就沒法優(yōu)化。
首先是把幾個核心接口加上metric,主要是請求量、耗時(p99 / p95 / p90)、錯誤請求量,無論是哪個項目,這點算是基本的了,如果沒加,得好好反思了。
其次對項目進(jìn)行一次壓測,不知道現(xiàn)在的性能,后面的優(yōu)化也無法證明其效果了。
以注冊接口為例,當(dāng)時注冊的性能大概是40qps,記住這個值,看我們是如何一步一步達(dá)到1000qps的。
壓測成功的請求標(biāo)準(zhǔn)是:p99耗時在1秒以內(nèi),且無報錯。
瓶頸在哪里
性能優(yōu)化的最關(guān)鍵之處在于找到瓶頸在哪,否則就是無頭蒼蠅,到處瞎碰。
注冊接口到底干了什么呢?我這里畫個簡圖

整個流程加鎖,防止并發(fā)操作 Create App和Create Cluster是創(chuàng)建應(yīng)用和集群,只會在應(yīng)用第一次創(chuàng)建,如果創(chuàng)建過就直接跳過 Insert Endpoint是插入注冊數(shù)據(jù),即ip和port 系統(tǒng)的底層存儲是基于MySQL,Lock和UnLock也是基于MySQL實現(xiàn)的悲觀鎖
從這個流程圖就能看出來,瓶頸大概率在鎖上,這是個悲觀鎖,而且粒度是App,把整個流程鎖住,同一時刻相同應(yīng)用的請只允許一個通過,可想而知性能有多差。
至于MySQL如何實現(xiàn)一個悲觀鎖,我相信你會的,所以我就不展開。
為了證明猜想,我用了一個非常笨但很有效的方法,在每一個關(guān)鍵節(jié)點執(zhí)行之后,記錄下耗時,最后打印到日志里,這樣就能一眼看出到底哪里慢,果然最慢的就是加鎖。
鎖優(yōu)化
在優(yōu)化鎖之前,我們先搞清楚為什么要加鎖,在我反復(fù)測試,讀代碼,看文檔之后,發(fā)現(xiàn)事情其實很簡單,這個鎖是為了防止App、Cluster、Endpoint重復(fù)寫入。
為什么防止重復(fù)寫入要這么折騰呢?一個數(shù)據(jù)庫的唯一索引不就搞定了?這無法考證,但現(xiàn)狀就是這樣,如何破解呢?
首先是看這些表能否加唯一索引,有則盡量加上 其次數(shù)據(jù)庫悲觀鎖能否換成Redis的樂觀鎖?
這個其實是可以的,原因在于客戶端具有重試機(jī)制,如果并發(fā)沖突了,則發(fā)起重試,我們堵這個概率很小。
上面兩條優(yōu)化下來只解決了部分問題,還有的表實在無法添加唯一索引,比如這里App、Cluster由于一些特殊原因無法添加唯一索引,他們發(fā)生沖突的概率很高,同一個集群發(fā)布時,很可能是100臺機(jī)器同時拉起,只有一臺成功,剩余99臺在創(chuàng)建App或者Cluster時被鎖擋住了,發(fā)起重試,重試又可能沖突,大家都陷入了無限重試,最終超時,我們的服務(wù)也可能被重試流量打垮。
這該怎么辦?這時我想起了剛學(xué)Java時練習(xí)寫單例模式中,有個叫「雙重校驗鎖」的東西,我們看代碼
public class Singleton {
private static volatile Singleton instance = null;
private Singleton() {
}
private static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
再結(jié)合我們的場景,App和Cluster只在創(chuàng)建時需要保證唯一性,后續(xù)都是先查詢,如果存在就不需要再執(zhí)行插入,我們寫出偽代碼
app = DB.get("app_name")
if app == null {
redis.lock()
app = DB.get("app_name")
if app == null {
app = DB.instert("app_name")
}
redis.unlock()
}
是不是和雙重校驗鎖一模一樣?為什么這樣會性能更高呢?因為App和Cluster的特性是只在第一次時插入,真正需要鎖住的概率很小,就拿擴(kuò)容的場景來說,必然不會走到鎖的邏輯,只有應(yīng)用初次創(chuàng)建時才會真正被Lock。
性能優(yōu)化有一點是很重要的,就是我們要去優(yōu)化執(zhí)行頻率非常高的場景,這樣收益才高,如果執(zhí)行的頻率很低,那么我們是可以選擇性放棄的。
經(jīng)過這輪優(yōu)化,注冊的性能從40qps提升到了430qps,10倍的提升。
讀走緩存
經(jīng)過上一輪的優(yōu)化,我們還有個結(jié)論能得出來,一個應(yīng)用或集群的基本信息基本不會變化,于是我在想,是否可以讀取這些信息時直接走Redis緩存呢?
于是將信息基本不變的對象加上了緩存,再測試,發(fā)現(xiàn)qps從430提升到了440,提升不是很多,但蒼蠅再小,好歹是塊肉。
CPU優(yōu)化
上一輪的優(yōu)化效果不理想,但在壓測時注意到了一個問題,我發(fā)現(xiàn)Registry的CPU降低的很厲害,感覺瓶頸從鎖轉(zhuǎn)移到了CPU。說到CPU,這好辦啊,上火焰圖,Go自帶的pprof就能干。
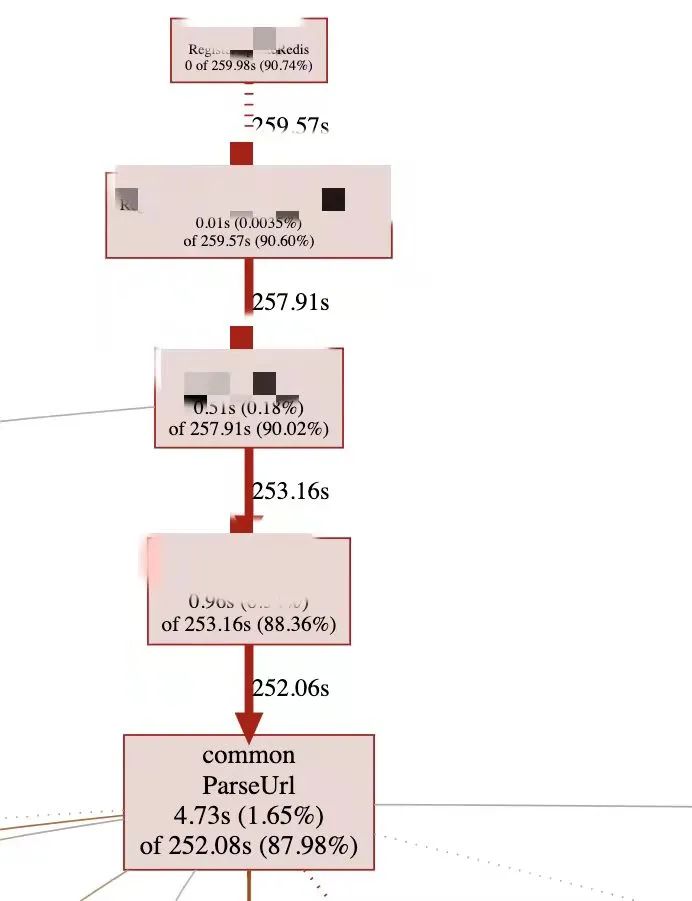
可以清楚地看到是ParseUrl占用了太多的CPU,這里簡單科普下,Dubbo傳參很多是靠URL傳參的,注冊中心拿到Dubbo的URL,需要去解析其中的參數(shù),比如ip、port等信息就存在于URL之中。
一開始拿到這個CPU profile的結(jié)果是有點難受的,因為ParseUrl是封裝的標(biāo)準(zhǔn)包里的URL解析方法,想要寫一個比它還高效的,基本可以勸退。
但還是順騰摸瓜,看看哪里調(diào)用了這個方法。不看不知道,一看嚇一跳,原來一個請求里的URL,會執(zhí)行過程中多次解析URL,為啥代碼會這么寫?可能是其中邏輯太復(fù)雜,一層一層的嵌套,但各個方法之間的傳參又不統(tǒng)一,所以帶來了這么糟糕的寫法,
這種情況怎么辦呢?
重構(gòu),把URL的解析統(tǒng)一放在一個地方,后續(xù)傳參就傳解析后的結(jié)果,不需要重復(fù)解析 對URL解析的方法,以每次請求的會話為粒度加一層緩存,保證只解析一次
我選擇了第二種方式,因為這樣對代碼的改動小,畢竟我剛接手這么龐大、混亂的代碼,最好能不動就不動,能少動就少動。
而且這種方式我很熟悉,在Dubbo的源碼中就有這樣的處理,Dubbo在反序列化時,如果是重復(fù)的對象,則直接走緩存而不是再去構(gòu)造一遍,代碼位于org.apache.dubbo.common.utils.PojoUtils#generalize
截取一點感受下
private static Object generalize(Object pojo, Map<Object, Object> history) {
...
Object o = history.get(pojo);
if (o != null) {
return o;
}
history.put(pojo, pojo);
...
}
根據(jù)這個思路,把ParseUrl改成帶cache的模式
func parseUrl(url, cache) {
if cache.get(url) != null {
return cache.get(url)
}
u = parseUrl0(url)
cache.put(url, u)
return u
}
因為是會話級別的緩存,所以每個會話會new一個cache,這樣能保證一個會話中對相同的url只解析一次。
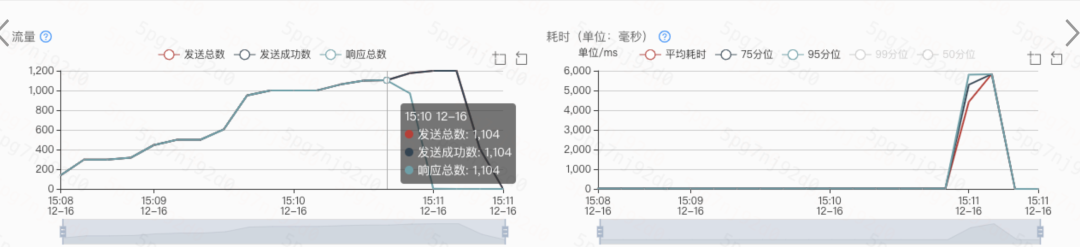
可以看下這次優(yōu)化的成果,qps直接到1100,達(dá)到目標(biāo)~
最后說兩句
可能有人看完就要噴了,這哪是性能優(yōu)化?這分明是填坑!對,你說的沒錯,只不過這坑是別人挖的。
本文就以一種最小的代價來搞定對祖?zhèn)鞔a的性能優(yōu)化,當(dāng)然并不是鼓勵大家都去取巧,這項目我也正在重構(gòu),只是每個階段都有不同的解法,比如老板要求你2周內(nèi)接手一個新項目,并完成性能優(yōu)化上線,重構(gòu)是不可能的。
希望通過本文你能學(xué)到一些性能優(yōu)化的基本知識,從為什么要做的拷問出發(fā),建立度量體系,找出瓶頸,一步一步進(jìn)行優(yōu)化,根據(jù)數(shù)據(jù)反饋及時調(diào)整優(yōu)化方向。