
python綜合程序設計 | 做一個可視化大屏
預覽


一、實驗目的
通過該實驗把Python語言中基本知識和第三方庫得到綜合應用。完成可視化熱搜榜和國內(nèi)疫情新增圖,提高學生的編程能力和分析問題、解決問題的能力。
二、設備與環(huán)境
硬件:多媒體計算機 軟件:Windows7或Windows10 操作系統(tǒng)、Python3.X 軟件。
三、實驗內(nèi)容
1、 實驗內(nèi)容 ① 使用python web框架flask搭建web項目 ② 使用爬蟲技術完成信息獲取 ③ 使用python基礎知識庫完成數(shù)據(jù)轉(zhuǎn)換并做數(shù)據(jù)分析 ④ 使用jieba庫對熱搜做詞頻分析 ⑤ 使用jQuery框架和HTML、css、JavaScript和echarts完成前端頁面設計
2、最后結(jié)果輸出。要求:輸出格式要界面直觀、清晰大方、格式規(guī)范。
四、實驗結(jié)果及分析
1、實驗運行過程及分析
#構(gòu)建首頁頁面路由路徑,并加載index.html頁面和傳送數(shù)據(jù)
@app.route('/Hot_Bot')
def Hot_Bot():
data=hotBot()
return render_template('index.html',form=data,title=data.title)
#構(gòu)建詞頻頁面和路由路徑,并加載test.html頁面和傳送數(shù)據(jù)
@app.route('/cipin')
def cipin():
data=spider.sum_hot_word()
print(data)
return render_template("test.html",form=data)
爬蟲階段以微博和知乎為例:
def weibo():
hot=[]
name=[]
value=[]
url='https://weibo.com/ajax/statuses/hot_band'
header={<!-- -->
'cookie': 'UOR=mp.weixin.qq.com,s.weibo.com,mp.weixin.qq.com; SINAGLOBAL=753710676249.8569.1621750150925; SUB=_2AkMXpEktf8NxqwJRmP4Tz2zkZYh3wwHEieKh-Lj2JRMxHRl-yT9jqhAztRB6PCRnwgM0JsVYPTwi5DuGI3N0YpgPChkI; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WhpfXwV9S99niOF07XLn8y7; WBPSESS=kErNolfXeoisUDB3d9TFH-1YhWD5pAkKF4olmR2WdEz_79spnMzQbf2Kt92964Tdvd3fcKY1c8a_Sd6CbCiw6P0wyFuEu1GQri6NrQ6_oBLuAYd8HR3zZI8_M6QfSsHD; ULV=1635245354703:3:1:1:6287771993091.978.1635245354698:1626916415441; XSRF-TOKEN=_LdujowesXEM4itQidVLNlJj',
'accept - encoding': 'gzip, deflate, br',
'user - agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36',
'referer': 'https://www.baidu.com/link?url=oBKJ9ZCKdgcrDL-WKTnXNgHhk2kNw6JfV0tShTgwv3KYkUracwd2FG6kuIrShm5b2aJDHZKZVgYG8QgZWSM-Ha&wd=&eqid=f74c877700049c31000000066177abe3'
}
req = requests.get(url,headers=header).text
soup = BeautifulSoup(req, "lxml")
#hot_word = re.findall('word.*?,',req)
hot_word=json.loads(req)['data']['band_list']
for i in range(len(hot_word)):
hot.append({<!-- -->"name":hot_word[i]['word'][0:10],"value":hot_word[i]["num"]})
name.append(hot_word[i]['word'])
value.append(hot_word[i]["num"])
return hot[0:3],name,value
def zhihu():
hot = []
browser=webdriver.Chrome('chromedriver.exe')
browser.get('https://www.zhihu.com/topsearch')
browser.refresh()
elements=browser.find_elements_by_class_name('TopSearchMain-title')
for i in elements:
hot.append(i.text)
return hot
以詞頻分析為例展示部分前端頁面代碼:
<div id="main" style="width: 600px;height: 800px;"></div>
<script>
var ectest = echarts.init(document.getElementById("main"));
var ec_right2_option = {<!-- -->
// backgroundColor: '#515151',
title: {<!-- -->
text: "今日疫情熱搜",
textStyle: {<!-- -->
color: 'white',
},
left: 'left'
},
tooltip: {<!-- -->
show: false
},
series: [{<!-- -->
type: 'wordCloud',
// drawOutOfBound:true,
gridSize: 1,
sizeRange: [12, 55],
rotationRange: [-45, 0, 45, 90],
// maskImage: maskImage,
textStyle: {<!-- -->
normal: {<!-- -->
color: function () {<!-- -->
return 'rgb(' +
Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) +
', ' + Math.round(Math.random() * 255) + ')'
}
}
},
right: null,
bottom: null,
data: ddd
}]
}
ectest.setOption(ec_right2_option);
</script>
2、運行結(jié)果
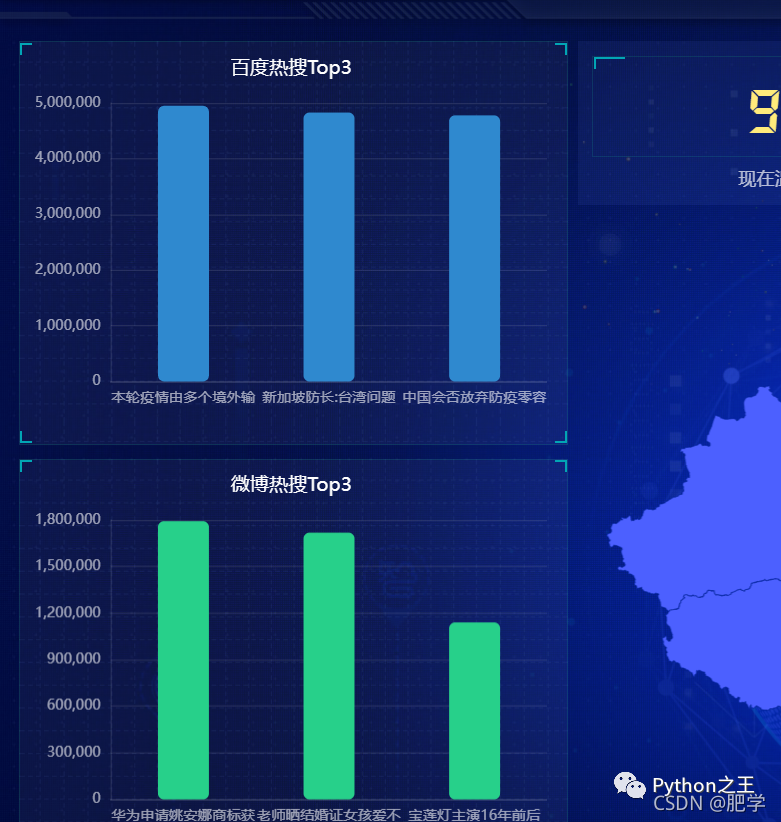
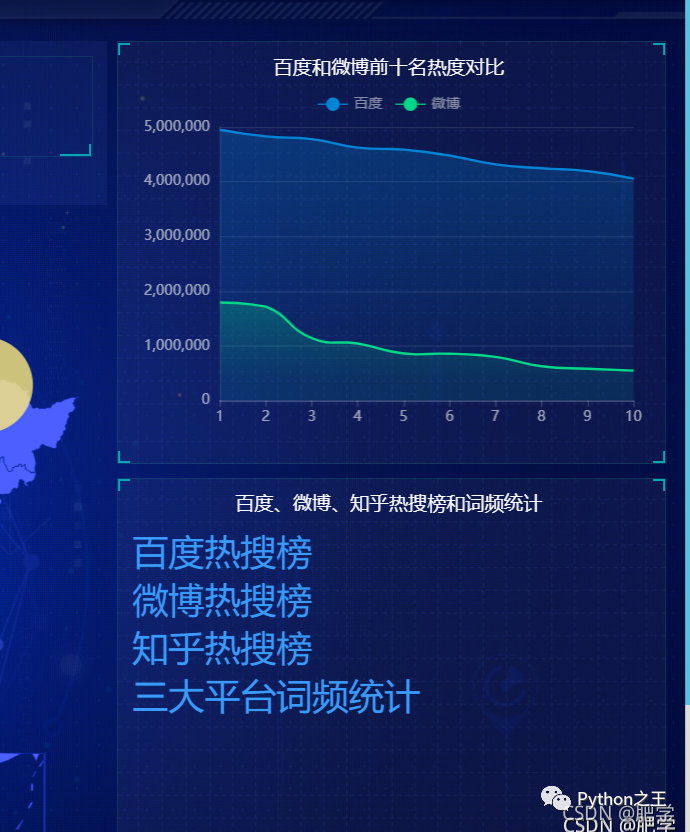
下面展示主頁面:中間是國內(nèi)疫情新增圖并動態(tài)顯示人數(shù),左上為百度熱搜榜top3、左下為微博熱搜榜top3、中上為當天天氣情況、右上為微博和百度熱搜熱度對比。右下為三大平臺的熱搜地址和詞頻統(tǒng)計。
下圖為百度、微博、知乎三大平臺的熱搜詞頻統(tǒng)計圖。
3、心得體會
通過本次課程設計我又溫習了一次python的一些基礎知識而且對前端技術有了進一步的了解使我更加清晰了以后的方向。而且也認識到在構(gòu)建項目的時候?qū)φw架構(gòu)的重要性,最重要的是更深的認識到python技術對于構(gòu)建網(wǎng)站的優(yōu)缺點和python語言的實用性。對以后的發(fā)展起到了良好的引導作用。同時也認識到了自己的薄弱項,比如在前端頁面設計的時候?qū)Query和JavaScript技術的應用很不熟練還有對echarts的圖表選擇也比較簡單,在選取疫情城市坐標標記的時候?qū)ymbolSize 的設定也沒有把控好直接導致了最終產(chǎn)品沒有達到預期效果,而且對python的基礎知識掌握也不是特別的牢固對于jieba庫的使用還有待提高。后續(xù)我會補上薄弱項,為爭取做一名全棧技術人員而奮斗。
源碼領取
公眾號回復可視化疫情