
偷偷告訴你 7個提升PyTorch性能的技巧
在過去的10個月里,在PyTorch Lightning工作期間,團隊和我已經(jīng)接觸過許多結構PyTorch代碼的風格,我們已經(jīng)發(fā)現(xiàn)了一些人們無意中引入瓶頸的關鍵地方。
我們非常小心地確保PyTorch Lightning不會對我們?yōu)槟阕詣泳帉懙拇a犯任何這些錯誤,我們甚至會在檢測到這些錯誤時為用戶糾正這些錯誤。然而,由于Lightning只是結構化的PyTorch,而你仍然控制所有的PyTorch,因此在許多情況下,我們不能為用戶做太多事情。此外,如果不使用Lightning,可能會在無意中將這些問題引入代碼。為了幫助你訓練得更快,這里有7個技巧,你應該知道它們可能會減慢你的代碼。
在DataLoaders中使用workers

第一個錯誤很容易糾正。PyTorch允許同時在多個進程上加載數(shù)據(jù)。
在這種情況下,PyTorch可以通過處理8個批次繞過GIL鎖,每個批次在一個單獨的進程上。你應該使用多少workers?一個好的經(jīng)驗法則是:
num_worker = 4 * num_GPU
https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813/7這里對此有一個很好的討論。
警告:缺點是你的內(nèi)存使用也會增加
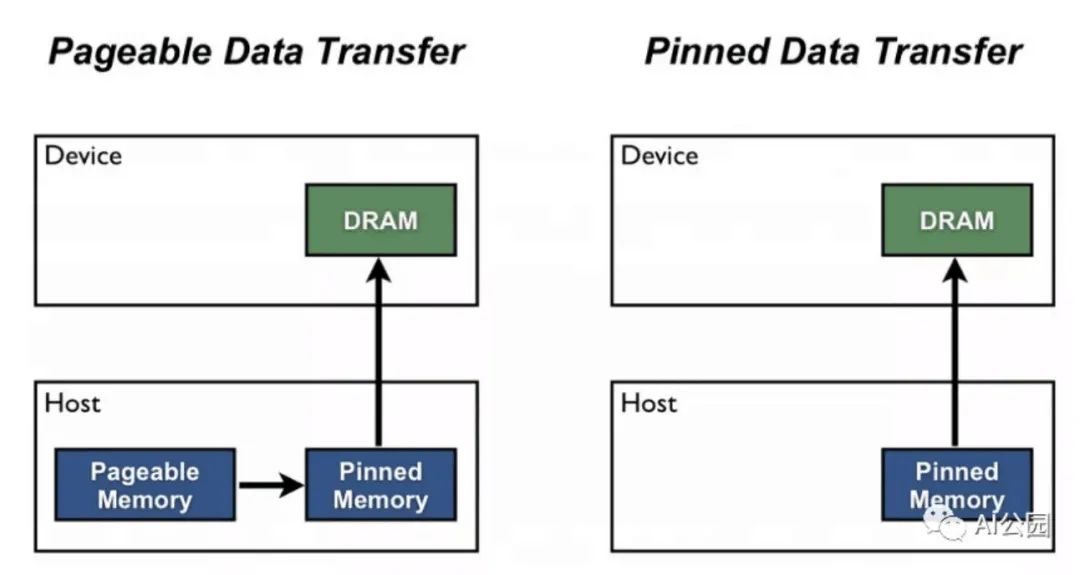
Pin memory

你知道有時候你的GPU內(nèi)存顯示它是滿的但你很確定你的模型沒有使用那么多?這種開銷稱為_pinned memory_。這個內(nèi)存被保留為一種“working allocation”類型。
當你在一個DataLoader中啟用pinned_memory時,它“自動將獲取的數(shù)據(jù)張量放在pinned memory中,并使數(shù)據(jù)更快地傳輸?shù)紺UDA-enabled的gpu”
這意味著你不應該不必要的去調(diào)用:
torch.cuda.empty_cache()
避免CPU到GPU的傳輸,反之亦然
# bad.cpu().item().numpy()
我看到大量使用.item()或.cpu()或.numpy()調(diào)用。這對于性能來說是非常糟糕的,因為每個調(diào)用都將數(shù)據(jù)從GPU傳輸?shù)紺PU,從而極大地降低了性能。
如果你試圖清除附加的計算圖,請使用.detach()。
# good.detach()
這不會將內(nèi)存轉(zhuǎn)移到GPU,它會刪除任何附加到該變量的計算圖。
直接在GPUs上構建張量
大多數(shù)人都是這樣在GPUs上創(chuàng)建張量的
t = tensor.rand(2,2).cuda()
然而,這首先創(chuàng)建CPU張量,然后將其轉(zhuǎn)移到GPU……這真的很慢。相反,直接在想要的設備上創(chuàng)建張量。
t = tensor.rand(2,2, device=torch.device('cuda:0'))
如果你正在使用Lightning,我們會自動把你的模型和批處理放到正確的GPU上。但是,如果你在代碼的某個地方創(chuàng)建了一個新的張量(例如:為一個VAE采樣隨機噪聲,或類似的東西),那么你必須自己放置張量。
t = tensor.rand(2,2, device=self.device)
每個LightningModule都有一個方便的self.device調(diào)用,無論你是在CPU上,多 GPUs上,還是在TPUs上,lightning會為那個張量選擇正確的設備。
使用DistributedDataParallel不要使用DataParallel
PyTorch有兩個主要的模式用于在多 GPUs訓練。第一種是DataParallel,它將一批數(shù)據(jù)分割到多個GPUs上。但這也意味著模型必須復制到每個GPU上,一旦在GPU 0上計算出梯度,它們必須同步到其他GPU。
這需要大量昂貴的GPU傳輸!相反,DistributedDataParallel在每個GPU(在它自己的進程中)上創(chuàng)建模型副本,并且只讓數(shù)據(jù)的一部分對該GPU可用。這就像是讓N個獨立的模型進行訓練,除了一旦每個模型都計算出梯度,它們就會在模型之間同步梯度……這意味著我們在每批處理中只在GPUs之間傳輸一次數(shù)據(jù)。
在Lightning中,你可以在兩者之間輕松切換
Trainer(distributed_backend='ddp', gpus=8)Trainer(distributed_backend='dp', gpus=8)請注意,PyTorch和Lightning都不鼓勵使用DP。
使用16-bit精度
這是另一種加快訓練速度的方法,我們沒有看到很多人使用這種方法。在你的模型進行16bit訓練的部分,數(shù)據(jù)從32位變到到16位。這有幾個優(yōu)點:
你使用了一半的內(nèi)存(這意味著你可以將batch大小翻倍,并將訓練時間減半)。 某些GPU(V100, 2080Ti)可以自動加速(3 -8倍),因為它們針對16位計算進行了優(yōu)化。
在Lightning中,這很簡單:
Trainer(precision=16)
注意:在PyTorch 1.6之前,你還必須安裝Nvidia Apex,現(xiàn)在16位是PyTorch的原生版本。但如果你使用的是Lightning,它同時支持這兩種功能,并根據(jù)檢測到的PyTorch版本自動切換。
對你的代碼進行Profile
如果沒有Lightning,最后一條建議可能很難實現(xiàn),但你可以使用cprofiler這樣的工具來實現(xiàn)。然而,在Lightning中,你可以通過兩種方式獲得所有在訓練期間所做的調(diào)用的總結:
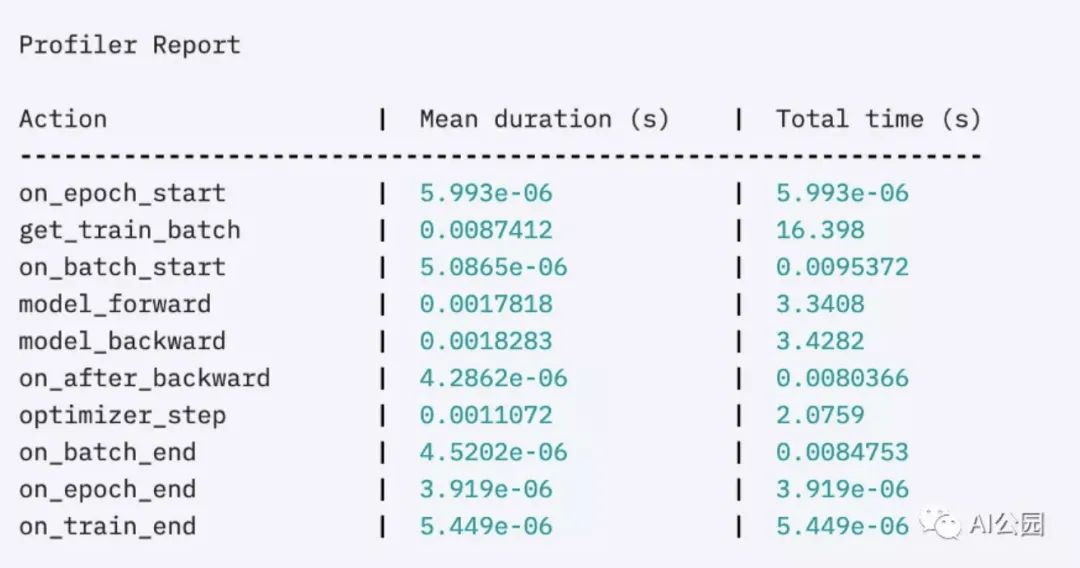
首先,內(nèi)置的basic profiler
Trainer(profile=True)
可以給出這樣的輸出:
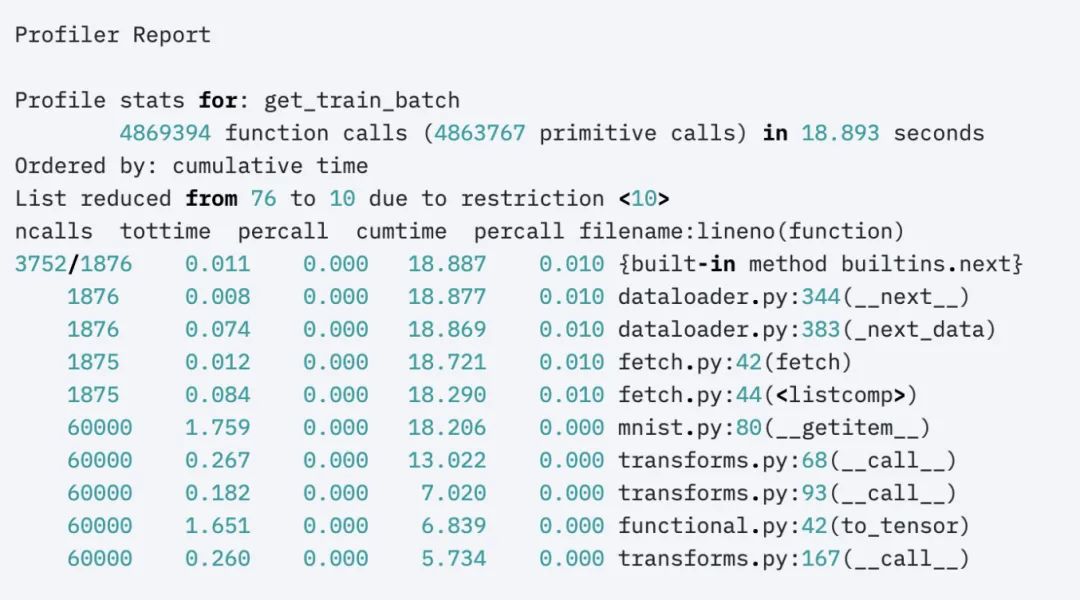
或者是高級的profiler:
profiler = AdvancedProfiler()trainer = Trainer(profiler=profiler)
得到更小粒度的結果:
英文原文:https://towardsdatascience.com/7-tips-for-squeezing-maximum-performance-from-pytorch-ca4a40951259
雙一流高校研究生團隊創(chuàng)建 ↓
專注于目標檢測原創(chuàng)并分享相關知識 ?
整理不易,點贊三連!