
數(shù)據(jù)庫連接池的優(yōu)化,到底怎么做呢?

我在研究HikariCP(一個數(shù)據(jù)庫連接池)時無意間在HikariCP的Github wiki上看到了一篇文章(即前面給出的鏈接),這篇文章有力地消除了我一直以來的疑慮,看完之后感覺神清氣爽。故在此做譯文分享。
接下來是正文
數(shù)據(jù)庫連接池的配置是開發(fā)者們常常搞出坑的地方,在配置數(shù)據(jù)庫連接池時,有幾個可以說是和直覺背道而馳的原則需要明確。
1萬并發(fā)用戶訪問
想象你有一個網(wǎng)站,壓力雖然還沒到Facebook那個級別,但也有個1萬上下的并發(fā)訪問——也就是說差不多2萬左右的TPS。那么這個網(wǎng)站的數(shù)據(jù)庫連接池應(yīng)該設(shè)置成多大呢?結(jié)果可能會讓你驚訝,因為這個問題的正確問法是:
“這個網(wǎng)站的數(shù)據(jù)庫連接池應(yīng)該設(shè)置成多小呢?”
下面這個視頻是Oracle Real World Performance Group發(fā)布的,請先看完:
http://www.dailymotion.com/video/x2s8uec
(因為這視頻是英文解說且沒有字幕,我替大家做一下簡單的概括:)
視頻中對Oracle數(shù)據(jù)庫進(jìn)行壓力測試,9600并發(fā)線程進(jìn)行數(shù)據(jù)庫操作,每兩次訪問數(shù)據(jù)庫的操作之間sleep 550ms,一開始設(shè)置的中間件線程池大小為2048:
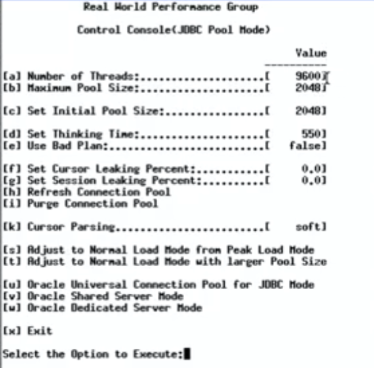
初始的配置
壓測跑起來之后是這個樣子的:

2048連接時的性能數(shù)據(jù)
每個請求要在連接池隊列里等待33ms,獲得連接后執(zhí)行SQL需要77ms
此時數(shù)據(jù)庫的等待事件是這個熊樣的:

各種buffer busy waits
各種buffer busy waits,數(shù)據(jù)庫CPU在95%左右(這張圖里沒截到CPU)
接下來,把中間件連接池減到1024(并發(fā)什么的都不變),性能數(shù)據(jù)變成了這樣:

連接池降到1024后
獲取鏈接等待時長沒怎么變,但是執(zhí)行SQL的耗時減少了。
下面這張圖,上半部分是wait,下半部分是吞吐量
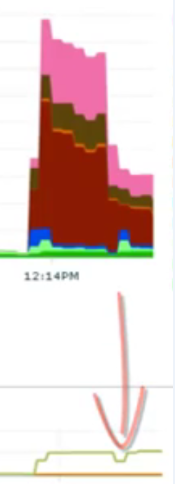
wait和吞吐量
能看到,中間件連接池從2048減半之后,吐吞量沒變,但wait事件減少了一半。
接下來,把數(shù)據(jù)庫連接池減到96,并發(fā)線程數(shù)仍然是9600不變。

96個連接時的性能數(shù)據(jù)
隊列平均等待1ms,執(zhí)行SQL平均耗時2ms。
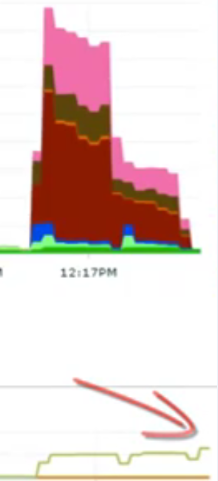
wait事件幾乎沒了,吞吐量上升。
沒有調(diào)整任何其他東西,僅僅只是縮小了中間件層的數(shù)據(jù)庫連接池,就把請求響應(yīng)時間從100ms左右縮短到了3ms。
But why?
為什么nginx只用4個線程發(fā)揮出的性能就大大超越了100個進(jìn)程的Apache HTTPD?回想一下計算機(jī)科學(xué)的基礎(chǔ)知識,答案其實是很明顯的。
即使是單核CPU的計算機(jī)也能“同時”運行數(shù)百個線程。但我們都[應(yīng)該]知道這只不過是操作系統(tǒng)用時間分片玩的一個小把戲。一顆CPU核心同一時刻只能執(zhí)行一個線程,然后操作系統(tǒng)切換上下文,核心開始執(zhí)行另一個線程的代碼,以此類推。給定一顆CPU核心,其順序執(zhí)行A和B永遠(yuǎn)比通過時間分片“同時”執(zhí)行A和B要快,這是一條計算機(jī)科學(xué)的基本法則。一旦線程的數(shù)量超過了CPU核心的數(shù)量,再增加線程數(shù)系統(tǒng)就只會更慢,而不是更快。
這幾乎就是真理了……
有限的資源
上面的說法只能說是接近真理,但還并沒有這么簡單,有一些其他的因素需要加入。當(dāng)我們尋找數(shù)據(jù)庫的性能瓶頸時,總是可以將其歸為三類:CPU、磁盤、網(wǎng)絡(luò)。把內(nèi)存加進(jìn)來也沒有錯,但比起磁盤和網(wǎng)絡(luò),內(nèi)存的帶寬要高出好幾個數(shù)量級,所以就先不加了。
如果我們無視磁盤和網(wǎng)絡(luò),那么結(jié)論就非常簡單。在一個8核的服務(wù)器上,設(shè)定連接/線程數(shù)為8能夠提供最優(yōu)的性能,再增加連接數(shù)就會因上下文切換的損耗導(dǎo)致性能下降。
數(shù)據(jù)庫通常把數(shù)據(jù)存儲在磁盤上,磁盤又通常是由一些旋轉(zhuǎn)著的金屬碟片和一個裝在步進(jìn)馬達(dá)上的讀寫頭組成的。讀/寫頭同一時刻只能出現(xiàn)在一個地方,然后它必須“尋址”到另外一個位置來執(zhí)行另一次讀寫操作。所以就有了尋址的耗時,此外還有旋回耗時,讀寫頭需要等待碟片上的目標(biāo)數(shù)據(jù)“旋轉(zhuǎn)到位”才能進(jìn)行操作。使用緩存當(dāng)然是能夠提升性能的,但上述原理仍然成立。
在這一時間段(即"I/O等待")內(nèi),線程是在“阻塞”著等待磁盤,此時操作系統(tǒng)可以將那個空閑的CPU核心用于服務(wù)其他線程。所以,由于線程總是在I/O上阻塞,我們可以讓線程/連接數(shù)比CPU核心多一些,這樣能夠在同樣的時間內(nèi)完成更多的工作。
那么應(yīng)該多多少呢?這要取決于磁盤。較新型的SSD不需要尋址,也沒有旋轉(zhuǎn)的碟片。可別想當(dāng)然地認(rèn)為“SSD速度更快,所以我們應(yīng)該增加線程數(shù)”,恰恰相反,無需尋址和沒有旋回耗時意味著更少的阻塞,所以更少的線程[更接近于CPU核心數(shù)]會發(fā)揮出更高的性能。只有當(dāng)阻塞創(chuàng)造了更多的執(zhí)行機(jī)會時,更多的線程數(shù)才能發(fā)揮出更好的性能。
網(wǎng)絡(luò)和磁盤類似。通過以太網(wǎng)接口讀寫數(shù)據(jù)時也會形成阻塞,10G帶寬會比1G帶寬的阻塞少一些,1G帶寬又會比100M帶寬的阻塞少一些。不過網(wǎng)絡(luò)通常是放在第三位考慮的,有些人會在性能計算中忽略它們。
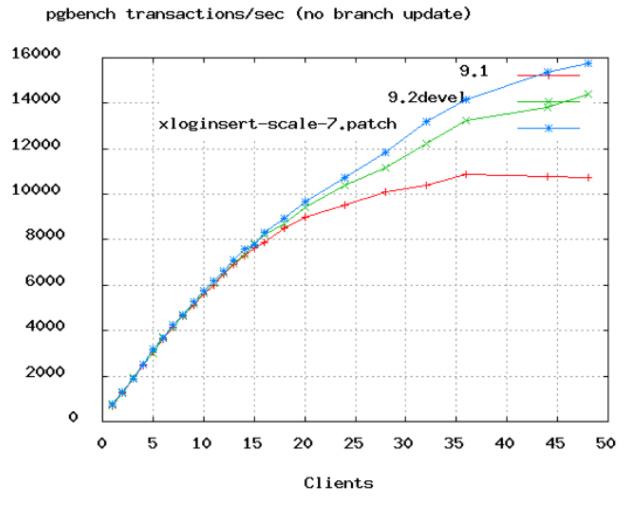
上圖是PostgreSQL的benchmark數(shù)據(jù),可以看到TPS增長率從50個連接數(shù)開始變緩。在上面Oracle的視頻中,他們把連接數(shù)從2048降到了96,實際上96都太高了,除非服務(wù)器有16或32顆核心。
計算公式
下面的公式是由PostgreSQL提供的,不過我們認(rèn)為可以廣泛地應(yīng)用于大多數(shù)數(shù)據(jù)庫產(chǎn)品。你應(yīng)該模擬預(yù)期的訪問量,并從這一公式開始測試你的應(yīng)用,尋找最合適的連接數(shù)值。
連接數(shù) = ((核心數(shù) * 2) + 有效磁盤數(shù))
核心數(shù)不應(yīng)包含超線程(hyper thread),即使打開了hyperthreading也是。如果活躍數(shù)據(jù)全部被緩存了,那么有效磁盤數(shù)是0,隨著緩存命中率的下降,有效磁盤數(shù)逐漸趨近于實際的磁盤數(shù)。這一公式作用于SSD時的效果如何尚未有分析。
按這個公式,你的4核i7數(shù)據(jù)庫服務(wù)器的連接池大小應(yīng)該為((4 * 2) + 1) = 9。取個整就算是是10吧。是不是覺得太小了?跑個性能測試試一下,我們保證它能輕松搞定3000用戶以6000TPS的速率并發(fā)執(zhí)行簡單查詢的場景。如果連接池大小超過10,你會看到響應(yīng)時長開始增加,TPS開始下降。
筆者注:
這一公式其實不僅適用于數(shù)據(jù)庫連接池的計算,大部分涉及計算和I/O的程序,線程數(shù)的設(shè)置都可以參考這一公式。我之前在對一個使用Netty編寫的消息收發(fā)服務(wù)進(jìn)行壓力測試時,最終測出的最佳線程數(shù)就剛好是CPU核心數(shù)的一倍。
公理:你需要一個小連接池,和一個充滿了等待連接的線程的隊列
如果你有10000個并發(fā)用戶,設(shè)置一個10000的連接池基本等于失了智。1000仍然很恐怖。即是100也太多了。你需要一個10來個連接的小連接池,然后讓剩下的業(yè)務(wù)線程都在隊列里等待。連接池中的連接數(shù)量應(yīng)該等于你的數(shù)據(jù)庫能夠有效同時進(jìn)行的查詢?nèi)蝿?wù)數(shù)(通常不會高于2*CPU核心數(shù))。
我們經(jīng)常見到一些小規(guī)模的web應(yīng)用,應(yīng)付著大約十來個的并發(fā)用戶,卻使用著一個100連接數(shù)的連接池。這會對你的數(shù)據(jù)庫造成極其不必要的負(fù)擔(dān)。
請注意
連接池的大小最終與系統(tǒng)特性相關(guān)。
比如一個混合了長事務(wù)和短事務(wù)的系統(tǒng),通常是任何連接池都難以進(jìn)行調(diào)優(yōu)的。最好的辦法是創(chuàng)建兩個連接池,一個服務(wù)于長事務(wù),一個服務(wù)于短事務(wù)。
再例如一個系統(tǒng)執(zhí)行一個任務(wù)隊列,只允許一定數(shù)量的任務(wù)同時執(zhí)行,此時并發(fā)任務(wù)數(shù)應(yīng)該去適應(yīng)連接池連接數(shù),而不是反過來。
作者:kelgon
來源:www.jianshu.com/p/a8f653fc0c54
——————END——————
歡迎關(guān)注“Java引導(dǎo)者”,我們分享最有價值的Java的干貨文章,助力您成為有思想的Java開發(fā)工程師!