
深入理解數(shù)據(jù)庫核心技術(shù)
“ 數(shù)據(jù)庫作為IT系統(tǒng)核心基石,為互聯(lián)網(wǎng)科技的進(jìn)步起著不可磨滅的功勞。”
來自:技術(shù)茶館
概述
數(shù)據(jù)庫是“按照數(shù)據(jù)結(jié)構(gòu)來組織、存儲和管理數(shù)據(jù)的倉庫”。是一個長期存儲在計算機內(nèi)的、有組織的、可共享的、統(tǒng)一管理的大量數(shù)據(jù)的集合。
數(shù)據(jù)庫系統(tǒng)把每一個應(yīng)用只定義并且維護(hù)自己的數(shù)據(jù)的這樣一種形式(圖1)改變?yōu)閷τ跀?shù)據(jù)的集中定義和集中管理(圖2)。這種新的變化帶來了數(shù)據(jù)獨立性(data independence), 使得應(yīng)用程序不再受到數(shù)據(jù)在邏輯組織或物理組織上帶來的變化影響,反之亦然。

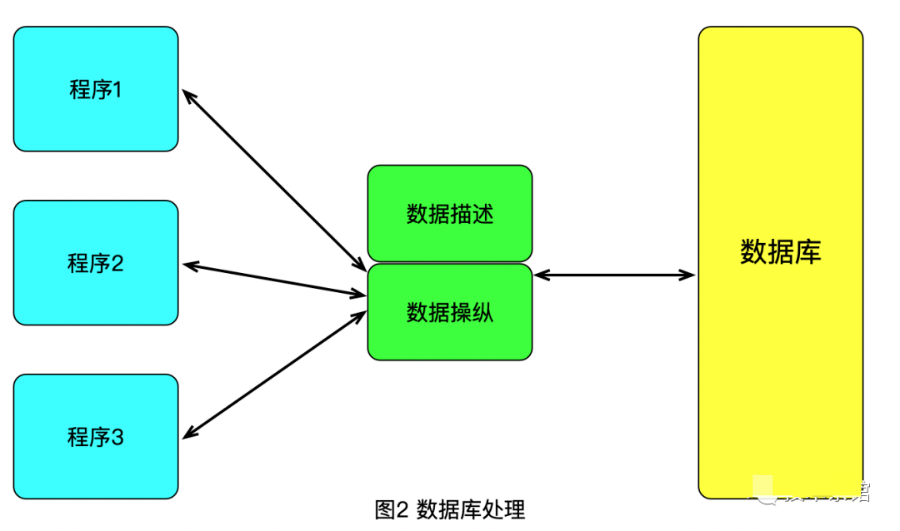
使用數(shù)據(jù)庫系統(tǒng)的動機之一就是集成企業(yè)的運營數(shù)據(jù),提供集中的、對于數(shù)據(jù)可控制的存取。
數(shù)據(jù)庫的演進(jìn)之路
數(shù)據(jù)庫已經(jīng)發(fā)展了40年,可以說是一個傳統(tǒng)又古老的領(lǐng)域。回顧數(shù)據(jù)庫的發(fā)展歷史,1980年到1990年屬于商業(yè)起步階段,此時Oracle、IBM DB2、Sybase以及SQL Server和Informix等開始出現(xiàn)。
1990年至2000年,開源數(shù)據(jù)庫開始展露頭角,出現(xiàn)了PostgreSQL和MySQL等。與此同時,出現(xiàn)了一些分析型數(shù)據(jù)庫,因為之前出現(xiàn)的都是OLTP,而現(xiàn)在隨著大量數(shù)據(jù)的出現(xiàn),需要對于這些數(shù)據(jù)進(jìn)行分析,因此出現(xiàn)了OLAP,而為了避免讀寫沖突,就需要建立分析型數(shù)據(jù)庫系統(tǒng),Teradata、Sybase IQ、Greenplum等就快速成長起來。

2000年到2010年期間,以谷歌為代表的互聯(lián)網(wǎng)公司逐漸推出了NoSQL數(shù)據(jù)庫。尤其是谷歌的GFS(Google File System)、Google Bigtable、Google MapReduce三大件。Google File System解決了分布式文件系統(tǒng)問題,Google Bigtable解決了分布式KV(Key-Value)存儲的問題,Google MapReduce解決了在分布式文件系統(tǒng)和分布式KV存儲上面如何做分布式計算和分析的問題。之所以產(chǎn)生了這三大件,是因為數(shù)據(jù)強一致性對系統(tǒng)的水平拓展以及海量數(shù)據(jù)爆發(fā)式增長的分析能力出現(xiàn)了斷層。因此就需要解決這個問題,把這種數(shù)據(jù)的強一致性需求弱化,換來能夠使用用分布式的集群做水平拓展處理。谷歌三大件在業(yè)界誕生以后,很快的衍生了一個新的領(lǐng)域叫NoSQL(Not Only SQL),就是針對非結(jié)構(gòu)化、半結(jié)構(gòu)化的海量數(shù)據(jù)處理系統(tǒng)。現(xiàn)在也有很多很好的商業(yè)公司基于NoSQL發(fā)展,比如說文檔數(shù)據(jù)(MongoDB)、緩存(Redis)等大家平常應(yīng)用開發(fā)都會用到的NoSQL系統(tǒng)。
而在2010年以后,AWS Aurora、Redshift、Azure SQL Database、Google Spanner發(fā)展起來了,它們的特點就是云原生、一體化分布式、HTAP的能力。
總結(jié)而言,數(shù)據(jù)庫的演進(jìn)經(jīng)歷了從結(jié)構(gòu)化數(shù)據(jù)在線處理到海量數(shù)據(jù)分析,從SQL+OLAP的RDBMS到ETL+OLAP的Data Warehouse和Data Lake,再到今天異構(gòu)多源的數(shù)據(jù)類型的發(fā)展歷程。
數(shù)據(jù)庫的發(fā)展-業(yè)務(wù)視角
大家知道,數(shù)據(jù)庫可以分為幾類:
最經(jīng)典的是傳統(tǒng)關(guān)系型OLTP數(shù)據(jù)庫,其主要用于事務(wù)處理的結(jié)構(gòu)化數(shù)據(jù)庫,典型例子是銀行的轉(zhuǎn)賬記賬、電商下單、訂單以及商品庫存管理等。其面臨的核心挑戰(zhàn)是高并發(fā)、高可用以及高性能下的數(shù)據(jù)正確性和一致性。
其次是NoSQL數(shù)據(jù)庫及專用型數(shù)據(jù)庫,其主要用于存儲和處理非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù)(如文檔,圖,時序、時空,K-V),不強制數(shù)據(jù)的一致性,以此換來系統(tǒng)的水平拓展、吞吐能力的提升。
再次是分析型數(shù)據(jù)庫 (On-Line Analytic Processing, OLAP),其應(yīng)用場景就是海量的數(shù)據(jù)、數(shù)據(jù)類型復(fù)雜以及分析條件復(fù)雜的情況,能夠支持深度智能化分析。其面臨的挑戰(zhàn)主要是高性能、分析深度、與TP數(shù)據(jù)庫的聯(lián)動,以及與NoSQL數(shù)據(jù)庫的聯(lián)動。
除了數(shù)據(jù)的核心引擎之外,還有數(shù)據(jù)庫外圍的服務(wù)和管理類工具,比如數(shù)據(jù)傳輸、數(shù)據(jù)備份以及數(shù)據(jù)管理等。
最后就是數(shù)據(jù)庫的管控平臺,無論是私有云、專有云、混合云還是自己的IDC機房內(nèi)進(jìn)行部署,總要有一套數(shù)據(jù)庫管控系統(tǒng)來管理數(shù)據(jù)庫實例的產(chǎn)生和消亡、實例的資源消費等,能夠以簡單的形式提供給DBA以及數(shù)據(jù)庫開發(fā)者。

數(shù)據(jù)庫的技術(shù)演進(jìn)之路
隨著數(shù)據(jù)庫的發(fā)展,漸漸的數(shù)據(jù)庫從傳統(tǒng)的集中式架構(gòu),逐步轉(zhuǎn)型成分布式架構(gòu)。因為遠(yuǎn)超單機數(shù)據(jù)庫容量的數(shù)據(jù)存儲和訪問峰值、實時數(shù)據(jù)分析檢索(OLTP兼顧OLAP)、更高級別的容災(zāi)需求。
傳統(tǒng)的集中式架構(gòu)在穩(wěn)定性和可用性方面有天然的優(yōu)勢,同時缺點也很明顯,擴(kuò)展性差。原來傳統(tǒng)企業(yè)接入的終端有限,銀行、政企的業(yè)務(wù)系統(tǒng)都是給內(nèi)部人員使用,其擴(kuò)展性方面的短板還不足以構(gòu)成挑戰(zhàn)。但是隨著互聯(lián)網(wǎng)尤其是移動互聯(lián)網(wǎng)的發(fā)展,業(yè)務(wù)系統(tǒng)除了滿足內(nèi)部人員使用,還要支撐海量移動終端的訪問請求,數(shù)據(jù)指數(shù)級增長所帶來的高并發(fā)使得集中式架構(gòu)面臨著挑戰(zhàn),依靠垂直型擴(kuò)展很難滿足需求。
因為傳統(tǒng)集中式數(shù)據(jù)庫的限制條件,無法滿足大數(shù)據(jù)時代對于數(shù)據(jù)庫性能的要求,那么分布式的數(shù)據(jù)庫逐漸進(jìn)入人們的視野,分布式數(shù)據(jù)庫一般具有以下特性具有靈活的體系結(jié)構(gòu)、適應(yīng)分布式的管理和控制機構(gòu)、經(jīng)濟(jì)性能優(yōu)越、系統(tǒng)的可靠性高、可用性好、局部應(yīng)用的響應(yīng)速度快、可擴(kuò)展性好,易于集成現(xiàn)有系統(tǒng)等特點。
那么我們從幾個方面來描述下數(shù)據(jù)庫在集中式架構(gòu)或分布式架構(gòu)中使用到的核心技術(shù)點有哪些。傳統(tǒng)集中式數(shù)據(jù)庫架構(gòu)指關(guān)系型數(shù)據(jù)庫,如MySQL、Oracle、SqlServer等。分布式數(shù)據(jù)庫系統(tǒng)架構(gòu)比如CirrData, Oceanbase, TiDB, Cloudera Impala等等。下面我們先講一下傳統(tǒng)的集中式數(shù)據(jù)庫架構(gòu)以Mysql為例, 來描述在集中式數(shù)據(jù)庫中涉及到的核心技術(shù)點。相關(guān)架構(gòu)中的核心技術(shù)不會細(xì)講,先知道有這么個東西就好,后期會專門一系列的文章來細(xì)講數(shù)據(jù)庫架構(gòu)中這些技術(shù)的使用方式、技術(shù)的原理、為什么要這么用。
一、傳統(tǒng)集中式數(shù)據(jù)庫架構(gòu)
將數(shù)據(jù)庫系統(tǒng)拆開來看,其核心模塊包括應(yīng)用接口、SQL接口、查詢執(zhí)行引擎、數(shù)據(jù)訪問模塊和存儲引擎。其中,查詢執(zhí)行引擎進(jìn)一步可以拆分為計劃生成器、計劃優(yōu)化器和計劃執(zhí)行器;數(shù)據(jù)訪問模塊則可以分為事務(wù)處理、內(nèi)存處理、安全管理以及文件和索引管理等模塊;并且事務(wù)處理是最核心的模塊,其中包括了崩潰恢復(fù)和并發(fā)控制;最底層的存儲引擎則包括數(shù)據(jù)文件、索引文件和系統(tǒng)及元數(shù)據(jù)文件。
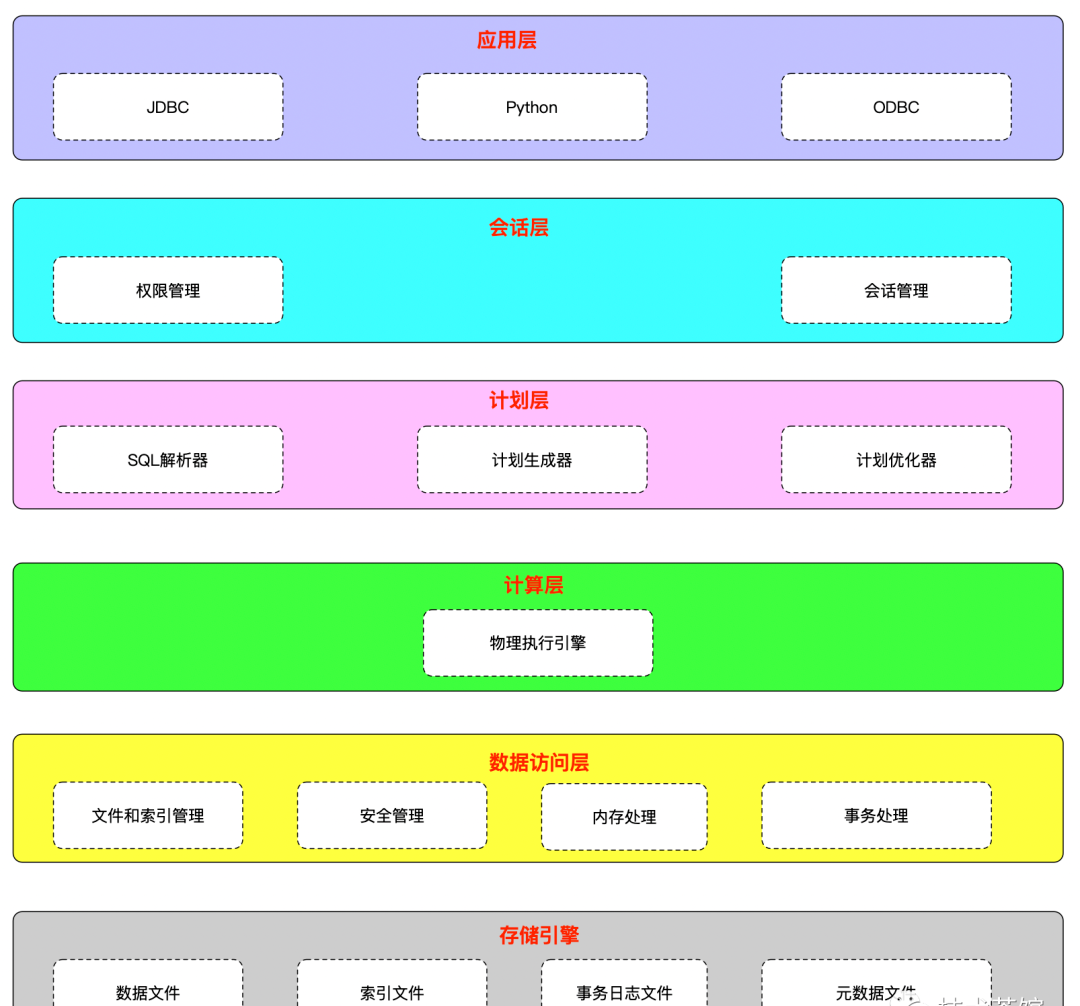
傳統(tǒng)數(shù)據(jù)庫架構(gòu)大致劃分為幾層:
應(yīng)用層: 給客戶端提供連接數(shù)據(jù)庫的工具。
會話層: 處理客戶端與服務(wù)器的session信息,并檢測是否有訪問數(shù)據(jù)庫的權(quán)限相關(guān)的權(quán)限動作。
計劃層: 解析SQL字符串和邏輯計劃的生成。
計算層: 把邏輯計劃轉(zhuǎn)成物理計劃,并計算結(jié)果。
數(shù)據(jù)訪問層: 文件和索引、事務(wù)的管理。
存儲引擎: 外部數(shù)據(jù)源存儲的數(shù)據(jù)文件。
下面舉一個查詢的例子,看各個層之間是如何配合實現(xiàn)的。
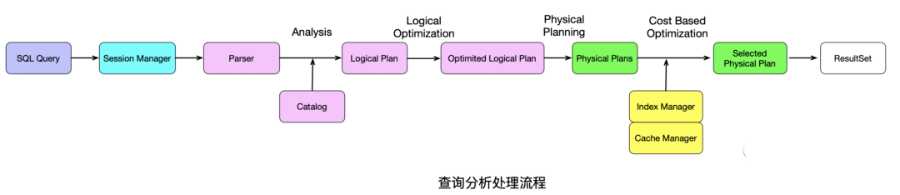
1. 查詢分析處理過程
數(shù)據(jù)庫查詢分析處理過程是這樣的:首先,通過SQL語句將查詢?nèi)蝿?wù)提交上來,之后經(jīng)過Session Manger和Parser進(jìn)行處理,此時會有各種各樣的執(zhí)行方式,并生成Catalog和邏輯執(zhí)行計劃;之后對于邏輯執(zhí)行計劃進(jìn)行優(yōu)化,并生成物理執(zhí)行計劃;之后在借助系統(tǒng)的統(tǒng)計信息,如索引管理、內(nèi)存管理來生成一個優(yōu)化后的物理執(zhí)行計劃,再執(zhí)行并生成最后結(jié)果。
簡單而言,數(shù)據(jù)庫系統(tǒng)的架構(gòu)就是持久化存儲的數(shù)據(jù)按照Data Page的形式進(jìn)行存儲,這些數(shù)據(jù)塊在查詢訪問的時候會被帶到內(nèi)存里面。系統(tǒng)中有內(nèi)存池,每個內(nèi)存池可以裝載一個Page,此時的問題就是內(nèi)存池的大小是有限的,如果數(shù)據(jù)存儲非常大,需要進(jìn)行優(yōu)化。此外,還涉及到優(yōu)化數(shù)據(jù)訪問的問題,一般通過索引解決,主要是Hash索引和樹形索引。那么我們把各個組件拆解,來描述下各個組件都使用什么樣的技術(shù)。
2. 核心技術(shù)
2.1 JDBC組件
大部分應(yīng)用場景下,使用的都是JDBC組件,那么JDBC是什么?JDBC (Java Database Connectivity) API,即Java數(shù)據(jù)庫編程接口,是一組標(biāo)準(zhǔn)的Java語言中的接口和類,使用這些接口和類,Java客戶端程序可以訪問各種不同類型的數(shù)據(jù)庫。比如建立數(shù)據(jù)庫連接、執(zhí)行SQL語句進(jìn)行數(shù)據(jù)的存取操作。通常和客戶應(yīng)用綁定在一起。
2.2 會話管理組件
在連接數(shù)據(jù)庫與斷開連接之間的時間被稱為一個數(shù)據(jù)會話。會話管理通常是數(shù)據(jù)庫和外部交互的組件。JDBC與會話管理通常數(shù)據(jù)交互,可以使用grpc或者thrift這種RPC通信的技術(shù)。
2.3 權(quán)限管理組件
權(quán)限是用戶對一項功能的執(zhí)行權(quán)利,在數(shù)據(jù)庫中,根據(jù)系統(tǒng)管理方式的不同,可將權(quán)限分為系統(tǒng)權(quán)限與對象權(quán)限兩類, 系統(tǒng)權(quán)限是指被授權(quán)用戶是否可以連接到數(shù)據(jù)庫上及數(shù)據(jù)庫中可以進(jìn)行哪些系統(tǒng)操作,另一類是對象權(quán)限是指用戶對數(shù)據(jù)庫中具體對象所擁有的權(quán)限, 對象權(quán)限,如數(shù)據(jù)庫中的表,視圖,存儲過程,存儲函數(shù)等。權(quán)限模組一般采用的技術(shù)是緩存機制。因為用戶權(quán)限相關(guān)的數(shù)據(jù)會被持久化到物理設(shè)備中。緩存機制可以有效的減少IO操作。
2.4 SQL解析器組件
數(shù)據(jù)庫需要支持標(biāo)準(zhǔn)的 SQL 語言,具體實現(xiàn)的時候必然要涉及到詞法分析和語法分析。早期的程序可能會優(yōu)先考慮手工實現(xiàn)詞法分析和語法分析,現(xiàn)在大多數(shù)場合下都會采用工具來簡化實現(xiàn)。MySQL、PostgreSQL 等采用 C/C++ 實現(xiàn)的開源數(shù)據(jù)庫采用的是現(xiàn)代的 yacc/lex 組合,也就是 GNU bison/flex。其他比較流行的工具還有 ANTLR、JavaCC 等等。這些工具大多采用擴(kuò)展的 BNF 語法,并支持很多定制化選項,使得語法比較容易維護(hù)和實現(xiàn)。通過這些工具可以使應(yīng)用端發(fā)送過來的SQL字符串,轉(zhuǎn)成一個AST(Abstract Syntax Tree)抽象SQL語法樹。
2.5 SQL查詢優(yōu)化器
優(yōu)化器作為數(shù)據(jù)庫核心功能之一,也是數(shù)據(jù)庫的“大腦”,理解優(yōu)化器將有助于我們更好地優(yōu)化SQL。
傳統(tǒng)關(guān)系型數(shù)據(jù)庫里面的優(yōu)化器分為CBO和RBO兩種。
RBO(Rule Based Potimizer) 基于規(guī)則的優(yōu)化器:
RBO :RBO所用的判斷規(guī)則是一組內(nèi)置的規(guī)則,這些規(guī)則是硬編碼在數(shù)據(jù)庫的編碼中的,RBO會根據(jù)這些規(guī)則去從SQL諸多的路徑中來選擇一條作為執(zhí)行計劃(比如在RBO里面,有這么一條規(guī)則:有索引使用索引。那么所有帶有索引的表在任何情況下都會走索引)所以,RBO現(xiàn)在被很多數(shù)據(jù)庫拋棄(oracle默認(rèn)是CBO,但是仍然保留RBO代碼,MySQL只有CBO)
RBO最大問題在于硬編碼在數(shù)據(jù)庫里面的一系列固定規(guī)則,來決定執(zhí)行計劃。并沒有考慮目標(biāo)SQL中所涉及的對象的實際數(shù)量,實際數(shù)據(jù)的分布情況,這樣一旦規(guī)則不適用于該SQL,那么很可能選出來的執(zhí)行計劃就不是最優(yōu)執(zhí)行計劃了。
CBO(Cost Based Potimizer) 基于成本的優(yōu)化器:
CBO :CBO在會從目標(biāo)諸多的執(zhí)行路徑中選擇一個成本最小的執(zhí)行路徑來作為執(zhí)行計劃。這里的成本他實際代表了MySQL根據(jù)相關(guān)統(tǒng)計信息計算出來目標(biāo)SQL對應(yīng)的步驟的IO,CPU等消耗。也就是意味著數(shù)據(jù)庫里的成本實際上就是對于執(zhí)行目標(biāo)SQL所需要IO,CPU等資源的一個估計值。而成本值是根據(jù)索引,表,行的統(tǒng)計信息計算出來的。(計算過程比較復(fù)雜)
2.6 物理執(zhí)行器組件
物理執(zhí)行器又叫做計劃執(zhí)行器。執(zhí)行器架構(gòu)一般采用Volcano Model經(jīng)典的基于行的流式迭代模型(Row-BasedStreaming Iterator Model)。比如我們熟知的主流關(guān)系數(shù)據(jù)庫中都采用了這種模型,例如Oracle,SQL Server, MySQL等。
在Volcano模型中,所有的代數(shù)運算符(operator)都被看成是一個迭代器,它們都提供一組簡單的接口:open()—next()—close(),查詢計劃樹由一個個這樣的關(guān)系運算符組成,每一次的next()調(diào)用,運算符就返回一行(Row),每一個運算符的next()都有自己的流控邏輯,數(shù)據(jù)通過運算符自上而下的next()嵌套調(diào)用而被動的進(jìn)行拉取。
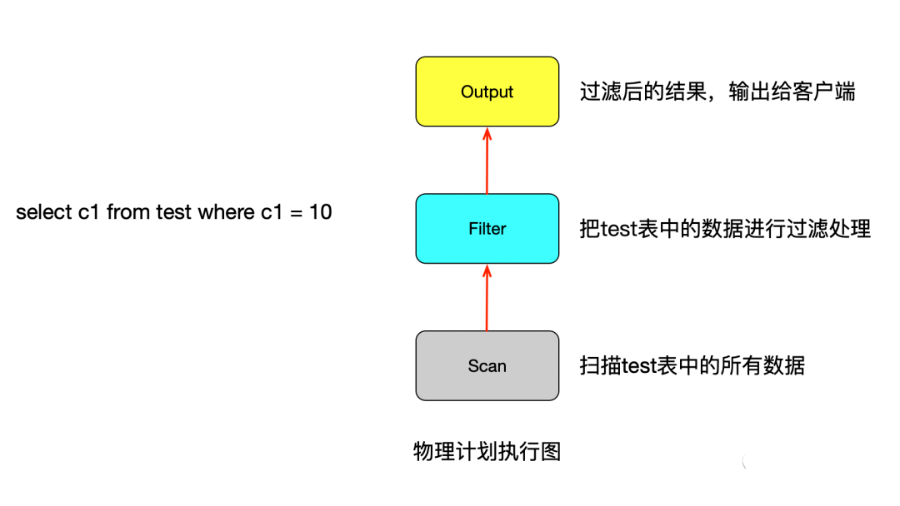
這是一個最簡單的火山模型例子,拉取數(shù)據(jù)的控制命令從最上層的Output運算符依次傳遞到執(zhí)行樹的最下層,而數(shù)據(jù)流動的方向正好相反。
這種計算模型對于CPU Cache是不友好的,所以一般在做表達(dá)式計算的時候通常采用編譯執(zhí)行。來提高CPU Cache的命中率。通常采用的的技術(shù)是Llvm技術(shù)。
對于OLAP數(shù)據(jù)的物理執(zhí)行引擎通常采用列存的數(shù)據(jù)結(jié)構(gòu),因為可以比較高效的提高CPU Cache的利用率,通常也可以采用比較高效SIMD指令來處理。
隨著各個商業(yè)數(shù)據(jù)庫做軟硬件一體化解決方案的產(chǎn)生,通常也會使用GPU和FPGA這種技術(shù)來提高計算性能。
2.7 索引組件
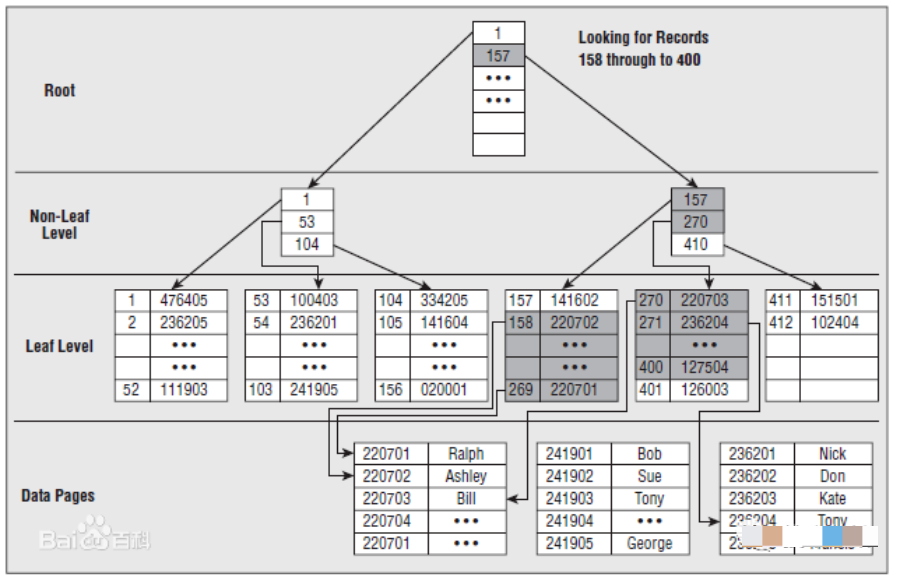
索引是對數(shù)據(jù)庫表中一列或多列的值進(jìn)行排序的一種結(jié)構(gòu),使用索引可快速訪問數(shù)據(jù)庫表中的特定信息。如果想按特定職員的姓來查找他或她,則與在表中搜索所有的行相比,索引有助于更快地獲取信息。
索引的一個主要目的就是加快檢索表中數(shù)據(jù),亦即能協(xié)助信息搜索者盡快的找到符合限制條件的記錄ID的輔助數(shù)據(jù)結(jié)構(gòu)。
數(shù)據(jù)庫索引的核心技術(shù)總的來說,索引就是拿空間換時間。數(shù)據(jù)庫技術(shù)和大數(shù)據(jù)技術(shù)會有一個融合的過程,除了前面講到的B樹索引、Hash索引等,還有倒排索引、MinMax索引、BitSet索引、MDK索引等。
2.8 事務(wù)處理組件

數(shù)據(jù)庫的事務(wù)處理是數(shù)據(jù)庫最重要的核心模組之一,數(shù)據(jù)庫事務(wù)(transaction)是訪問并可能操作各種數(shù)據(jù)項的一個數(shù)據(jù)庫操作序列,這些操作要么全部執(zhí)行,要么全部不執(zhí)行,是一個不可分割的工作單位。事務(wù)由事務(wù)開始與事務(wù)結(jié)束之間執(zhí)行的全部數(shù)據(jù)庫操作組成。
事務(wù)是并發(fā)控制的基本單位。
一個事務(wù)包含的諸操作要么都執(zhí)行,要么都不執(zhí)行。
事務(wù)的屬性
原子性 :事務(wù)是數(shù)據(jù)庫的邏輯工作單位,一個事務(wù)的諸操作要么都做,要么都不做。
一致性 :指事務(wù)執(zhí)行前后必須保持?jǐn)?shù)據(jù)庫的邏輯一致性。一致性和原子性是密切相關(guān)的。
隔離性 :指并發(fā)執(zhí)行的各個事務(wù)之間不能互相干擾。
持久性 :指一個事務(wù)的操作提交后, 其對數(shù)據(jù)庫的改變是永久的,屬于物理的而非邏輯的。
數(shù)據(jù)庫的事務(wù)隔離級別
READ UNCOMMITTED(讀未提交數(shù)據(jù)):允許事務(wù)讀取未被其他事務(wù)提交的變更數(shù)據(jù),會出現(xiàn)臟讀、不可重復(fù)讀和幻讀問題。
READ COMMITTED(讀已提交數(shù)據(jù)):只允許事務(wù)讀取已經(jīng)被其他事務(wù)提交的變更數(shù)據(jù),可避免臟讀,仍會出現(xiàn)不可重復(fù)讀和幻讀問題。
REPEATABLE READ(可重復(fù)讀):確保事務(wù)可以多次從一個字段中讀取相同的值,在此事務(wù)持續(xù)期間,禁止其他事務(wù)對此字段的更新,可以避免臟讀和不可重復(fù)讀,仍會出現(xiàn)幻讀問題。
SERIALIZABLE(序列化):確保事務(wù)可以從一個表中讀取相同的行,在這個事務(wù)持續(xù)期間,禁止其他事務(wù)對該表執(zhí)行插入、更新和刪除操作,可避免所有并發(fā)問題,但性能非常低。
原子性使用的核心技術(shù)
Transaction Undo Log來保證數(shù)據(jù)的原子性。日志的作用能夠在發(fā)生錯誤時撤銷之前的全部操作,肯定是需要將之前的操作都記錄下來的,這樣在發(fā)生錯誤時才可以回滾。
回滾日志除了能夠在發(fā)生錯誤或者用戶執(zhí)行 ROLLBACK 時提供回滾相關(guān)的信息,它還能夠在整個系統(tǒng)發(fā)生崩潰、數(shù)據(jù)庫進(jìn)程直接被殺死后,當(dāng)用戶再次啟動數(shù)據(jù)庫進(jìn)程時,還能夠立刻通過查詢回滾日志將之前未完成的事務(wù)進(jìn)行回滾,這也就需要回滾日志必須先于數(shù)據(jù)持久化到磁盤上,是我們需要先寫日志后寫數(shù)據(jù)庫的主要原因。
一致性使用的核心技術(shù)
數(shù)據(jù)庫一致性(Database Consistency)是指事務(wù)執(zhí)行的結(jié)果必須是使數(shù)據(jù)庫從一個一致性狀態(tài)變到另一個一致性狀態(tài)。保證數(shù)據(jù)庫一致性是指當(dāng)事務(wù)完成時,必須使所有數(shù)據(jù)都具有一致的狀態(tài)。通常需要使用一致性協(xié)議來保證例如Paxos、Raft。
隔離性使用的核心技術(shù)
鎖、時間戳、MVCC來保證數(shù)據(jù)的隔離性。
鎖是一種最為常見的并發(fā)控制機制,在一個事務(wù)中,我們并不會將整個數(shù)據(jù)庫都加鎖,而是只會鎖住那些需要訪問的數(shù)據(jù)項,常見數(shù)據(jù)庫中的鎖都分為兩種,共享鎖(Shared)和互斥鎖(Exclusive),前者也叫讀鎖,后者叫寫鎖。讀鎖保證了讀操作可以并發(fā)執(zhí)行,相互不會影響,而寫鎖保證了在更新數(shù)據(jù)庫數(shù)據(jù)時不會有其他的事務(wù)訪問或者更改同一條記錄造成不可預(yù)知的問題。
時間戳也是實現(xiàn)事務(wù)的隔離性的一種方式,使用這種方式實現(xiàn)事務(wù)的數(shù)據(jù)庫,例如 PostgreSQL 會為每一條記錄保留兩個字段;讀時間戳中包括了所有訪問該記錄的事務(wù)中的最大時間戳,而記錄行的寫時間戳中保存了將記錄改到當(dāng)前值的事務(wù)的時間戳。使用時間戳實現(xiàn)事務(wù)的隔離性時,往往都會使用樂觀鎖,先對數(shù)據(jù)進(jìn)行修改,在寫回時再去判斷當(dāng)前值,也就是時間戳是否改變過,如果沒有改變過,就寫入,否則,生成一個新的時間戳并再次更新數(shù)據(jù),樂觀鎖其實并不是真正的鎖機制。
MVCC也是實現(xiàn)事務(wù)的隔離性的一種方式,通過維護(hù)多個版本的數(shù)據(jù),數(shù)據(jù)庫可以允許事務(wù)在數(shù)據(jù)被其他事務(wù)更新時對舊版本的數(shù)據(jù)進(jìn)行讀取,很多數(shù)據(jù)庫都對這一機制進(jìn)行了實現(xiàn);因為所有的讀操作不再需要等待寫鎖的釋放,所以能夠顯著地提升讀的性能,MySQL 和 PostgreSQL 都對這一機制進(jìn)行自己的實現(xiàn)。
持久性使用的核心技術(shù)
Transacation Redo Log來保證數(shù)據(jù)的持久性。日志由兩部分組成,一是內(nèi)存中的重做日志緩沖區(qū),因為重做日志緩沖區(qū)在內(nèi)存中,所以它是易失的,另一個就是在磁盤上的重做日志文件,它是持久的。
2.9 存儲引擎組件
存儲引擎通常要處理的事情
并發(fā)性:某些應(yīng)用程序比其他應(yīng)用程序具有很多的顆粒級鎖定要求(如行級鎖定)。
事務(wù)支持:并非所有的應(yīng)用程序都需要事務(wù),但對的確需要事務(wù)的應(yīng)用程序來說,有著定義良好的需求,如ACID兼容等。
引用完整性:通過DDL定義的 外鍵,服務(wù)器需要強制保持關(guān)聯(lián)數(shù)據(jù)庫的引用完整性。
物理存儲:它包括各種各樣的事項,從表和索引的總的頁大小,到存儲數(shù)據(jù)所需的格式,到物理磁盤。
索引支持:不同的應(yīng)用程序傾向于采用不同的索引策略,每種存儲引擎通常有自己的編制索引方法,但某些索引方法(如B-tree索引)對幾乎所有的存儲引擎來說是共同的。
內(nèi)存高速緩沖:與其他應(yīng)用程序相比,不同的應(yīng)用程序?qū)δ承﹥?nèi)存高速緩沖策略的響應(yīng)更好,因此,盡管某些內(nèi)存高速緩沖對所有存儲引擎來說是共同的(如用于用戶連接的高速緩沖,MySQL的高速查詢高速緩沖等),其他高速緩沖策略僅當(dāng)使用特殊的存儲引擎時才唯一定義。
性能幫助:包括針對并行操作的多I/O線程,線程并發(fā)性,數(shù)據(jù)庫檢查點,成批插入處理等。
其他目標(biāo)特性:可能包括對地理空間操作的支持,對特定數(shù)據(jù)處理操作的安全限制等。
二、分布式數(shù)據(jù)庫架構(gòu)
分布式數(shù)據(jù)庫一般由多個管理節(jié)點和數(shù)據(jù)節(jié)點組成,分別負(fù)責(zé)分布式數(shù)據(jù)庫的運維和數(shù)據(jù)存儲。相比于單機數(shù)據(jù)庫,分布式數(shù)據(jù)庫具有“邏輯統(tǒng)一、物理分散”的特點,邏輯統(tǒng)一是指,從用戶角度看,不論多少個節(jié)點組成數(shù)據(jù)庫的完整功能,對用戶而言,都表現(xiàn)的像是一個單機數(shù)據(jù)庫;物理分散是指,從實現(xiàn)角度看,分布式的數(shù)據(jù)庫功能分別由不同的節(jié)點完成,由其內(nèi)部進(jìn)行自動化的統(tǒng)一調(diào)度。邏輯統(tǒng)一的要求和物理分散的實現(xiàn),決定了在很多產(chǎn)品功能實現(xiàn)上,相較于單機數(shù)據(jù)庫具有一定的復(fù)雜性和技術(shù)難度。
目前業(yè)界的分布式數(shù)據(jù)庫產(chǎn)品非常多比如(Oceanbase, Impala, Greenplum, CirroData, SAP HANA)等等。按照目前業(yè)界這些分布式數(shù)據(jù)庫的現(xiàn)狀,技術(shù)路線分類如下:
基于開源數(shù)據(jù)庫 + 中間件:開源單機數(shù)據(jù)庫(如 mysql 、 postgres 等)已經(jīng)經(jīng)過了幾十年的應(yīng)用,產(chǎn)品功能相對穩(wěn)定,單機數(shù)據(jù)處理性能也相對比較高。這種方案的優(yōu)點是可以利用現(xiàn)有單機數(shù)據(jù)庫穩(wěn)定的產(chǎn)品功能,缺點是中間件的功能實現(xiàn)要受限于單機數(shù)據(jù)庫的功能。當(dāng)然,也有足夠研究能力的廠商會對單機數(shù)據(jù)庫進(jìn)行功能優(yōu)化和改進(jìn),比如 mysql 的主從同步機制、熱點數(shù)據(jù)訪問等,這對廠商的研發(fā)能力和技能儲備要求非常高。
完全自研:公司組建團(tuán)隊進(jìn)行產(chǎn)品的自研開發(fā),當(dāng)然,不可能完全重復(fù)造輪子,在實現(xiàn)部分產(chǎn)品功能時可能會采用或者借鑒一些開源軟件,比如 TiDB 的數(shù)據(jù)存儲使用了 RocksDB 。數(shù)據(jù)資產(chǎn)是公司最核心的資源,尤其是銀行等金融行業(yè),數(shù)據(jù)庫不能出現(xiàn)重大問題,但數(shù)據(jù)庫的產(chǎn)品功能完善需要經(jīng)過一段時期的生成環(huán)境驗證,需要填各種坑。因此,這種方案的優(yōu)點是天生具有分布式的特性,從設(shè)計之初就是針對分布式架構(gòu)進(jìn)行設(shè)計的,而單機數(shù)據(jù)庫的很多設(shè)計當(dāng)時還未具備分布式的思維理念,缺點是產(chǎn)品的功能需要經(jīng)過不同場景、不同數(shù)據(jù)量和不同行業(yè)用戶的檢驗、改進(jìn)和完善,才能具備成熟度,需要團(tuán)隊具備相應(yīng)的應(yīng)用場景。
目前數(shù)據(jù)庫產(chǎn)品的業(yè)務(wù)場景一般分為支持 OLTP(交易性數(shù)據(jù)庫)、 OLAP(分析性數(shù)據(jù)庫) 和 HTAP(分析交易混合型數(shù)據(jù)庫)。目前 OLAP 已經(jīng)有很多成熟的產(chǎn)品或者大數(shù)據(jù)開源軟件支持, HTAP 的理念是用一款產(chǎn)品同時解決 OLAP 和 OLTP 的場景。
那么我們來看下分布式數(shù)據(jù)庫有哪些核心技術(shù)
數(shù)據(jù)分布
單機的縱向擴(kuò)展能力受主板卡槽等影響存在上限,有單機處理容量和速度的上限,而分布式數(shù)據(jù)庫則是通過橫向擴(kuò)展能力來無限提升數(shù)據(jù)庫處理速度、性能和容量。對于一個數(shù)據(jù)量很大的表,往往需要將其分布到多個節(jié)點進(jìn)行處理。目前技術(shù)趨勢如下:
支持常見的數(shù)據(jù)分布方式有 hash 、 range 和 list 。MySQL 的語法還有一種 key ,但是可以類似于 hash ,區(qū)別在于 key 的 hash 函數(shù)由服務(wù)器提供。當(dāng)然,有部分產(chǎn)品只支持其中一種或者兩種。在銀行業(yè),比如銀行卡等部分業(yè)務(wù)數(shù)據(jù)還具有一個特征,就是某個字符串的中間部分是具有業(yè)務(wù)特征,比如可能是省市代碼,如果可以支持對字符串的子串支持多種分布方式會簡化應(yīng)用開發(fā),但目前幾乎沒有產(chǎn)品支持這個功能。
單表復(fù)制。在對分布在多個數(shù)據(jù)節(jié)點的 2 個表進(jìn)行表連接時,會涉及網(wǎng)絡(luò)通訊和大量數(shù)據(jù)傳輸,會影響性能。比如, A 表和 B 表進(jìn)行表連接, B 表進(jìn)行 hash 后保存在四個節(jié)點,如果此時在四個節(jié)點上均保存一份全量數(shù)據(jù) A ,那么可以分別在四個節(jié)點完成表連接,然后再進(jìn)行數(shù)據(jù)匯總。這種場景成為單表復(fù)制。這種表一般是數(shù)據(jù)量相對較少,數(shù)據(jù)改動較小。數(shù)據(jù)量少,是需要單個數(shù)據(jù)節(jié)點可以對其進(jìn)行處理,數(shù)據(jù)改動較小是為了降低數(shù)據(jù)頻繁改動時的性能影響。因為每次修改數(shù)據(jù),需要同步修改四個數(shù)據(jù)節(jié)點的數(shù)據(jù)。
分布式事務(wù)
分布式事務(wù)是分布式數(shù)據(jù)庫的重點,也是它的難點。產(chǎn)品的實現(xiàn)方式各不相同,主要有如下兩種流派:
兩階段提交:這種業(yè)界最主流的選擇方案,區(qū)別在于不同的產(chǎn)品對兩階段的實現(xiàn)方式不同,一種是利用 MySQL 支持的 XA 協(xié)議, MySQL 提供了 XA 協(xié)議的接口,可以在此基礎(chǔ)上實現(xiàn),一般用于采用中間件技術(shù)路線的產(chǎn)品;一種自己實現(xiàn) XA 協(xié)議,一般用于自研路線的產(chǎn)品。目前這是業(yè)界實現(xiàn)主流。
一階段提交 + 事務(wù)補償:這種方案設(shè)計者一般認(rèn)為兩階段的成本較高,因此將分布式事務(wù)的各個階段分別進(jìn)行提交,如果某個階段發(fā)生異常時,再對已提交的各階段事務(wù)進(jìn)行事務(wù)沖正。目前只有個別產(chǎn)品采用這種方案。
不論哪種流派,分布式事務(wù)的設(shè)計有幾個難點:
分布式事務(wù)的異常處理:從正常流程看,哪種方案都看似行得通,無法厚非。但真正設(shè)計難點在于分布式的參與節(jié)點多,在這個過程中,無論哪個節(jié)點都有可能故障,問題在于:無論哪個節(jié)點或者階段發(fā)生過程,如何保證事務(wù)的完整性和數(shù)據(jù)一致性。
分布式事務(wù)的隔離級別:如果對標(biāo)單機數(shù)據(jù)庫的四個事務(wù)隔離級別,分布式事務(wù)完全實現(xiàn)具有很高的難度,所有產(chǎn)品均實現(xiàn)難度不大的已提交讀,部分產(chǎn)品實現(xiàn)了可串行化讀,其它兩個隔離級別實現(xiàn)起來復(fù)雜度較高。
分布式事務(wù)的性能優(yōu)化:由于分布式事務(wù)在 commit 階段需要處理大量操作,甚至是跨節(jié)點的操作,因此,如何區(qū)分本地事務(wù)和分布式事務(wù),如何優(yōu)化提升分別式事務(wù),是一個復(fù)雜的問題。由于每家產(chǎn)品各不相同,因為不具有通用可總結(jié)的規(guī)律。
分布式事務(wù)的數(shù)據(jù)多版本控制( MVCC ):Oracle 和 MySQL 均實現(xiàn)了 MVCC 功能。但分布式事務(wù)的 MVCC 功能實現(xiàn)具有一定難度,如果結(jié)合事務(wù)隔離級別,實現(xiàn)難度更大。
數(shù)據(jù)復(fù)制
不同于 DB2 、 Oracle 等數(shù)據(jù)庫采用增強存儲硬件可靠性,分布式數(shù)據(jù)庫使用廉價 PC 服務(wù)器,它們的特點就是故障率相對比較高。對于一個數(shù)百臺機器組成的分布式數(shù)據(jù)庫時,出現(xiàn)幾臺服務(wù)器故障都是正常現(xiàn)象。分布式數(shù)據(jù)庫一般采用 share nothing 的模型,每個數(shù)據(jù)節(jié)點都采用自己的本地存儲。主要技術(shù)特點如下:
為了保證數(shù)據(jù)的可靠性,必須將數(shù)據(jù)保存多份,經(jīng)典的數(shù)值是三份:hadoop 中數(shù)據(jù)也是默認(rèn)保存三份。這樣,三個節(jié)點完全壞掉的可能性非常小,但并非理論上的不可能。對于一些數(shù)據(jù)安全性要求高的場景,可以保存五份。每多保存一份,就多一份的硬件支出成本,因此需要進(jìn)行硬件成本和數(shù)據(jù)安全容忍度的平衡。
為兼顧多個節(jié)點的數(shù)據(jù)安全性和數(shù)據(jù)寫性能,一般采用超半數(shù)同步寫成功的原則。在將數(shù)據(jù)保存三份或者五份時,在寫數(shù)據(jù)時,如果只有一個節(jié)點寫成功,其它節(jié)點采用異步模式,當(dāng)該節(jié)點宕機,其它節(jié)點還未寫成功時就會存在數(shù)據(jù)丟失的可能性;如果等待所有節(jié)點寫成功,那么響應(yīng)時間可能比較長,無法滿足性能要求。因此,采用了折中方法,即超過半數(shù)同步寫成功即可。這種思想可以采用 paxos 或者 raft 協(xié)議實現(xiàn)。
讀寫分離
在數(shù)據(jù)存在多份時,會有一個節(jié)點作為主節(jié)點,其余節(jié)點保持與它的同步,稱為從節(jié)點。由于半數(shù)寫成功原則的存儲,尤其在數(shù)據(jù)節(jié)點比較繁忙的時候,存在部分從節(jié)點與主節(jié)點不一致的情況。如果所有客戶端的請求均發(fā)給主節(jié)點,主節(jié)點要承擔(dān)所有讀寫功能,在高負(fù)載的情況下會雪上加霜,造成響應(yīng)速度很慢。在常用業(yè)務(wù)場景中,一般都是寫少讀多。因此,對于一些對數(shù)據(jù)實時性要求不高的業(yè)務(wù)場景,可以將客戶端的讀請求發(fā)給從節(jié)點,從而降低從節(jié)點的負(fù)載。
數(shù)據(jù)備份恢復(fù)
數(shù)據(jù)的備份恢復(fù)是數(shù)據(jù)庫運維的基本操作。對于運維人員而言,一般是希望通過一個命令操作可以備份所有數(shù)據(jù)節(jié)點的數(shù)據(jù),如同單機數(shù)據(jù)庫備份一樣。但是,因為備份過程需要每個節(jié)點的數(shù)據(jù)庫單獨進(jìn)行備份,因此,需要保持每個數(shù)據(jù)節(jié)點的備份都是在同一個時間節(jié)點的備份快照,這非常重要。
業(yè)界常用的解決方法是在備份操作啟動的時間,記錄下整個數(shù)據(jù)庫的當(dāng)前最大事務(wù) ID ,比如 LSN ,同時備份數(shù)據(jù)文件和日志文件。數(shù)據(jù)文件的備份可以采用物理備份,在備份的過程中可能會產(chǎn)生客戶端請求修改數(shù)據(jù)的情況,這些修改的操作都已經(jīng)通過日志文件進(jìn)行了備份。在進(jìn)行數(shù)據(jù)恢復(fù)時,首先還原數(shù)據(jù)文件,然后通過重復(fù)日志文件,一直到需要操作的時間點。
容災(zāi)高可用
傳統(tǒng)單機數(shù)據(jù)庫的高可用和異地容災(zāi),比如 Oracle ,多采用 ADG(active data guard) 和 OGG(oracle golden gate) 的模式進(jìn)行數(shù)據(jù)實時同步,但是當(dāng)主庫發(fā)生故障時,切換到備庫。在實時操作過程中,雖然可以進(jìn)行自動切換,但為了檢查主庫和從庫的一致性,銀行業(yè)很多案例都需要進(jìn)行人工核對,這樣故障恢復(fù)就需要一定時間。但是分布式數(shù)據(jù)庫的多數(shù)據(jù)副本模式就很好的解決了這個問題。比如三副本情況下,可以將 2 個節(jié)點放在本地機房,第三個節(jié)點放在異地機房。在正常情況下,進(jìn)行數(shù)據(jù)修改時,按照超過半數(shù)即為成功的原則,由于本地的 2 個節(jié)點網(wǎng)絡(luò)時延小,就會很快完成操作并相應(yīng)客戶端。當(dāng)發(fā)生某個節(jié)點故障時,可以自動切換到本地節(jié)點的另外一個節(jié)點,同時第三個節(jié)點還在運行,只要這 2 個節(jié)點都寫成功,仍然正常提供服務(wù),此時業(yè)務(wù)系統(tǒng)相應(yīng)時間過變長,可以視作服務(wù)能力降級,但是不會發(fā)生業(yè)務(wù)系統(tǒng)宕機。對于一些非常重要的系統(tǒng),甚至可能采用 4+1 ,同城機房有 4 個節(jié)點,兩個機房各有 2 個節(jié)點,第 5 個節(jié)點(即 4+1 中的 1 )在異地機房,這樣,即便本地機房節(jié)點故障發(fā)生 1 個節(jié)點故障,不會服務(wù)降級。
三、SMP VS MPP
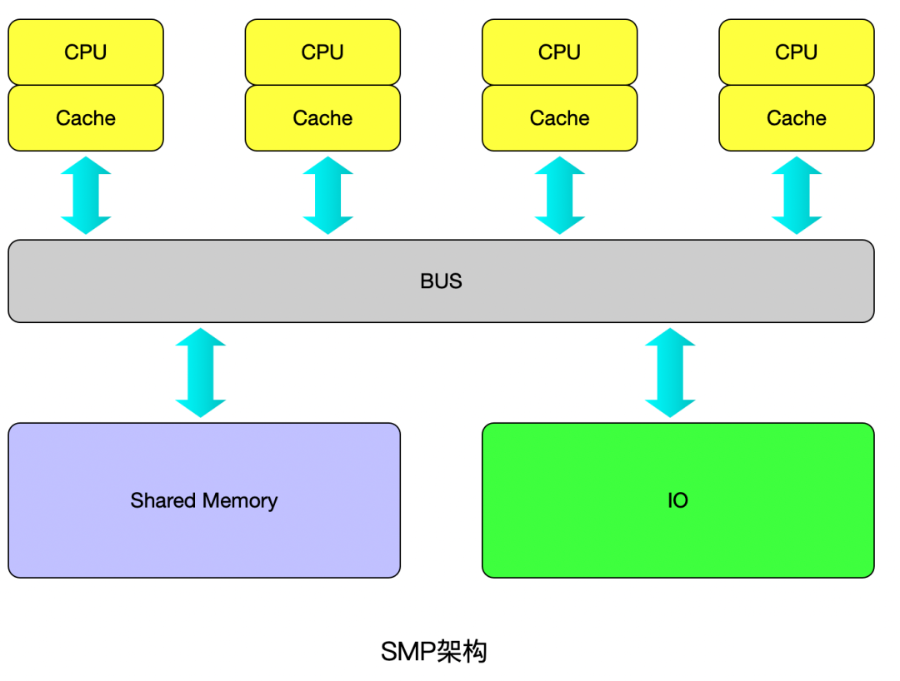
SMP(Symmetric Multi-Processor)系統(tǒng)內(nèi)有許多緊耦合多處理器,在這樣的系統(tǒng)中,所有的CPU共享全部資源,如總線,內(nèi)存和I/O系統(tǒng)等;
所謂對稱多處理器結(jié)構(gòu),是指服務(wù)器中多個 CPU 對稱工作,無主次或從屬關(guān)系。各 CPU 共享相同的物理內(nèi)存,每個 CPU 訪問內(nèi)存中的任何地址所需時間是相同的,因此 SMP 也被稱為一致存儲器訪問結(jié)構(gòu) (UMA :Uniform Memory Access) 。對 SMP 服務(wù)器進(jìn)行擴(kuò)展的方式包括增加內(nèi)存、使用更快的 CPU 、增加 CPU 、擴(kuò)充 I/O( 槽口數(shù)與總線數(shù) ) 以及添加更多的外部設(shè)備 ( 通常是磁盤存儲 ) 。
主要特征是共享,系統(tǒng)中所有資源 (CPU 、內(nèi)存、 I/O 等 ) 都是共享的。也正是由于這種特征,導(dǎo)致了
SMP 服務(wù)器的主要問題,那就是它的擴(kuò)展能力非常有限。對于 SMP 服務(wù)器而言,每一個共享的環(huán)節(jié)都可能造成 SMP 服務(wù)器擴(kuò)展時的瓶頸,而最受限制的則是內(nèi)存。由于每個 CPU 必須通過相同的內(nèi)存總線訪問相同的內(nèi)存資源,因此隨著 CPU 數(shù)量的增加,內(nèi)存訪問沖突將迅速增加,最終會造成 CPU 資源的浪費,使 CPU 性能的有效性大大降低。實驗證明, SMP 服務(wù)器 CPU 利用率最好的情況是 2 至 4 個 CPU 。
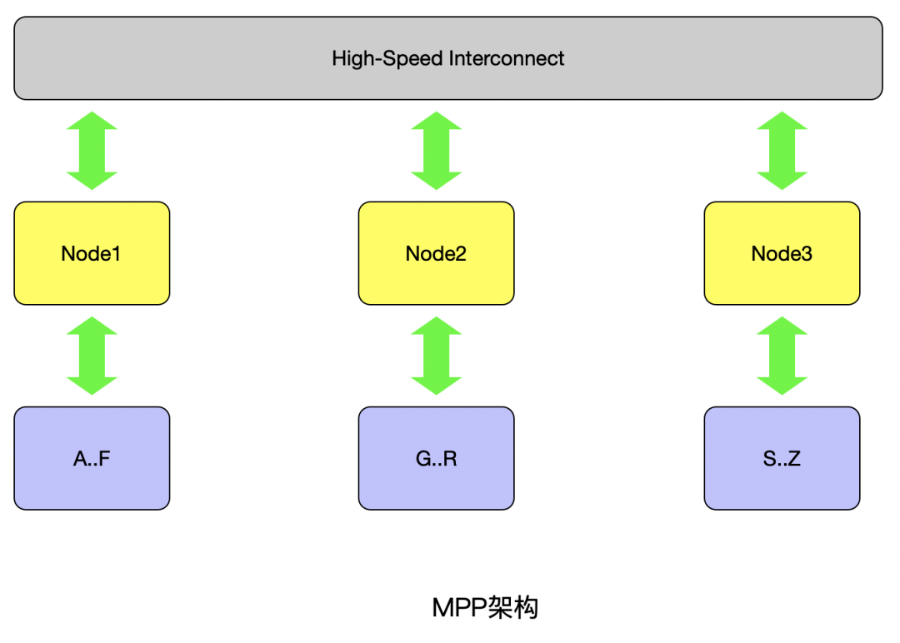
MPP(Massive Parallel Processing)由多個 SMP 服務(wù)器通過一定的節(jié)點互聯(lián)網(wǎng)絡(luò)進(jìn)行連接,協(xié)同工作,完成相同的任務(wù),從用戶的角度來看是一個服務(wù)器系統(tǒng)。其基本特征是由多個 SMP 服務(wù)器 ( 每個 SMP 服務(wù)器稱節(jié)點 ) 通過節(jié)點互聯(lián)網(wǎng)絡(luò)連接而成,每個節(jié)點只訪問自己的本地資源 ( 內(nèi)存、存儲等 ) ,是一種完全無共享 (Share Nothing) 結(jié)構(gòu)。
既然有兩種結(jié)構(gòu),那它們各有什么特點呢?采用什么結(jié)構(gòu)比較合適呢?通常情況下,MPP系統(tǒng)因為要在不同處理單元之間傳送信息,所以它的效率要比SMP要差一點,但是這也不是絕對的,因為MPP系統(tǒng)不共享資源,因此對它而言,資源比SMP要多,當(dāng)需要處理的事務(wù)達(dá)到一定規(guī)模時,MPP的效率要比SMP好。這就是看通信時間占用計算時間的比例而定,如果通信時間比較多,那MPP系統(tǒng)就不占優(yōu)勢了,相反,如果通信時間比較少,那MPP系統(tǒng)可以充分發(fā)揮資源的優(yōu)勢,達(dá)到高效率。當(dāng)前使用的OTLP程序中,用戶訪問一個中心數(shù)據(jù)庫,如果采用SMP系統(tǒng)結(jié)構(gòu),它的效率要比采用MPP結(jié)構(gòu)要快得多。而MPP系統(tǒng)在決策支持和數(shù)據(jù)挖掘方面顯示了優(yōu)勢,可以這樣說,如果操作相互之間沒有什么關(guān)系,處理單元之間需要進(jìn)行的通信比較少,那采用MPP系統(tǒng)就要好,相反就不合適了。
四、資源訪問方式

Shared Everthting:一般是針對單個主機,完全透明共享CPU/MEMORY/IO,并行處理能力是最差的,典型的代表SQLServer
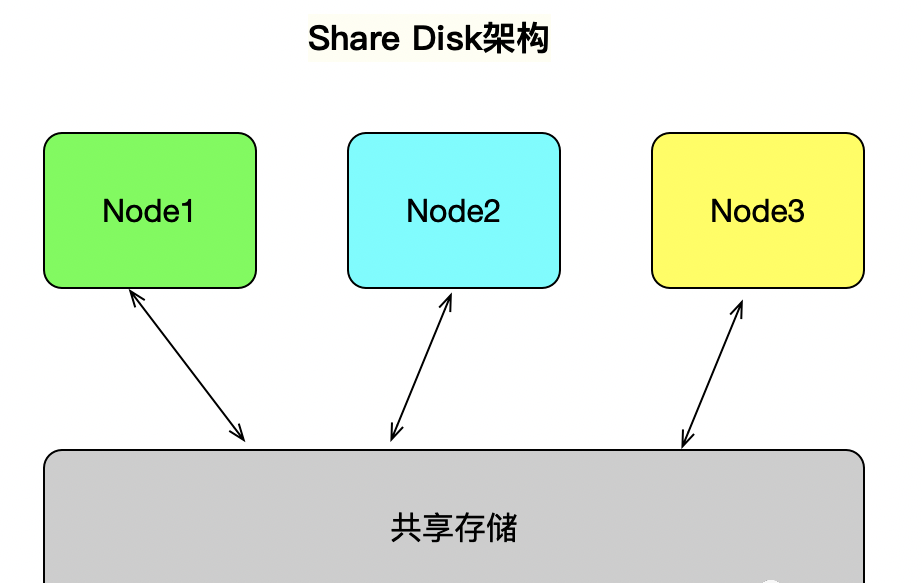
Shared Disk:各個處理單元使用自己的私有 CPU和Memory,共享磁盤系統(tǒng)。典型的代表Oracle Rac, 它是數(shù)據(jù)共享,可通過增加節(jié)點來提高并行處理的能力,擴(kuò)展能力較好。其類似于SMP(對稱多處理)模式,但是當(dāng)存儲器接口達(dá)到飽和的時候,增加節(jié)點并不能獲得更高的性能 。
Shared Nothing:各個處理單元都有自己私有的CPU/內(nèi)存/硬盤等,不存在共享資源,類似于MPP(大規(guī)模并行處理)模式,各處理單元之間通過協(xié)議通信,并行處理和擴(kuò)展能力更好。典型代表DB2 DPF和Hadoop ,各節(jié)點相互獨立,各自處理自己的數(shù)據(jù),處理后的結(jié)果可能向上層匯總或在節(jié)點間流轉(zhuǎn)。
我們常說的 Sharding 其實就是Share Nothing架構(gòu),它是把某個表從物理存儲上被水平分割,并分配給多臺服務(wù)器(或多個實例),每臺服務(wù)器可以獨立工作,具備共同的schema,比如MySQL Proxy和Google的各種架構(gòu),只需增加服務(wù)器數(shù)就可以增加處理能力和容量。
Shared nothing架構(gòu)(shared nothing architecture)是一 種分布式計算架構(gòu)。這種架構(gòu)中的每一個節(jié)點( node)都是獨立、自給的,而且整個系統(tǒng)中沒有單點競爭。
結(jié)論
前幾年大數(shù)據(jù)時代剛來臨的時候,Hadoop分布式組件應(yīng)運而生,Hadoop有三大組件HDFS、MapReduce、Yarn,HDFS的作用是分布式的存儲,來提高容災(zāi)和高可用,MapReduce來提供分布式計算,Yarn用來做集群的資源調(diào)度和資源整合。
于是業(yè)界就產(chǎn)生了一個說法,叫做”數(shù)據(jù)庫已死“,數(shù)據(jù)庫領(lǐng)域會被改朝換代。存儲、計算、調(diào)度通過Hadoop組件都可以辦到,那么我們還用數(shù)據(jù)庫做什么呢?經(jīng)過時間的證明OLTP還是OLAP或者HTAP,開源數(shù)據(jù)庫與商業(yè)數(shù)據(jù)庫都存在巨大的功能和性能鴻溝。
開源數(shù)據(jù)庫雖然廣泛應(yīng)用在互聯(lián)網(wǎng)等場景,但是傳統(tǒng)的企業(yè)用戶,無論是金融、保險、醫(yī)療、電信、等等,還是高度依賴商業(yè)數(shù)據(jù)庫。互聯(lián)網(wǎng)高數(shù)據(jù)量、高性能、高并發(fā)、擴(kuò)展性、軟件成本等等的限制條件。數(shù)據(jù)庫的重要性越來越重要。
上文只是講了數(shù)據(jù)庫中會用到什么要的技術(shù),后續(xù)會對于每一個技術(shù)進(jìn)行詳細(xì)講解。
參考資料
1.https://baike.baidu.com/item/分布式數(shù)據(jù)庫系統(tǒng)
2.MySQL的多存儲引擎架構(gòu)
3.MySQL 架構(gòu)及優(yōu)化原理
4.全面講解分布式數(shù)據(jù)庫架構(gòu)設(shè)計特點
5.李飛飛:如何看待數(shù)據(jù)庫的未來?
6.分布式系統(tǒng):概念與設(shè)計(第3版)》
推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf