
Spark 特性|Spark 3.3.0 中 DS V2 Push-down 的重構(gòu)與新特性
本文作者耿嘉安,暢銷書《深入理解 Spark》和《Spark 內(nèi)核設(shè)計的藝術(shù)》作者,Apache Spark Contributor,15 年 IT 經(jīng)驗的 Kyligence 高級性能工程師。
近日 Apache Spark 3.3.0 正式發(fā)布。在本文中,作者將對 Spark 3.2 DS V2 Push-down 框架進行深入分析,并分享 Kyligence 開源團隊是如何在 Spark 3.3.0 中完成對 DS V2 Push-down 的重構(gòu)與改進的,歡迎大家在評論區(qū)分享你的看法。
#01
引言

Spark 自正式開源以來,已到了第十個年頭。如今,這樣一款優(yōu)秀的分布式大數(shù)據(jù)計算框架早已在國內(nèi)獲得普遍使用。筆者是在 Spark 1.2.0 版本時開始接觸它,已有近八年時光。最初,廣大用戶主要將它作為“大數(shù)據(jù) 2.0”的新生兒看待,用來解決“大數(shù)據(jù) 1.0”批處理技術(shù)的不足。其實,這里所謂的 1.0 或者 2.0 都只是國內(nèi)玩家創(chuàng)造的衍生物,甚至也有提出“大數(shù)據(jù) 3.0”。至于什么是 1.0,2.0 甚至 3.0,其實并沒有什么嚴(yán)格的定義,更多的是商業(yè)戰(zhàn)略。究竟什么才是 2.0 或是 3.0,交給后人評說更為恰當(dāng)。
一開始,國內(nèi)技術(shù)公司寄希望于 Spark,希望它能解決實時、流計算、批處理,更不用說什么數(shù)據(jù)異構(gòu)、數(shù)據(jù)規(guī)模、分布式等問題。國內(nèi)技術(shù)公司跟 Spark 磨合了很多年,發(fā)現(xiàn)它并沒有像人們所說的那么符合期待。再加上其他大數(shù)據(jù)技術(shù)的異軍突起,使得 Spark 的應(yīng)用場景發(fā)生了很多變化。Spark 依然是批處理中加速 Hadoop 生態(tài)的產(chǎn)品,甚至也轉(zhuǎn)變?yōu)槠渌髷?shù)據(jù)技術(shù)的底層引擎。越來越多的用戶希望 Spark 不僅僅解決 Hadoop 生態(tài)的問題,于是 Spark 除了遵循 ANSI SQL 標(biāo)準(zhǔn),也對 Parquet、Orc、Avro 等數(shù)據(jù)格式,對 SnowFlake、PostgreSQL、Teradata 等廠商做了更多的兼容。既然 Spark 支持了越來越多的數(shù)據(jù)源,那么對 Spark 的基本要求就是計算效率不能比數(shù)據(jù)源本身的計算效率低。
實際上,Spark 在一開始接入各種數(shù)據(jù)源都是通過早期提供的數(shù)據(jù)源 Connector 來完成的。Connector 可以作為 Plugin 接入 Spark 早期的批處理計算中,這種方式在當(dāng)時以非常快速的方式讓 Spark 在大數(shù)據(jù)生態(tài)中立足。但是批處理計算的過程,需要將數(shù)據(jù)源數(shù)據(jù)拉取到 Executor 本地,然后再進行計算。計算過程中如果產(chǎn)生了 Shuffle,那么寫入磁盤的 Shuffle 數(shù)據(jù)也會很多,導(dǎo)致對網(wǎng)絡(luò)傳輸有更高要求。
因此,批處理的方式未必是對數(shù)據(jù)源數(shù)據(jù)進行計算的最好方式——最典型的例子莫過數(shù)據(jù)流。當(dāng)然,早期的 Spark 依然用批處理的經(jīng)典理論來解決數(shù)據(jù)流的問題。為了一定程度解決數(shù)據(jù)延遲的問題,引入了“微批”。但是這種方式畢竟違背了數(shù)據(jù)流提供方的最初意愿,于是 Spark 漸漸開始解決數(shù)據(jù)流的實時處理問題,不得不舍棄批處理的一些樊籠。除此之外,Spark 對于其他數(shù)據(jù)源采用批處理的方式也是不適當(dāng)?shù)模P者對這一點就深有感觸。例如:一條 SQL 在 MySQL 中執(zhí)行只需要幾百毫秒,但是 Spark 卻需要幾十分鐘。筆者最初遇到這種情況時,是通過魔改 Spark 算子的方式解決的。這種方式當(dāng)然不值得提倡,但是迫于生產(chǎn)的需要,這是最快解決問題的方式。
隨著 Spark 2.4.0 的發(fā)布,我們發(fā)現(xiàn)越來越多的數(shù)據(jù)源正在努力向 Spark 社區(qū)貢獻將查詢下推到數(shù)據(jù)源的能力。例如:Parquet 和 Orc 的 Filter 下推。Spark 3.0.0 發(fā)布了 Catalog Plugin API,這套 API 的設(shè)計比老的 Connector 更加高明,用戶可以實現(xiàn)更加豐富的內(nèi)容,比如:Catalog 和 Table。用戶可以在此基礎(chǔ)上實現(xiàn)更加自定義的物理行為。Spark 3.1.0 和 Spark 3.2.0 又陸續(xù)提供了列裁剪、Filter 下推、Aggregate 下推等可以影響物理執(zhí)行的功能。在這里我們下一個定義——所有基于 Catalog Plugin API 的東西我們簡單稱其為 DS V2;基于 DS V2 實現(xiàn)的下推,我們簡單稱其為 DS V2 Push-down。
由于 Spark 之前版本提供的 DS V2 Push-down 有各種功能上的不足,因此 Kyligence 著力向 Spark 社區(qū)持續(xù)推動對它的改進。下面先來看看 DS V2 Push-down 在 Spark 3.2.0 版本時的情況。
#02
Spark 3.2 DS V2 Push-down
Spark 3.2 DS V2 Push-down 的最根本能力需要影響 Spark 的物理計劃,所有這一切發(fā)生在 V2ScanRelationPushDown 這個優(yōu)化器規(guī)則中。
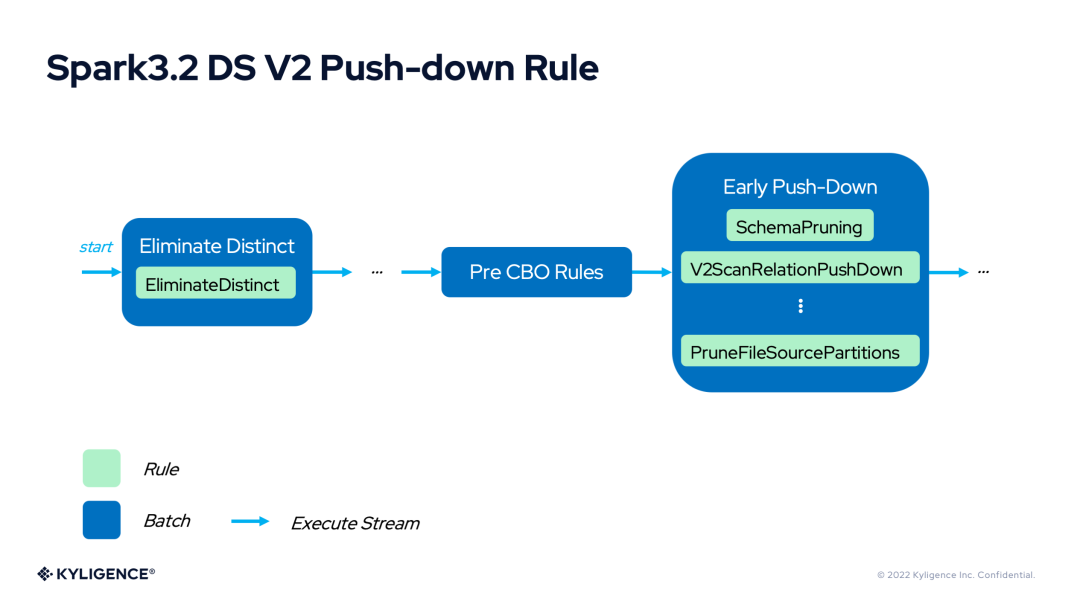
這個規(guī)則可以完成對列裁剪、Filter 下推、Aggregate 下推等功能的支持。下面對下推相關(guān)的功能進行簡單介紹。
1. Spark 3.2 DS V2 Filter Push-down
Filter 下推干的事情很簡單(為了行文方便,這里以 JDBC 數(shù)據(jù)源為例,后文不再贅述),那就是把 Filter 的計算交給數(shù)據(jù)源。因為數(shù)據(jù)源最清楚數(shù)據(jù)的結(jié)構(gòu)、數(shù)據(jù)的分布、數(shù)據(jù)的索引還有緩存等信息,,因此數(shù)據(jù)源計算往往有最優(yōu)的方案來處理。
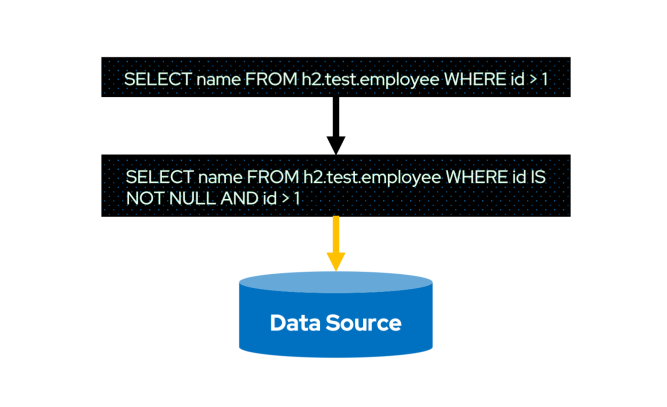
上圖是 Filter 下推的示意圖。細心的讀者會發(fā)現(xiàn) WHERE 條件中多了id IS NOT NULL,這里額外做個說明——這是 Spark 對執(zhí)行計劃優(yōu)化過程中添加的 Filter。所以真正下推到數(shù)據(jù)源的 SQL 未必是用戶輸入的原始 SQL。
既然 Filter 由數(shù)據(jù)源計算了,那么 Spark 就可以避免這些計算。更重要的是,可以減少磁盤 I/O 和網(wǎng)絡(luò) I/O,甚至減少 Spark Shuffle 的數(shù)據(jù)量。原先可能需要讀取一張表所有的數(shù)據(jù)文件,現(xiàn)在數(shù)據(jù)源也許只需要讀取幾個文件,甚至不用讀取數(shù)據(jù)了。Spark 得到了數(shù)據(jù)源返回的已經(jīng)執(zhí)行過 Filter 的數(shù)據(jù)后,再進行其他計算的初始數(shù)據(jù)量會有明顯的下降,這對于整個 Spark Job 的生命周期都是有效的。
不過,Spark 在實現(xiàn) Filter 下推的時候,用到的是 DS V1 的 Filter 表達式。DS V1 的 Filter 表達式有個缺陷,那就是只能表示基本的 Filter 表達式,無法表達復(fù)雜表達式。

例如,上圖中的id IS NOT NULL和id > 1是 DS V1 的 Filter 能夠表達的,但是cast(col as int) IS NOT NULL和cast(col as int) > 1卻是不行的。這會對最終的 Filter 下推產(chǎn)生影響,請看下圖。
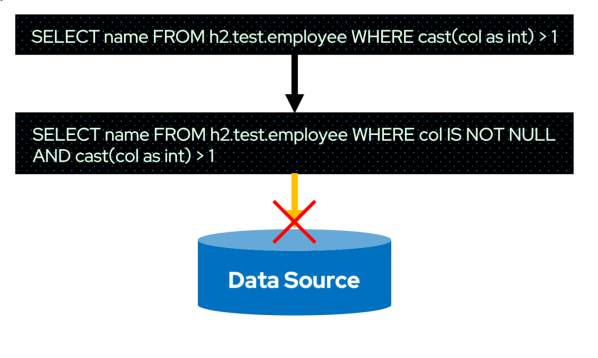
上圖中的 Cast 表達式與比較表達式組成的復(fù)雜表達式,DS V1 的 Filter 表達式就無法表達。雖然cast(col as int) > 1無法下推,但是col IS NOT NULL依然是可以下推的。
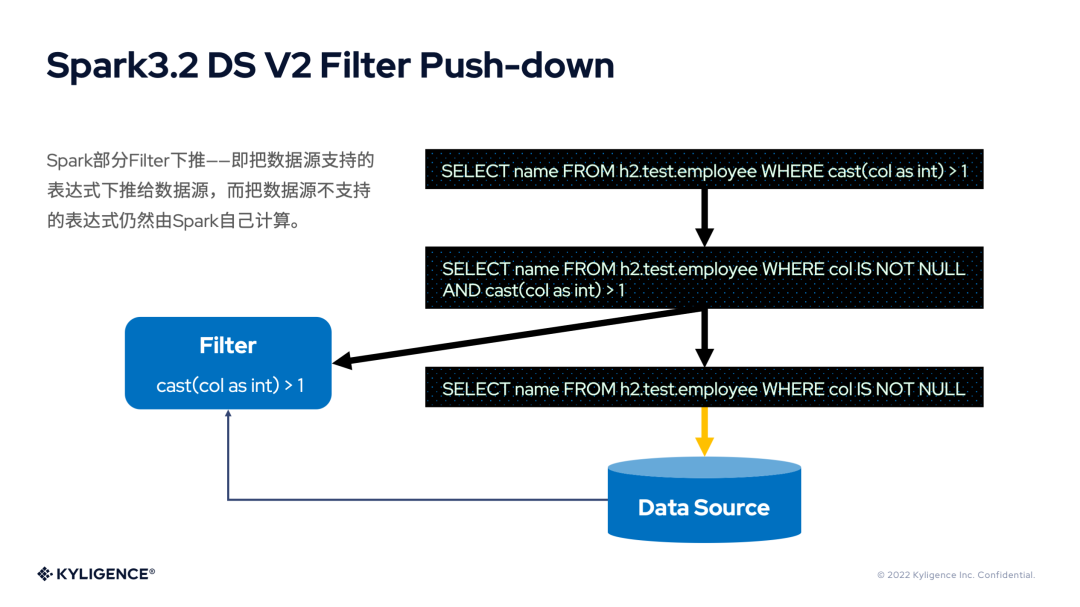
具體的辦法就是col IS NOT NULL交給數(shù)據(jù)源處理,而cast(col as int) > 1依然由 Spark 的 Filter 算子計算。其結(jié)果是顯而易見的——大量業(yè)務(wù)場景中使用的WHERE條件都無法下推,因而無法有效減少 I/O。因此,Spark 3.2 時的 DS V2 Filter Push-down 很難在生產(chǎn)環(huán)境發(fā)揮作用。
2. Spark 3.2 DS V2 Aggregate Push-down
Aggregate 下推是將 Aggregate 的計算交給數(shù)據(jù)源。例如,SUM(SALARY)由數(shù)據(jù)源計算。同樣因為數(shù)據(jù)源最清楚數(shù)據(jù)的結(jié)構(gòu)、數(shù)據(jù)的分布、數(shù)據(jù)的索引還有緩存等信息,因此數(shù)據(jù)源計算往往有最優(yōu)的方案來處理。
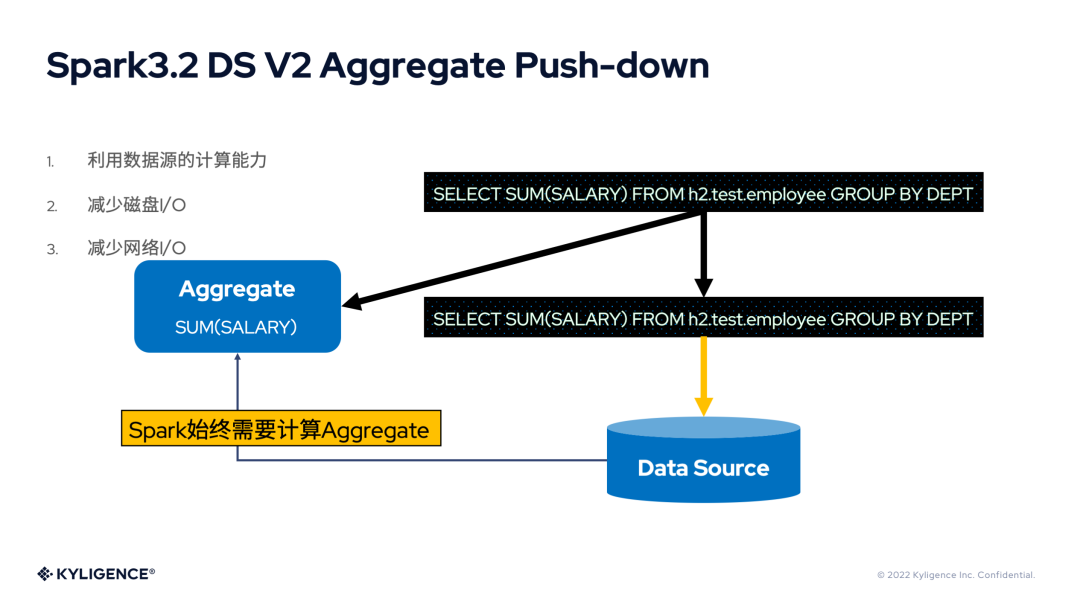
上圖是 Aggregate 下推的示意圖。細心的讀者會發(fā)現(xiàn),聚合既然已經(jīng)下推到數(shù)據(jù)源計算了,那么Spark 為什么依然會保留 Aggregate 算子?依然以SUM(SALARY)為例,當(dāng)數(shù)據(jù)源擁有多個 Partition 時,各個 Partition 返回到 Spark 的數(shù)據(jù)只是各個 Partition 分別計算得到的和,并不是最終需要的和。因此,Spark 需要再次通過 Sum 函數(shù)進行一次計算,所以 Aggregate 是需要保留的。
固執(zhí)點的讀者會說,如果 Partition 只有一個時呢?是不是不需要 Aggregate 算子了。是的,但是 Spark 3.2.0 最初實現(xiàn) Aggregate 下推時,只是功能實現(xiàn),還沒有更加細化。本文將在介紹 Spark 3.3.0 的 Aggregate 下推時,介紹這個優(yōu)化。
既然 Aggregate 由數(shù)據(jù)源計算了,那么 Spark 就可以避免這些計算。更重要的是,可以減少磁盤 I/O 和網(wǎng)絡(luò) I/O,甚至減少 Spark Shuffle 的數(shù)據(jù)量。原先可能需要讀取一張表所有的數(shù)據(jù)文件,現(xiàn)在數(shù)據(jù)源也許只需要讀取幾個文件,甚至不用讀取數(shù)據(jù)了。Spark 得到了數(shù)據(jù)源返回的已經(jīng)執(zhí)行了 Aggregate 的數(shù)據(jù)后,再進行其他計算的初始數(shù)據(jù)量會有明顯的下降,這對于整個 Spark Job 的生命周期都是有效的。但是 Spark 3.2.0 始終保留了 Aggregate 算子,勢必帶來計算冗余與開銷。
在表達式支持上,Aggregate 下推只支持 MIN、MAX、SUM、COUNT 四個聚合函數(shù),而且只支持對列進行聚合,不支持對復(fù)雜表達式的聚合。
3. Spark 3.2 DS V2 Push-down 的問題歸納
根據(jù)前面對 Spark3.2 DS V2 Push-down 現(xiàn)有下推功能的分析,我們知道了一些問題。但除此之外,它依然有很多功能上的缺失,例如 Limit 下推。下面列出我們需要去改進的地方:
只支持簡單 Filter 和Aggregate,導(dǎo)致無法在真實的業(yè)務(wù)場景應(yīng)用
SQL語法的不兼容性,導(dǎo)致無法在真實的業(yè)務(wù)場景應(yīng)用
Spark額外的 Aggregate 造成一定的開銷
不支持 Limit 下推
不支持 Top N 下推
不支持分頁下推
好了,有了以上分析,來看看 Kyligence 開源團隊是如何在 Spark 3.3.0 中完成對 DS V2 Push-down 的重構(gòu)與改進的。
#03
Spark 3.3 DS V2 Push-down
Kyligence 開源團隊經(jīng)過對 Spark3.2 DS V2 Push-down 框架的分析,發(fā)現(xiàn)打通任督二脈的關(guān)鍵有三點:
強大的 Catalyst 表達式 Translate 能力
通用的 DS V2 表達式標(biāo)準(zhǔn)
自由的 DS V2 表達式 Compile 能力
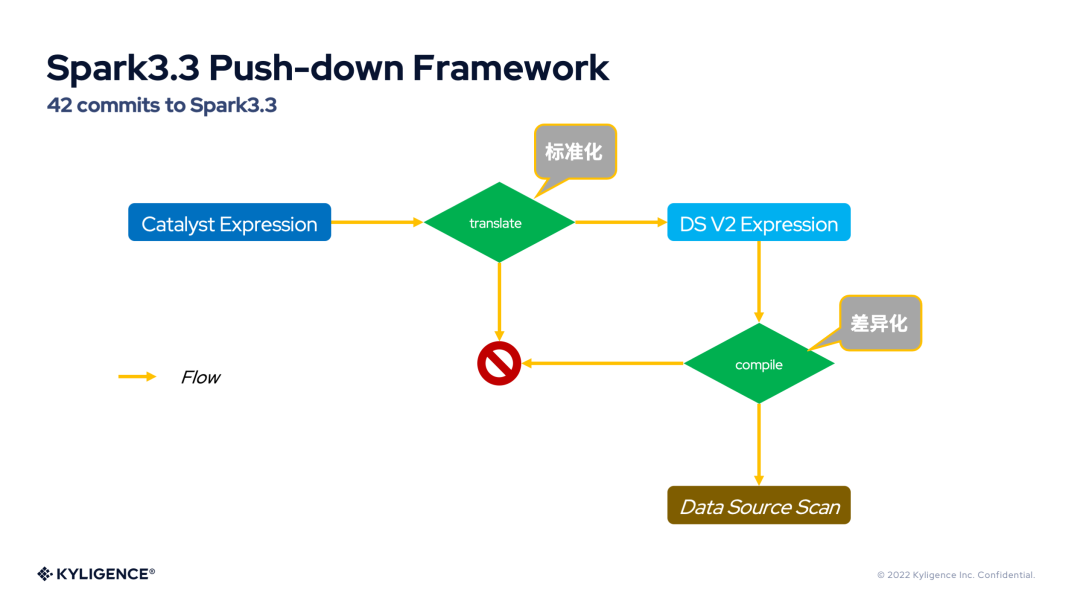
上圖是 Spark3.3 DS V2 Push-down 框架的示意圖。前兩點與 Catalyst 表達式的 translate 的標(biāo)準(zhǔn)化相關(guān),第三點則與 DS V2 表達式的 compile 的差異化相關(guān)。
如果上圖中的數(shù)據(jù)源為 JDBC,那么我們可以用下圖來表示 Spark3.3 DS V2 Push-down 框架。
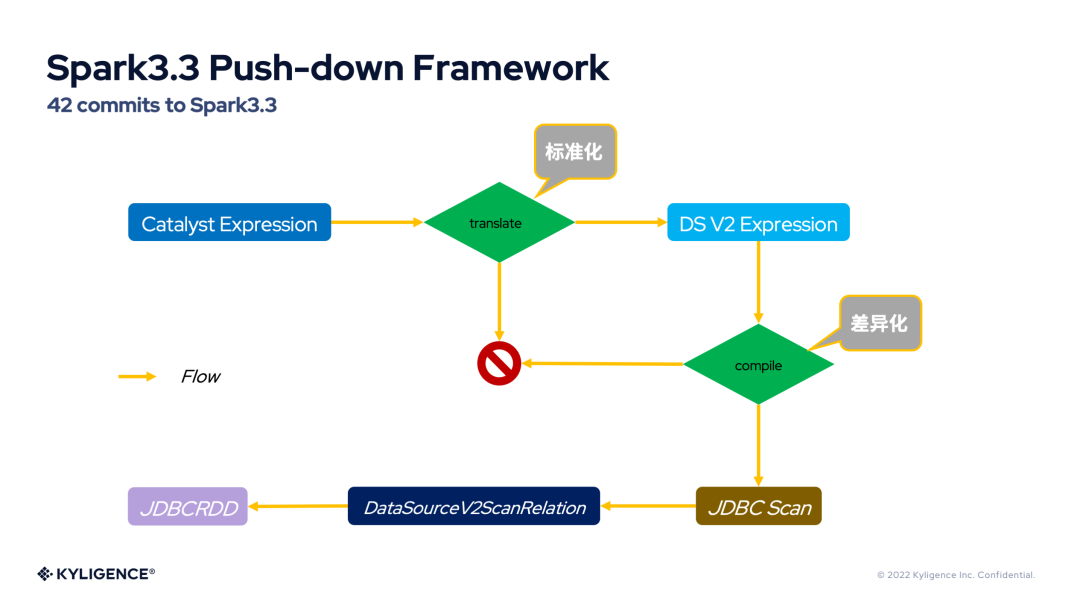
下面來看看 Spark3.3 DS V2 Push-down 框架是如何打通任督二脈的?
1. Catalyst Expression translate Framework
Catalyst 表達式翻譯框架(Catalyst Expression translate Framework)提供了強大的 Catalyst 表達式 Translate 能力。Catalyst 表達式翻譯框架提供了將各種 Catalyst 表達式翻譯為 DS V2 表達式的切入點,無論是計算表達式,布爾表達式等基礎(chǔ)表達式,還是 Filter 表達式,Aggregate 表達式,這些 Catalyst 表達式都可以被翻譯為 DS V2 表達式。下圖展示了 Catalyst 表達式翻譯框架的流程圖。
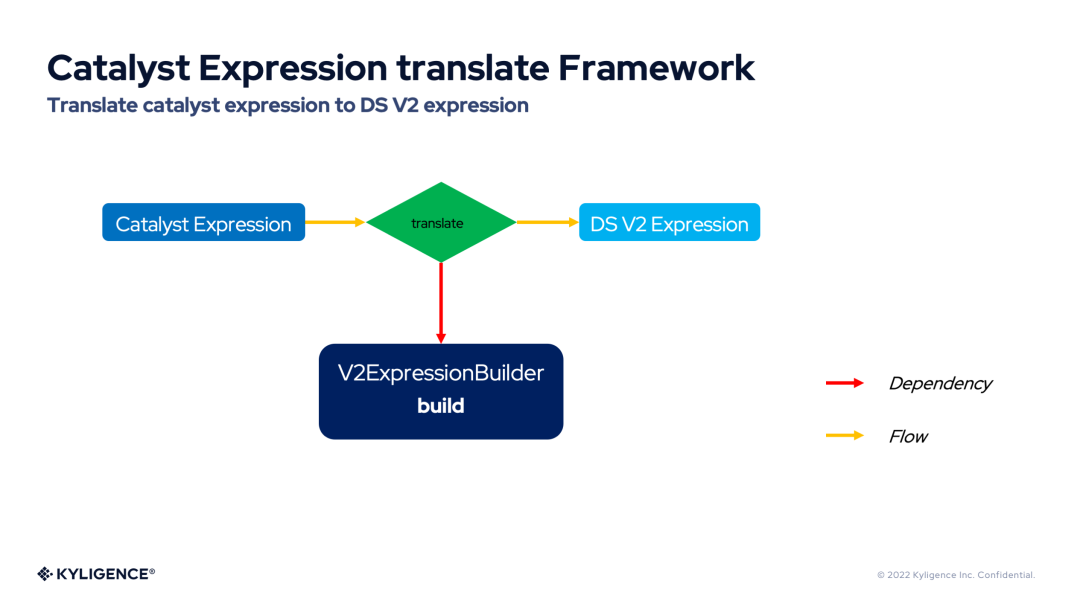
從上圖可以看到,Catalyst 表達式翻譯框架依賴于 V2ExpressionBuilder,表達式的翻譯工作都交給它來完成。
2. General DS V2 Expression Standard
DS V2 表達式是一種通用的表達式形式,作為標(biāo)準(zhǔn)。Filter,Aggregate 等算子都可以復(fù)用它們。
這里對主要的 DS V2 表達式進行介紹:
AggregateFunc:DS V2 聚合函數(shù)的統(tǒng)一接口,具體的實現(xiàn)有 Min,Max,Sum,Count,CountStar 和 Avg。這是最常用的聚合函數(shù),DS V2 為它們提供了度身定制的表達式。
GeneralAggregateFunc:AggregateFunc 的通用實現(xiàn),用來表示一些符合 ANSI SQL 標(biāo)準(zhǔn),但是使用頻率不那么高的聚合函數(shù)(例如:VAR_POP和VAR_SAMP)。
LiteralValue:DS V2 的字面量表達式,對應(yīng) Catalyst 的 Literal。
NamedReference:代表字段或者列的 DS V2 表達式接口,目前只有 FieldReference 一個實現(xiàn)。
FieldReference:DS V2 的字段表達式。
GeneralScalarExpression:DS V2 表達式的通用實現(xiàn),用于表示最廣泛的表達式。
Predicate:GeneralScalarExpression 的特殊實現(xiàn),用于代表 Filter 表達式。Spark 社區(qū)將逐步統(tǒng)一DS V1 與 V2 的 Filter 表達式 。
AlwaysTrue 和 AlwaysFalse:特殊的 Predicate,用于代表恒等于 true 或 false 的 Filter 表達式。
有了 DS V2 表達式的豐富表達能力,我們將 DS V2 Push-down 框架在 Spark 3.2 和 Spark 3.3 版本所支持的表達式或函數(shù)做個對比。
Supported Aggregate Functions
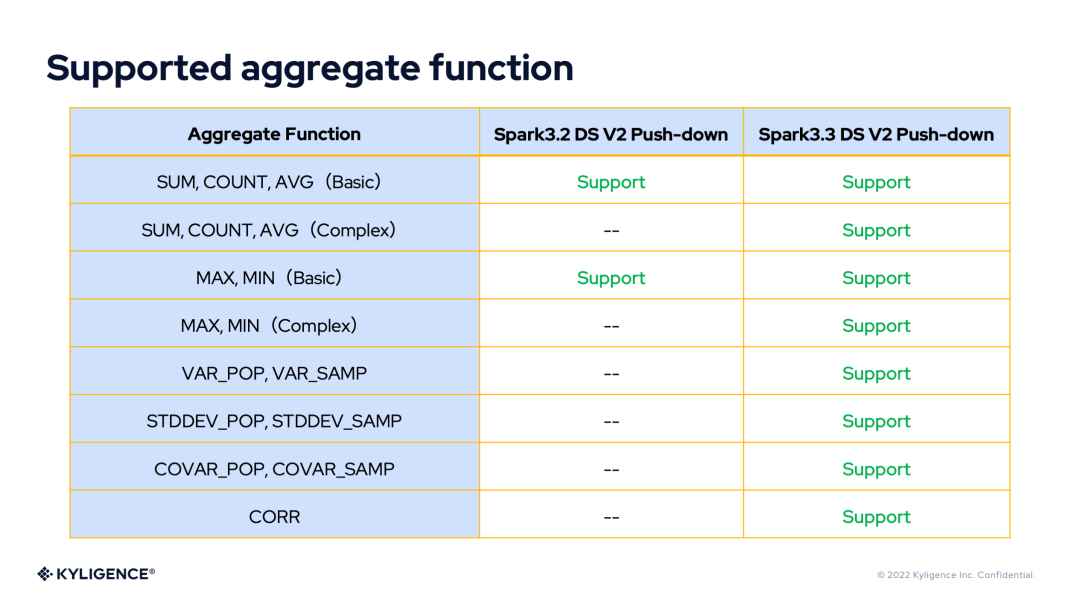
Supported Expressions
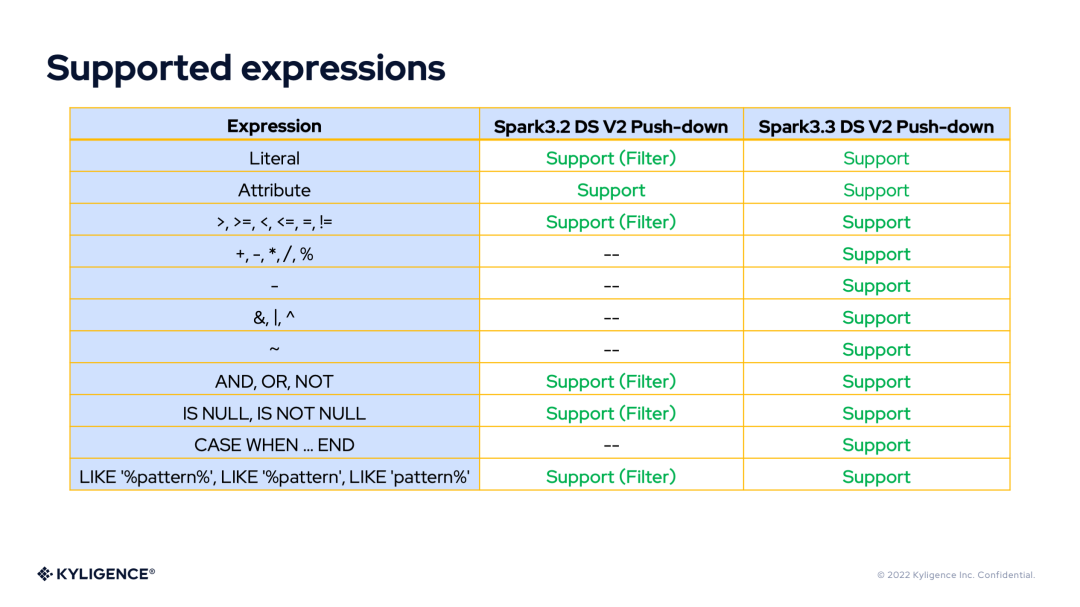
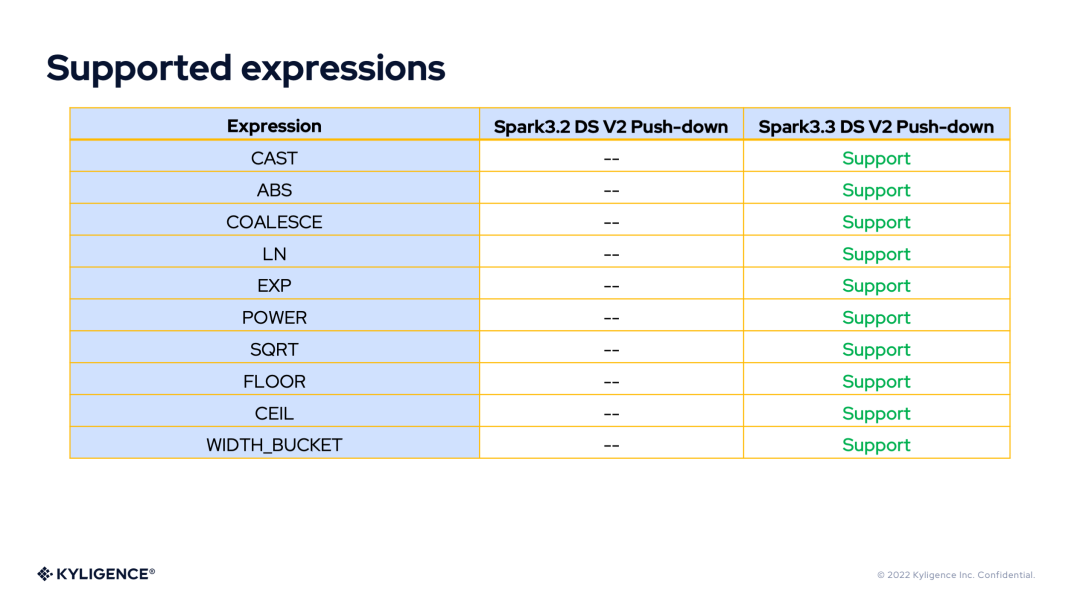
3. DS V2 Expression compile Framework
DS V2 表達式編譯框架(DS V2 Expression compile Framework)提供了將 DS V2 表達式自由靈活的編譯為 ANSI SQL 或 SQL 方言的能力。下圖展示了 DS V2 表達式編譯框架的流程圖。
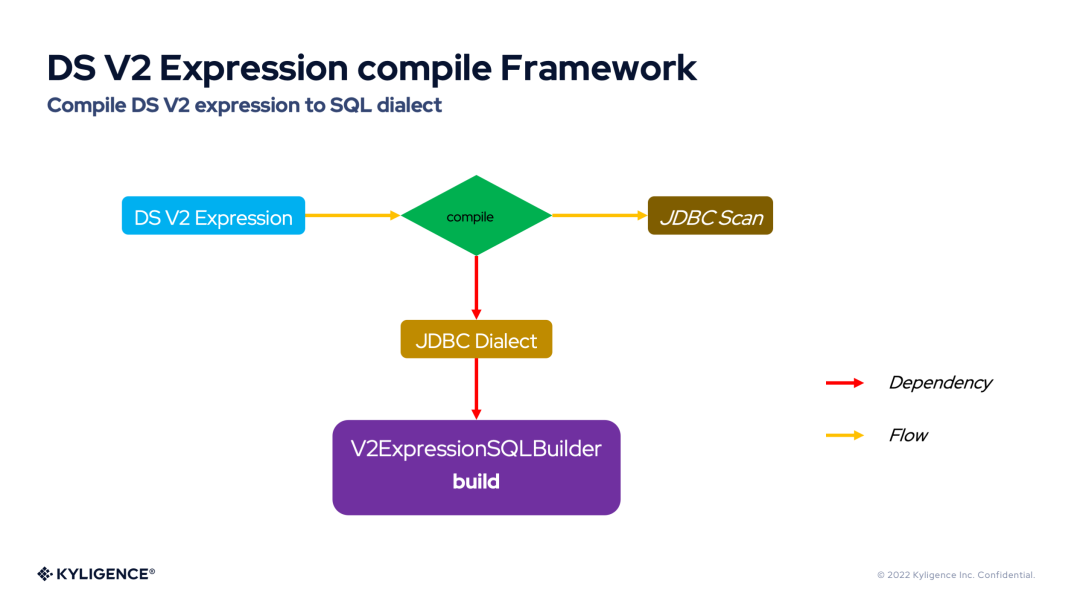
從上圖可以看到——編譯 DS V2 表達式依賴于 JDBC 方言(JDBC Dialect),默認的 JDBC 方言將 DS V2 表達式編譯為 ANSI SQL。Spark 內(nèi)置了很多 JDBC 方言,例如:H2Dialect,MySQLDialect。而 JDBC 方言對 DS V2 表達式的編譯實際又依賴于 V2ExpressionSQLBuilder,V2ExpressionSQLBuilder 內(nèi)部通過訪問者模式提供了對各類表達式的 compile 接口。因此,每個 JDBC 方言都可以靈活定制自己的 V2ExpressionSQLBuilder 行為,符合數(shù)據(jù)庫本身的語法特點。
4. Spark 3.3 DS V2 Filter Push-down
由于 Spark 3.3 DS V2 Push-down 框架有更加通用、豐富和靈活的 DS V2 表達式,因此 Spark3.3 DS V2 Filter Push-down 將可以下推更加豐富的 Filter 表達式。

因而,以前無法下推的 Filter 表達式也可以下推到數(shù)據(jù)源,就再也不用 Spark 做二次過濾了。
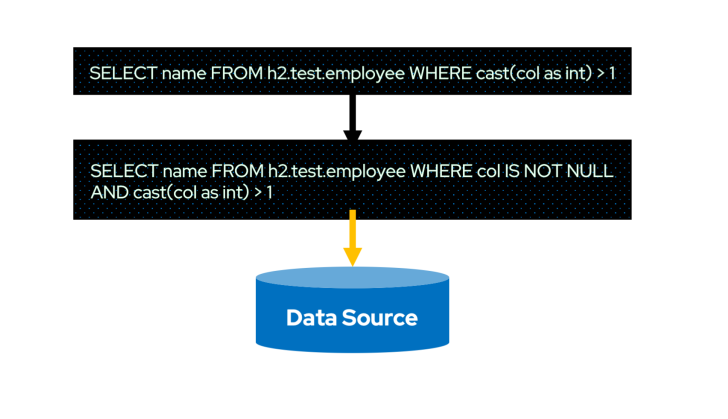
當(dāng)常見的 Filter 表達式都可以下推時,這將極大的減少 I/O,并促進在生產(chǎn)環(huán)境的應(yīng)用。
5. Spark 3.3 DS V2 Aggregate Push-down
同樣由于 Spark 3.3 DS V2 Push-down 框架有更加通用、豐富和靈活的 DS V2 表達式,因此 Spark 3.3 DS V2 Aggregate Push-down 將可以下推更加豐富的Aggregate表達式。

因而,以前無法下推的 Aggregate 表達式也可以下推到數(shù)據(jù)源。但是 Spark 3.2 DS V2 Aggregate Push-down 之前一直保留著 Aggregate 算子,所以這個算子的額外計算就顯得很不必要了。于是,Spark 3.3 DS V2 Aggregate Push-down 引入了聚合全下推(Aggregate Complete Push-down)和聚合部分下推(Aggregate Partial Push-down)。
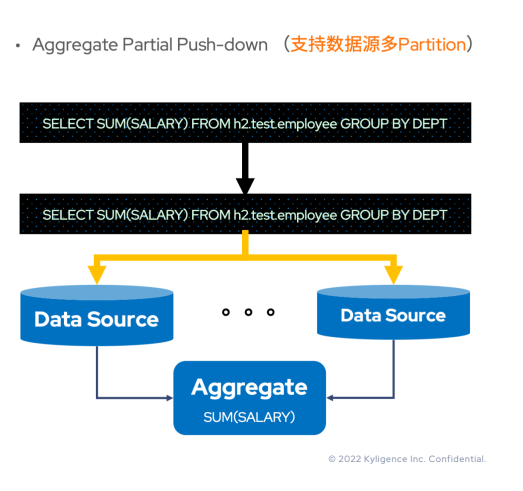
Aggregate Partial Push-down
即便所有的 Aggregate 表達式可以下推到數(shù)據(jù)源,那么 Aggregate 算子是否就真的不需要了?了解過 Hive 或者 Orc 的讀者應(yīng)當(dāng)知道——很多文件存儲本身是有 Partition 的概念。如果數(shù)據(jù)源有多個 Partition,并且SUM(SALARY)可以下推,那么 Spark 從多個分區(qū) Task 拿到多份結(jié)果后該如何處理?是不是還應(yīng)該求一次和?答案是肯定的。
既然 Aggregate 下推本身可以縮減 I/O,改進性能,那么還是需要下推的,所以這種下推后還需要由 Spark 進行 Aggregate 計算的 Aggregate 下推稱為聚合部分下推(Aggregate Partial Push-down)。
Aggregate Complete Push-down
與聚合部分下推相對應(yīng),當(dāng) Aggregate 可以下推到數(shù)據(jù)源并且存儲本身只有一個 Partition 時,也不需要 Spark 再進行額外的 Aggregate 計算了。此時,可以消除 Spark 進行 Aggregate 計算的開銷。這種下推后不再需要 Spark 進行 Aggregate 計算的 Aggregate 下推稱為聚合全下推(Aggregate Complete Push-down)。
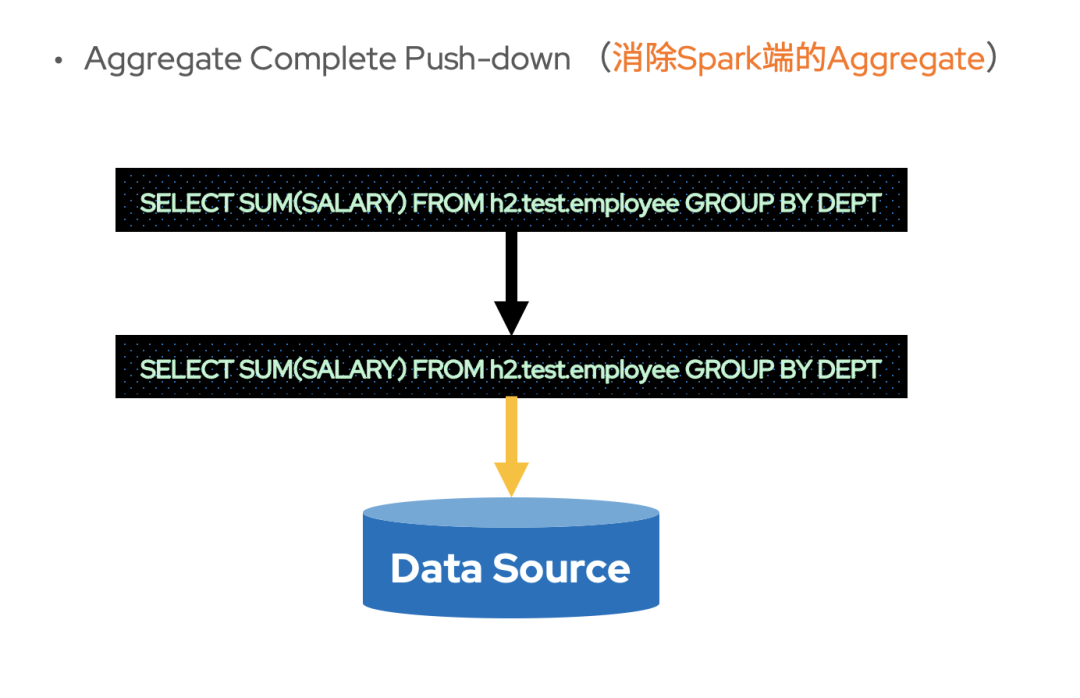
不過,在數(shù)據(jù)源擁有多 Partition 時,也未必不能夠聚合全下推。以SELECT SUM(SALARY) FROM h2.test.employee GROUP BY DEPT這條 SQL 為例,當(dāng) Partition 字段為DEPT的時候,各個分區(qū) Task 計算 Aggregate 得到的數(shù)據(jù)就是最終結(jié)果了。也就是說,當(dāng)分區(qū)字段與GROUP BY的 key 相同時,也是可以聚合全下推的。
6. Spark 3.3 DS V2 Limit Push-down
Limit 是最常用的語法之一,如果能將其下推到數(shù)據(jù)源,其數(shù)據(jù)量的縮減顯而易見,對于 I/O 和性能都有極大的優(yōu)化空間。Spark 3.3 支持了 Limit 的下推。不過其實現(xiàn)類似于 Spark 3.2 DS V2 Aggregate Push-down,保留了 Limit 算子。
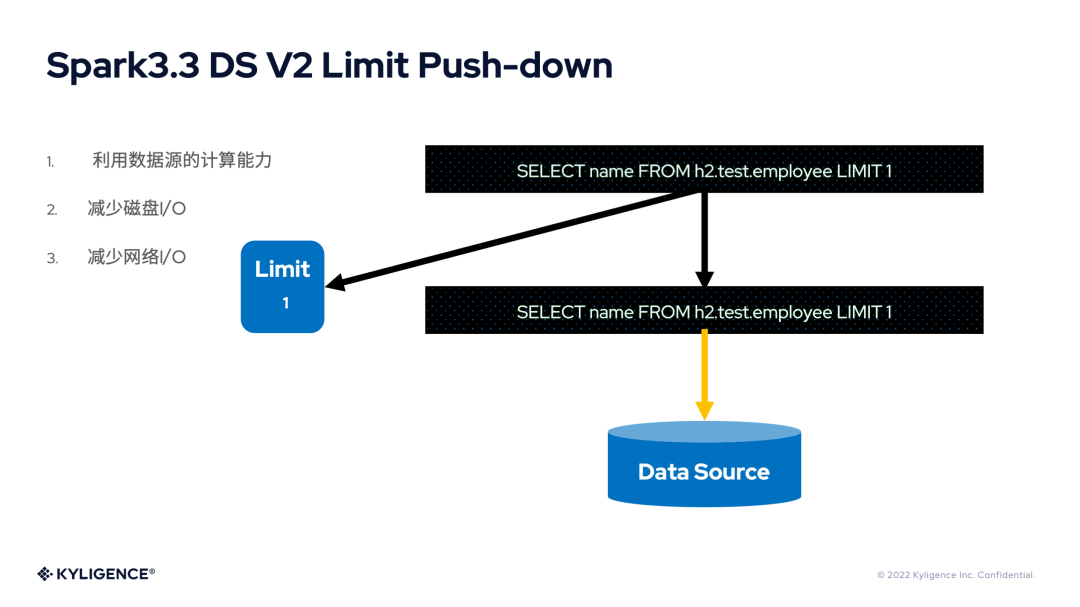
其實,在數(shù)據(jù)源單 Partition 的情況下,Limit 算子依然可以被優(yōu)化掉。由于 Spark 社區(qū)版本發(fā)布的關(guān)系,這部分功能應(yīng)該將在 Spark 3.4 版本中發(fā)布。
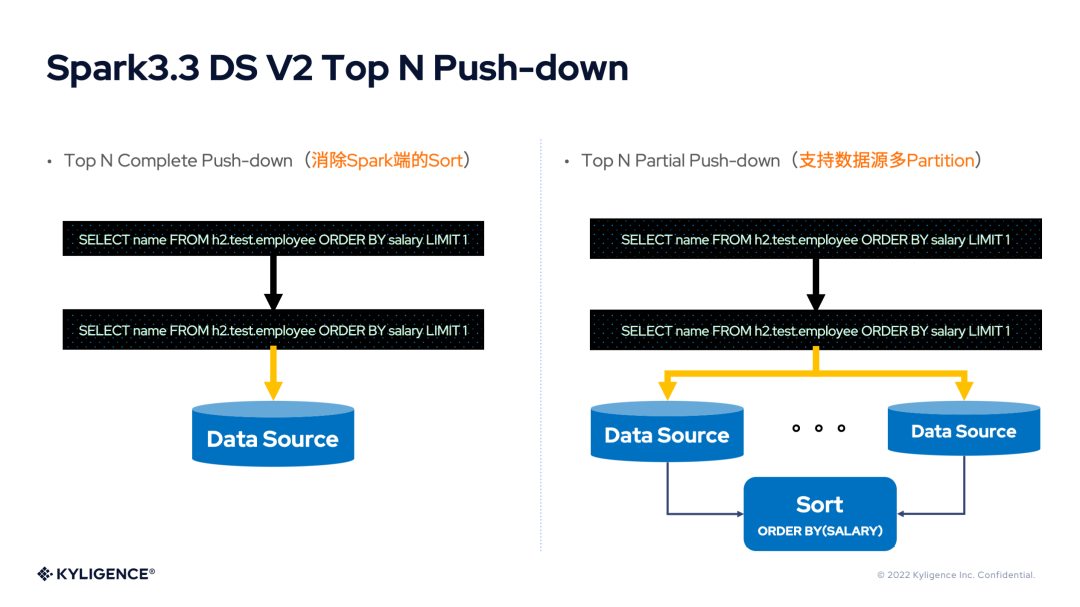
7. Spark 3.3 DS V2 Top N Push-down
Top N 查詢在業(yè)務(wù)場景中非常常見,但是 Spark 對于 Top N 查詢需要進行全局排序,當(dāng)數(shù)據(jù)量很大時,性能表現(xiàn)不佳!如果能對這里進行性能改進,那么將取得極佳的效果。Top N 查詢的處理根據(jù) Partition 的數(shù)量分為 Top N 部分下推(Top N Partial Push-down)和 Top N 全下推(Top N Complete Push-down),與 Spark 3.3 DS V2 Aggregate Push-down 非常相似。
8. Differences between Spark 3.2 and Spark 3.3
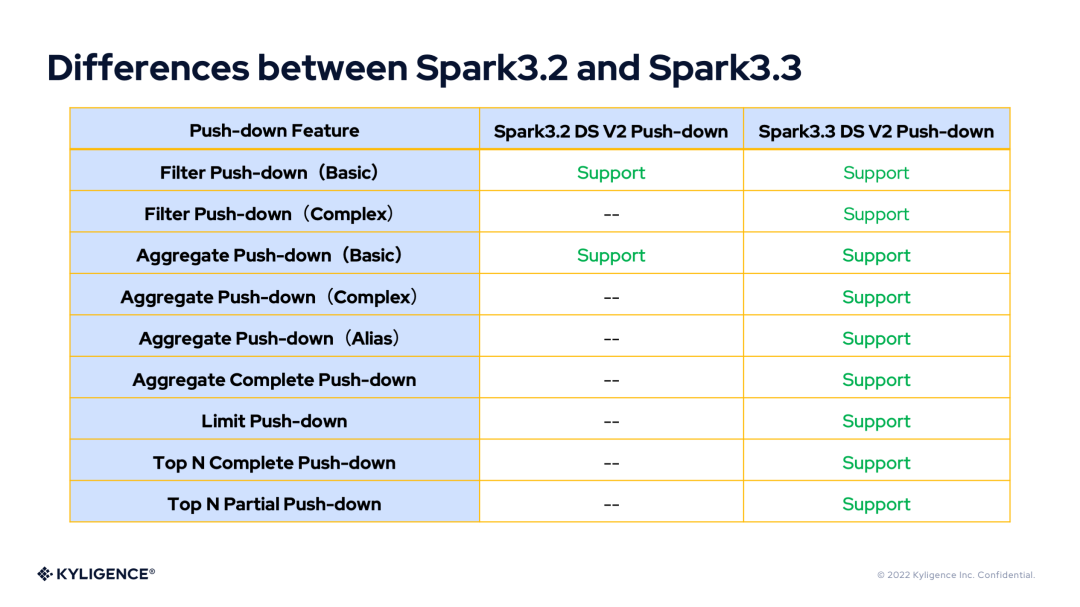
根據(jù)前面的介紹,下面用表格來對 Spark 3.2 DS V2 push-down 和 Spark 3.3 DS V2 push-down 的特性差異進行比較。
#04
Plan of Spark 3.4 DS V2 Push-down
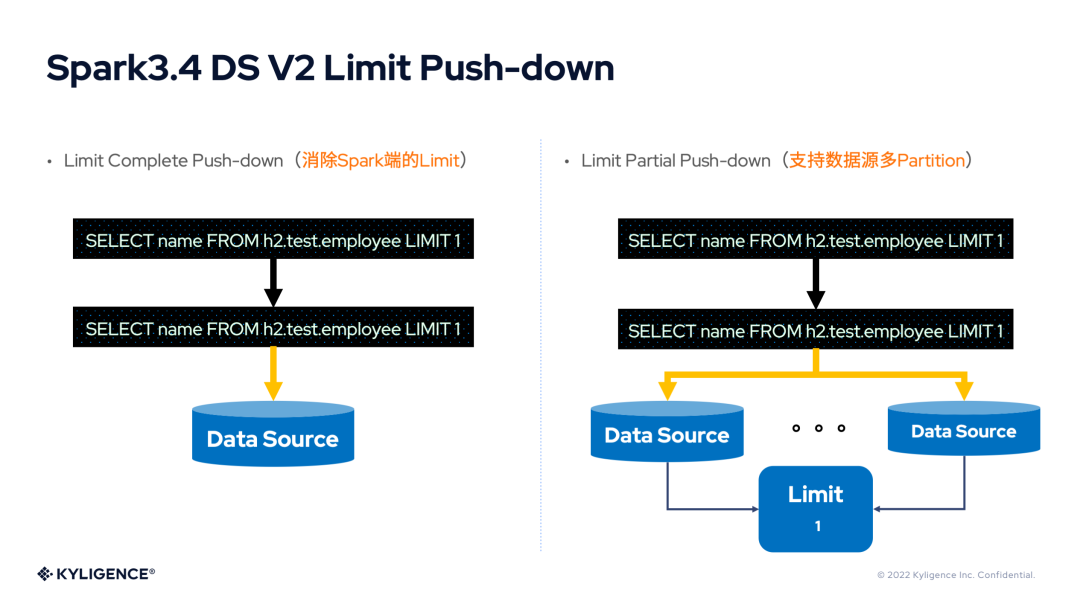
1. Spark 3.4 DS V2 Limit Push-down
盡管,Spark 3.3 提供了 Limit 的下推,但是保留著 Limit 算子,始終是一筆開銷。在 Spark 3.4 版本中將發(fā)布 Limit 部分下推(Limit Partial Push-down)和 Limit 全下推(Limit Complete Push-down)。
2. Spark 3.4 DS V2 Offset Push-down
由于 Spark 3.4 已經(jīng)完成了對 Offset 算子的支持,因此可以將 Offset 下推到數(shù)據(jù)源。其下推原理類似于 Limit。
3. Spark 3.4 DS V2 Paging Push-down
由于 Spark 3.4 已經(jīng)完成了對 Offset 算子的支持,業(yè)務(wù)場景已經(jīng)可以使用 Spark 完成分頁查詢了。如果將分頁查詢下推到數(shù)據(jù)源,必然有很大的收益。其下推原理類似于 Top N。
4. Spark 3.4 DS V2 Aggregate Push-down supports push down group by expressions without aggregate function.
目前,Spark 3.4 DS V2 Aggregate Push-down 不支持select key from tab group by key。這個功能將在 Spark 3.4 發(fā)布。
5. Spark 3.4 DS V2 Top N Push-down supports order by expressions
目前,Spark 3.3 DS V2 Top N Push-down 只支持 order by 字段。由于 Spark 版本發(fā)布的原因,這個功能將在 Spark 3.4 發(fā)布。
6. Spark 3.4 DS V2 supports more expression
在 Spark 3.4 版本中繼續(xù)擴充對表達式的支持,例如:字符串表達式和日期表達式等。
7. Spark 3.4 DS V2 supports UDF and UDAF
在 Spark 3.4 版本中增加對 UDF 的支持。此功能將繼續(xù)釋放外部開發(fā)者的自由度。
8. Spark 3.4 DS V2 supports more flexiable
在 Spark 3.4 版本中增加數(shù)據(jù)庫方言的更多靈活性,例如:決定哪些函數(shù)可以下推,注冊可以下推的 UDF 和 UDAF 等。
9. Orc/Parquet follows more features of DS V2 Push-down
目前,Orc,Parquet 等的下推,依然采用了早期的下推方案,可以將它們慢慢適配、遷移到新的下推框架中。
Kyligence 內(nèi)部使用了 Kylin、Spark、ClickHouse等多種開源技術(shù),Spark 3.3 DS V2 Push-down 能夠大大加速 Spark 對 Clickhouse 數(shù)據(jù)的查詢。如果想了解相關(guān)內(nèi)容,請大家點擊下方關(guān)注我們,我們后續(xù)將分享更多相關(guān)技術(shù)博客。
關(guān)于 Kyligence
上海跬智信息技術(shù)有限公司 (Kyligence) 由 Apache Kylin 創(chuàng)始團隊于 2016 年創(chuàng)辦,致力于打造下一代企業(yè)級智能多維數(shù)據(jù)庫,為企業(yè)簡化數(shù)據(jù)湖上的多維數(shù)據(jù)分析(OLAP)。通過 AI 增強的高性能分析引擎、統(tǒng)一 SQL 服務(wù)接口、業(yè)務(wù)語義層等功能,Kyligence 提供成本最優(yōu)的多維數(shù)據(jù)分析能力,支撐企業(yè)商務(wù)智能(BI)分析、靈活查詢和互聯(lián)網(wǎng)級數(shù)據(jù)服務(wù)等多類應(yīng)用場景,助力企業(yè)構(gòu)建更可靠的指標(biāo)體系,釋放業(yè)務(wù)自助分析潛力。
Kyligence 已服務(wù)中國、美國、歐洲及亞太的多個銀行、證券、保險、制造、零售等行業(yè)客戶,包括建設(shè)銀行、浦發(fā)銀行、招商銀行、平安銀行、寧波銀行、太平洋保險、中國銀聯(lián)、上汽、Costa、UBS、MetLife 等全球知名企業(yè),并和微軟、亞馬遜、華為、Tableau 等技術(shù)領(lǐng)導(dǎo)者達成全球合作伙伴關(guān)系。目前公司已經(jīng)在上海、北京、深圳、廈門、武漢及美國的硅谷、紐約、西雅圖等開設(shè)分公司或辦事機構(gòu)。

點擊「閱讀原文」了解更多