
Spark高頻面試題(建議收藏)
? ? ? ?
一、你是怎么理解Spark,它的特點(diǎn)是什么?
????????Spark是一個(gè)基于內(nèi)存的,用于大規(guī)模數(shù)據(jù)處理(離線計(jì)算、實(shí)時(shí)計(jì)算、快速查詢(交互式查詢))的統(tǒng)一分析引擎。
????????它內(nèi)部的組成模塊,包含SparkCore,SparkSQL,SparkStreaming,SparkMLlib,SparkGraghx等...
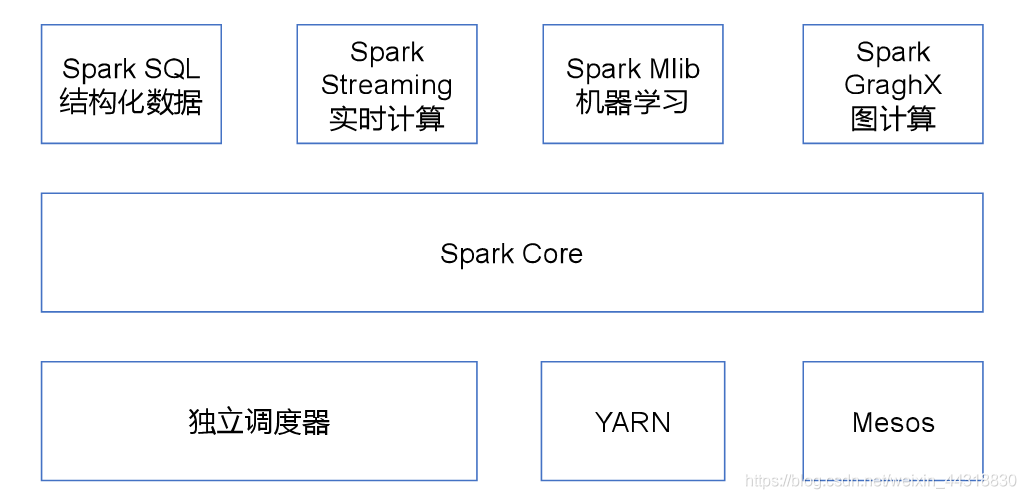 ????????它的特點(diǎn):
????????它的特點(diǎn):
快
????????Spark計(jì)算速度是MapReduce計(jì)算速度的10-100倍
易用
????????MR支持1種計(jì)算模型,Spsark支持更多的計(jì)算模型(算法多)
通用
????????Spark 能夠進(jìn)行離線計(jì)算、交互式查詢(快速查詢)、實(shí)時(shí)計(jì)算、機(jī)器學(xué)習(xí)、圖計(jì)算
兼容性
??????? Spark支持大數(shù)據(jù)中的Yarn調(diào)度,支持mesos。可以處理hadoop計(jì)算的數(shù)據(jù)。
????????
二、Spark有幾種部署方式,請(qǐng)分別簡(jiǎn)要論述
??????? 1) Local:運(yùn)行在一臺(tái)機(jī)器上,通常是練手或者測(cè)試環(huán)境。
??????? 2)Standalone:構(gòu)建一個(gè)基于Mster+Slaves的資源調(diào)度集群,Spark任務(wù)提交給Master運(yùn)行。是Spark自身的一個(gè)調(diào)度系統(tǒng)。
??????? 3)Yarn: Spark客戶端直接連接Yarn,不需要額外構(gòu)建Spark集群。有yarn-client和yarn-cluster兩種模式,主要區(qū)別在于:Driver程序的運(yùn)行節(jié)點(diǎn)。
??????? 4)Mesos:國(guó)內(nèi)大環(huán)境比較少用。
????????
三、Spark提交作業(yè)的參數(shù)
????????因?yàn)槲覀僑park任務(wù)是采用的Shell腳本進(jìn)行提交,所以一定會(huì)涉及到幾個(gè)重要的參數(shù),而這個(gè)也是在面試的時(shí)候容易被考察到的“細(xì)節(jié)”。
executor-cores?——?每個(gè)executor使用的內(nèi)核數(shù),默認(rèn)為1,官方建議2-5個(gè),我們企業(yè)是4個(gè)
num-executors?——?啟動(dòng)executors的數(shù)量,默認(rèn)為2
executor-memory?——?executor內(nèi)存大小,默認(rèn)1G
driver-cores?——?driver使用內(nèi)核數(shù),默認(rèn)為1
driver-memory?——?driver內(nèi)存大小,默認(rèn)512M
????????
四、簡(jiǎn)述Spark的作業(yè)提交流程
??????? Spark的任務(wù)提交方式實(shí)際上有兩種,分別是YarnClient模式和YarnCluster模式。大家在回答這個(gè)問(wèn)題的時(shí)候,也需要分類去介紹。千萬(wàn)不要被冗長(zhǎng)的步驟嚇到,一定要學(xué)會(huì)總結(jié)差異,發(fā)現(xiàn)規(guī)律,通過(guò)圖形去增強(qiáng)記憶。
YarnClient ?運(yùn)行模式介紹
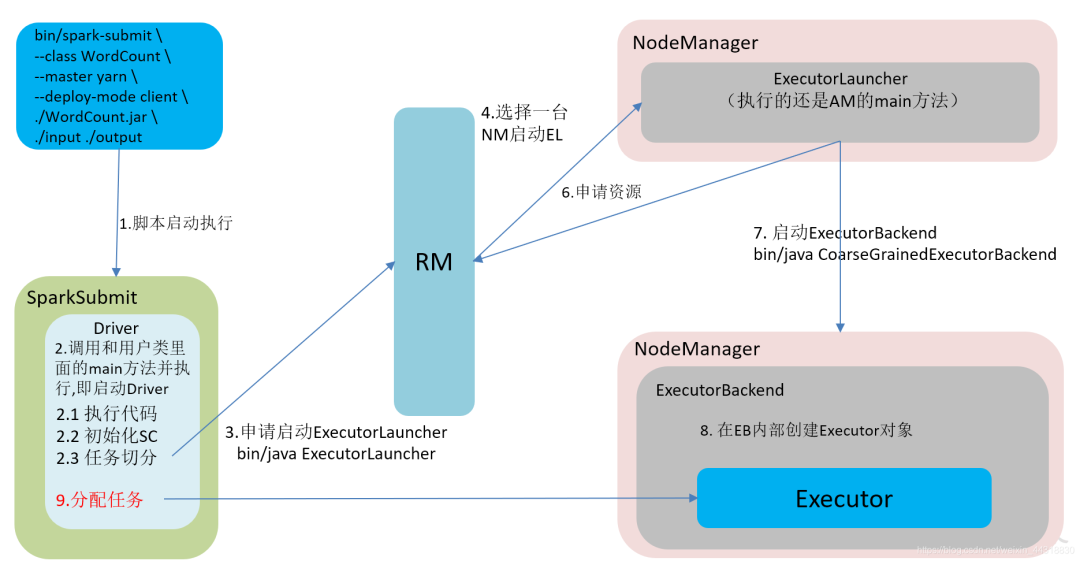 ????????在YARN Client模式下,Driver在任務(wù)提交的本地機(jī)器上運(yùn)行,Driver啟動(dòng)后會(huì)和ResourceManager通訊申請(qǐng)啟動(dòng)ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動(dòng)ApplicationMaster,此時(shí)的ApplicationMaster的功能相當(dāng)于一個(gè)ExecutorLaucher,只負(fù)責(zé)向ResourceManager申請(qǐng)Executor內(nèi)存。
????????在YARN Client模式下,Driver在任務(wù)提交的本地機(jī)器上運(yùn)行,Driver啟動(dòng)后會(huì)和ResourceManager通訊申請(qǐng)啟動(dòng)ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動(dòng)ApplicationMaster,此時(shí)的ApplicationMaster的功能相當(dāng)于一個(gè)ExecutorLaucher,只負(fù)責(zé)向ResourceManager申請(qǐng)Executor內(nèi)存。
??????? ResourceManager接到ApplicationMaster的資源申請(qǐng)后會(huì)分配container,然后ApplicationMaster在資源分配指定的NodeManager上啟動(dòng)Executor進(jìn)程,Executor進(jìn)程啟動(dòng)后會(huì)向Driver反向注冊(cè),Executor全部注冊(cè)完成后Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時(shí),觸發(fā)一個(gè)job,并根據(jù)寬依賴開始劃分stage,每個(gè)stage生成對(duì)應(yīng)的taskSet,之后將task分發(fā)到各個(gè)Executor上執(zhí)行。????????
YarnCluster 模式介紹
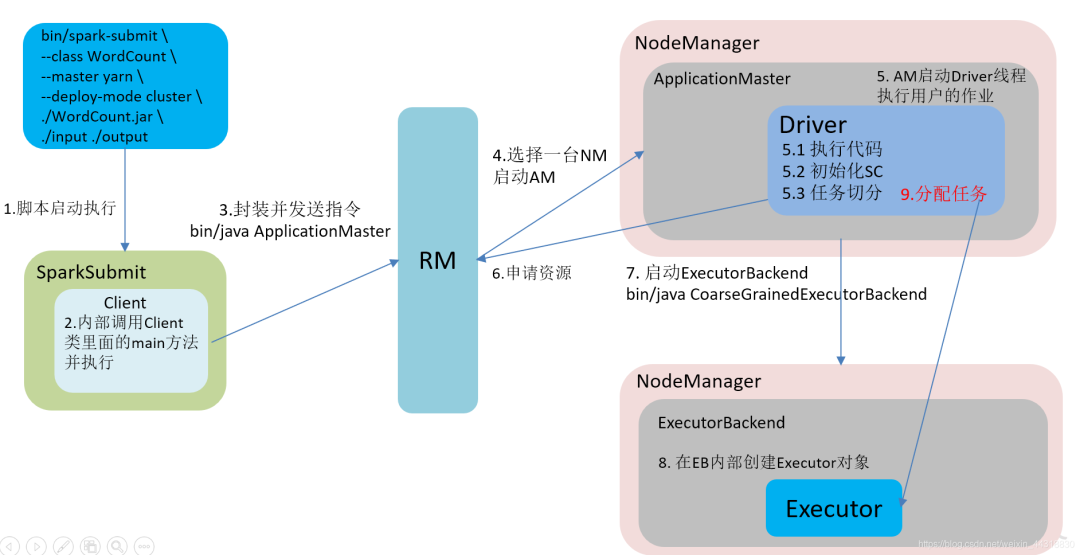 ???????? 在YARN Cluster模式下,任務(wù)提交后會(huì)和ResourceManager通訊申請(qǐng)啟動(dòng)ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動(dòng)ApplicationMaster,此時(shí)的ApplicationMaster就是Driver。
???????? 在YARN Cluster模式下,任務(wù)提交后會(huì)和ResourceManager通訊申請(qǐng)啟動(dòng)ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動(dòng)ApplicationMaster,此時(shí)的ApplicationMaster就是Driver。
??????? Driver啟動(dòng)后向ResourceManager申請(qǐng)Executor內(nèi)存,ResourceManager接到ApplicationMaster的資源申請(qǐng)后會(huì)分配container,然后在合適的NodeManager上啟動(dòng)Executor進(jìn)程,Executor進(jìn)程啟動(dòng)后會(huì)向Driver反向注冊(cè),Executor全部注冊(cè)完成后Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時(shí),觸發(fā)一個(gè)job,并根據(jù)寬依賴開始劃分stage,每個(gè)stage生成對(duì)應(yīng)的taskSet,之后將task分發(fā)到各個(gè)Executor上執(zhí)行。
????????
五、你是如何理解Spark中血統(tǒng)(RDD)的概念?它的作用是什么?
??????? RDD 可是Spark中最基本的數(shù)據(jù)抽象,我想就算面試不被問(wèn)到,那自己是不是也應(yīng)該非常清楚呢!
????????下面提供菌哥的回答,供大家參考:
概念
????????RDD是彈性分布式數(shù)據(jù)集,是Spark中最基本的數(shù)據(jù)抽象,代表一個(gè)不可變、可分區(qū)、里面的元素可并行計(jì)算 的集合。
作用
????????提供了一個(gè)抽象的數(shù)據(jù)模型,將具體的應(yīng)用邏輯表達(dá)為一系列轉(zhuǎn)換操作(函數(shù))。另外不同RDD之間的轉(zhuǎn)換操作之間還可以形成依賴關(guān)系,進(jìn)而實(shí)現(xiàn)管道化,從而避免了中間結(jié)果的存儲(chǔ),大大降低了數(shù)據(jù)復(fù)制、磁盤IO和序列化開銷,并且還提供了更多的API(map/reduec/filter/groupBy...)
????????如果還想錦上添花,可以添上這一句:
“RDD在Lineage依賴方面分為兩種Narrow Dependencies與Wide Dependencies,用來(lái)解決數(shù)據(jù)容錯(cuò)時(shí)的高效性以及劃分任務(wù)時(shí)候起到重要作用
”
六、簡(jiǎn)述Spark的寬窄依賴,以及Spark如何劃分stage,每個(gè)stage又根據(jù)什么決定task個(gè)數(shù)?
????????Spark的寬窄依賴問(wèn)題是SparkCore部分的重點(diǎn)考察內(nèi)容,多數(shù)出現(xiàn)在筆試中,大家需要注意。
????????窄依賴:父RDD的一個(gè)分區(qū)只會(huì)被子RDD的一個(gè)分區(qū)依賴
????????寬依賴:父RDD的一個(gè)分區(qū)會(huì)被子RDD的多個(gè)分區(qū)依賴(涉及到shuffle)
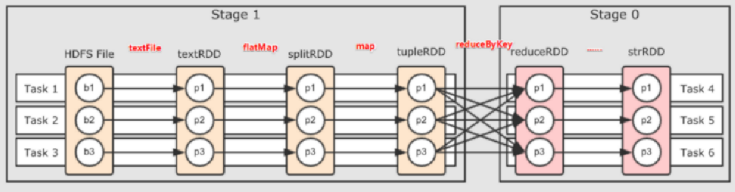
????????那Stage是如何劃分的呢?
????????根據(jù)RDD之間的依賴關(guān)系的不同將Job劃分成不同的Stage,遇到一個(gè)寬依賴則劃分一個(gè)Stage。
????????每個(gè)stage又根據(jù)什么決定task個(gè)數(shù)?
??????? Stage是一個(gè)TaskSet,將Stage根據(jù)分區(qū)數(shù)劃分成一個(gè)個(gè)的Task。
????????這里為了方便大家理解,貼上一張過(guò)程圖
七、列舉Spark常用的transformation和action算子,有哪些算子會(huì)導(dǎo)致Shuffle?
????????我們?cè)赟park開發(fā)過(guò)程中,避不開與各種算子打交道,其中Spark 算子分為transformation 和 action 算子,下面列出一些常用的算子,具體的功能還需要小伙伴們自行去了解。
transformation
map
mapRartition
flatMap
filter
?...
action
reduce
collect
first
take
...
????????如果面試官問(wèn)你,那小伙幾,有哪些會(huì)引起Shuffle過(guò)程的Spark算子呢?
????????你只管自信的回答:
reduceByKey groupByKey ...ByKey
八、reduceByKey與groupByKey的區(qū)別,哪一種更具優(yōu)勢(shì)?
????????既然你上面都提到 reduceByKey 和groupByKey ?,那哪一種更具優(yōu)勢(shì),你能簡(jiǎn)單分析一下嗎?
????????能問(wèn)這樣的問(wèn)題,已經(jīng)暗示面試官的水平不低了,那么我們?cè)撊绾位卮鹉兀?/p>
????????reduceByKey:按照key進(jìn)行聚合,在shuffle之前有combine(預(yù)聚合)操作,返回結(jié)果是RDD[k,v]。
????????groupByKey:按照key進(jìn)行分組,直接進(jìn)行shuffle
????????所以,在實(shí)際開發(fā)過(guò)程中,reduceByKey比groupByKey,更建議使用。但是需要注意是否會(huì)影響業(yè)務(wù)邏輯。
????????
九、Repartition和Coalesce 的關(guān)系與區(qū)別,能簡(jiǎn)單說(shuō)說(shuō)嗎?
????????這道題就已經(jīng)開始摻和有“源碼”的味道了,為什么呢?
??????? 1)關(guān)系:
????????兩者都是用來(lái)改變RDD的partition數(shù)量的,repartition底層調(diào)用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
??????? 2)區(qū)別:
??????? repartition一定會(huì)發(fā)生shuffle,coalesce 根據(jù)傳入的參數(shù)來(lái)判斷是否發(fā)生shuffle。
????????一般情況下增大rdd的partition數(shù)量使用repartition,減少partition數(shù)量時(shí)使用coalesce。
????????
十、簡(jiǎn)述下Spark中的緩存(cache和persist)與checkpoint機(jī)制,并指出兩者的區(qū)別和聯(lián)系
????????關(guān)于Spark緩存和檢查點(diǎn)的區(qū)別,大致可以從這3個(gè)角度去回答:
位置
????????Persist 和 Cache將數(shù)據(jù)保存在內(nèi)存,Checkpoint將數(shù)據(jù)保存在HDFS
生命周期
??????? Persist 和 Cache ?程序結(jié)束后會(huì)被清除或手動(dòng)調(diào)用unpersist方法,Checkpoint永久存儲(chǔ)不會(huì)被刪除。
RDD依賴關(guān)系
??????? Persist 和 Cache,不會(huì)丟掉RDD間的依賴鏈/依賴關(guān)系,CheckPoint會(huì)斬?cái)嘁蕾囨湣?/p>
????????
十一、簡(jiǎn)述Spark中共享變量(廣播變量和累加器)的基本原理與用途
????????關(guān)于Spark中的廣播變量和累加器的基本原理和用途,答案較為固定,大家無(wú)需刻意去記憶。
????????累加器(accumulator)是Spark中提供的一種分布式的變量機(jī)制,其原理類似于mapreduce,即分布式的改變,然后聚合這些改變。累加器的一個(gè)常見用途是在調(diào)試時(shí)對(duì)作業(yè)執(zhí)行過(guò)程中的事件進(jìn)行計(jì)數(shù)。
????????廣播變量是在每個(gè)機(jī)器上緩存一份,不可變,只讀的,相同的變量,該節(jié)點(diǎn)每個(gè)任務(wù)都能訪問(wèn),起到節(jié)省資源和優(yōu)化的作用。它通常用來(lái)高效分發(fā)較大的對(duì)象。
十二、當(dāng)Spark涉及到數(shù)據(jù)庫(kù)的操作時(shí),如何減少Spark運(yùn)行中的數(shù)據(jù)庫(kù)連接數(shù)?
????????嗯,有點(diǎn)“調(diào)優(yōu)”的味道,感覺真正的“風(fēng)暴”即將到來(lái),這道題還是很好回答的,我們只需要減少連接數(shù)據(jù)庫(kù)的次數(shù)即可。
????????使用foreachPartition代替foreach,在foreachPartition內(nèi)獲取數(shù)據(jù)庫(kù)的連接。????????
十三、能介紹下你所知道和使用過(guò)的Spark調(diào)優(yōu)嗎?
????????恐怖如斯,該來(lái)的還是會(huì)來(lái)的,慶幸自己看了菌哥的面試殺招,絲毫不慌:????????
資源參數(shù)調(diào)優(yōu)
num-executors:設(shè)置Spark作業(yè)總共要用多少個(gè)Executor進(jìn)程來(lái)執(zhí)行 executor-memory:設(shè)置每個(gè)Executor進(jìn)程的內(nèi)存 executor-cores:設(shè)置每個(gè)Executor進(jìn)程的CPU core數(shù)量 driver-memory:設(shè)置Driver進(jìn)程的內(nèi)存 spark.default.parallelism:設(shè)置每個(gè)stage的默認(rèn)task數(shù)量 ...
開發(fā)調(diào)優(yōu)
避免創(chuàng)建重復(fù)的RDD 盡可能復(fù)用同一個(gè)RDD 對(duì)多次使用的RDD進(jìn)行持久化 盡量避免使用shuffle類算子 使用map-side預(yù)聚合的shuffle操作 使用高性能的算子
“①使用reduceByKey/aggregateByKey替代groupByKey
②使用mapPartitions替代普通map?
③使用foreachPartitions替代foreach?
④使用filter之后進(jìn)行coalesce操作
⑤使用repartitionAndSortWithinPartitions替代repartition與sort類操作
”
廣播大變量
“在算子函數(shù)中使用到外部變量時(shí),默認(rèn)情況下,Spark會(huì)將該變量復(fù)制多個(gè)副本,通過(guò)網(wǎng)絡(luò)傳輸?shù)絫ask中,此時(shí)每個(gè)task都有一個(gè)變量副本。如果變量本身比較大的話(比如100M,甚至1G),那么大量的變量副本在網(wǎng)絡(luò)中傳輸?shù)男阅荛_銷,以及在各個(gè)節(jié)點(diǎn)的Executor中占用過(guò)多內(nèi)存導(dǎo)致的頻繁GC(垃圾回收),都會(huì)極大地影響性能。
”
使用Kryo優(yōu)化序列化性能 優(yōu)化數(shù)據(jù)結(jié)構(gòu)
“在可能以及合適的情況下,使用占用內(nèi)存較少的數(shù)據(jù)結(jié)構(gòu),但是前提是要保證代碼的可維護(hù)性。
”
????????如果能夠盡可能的把這些要點(diǎn)說(shuō)出來(lái),我想面試官可能就一個(gè)想法:

十四、如何使用Spark實(shí)現(xiàn)TopN的獲取(描述思路或使用偽代碼)?
????????能讓你使用偽代碼來(lái)描述這已經(jīng)非常“苛刻”了,但是不慌,這里提供3種思路供大家參考:
方法1:
????????(1)按照key對(duì)數(shù)據(jù)進(jìn)行聚合(groupByKey)
????????(2)將value轉(zhuǎn)換為數(shù)組,利用scala的sortBy或者sortWith進(jìn)行排序(mapValues)
????????注意:當(dāng)數(shù)據(jù)量太大時(shí),會(huì)導(dǎo)致OOM
方法2:
????????(1)取出所有的key
????????(2)對(duì)key進(jìn)行迭代,每次取出一個(gè)key利用spark的排序算子進(jìn)行排序
方法3:
????????(1)自定義分區(qū)器,按照key進(jìn)行分區(qū),使不同的key進(jìn)到不同的分區(qū)
????????(2)對(duì)每個(gè)分區(qū)運(yùn)用spark的排序算子進(jìn)行排序
--end--