
史上最全Zookeeper核心原理
點(diǎn)擊關(guān)注公眾號(hào),Java干貨及時(shí)送達(dá)

真香!24W字的Java面試手冊(cè)(點(diǎn)擊查看)
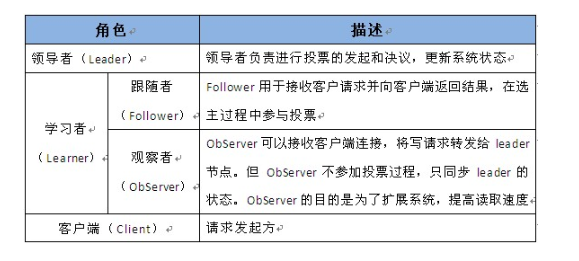
1、Zookeeper的角色
? 領(lǐng)導(dǎo)者(leader),負(fù)責(zé)進(jìn)行投票的發(fā)起和決議,更新系統(tǒng)狀態(tài)
? 學(xué)習(xí)者(learner),包括跟隨者(follower)和觀察者(observer),follower用于接受客戶端請(qǐng)求并想客戶端返回結(jié)果,在選主過(guò)程中參與投票
? Observer可以接受客戶端連接,將寫(xiě)請(qǐng)求轉(zhuǎn)發(fā)給leader,但observer不參加投票過(guò)程,只同步leader的狀態(tài),observer的目的是為了擴(kuò)展系統(tǒng),提高讀取速度
? 客戶端(client),請(qǐng)求發(fā)起方

? Zookeeper的核心是原子廣播,這個(gè)機(jī)制保證了各個(gè)Server之間的同步。實(shí)現(xiàn)這個(gè)機(jī)制的協(xié)議叫做Zab協(xié)
議。Zab協(xié)議有兩種模式,它們分別是恢復(fù)模式(選主)和廣播模式(同步)。當(dāng)服務(wù)啟動(dòng)或者在領(lǐng)導(dǎo)者
崩潰后,Zab就進(jìn)入了恢復(fù)模式,當(dāng)領(lǐng)導(dǎo)者被選舉出來(lái),且大多數(shù)Server完成了和leader的狀態(tài)同步以后
,恢復(fù)模式就結(jié)束了。狀態(tài)同步保證了leader和Server具有相同的系統(tǒng)狀態(tài)。
? 為了保證事務(wù)的順序一致性,zookeeper采用了遞增的事務(wù)id號(hào)(zxid)來(lái)標(biāo)識(shí)事務(wù)。所有的提議(
proposal)都在被提出的時(shí)候加上了zxid。實(shí)現(xiàn)中zxid是一個(gè)64位的數(shù)字,它高32位是epoch用來(lái)標(biāo)識(shí)
leader關(guān)系是否改變,每次一個(gè)leader被選出來(lái),它都會(huì)有一個(gè)新的epoch,標(biāo)識(shí)當(dāng)前屬于那個(gè)leader的
統(tǒng)治時(shí)期。低32位用于遞增計(jì)數(shù)。
? 每個(gè)Server在工作過(guò)程中有三種狀態(tài):
LOOKING:當(dāng)前Server不知道leader是誰(shuí),正在搜尋
LEADING:當(dāng)前Server即為選舉出來(lái)的leader
FOLLOWING:leader已經(jīng)選舉出來(lái),當(dāng)前Server與之同步
其他文檔:
http://www.cnblogs.com/lpshou/archive/2013/06/14/3136738.html
2、Zookeeper 的讀寫(xiě)機(jī)制
? Zookeeper是一個(gè)由多個(gè)server組成的集群
? 一個(gè)leader,多個(gè)follower
? 每個(gè)server保存一份數(shù)據(jù)副本
? 全局?jǐn)?shù)據(jù)一致
? 分布式讀寫(xiě)
? 更新請(qǐng)求轉(zhuǎn)發(fā),由leader實(shí)施
3、Zookeeper 的保證
? 更新請(qǐng)求順序進(jìn)行,來(lái)自同一個(gè)client的更新請(qǐng)求按其發(fā)送順序依次執(zhí)行
? 數(shù)據(jù)更新原子性,一次數(shù)據(jù)更新要么成功,要么失敗
? 全局唯一數(shù)據(jù)視圖,client無(wú)論連接到哪個(gè)server,數(shù)據(jù)視圖都是一致的
? 實(shí)時(shí)性,在一定事件范圍內(nèi),client能讀到最新數(shù)據(jù)
4、Zookeeper節(jié)點(diǎn)數(shù)據(jù)操作流程
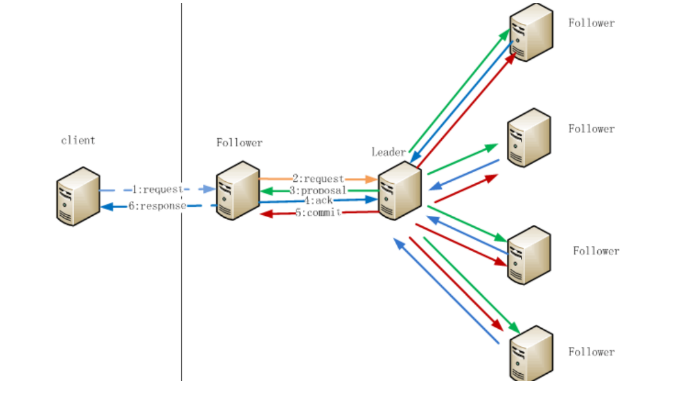
注:1.在Client向Follwer發(fā)出一個(gè)寫(xiě)的請(qǐng)求
2.Follwer把請(qǐng)求發(fā)送給Leader
3.Leader接收到以后開(kāi)始發(fā)起投票并通知Follwer進(jìn)行投票
4.Follwer把投票結(jié)果發(fā)送給Leader
5.Leader將結(jié)果匯總后如果需要寫(xiě)入,則開(kāi)始寫(xiě)入同時(shí)把寫(xiě)入操作通知給 Leader,然后commit;
6.Follwer把請(qǐng)求結(jié)果返回給Client
Follower主要有四個(gè)功能:
? 1. 向Leader發(fā)送請(qǐng)求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
? 2 .接收Leader消息并進(jìn)行處理;
? 3 .接收Client的請(qǐng)求,如果為寫(xiě)請(qǐng)求,發(fā)送給Leader進(jìn)行投票;
? 4 .返回Client結(jié)果。
Follower的消息循環(huán)處理如下幾種來(lái)自Leader的消息:
? 1 .PING消息:心跳消息;
? 2 .PROPOSAL消息:Leader發(fā)起的提案,要求Follower投票;
? 3 .COMMIT消息:服務(wù)器端最新一次提案的信息;
? 4 .UPTODATE消息:表明同步完成;
? 5 .REVALIDATE消息:根據(jù)Leader的REVALIDATE結(jié)果,關(guān)閉待revalidate的 session還是允許其接受消息;
? 6 .SYNC消息:返回SYNC結(jié)果到客戶端,這個(gè)消息最初由客戶端發(fā)起,用來(lái)強(qiáng)制得到最新的更新。
5、Zookeeper leader 選舉
選舉機(jī)制(全新集群paxos)
以一個(gè)簡(jiǎn)單的例子來(lái)說(shuō)明整個(gè)選舉的過(guò)程.
假設(shè)有五臺(tái)服務(wù)器組成的zookeeper集群,它們的id從1-5,同時(shí)它們都是最新啟動(dòng)的,也就是沒(méi)有歷史數(shù)據(jù),在存放數(shù)據(jù)量這一點(diǎn)上,都是一樣的.假設(shè)這些服務(wù)器依序啟動(dòng),來(lái)看看會(huì)發(fā)生什么.
1) 服務(wù)器1啟動(dòng),此時(shí)只有它一臺(tái)服務(wù)器啟動(dòng)了,它發(fā)出去的報(bào)沒(méi)有任何響應(yīng),所以它的選舉狀態(tài)一直是LOOKING狀態(tài)
2) 服務(wù)器2啟動(dòng),它與最開(kāi)始啟動(dòng)的服務(wù)器1進(jìn)行通信,互相交換自己的選舉結(jié)果,由于兩者都沒(méi)有歷史數(shù)據(jù),所以id值較大的服務(wù)器2勝出,但是由于沒(méi)有達(dá)到超過(guò)半數(shù)以上的服務(wù)器都同意選舉它(這個(gè)例子中的半數(shù)以上是3),所以服務(wù)器1,2還是繼續(xù)保持LOOKING狀態(tài).
3) 服務(wù)器3啟動(dòng),根據(jù)前面的理論分析,服務(wù)器3成為服務(wù)器1,2,3中的老大,而與上面不同的是,此時(shí)有三臺(tái)服務(wù)器選舉了它,所以它成為了這次選舉的leader.
4) 服務(wù)器4啟動(dòng),根據(jù)前面的分析,理論上服務(wù)器4應(yīng)該是服務(wù)器1,2,3,4中最大的,但是由于前面已經(jīng)有半數(shù)以上的服務(wù)器選舉了服務(wù)器3,所以它只能接收當(dāng)小弟的命了.
5) 服務(wù)器5啟動(dòng),同4一樣,當(dāng)小弟.
非全新集群的選舉機(jī)制(數(shù)據(jù)恢復(fù))
那么,初始化的時(shí)候,是按照上述的說(shuō)明進(jìn)行選舉的,但是當(dāng)zookeeper運(yùn)行了一段時(shí)間之后,有機(jī)器down掉,重新選舉時(shí),選舉過(guò)程就相對(duì)復(fù)雜了。
需要加入數(shù)據(jù)id、leader id和邏輯時(shí)鐘。
數(shù)據(jù)id:數(shù)據(jù)新的id就大,數(shù)據(jù)每次更新都會(huì)更新id。
Leader id:就是我們配置的myid中的值,每個(gè)機(jī)器一個(gè)。
邏輯時(shí)鐘:這個(gè)值從0開(kāi)始遞增,每次選舉對(duì)應(yīng)一個(gè)值,也就是說(shuō): 如果在同一次選舉中,那么這個(gè)值應(yīng)該是一致的 ; 邏輯時(shí)鐘值越大,說(shuō)明這一次選舉leader的進(jìn)程更新.
選舉的標(biāo)準(zhǔn)就變成:
1、邏輯時(shí)鐘小的選舉結(jié)果被忽略,重新投票
2、統(tǒng)一邏輯時(shí)鐘后,數(shù)據(jù)id大的勝出
3、數(shù)據(jù)id相同的情況下,leader id大的勝出
根據(jù)這個(gè)規(guī)則選出leader。
? 半數(shù)通過(guò)
– 3臺(tái)機(jī)器 掛一臺(tái) 2>3/2
– 4臺(tái)機(jī)器 掛2臺(tái) 2!>4/2
? A提案說(shuō),我要選自己,B你同意嗎?C你同意嗎?B說(shuō),我同意選A;C說(shuō),我同意選A。(注意,這里超過(guò)半數(shù)了,其實(shí)在現(xiàn)實(shí)世界選舉已經(jīng)成功了。
但是計(jì)算機(jī)世界是很嚴(yán)格,另外要理解算法,要繼續(xù)模擬下去。)
? 接著B(niǎo)提案說(shuō),我要選自己,A你同意嗎;A說(shuō),我已經(jīng)超半數(shù)同意當(dāng)選,你的提案無(wú)效;C說(shuō),A已經(jīng)超半數(shù)同意當(dāng)選,B提案無(wú)效。
? 接著C提案說(shuō),我要選自己,A你同意嗎;A說(shuō),我已經(jīng)超半數(shù)同意當(dāng)選,你的提案無(wú)效;B說(shuō),A已經(jīng)超半數(shù)同意當(dāng)選,C的提案無(wú)效。
? 選舉已經(jīng)產(chǎn)生了Leader,后面的都是follower,只能服從Leader的命令。而且這里還有個(gè)小細(xì)節(jié),就是其實(shí)誰(shuí)先啟動(dòng)誰(shuí)當(dāng)頭。

6、zxid
? znode節(jié)點(diǎn)的狀態(tài)信息中包含czxid, 那么什么是zxid呢?
? ZooKeeper狀態(tài)的每一次改變, 都對(duì)應(yīng)著一個(gè)遞增的Transaction id, 該id稱為zxid. 由于zxid的遞增性質(zhì), 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2發(fā)生.
創(chuàng)建任意節(jié)點(diǎn), 或者更新任意節(jié)點(diǎn)的數(shù)據(jù), 或者刪除任意節(jié)點(diǎn), 都會(huì)導(dǎo)致Zookeeper狀態(tài)發(fā)生改變, 從而導(dǎo)致zxid的值增加.
7、Zookeeper工作原理
? Zookeeper的核心是原子廣播,這個(gè)機(jī)制保證了各個(gè)server之間的同步。實(shí)現(xiàn)這個(gè)機(jī)制的協(xié)議叫做Zab協(xié)議。Zab協(xié)議有兩種模式,它們分別是恢復(fù)模式和廣播模式。
當(dāng)服務(wù)啟動(dòng)或者在領(lǐng)導(dǎo)者崩潰后,Zab就進(jìn)入了恢復(fù)模式,當(dāng)領(lǐng)導(dǎo)者被選舉出來(lái),且大多數(shù)server的完成了和leader的狀態(tài)同步以后,恢復(fù)模式就結(jié)束了。
狀態(tài)同步保證了leader和server具有相同的系統(tǒng)狀態(tài)
? 一旦leader已經(jīng)和多數(shù)的follower進(jìn)行了狀態(tài)同步后,他就可以開(kāi)始廣播消息了,即進(jìn)入廣播狀態(tài)。這時(shí)候當(dāng)一個(gè)server加入zookeeper服務(wù)中,它會(huì)在恢復(fù)模式下啟動(dòng),
發(fā)現(xiàn)leader,并和leader進(jìn)行狀態(tài)同步。待到同步結(jié)束,它也參與消息廣播。Zookeeper服務(wù)一直維持在Broadcast狀態(tài),直到leader崩潰了或者leader失去了大部分
的followers支持。
? 廣播模式需要保證proposal被按順序處理,因此zk采用了遞增的事務(wù)id號(hào)(zxid)來(lái)保證。所有的提議(proposal)都在被提出的時(shí)候加上了zxid。
實(shí)現(xiàn)中zxid是一個(gè)64為的數(shù)字,它高32位是epoch用來(lái)標(biāo)識(shí)leader關(guān)系是否改變,每次一個(gè)leader被選出來(lái),它都會(huì)有一個(gè)新的epoch。低32位是個(gè)遞增計(jì)數(shù)。
? 當(dāng)leader崩潰或者leader失去大多數(shù)的follower,這時(shí)候zk進(jìn)入恢復(fù)模式,恢復(fù)模式需要重新選舉出一個(gè)新的leader,讓所有的server都恢復(fù)到一個(gè)正確的狀態(tài)。
? 每個(gè)Server啟動(dòng)以后都詢問(wèn)其它的Server它要投票給誰(shuí)。
? 對(duì)于其他server的詢問(wèn),server每次根據(jù)自己的狀態(tài)都回復(fù)自己推薦的leader的id和上一次處理事務(wù)的zxid(系統(tǒng)啟動(dòng)時(shí)每個(gè)server都會(huì)推薦自己)
? 收到所有Server回復(fù)以后,就計(jì)算出zxid最大的哪個(gè)Server,并將這個(gè)Server相關(guān)信息設(shè)置成下一次要投票的Server。
? 計(jì)算這過(guò)程中獲得票數(shù)最多的的sever為獲勝者,如果獲勝者的票數(shù)超過(guò)半數(shù),則改server被選為leader。否則,繼續(xù)這個(gè)過(guò)程,直到leader被選舉出來(lái)
? leader就會(huì)開(kāi)始等待server連接
? Follower連接leader,將最大的zxid發(fā)送給leader
? Leader根據(jù)follower的zxid確定同步點(diǎn)
? 完成同步后通知follower 已經(jīng)成為uptodate狀態(tài)
? Follower收到uptodate消息后,又可以重新接受client的請(qǐng)求進(jìn)行服務(wù)了
8、數(shù)據(jù)一致性與paxos 算法
? 據(jù)說(shuō)Paxos算法的難理解與算法的知名度一樣令人敬仰,所以我們先看如何保持?jǐn)?shù)據(jù)的一致性,這里有個(gè)原則就是:
? 在一個(gè)分布式數(shù)據(jù)庫(kù)系統(tǒng)中,如果各節(jié)點(diǎn)的初始狀態(tài)一致,每個(gè)節(jié)點(diǎn)都執(zhí)行相同的操作序列,那么他們最后能得到一個(gè)一致的狀態(tài)。
? Paxos算法解決的什么問(wèn)題呢,解決的就是保證每個(gè)節(jié)點(diǎn)執(zhí)行相同的操作序列。好吧,這還不簡(jiǎn)單,master維護(hù)一個(gè)
全局寫(xiě)隊(duì)列,所有寫(xiě)操作都必須 放入這個(gè)隊(duì)列編號(hào),那么無(wú)論我們寫(xiě)多少個(gè)節(jié)點(diǎn),只要寫(xiě)操作是按編號(hào)來(lái)的,就能保證一
致性。沒(méi)錯(cuò),就是這樣,可是如果master掛了呢。
? Paxos算法通過(guò)投票來(lái)對(duì)寫(xiě)操作進(jìn)行全局編號(hào),同一時(shí)刻,只有一個(gè)寫(xiě)操作被批準(zhǔn),同時(shí)并發(fā)的寫(xiě)操作要去爭(zhēng)取選票,
只有獲得過(guò)半數(shù)選票的寫(xiě)操作才會(huì)被 批準(zhǔn)(所以永遠(yuǎn)只會(huì)有一個(gè)寫(xiě)操作得到批準(zhǔn)),其他的寫(xiě)操作競(jìng)爭(zhēng)失敗只好再發(fā)起一
輪投票,就這樣,在日復(fù)一日年復(fù)一年的投票中,所有寫(xiě)操作都被嚴(yán)格編號(hào)排 序。編號(hào)嚴(yán)格遞增,當(dāng)一個(gè)節(jié)點(diǎn)接受了一個(gè)
編號(hào)為100的寫(xiě)操作,之后又接受到編號(hào)為99的寫(xiě)操作(因?yàn)榫W(wǎng)絡(luò)延遲等很多不可預(yù)見(jiàn)原因),它馬上能意識(shí)到自己 數(shù)據(jù)
不一致了,自動(dòng)停止對(duì)外服務(wù)并重啟同步過(guò)程。任何一個(gè)節(jié)點(diǎn)掛掉都不會(huì)影響整個(gè)集群的數(shù)據(jù)一致性(總2n+1臺(tái),除非掛掉大于n臺(tái))。
總結(jié)
? Zookeeper 作為 Hadoop 項(xiàng)目中的一個(gè)子項(xiàng)目,是 Hadoop 集群管理的一個(gè)必不可少的模塊,它主要用來(lái)控制集群中的數(shù)據(jù),
如它管理 Hadoop 集群中的 NameNode,還有 Hbase 中 Master Election、Server 之間狀態(tài)同步等。\
關(guān)于Paxos算法可以查看文章 Zookeeper全解析——Paxos作為靈魂
推薦書(shū)籍:《從Paxos到Zookeeper分布式一致性原理與實(shí)踐》
9、Observer
? Zookeeper需保證高可用和強(qiáng)一致性;
? 為了支持更多的客戶端,需要增加更多Server;
? Server增多,投票階段延遲增大,影響性能;
? 權(quán)衡伸縮性和高吞吐率,引入Observer
? Observer不參與投票;
? Observers接受客戶端的連接,并將寫(xiě)請(qǐng)求轉(zhuǎn)發(fā)給leader節(jié)點(diǎn);
? 加入更多Observer節(jié)點(diǎn),提高伸縮性,同時(shí)不影響吞吐率
10、 為什么zookeeper集群的數(shù)目,一般為奇數(shù)個(gè)?
?Leader選舉算法采用了Paxos協(xié)議;
?Paxos核心思想:當(dāng)多數(shù)Server寫(xiě)成功,則任務(wù)數(shù)據(jù)寫(xiě)成功如果有3個(gè)Server,則兩個(gè)寫(xiě)成功即可;如果有4或5個(gè)Server,則三個(gè)寫(xiě)成功即可。
?Server數(shù)目一般為奇數(shù)(3、5、7)如果有3個(gè)Server,則最多允許1個(gè)Server掛掉;如果有4個(gè)Server,則同樣最多允許1個(gè)Server掛掉由此,
我們看出3臺(tái)服務(wù)器和4臺(tái)服務(wù)器的的容災(zāi)能力是一樣的,所以為了節(jié)省服務(wù)器資源,一般我們采用奇數(shù)個(gè)數(shù),作為服務(wù)器部署個(gè)數(shù)。
11、Zookeeper 的數(shù)據(jù)模型
? 層次化的目錄結(jié)構(gòu),命名符合常規(guī)文件系統(tǒng)規(guī)范
? 每個(gè)節(jié)點(diǎn)在zookeeper中叫做znode,并且其有一個(gè)唯一的路徑標(biāo)識(shí)
? 節(jié)點(diǎn)Znode可以包含數(shù)據(jù)和子節(jié)點(diǎn),但是EPHEMERAL類型的節(jié)點(diǎn)不能有子節(jié)點(diǎn)
? Znode中的數(shù)據(jù)可以有多個(gè)版本,比如某一個(gè)路徑下存有多個(gè)數(shù)據(jù)版本,那么查詢這個(gè)路徑下的數(shù)據(jù)就需要帶上版本
? 客戶端應(yīng)用可以在節(jié)點(diǎn)上設(shè)置監(jiān)視器
? 節(jié)點(diǎn)不支持部分讀寫(xiě),而是一次性完整讀寫(xiě)
12、Zookeeper 的節(jié)點(diǎn)
? Znode有兩種類型,短暫的(ephemeral)和持久的(persistent)
? Znode的類型在創(chuàng)建時(shí)確定并且之后不能再修改
? 短暫znode的客戶端會(huì)話結(jié)束時(shí),zookeeper會(huì)將該短暫znode刪除,短暫znode不可以有子節(jié)點(diǎn)
? 持久znode不依賴于客戶端會(huì)話,只有當(dāng)客戶端明確要?jiǎng)h除該持久znode時(shí)才會(huì)被刪除
? Znode有四種形式的目錄節(jié)點(diǎn)
? PERSISTENT(持久的)
? EPHEMERAL(暫時(shí)的)
? PERSISTENT_SEQUENTIAL(持久化順序編號(hào)目錄節(jié)點(diǎn))
? EPHEMERAL_SEQUENTIAL(暫時(shí)化順序編號(hào)目錄節(jié)點(diǎn))
————————————————
版權(quán)聲明:本文為CSDN博主「一塵在心」的原創(chuàng)文章,遵循CC 4.0 BY-SA版權(quán)協(xié)議,轉(zhuǎn)載請(qǐng)附上原文出處鏈接及本聲明。
原文鏈接:
https://blog.csdn.net/zhanaolu4821/article/details/85235609
如有文章對(duì)你有幫助,
歡迎關(guān)注??、點(diǎn)贊??、轉(zhuǎn)發(fā)??!
推薦, Java面試手冊(cè) 內(nèi)容包括網(wǎng)絡(luò)協(xié)議、Java基礎(chǔ)、進(jìn)階、字符串、集合、并發(fā)、JVM、數(shù)據(jù)結(jié)構(gòu)、算法、MySQL、Redis、Mongo、Spring、SpringBoot、MyBatis、SpringCloud、Linux以及各種中間件(Dubbo、Nginx、Zookeeper、MQ、Kafka、ElasticSearch)等等... 點(diǎn)擊文末“閱讀原文”可直達(dá)
