
《面試八股文》之 MySQL 35 卷
微信公眾號:「moon聊技術(shù)」
關(guān)注選擇“「星標」”, 重磅干貨,第一 時間送達!
[如果你覺得文章對你有幫助,歡迎「關(guān)注,在看,點贊,轉(zhuǎn)發(fā)」]
 35 個 Mysql 常見的小問題,moon 濃縮成了精華,祝大家卷的愉快~
35 個 Mysql 常見的小問題,moon 濃縮成了精華,祝大家卷的愉快~
再再再說一下,moon 的群聊開放了,可以在下方添加 moon 的微信,單獨拉你進去,一起聊技術(shù),侃生活吧~
1.說一說三大范式
2.MyISAM 與 InnoDB 的區(qū)別是什么?
3.為什么推薦使用自增 id 作為主鍵?
4.一條查詢語句是怎么執(zhí)行的?
5.使用 Innodb 的情況下,一條更新語句是怎么執(zhí)行的?
6.Innodb 事務(wù)為什么要兩階段提交?
7.什么是索引?
8.索引失效的場景有哪些?
9.為什么采用 B+ 樹,而不是 B-樹
10.WAl 是什么?有什么好處?
11.什么是回表?
12.什么是索引下推?
13.什么是覆蓋索引?
14.什么是最左前綴原則?
15.普通索引和唯一索引該怎么選擇?
16.什么是事務(wù)?其特性是什么?
17.事務(wù)的隔離級別?
18.binlog 是做什么的?
19.undolog 是做什么的?
20.relaylog 是做什么的?
21.redolog 是做什么的?
22.redolog 是怎么記錄日志的?
23.redolog 和 binlog 的區(qū)別是什么?
24.說一說 mvcc 吧,有什么作用?
25.一條 Sql 語句查詢一直慢會是什么原因?
26.一條 Sql 語句查詢偶爾慢會是什么原因?
27.Mysql 主從之間是怎么同步數(shù)據(jù)的?
28.主從延遲要怎么解決?
29.刪除表數(shù)據(jù)后表的大小卻沒有變動,這是為什么?
30.為什么 VarChar 建議不要超過255?
31.分布式式事務(wù)怎么實現(xiàn)?
32.Mysql 中有哪些鎖?
33.為什么不要使用長事務(wù)?
34.buffer pool 是做什么的?
35.說說你的 Sql 調(diào)優(yōu)思路吧
1.說一說三大范式
「第一范式」:數(shù)據(jù)庫中的字段具有「原子性」,不可再分,并且是單一職責
「第二范式」:「建立在第一范式的基礎(chǔ)上」,第二范式要求數(shù)據(jù)庫表中的每個實例或行必須「可以被惟一地區(qū)分」。為實現(xiàn)區(qū)分通常需要為表加上一個列,以存儲各個實例的惟一標識。這個惟一屬性列被稱為主鍵
「第三范式」:「建立在第一,第二范式的基礎(chǔ)上」,確保每列都和主鍵列直接相關(guān),而不是間接相關(guān)不存在其他表的非主鍵信息
但是在我們的日常開發(fā)當中,「并不是所有的表一定要滿足三大范式」,有時候冗余幾個字段可以少關(guān)聯(lián)幾張表,帶來的查詢效率的提升有可能是質(zhì)變的
2.MyISAM 與 InnoDB 的區(qū)別是什么?

「InnoDB支持事務(wù),MyISAM不支持」。 「InnoDB 支持外鍵,而 MyISAM 不支持」。 「InnoDB是聚集索引」,使用B+Tree作為索引結(jié)構(gòu),數(shù)據(jù)文件是和索引綁在一起的,必須要有主鍵。「MyISAM是非聚集索引」,也是使用B+Tree作為索引結(jié)構(gòu),索引和數(shù)據(jù)文件是分離的,索引保存的是數(shù)據(jù)文件的指針。主鍵索引和輔助索引是獨立的。 「InnoDB 不保存表的具體行數(shù)」。「MyISAM 用一個變量保存了整個表的行數(shù)」。 5.Innodb 有 「redolog」 日志文件,MyISAM 沒有
6.「Innodb存儲文件有frm、ibd,而Myisam是frm、MYD、MYI」
Innodb:frm是表定義文件,ibd是數(shù)據(jù)文件 Myisam:frm是表定義文件,myd是數(shù)據(jù)文件,myi是索引文件 「InnoDB 支持表、行鎖,而 MyISAM 支持表級鎖」 8、「InnoDB 必須有唯一索引(主鍵)」,如果沒有指定的話 InnoDB 會自己生成一個隱藏列Row_id來充當默認主鍵,「MyISAM 可以沒有」
3.為什么推薦使用自增 id 作為主鍵?

1.普通索引的 B+ 樹上存放的是主鍵索引的值,如果該值較大,會「導致普通索引的存儲空間較大」 2.使用自增 id 做主鍵索引新插入數(shù)據(jù)只要放在該頁的最尾端就可以,直接「按照順序插入」,不用刻意維護 3.頁分裂容易維護,當插入數(shù)據(jù)的當前頁快滿時,會發(fā)生頁分裂的現(xiàn)象,如果主鍵索引不為自增 id,那么數(shù)據(jù)就可能從頁的中間插入,頁的數(shù)據(jù)會頻繁的變動,「導致頁分裂維護成本較高」
4.一條查詢語句是怎么執(zhí)行的?

1.通過連接器跟客戶端「建立連接」 2.通過查詢「緩存查詢」之前是否有查詢過該 sql 有則直接返回結(jié)果 沒有則執(zhí)行第三步 3.通過分析器「分析該 sql 的語義」是否正確,包括格式,表等等 4.通過優(yōu)化器「優(yōu)化該語句」,比如選擇索引,join 表的連接順序 5.「驗證權(quán)限」,驗證是否有該表的查詢權(quán)限 沒有則返回無權(quán)限的錯誤 有則執(zhí)行第六步 6.通過執(zhí)行器調(diào)用存儲引擎執(zhí)行該 sql,然后返回「執(zhí)行結(jié)果」
5.使用 Innodb 的情況下,一條更新語句是怎么執(zhí)行的?
用以下語句來舉例,c 字段無索引,id 為主鍵索引
update?T?set?c=c+1?where?id=2;
1.執(zhí)行器先找引擎取 id=2 這一行。id 是主鍵,引擎直接用樹搜索找到這一行
如果 id=2 這一行所在的數(shù)據(jù)頁本來就「在內(nèi)存中」,就「直接返回」給執(zhí)行器 「不在內(nèi)存」中,需要先從磁盤「讀入內(nèi)存」,然后再「返回」 2.執(zhí)行器拿到引擎給的行數(shù)據(jù),把這個值加上 1,比如原來是 N,現(xiàn)在就是 N+1,得到新的一行數(shù)據(jù),再調(diào)用引擎接口「寫入這行新數(shù)據(jù)」
3.引擎將這行新數(shù)據(jù)更新到內(nèi)存中,同時將這個更新操作「記錄到 redo log 里面」,此時 redo log 處于 「prepare」 狀態(tài)。然后告知執(zhí)行器執(zhí)行完成了,隨時可以提交事務(wù)
4.執(zhí)行器「生成這個操作的 binlog」,并把 binlog 「寫入磁盤」
5.執(zhí)行器調(diào)用引擎的「提交事務(wù)」接口,引擎把剛剛寫入的 redo log 改成提交(commit)狀態(tài),「更新完成」
6.Innodb 事務(wù)為什么要兩階段提交?
先寫 redolog 后寫binlog。假設(shè)在 redolog 寫完,binlog 還沒有寫完的時候,MySQL 進程異常重啟,這時候 binlog 里面就沒有記錄這個語句。然后你會發(fā)現(xiàn),如果需要用這個 binlog 來恢復臨時庫的話,由于這個語句的 「binlog 丟失」,這個臨時庫就會少了這一次更新,恢復出來的這一行 c 的值就是 0,與原庫的值不同。
先寫 binlog 后寫 redolog。如果在 binlog 寫完之后 crash,由于 redolog 還沒寫,崩潰恢復以后這個事務(wù)無效,所以這一行c的值是0。但是 binlog 里面已經(jīng)記錄了“把c從0改成1”這個日志。所以,在之后用 binlog 來恢復的時候就「多了一個事務(wù)出來」,恢復出來的這一行 c 的值就是 1,與原庫的值不同。
可以看到,「如果不使用“兩階段提交”,那么數(shù)據(jù)庫的狀態(tài)就有可能和用它的日志恢復出來的庫的狀態(tài)不一致」。
7.什么是索引?
相信大家小時候?qū)W習漢字的時候都會查字典,想想你查字典的步驟,我們是通過漢字的首字母 a~z 一個一個在字典目錄中查找,最終找到該字的頁數(shù)。想想,如果沒有目錄會怎么樣,最差的結(jié)果是你有可能翻到字典的最后一頁才找到你想要找的字。
索引就「相當于我們字典中的目錄」,可以極大的提高我們在數(shù)據(jù)庫的查詢效率。
8.索引失效的場景有哪些?
以下隨便列舉幾個,不同版本的 mysql 場景不一
1.最左前綴法則(帶頭索引不能死,中間索引不能斷
2.不要在索引上做任何操作(計算、函數(shù)、自動/手動類型轉(zhuǎn)換),不然會導致索引失效而轉(zhuǎn)向全表掃描
3.不能繼續(xù)使用索引中范圍條件(bettween、<、>、in等)右邊的列,如:
select?a?from?user?where?c > 5 and b = 4;
4.索引字段上使用(!= 或者 < >)判斷時,會導致索引失效而轉(zhuǎn)向全表掃描
5.索引字段上使用 is null / is not null 判斷時,會導致索引失效而轉(zhuǎn)向全表掃描。
6.索引字段使用like以通配符開頭(‘%字符串’)時,會導致索引失效而轉(zhuǎn)向全表掃描,也是最左前綴原則。
7.索引字段是字符串,但查詢時不加單引號,會導致索引失效而轉(zhuǎn)向全表掃描
8.索引字段使用 or 時,會導致索引失效而轉(zhuǎn)向全表掃描
9.為什么采用 B+ 樹,而不是 B-樹
B+ 樹只在葉子結(jié)點儲存數(shù)據(jù),非葉子結(jié)點不存具體數(shù)據(jù),只存 key,查詢更穩(wěn)定,增大了廣度,而一個節(jié)點就是磁盤一個內(nèi)存頁,內(nèi)存頁大小固定,那么相比 B 樹,B- 樹這些「可以存更多的索引結(jié)點」,寬度更大,樹高矮,節(jié)點小,拉取一次數(shù)據(jù)的磁盤 IO 次數(shù)少,并且 B+ 樹只需要去遍歷葉子節(jié)點就可以實現(xiàn)整棵樹的遍歷。而且在數(shù)據(jù)庫中基于范圍的查詢是非常頻繁的,效率更高。
10.WAl 是什么?有什么好處?
WAL 就是 Write-Ahead Logging,其實就是「所有的修改都先被寫入到日志中,然后再寫磁盤」,用于保證數(shù)據(jù)操作的原子性和持久性。
好處:
1.「讀和寫可以完全地并發(fā)執(zhí)行」,不會互相阻塞 2.先寫入 log 中,磁盤寫入從「隨機寫變?yōu)轫樞驅(qū)憽?/strong>,降低了 client 端的延遲就。并且,由于順序?qū)懭氪蟾怕适窃谝粋€磁盤塊內(nèi),這樣產(chǎn)生的 io 次數(shù)也大大降低 3.寫入日志當數(shù)據(jù)庫崩潰的時候「可以使用日志來恢復磁盤數(shù)據(jù)」
11.什么是回表?

回表就是先通過數(shù)據(jù)庫索引掃描出該索引樹中數(shù)據(jù)所在的行,取到主鍵 id,再通過主鍵 id 取出主鍵索引數(shù)中的數(shù)據(jù),即基于非主鍵索引的查詢需要多掃描一棵索引樹.
12.什么是索引下推?
如果存在某些被索引的列的判斷條件時,MySQL 將這一部分判斷條件傳遞給存儲引擎,然后由存儲引擎通過判斷索引是否符合 MySQL 服務(wù)器傳遞的條件,「只有當索引符合條件時才會將數(shù)據(jù)檢索出來返回給 MySQL 服務(wù)器」 。
13.什么是覆蓋索引?
覆蓋索引(covering index)指一個查詢語句的執(zhí)行只用從索引中就能夠取得,不必從數(shù)據(jù)表中讀取,可以減少回表的次數(shù)。比如:
select?id?from?t?where?age?=?1;
id 為主鍵索引,age 為普通索引,age 這個索引樹存儲的就是逐漸信息,可以直接返回
14.什么是最左前綴原則?
最左前綴其實說的是,在 where 條件中出現(xiàn)的字段,「如果只有組合索引中的部分列,則這部分列的觸發(fā)索引順序」,是按照定義索引的時候的順序從前到后觸發(fā),最左面一個列觸發(fā)不了,之后的所有列索引都無法觸發(fā)。
比如「有一個 (a,b,c) 的組合索引」
where?a?=?1?and?b?=?1
此時 a,b 會命中該組合索引
where?a?=?1?and?c?=?1
此時 a 會命中該組合索引, c 不會
where?b?=?1?and?c?=?1
此時不會命中該組合索引
15.普通索引和唯一索引該怎么選擇?
查詢
當普通索引為條件時查詢到數(shù)據(jù)會一直掃描,直到掃完整張表 當唯一索引為查詢條件時,查到該數(shù)據(jù)會直接返回,不會繼續(xù)掃表 更新
普通索引會直接將操作更新到 change buffer 中,然后結(jié)束 唯一索引需要判斷數(shù)據(jù)是否沖突
所以「唯一索引更加適合查詢的場景,普通索引更適合插入的場景」
16.什么是事務(wù)?其特性是什么?
事務(wù)是指是程序中一系列操作必須全部成功完成,有一個失敗則全部失敗。
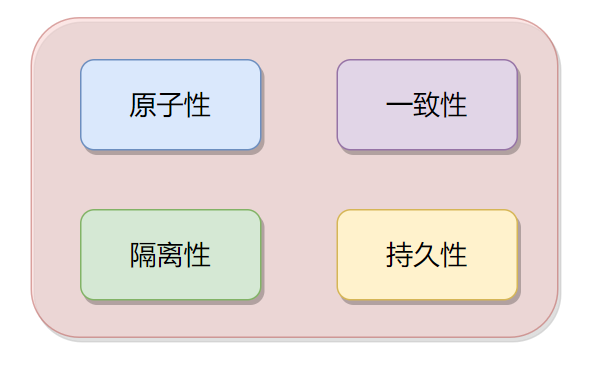
特性
「1.原子性(Atomicity)」:要么全部執(zhí)行成功,要么全部不執(zhí)行。 「2.一致性(Consistency)」:事務(wù)前后數(shù)據(jù)的完整性必須保持一致。 「3.隔離性(Isolation)」:隔離性是當多個事務(wù)同事觸發(fā)時,不能被其他事務(wù)的操作所干擾,多個并發(fā)事務(wù)之間要相互隔離。 「4.持久性(Durability)」:事務(wù)完成之后的改變是永久的。
17.事務(wù)的隔離級別?
1.「讀提交」:即能夠「讀取到那些已經(jīng)提交」的數(shù)據(jù) 2.「讀未提交」:即能夠「讀取到?jīng)]有被提交」的數(shù)據(jù) 3.「可重復讀」:可重復讀指的是在一個事務(wù)內(nèi),最開始讀到的數(shù)據(jù)和事務(wù)結(jié)束前的「任意時刻讀到的同一批數(shù)據(jù)都是一致的」 4.「可串行化」:最高事務(wù)隔離級別,不管多少事務(wù),都是「依次按序一個一個執(zhí)行」

「臟讀」
臟讀指的是「讀到了其他事務(wù)未提交的數(shù)據(jù)」,未提交意味著這些數(shù)據(jù)可能會回滾,也就是可能最終不會存到數(shù)據(jù)庫中,也就是不存在的數(shù)據(jù)。讀到了并一定最終存在的數(shù)據(jù),這就是臟讀 「不可重復讀」
對比可重復讀,不可重復讀指的是在同一事務(wù)內(nèi),「不同的時刻讀到的同一批數(shù)據(jù)可能是不一樣的」。 「幻讀」
幻讀是針對數(shù)據(jù)插入(INSERT)操作來說的。假設(shè)事務(wù)A對某些行的內(nèi)容作了更改,但是還未提交,此時事務(wù)B插入了與事務(wù)A更改前的記錄相同的記錄行,并且在事務(wù)A提交之前先提交了,而這時,在事務(wù)A中查詢,會發(fā)現(xiàn)「好像剛剛的更改對于某些數(shù)據(jù)未起作用」,但其實是事務(wù)B剛插入進來的這就叫幻讀
18.binlog 是做什么的?
binlog 是歸檔日志,屬于 Server 層的日志,是一個二進制格式的文件,用于「記錄用戶對數(shù)據(jù)庫更新的SQL語句信息」。
主要作用
主從復制 數(shù)據(jù)恢復
19.undolog 是做什么的?
undolog 是 InnoDB 存儲引擎的日志,用于保證數(shù)據(jù)的原子性,「保存了事務(wù)發(fā)生之前的數(shù)據(jù)的一個版本,也就是說記錄的是數(shù)據(jù)是修改之前的數(shù)據(jù),可以用于回滾」,同時可以提供多版本并發(fā)控制下的讀(MVCC)。
主要作用
事務(wù)回滾 實現(xiàn)多版本控制(MVCC)
20.relaylog 是做什么的?
relaylog 是中繼日志,「在主從同步的時候使用到」,它是一個中介臨時的日志文件,用于存儲從master節(jié)點同步過來的binlog日志內(nèi)容。
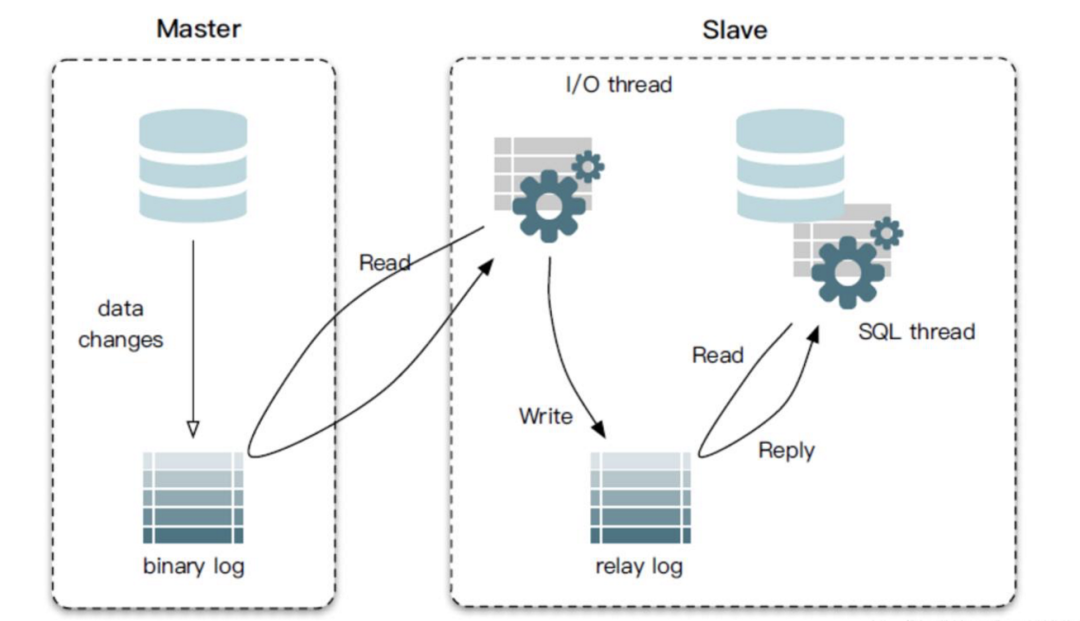
master 主節(jié)點的 binlog 傳到 slave 從節(jié)點后,被寫入 relay log 里,從節(jié)點的 slave sql 線程從 relaylog 里讀取日志然后應(yīng)用到 slave 從節(jié)點本地。從服務(wù)器 I/O 線程將主服務(wù)器的二進制日志讀取過來記錄到從服務(wù)器本地文件,然后 SQL 線程會讀取 relay-log 日志的內(nèi)容并應(yīng)用到從服務(wù)器,從而「使從服務(wù)器和主服務(wù)器的數(shù)據(jù)保持一致」。
21.redolog 是做什么的?
redolog 是 「InnoDB 存儲引擎所特有的一種日志」,用于記錄事務(wù)操作的變化,記錄的是數(shù)據(jù)修改之后的值,不管事務(wù)是否提交都會記錄下來。
可以做「數(shù)據(jù)恢復并且提供 crash-safe 能力」
當有增刪改相關(guān)的操作時,會先記錄到 Innodb 中,并修改緩存頁中的數(shù)據(jù),「等到 mysql 閑下來的時候才會真正的將 redolog 中的數(shù)據(jù)寫入到磁盤當中」。
22.redolog 是怎么記錄日志的?
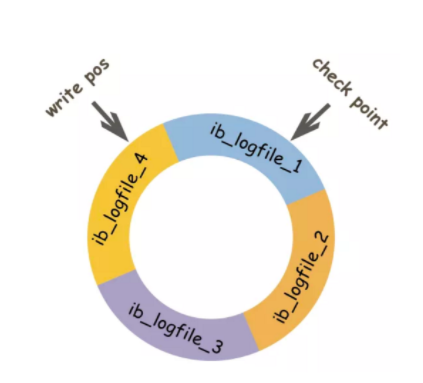
InnoDB 的 redo log 是固定大小的,比如可以配置為一組4個文件,每個文件的大小是1GB,那么總共就可以記錄4GB的操作。「從頭開始寫,寫到末尾就又回到開頭循環(huán)寫」。
所以,如果數(shù)據(jù)寫滿了但是還沒有來得及將數(shù)據(jù)真正的刷入磁盤當中,那么就會發(fā)生「內(nèi)存抖動」現(xiàn)象,從肉眼的角度來觀察會發(fā)現(xiàn) mysql 會宕機一會兒,此時就是正在刷盤了。
23.redolog 和 binlog 的區(qū)別是什么?

1.「redolog」 是 「Innodb」 獨有的日志,而 「binlog」 是 「server」 層的,所有的存儲引擎都有使用到 2.「redolog」 記錄了「具體的數(shù)值」,對某個頁做了什么修改,「binlog」 記錄的「操作內(nèi)容」 3.「binlog」 大小達到上限或者 flush log 「會生成一個新的文件」,而 「redolog」 有固定大小「只能循環(huán)利用」 4.「binlog 日志沒有 crash-safe 的能力」,只能用于歸檔。而 redo log 有 crash-safe 能力。
24.說一說 mvcc 吧,有什么作用?
MVCC:多版本并發(fā)控制,是現(xiàn)代數(shù)據(jù)庫(包括 MySQL、Oracle、PostgreSQL 等)引擎實現(xiàn)中常用的處理讀寫沖突的手段,目的在于「提高數(shù)據(jù)庫高并發(fā)場景下的吞吐性能」。
在 MVCC 協(xié)議下,每個讀操作會看到一個一致性的快照,「這個快照是基于整個庫的」,并且可以實現(xiàn)非阻塞的讀,用于「支持讀提交和可重復讀隔離級別的實現(xiàn)」。
MVCC 允許數(shù)據(jù)具有多個版本,這個版本可以是時間戳或者是全局遞增的事務(wù) ID,在同一個時間點,不同的事務(wù)看到的數(shù)據(jù)是不同的,這個修改的數(shù)據(jù)是「記錄在 undolog 中」的。
25.一條 Sql 語句查詢一直慢會是什么原因?

「1.沒有用到索引」 比如函數(shù)導致的索引失效,或者本身就沒有加索引 「2.表數(shù)據(jù)量太大」 考慮分庫分表吧 「3.優(yōu)化器選錯了索引」 「考慮使用」 force index 強制走索引
26.一條 Sql 語句查詢偶爾慢會是什么原因?

「1. 數(shù)據(jù)庫在刷新臟頁」 比如 「redolog 寫滿了」,「內(nèi)存不夠用了」釋放內(nèi)存如果是臟頁也需要刷,mysql 「正常空閑狀態(tài)刷臟頁」 「2. 沒有拿到鎖」
27.Mysql 主從之間是怎么同步數(shù)據(jù)的?
1.master 主庫將此次更新的事件類型「寫入到主庫的 binlog 文件」中 2.master 「創(chuàng)建 log dump 線程通知 slave」 需要更新數(shù)據(jù) 3.「slave」 向 master 節(jié)點發(fā)送請求,「將該 binlog 文件內(nèi)容存到本地的 relaylog 中」 4.「slave 開啟 sql 線程」讀取 relaylog 中的內(nèi)容,「將其中的內(nèi)容在本地重新執(zhí)行一遍」,完成主從數(shù)據(jù)同步

「同步策略」:
1.「全同步復制」:主庫強制同步日志到從庫,等全部從庫執(zhí)行完才返回客戶端,性能差 2.「半同步復制」:主庫收到至少一個從庫確認就認為操作成功,從庫寫入日志成功返回ack確認
28.主從延遲要怎么解決?
1.MySQL 5.6 版本以后,提供了一種「并行復制」的方式,通過將 SQL 線程轉(zhuǎn)換為多個 work 線程來進行重放 2.「提高機器配置」(王道) 3.在業(yè)務(wù)初期就選擇合適的分庫、分表策略,「避免單表單庫過大」帶來額外的復制壓力 4.「避免長事務(wù)」 5.「避免讓數(shù)據(jù)庫進行各種大量運算」 6.對于一些對延遲很敏感的業(yè)務(wù)「直接使用主庫讀」
29.刪除表數(shù)據(jù)后表的大小卻沒有變動,這是為什么?
在使用 delete 刪除數(shù)據(jù)時,其實對應(yīng)的數(shù)據(jù)行并不是真正的刪除,是「邏輯刪除」,InnoDB 僅僅是將其「標記成可復用的狀態(tài)」,所以表空間不會變小
30.為什么 VarChar 建議不要超過255?

當定義varchar長度小于等于255時,長度標識位需要一個字節(jié)(utf-8編碼)
當大于255時,長度標識位需要兩個字節(jié),并且建立的「索引也會失效」
31.分布式式事務(wù)怎么實現(xiàn)?
1.「本地消息表」 2.「消息事務(wù)」 3.「二階段提交」 4.「三階段提交」 5.「TCC」 6.「最大努力通知」 7.「Seata 框架」
32.Mysql 中有哪些鎖?
以下并不全,主要理解下鎖的意義即可
基于鎖的屬性分類:共享鎖、排他鎖 基于鎖的粒度分類:表鎖、行鎖、記錄鎖、間隙鎖、臨鍵鎖 基于鎖的狀態(tài)分類:意向共享鎖、意向排它鎖、死鎖
33.為什么不要使用長事務(wù)?
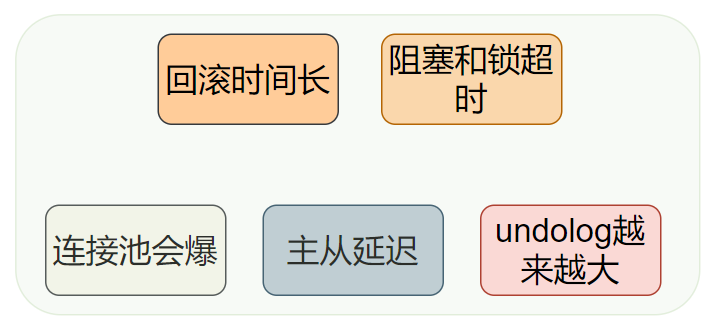
1.并發(fā)情況下,數(shù)據(jù)庫「連接池容易被撐爆」 2.「容易造成大量的阻塞和鎖超時」 長事務(wù)還占用鎖資源,也可能拖垮整個庫, 3.執(zhí)行時間長,容易造成「主從延遲」 4.「回滾所需要的時間比較長」 事務(wù)越長整個時間段內(nèi)的事務(wù)也就越多 5.「undolog 日志越來越大」 長事務(wù)意味著系統(tǒng)里面會存在很老的事務(wù)視圖。由于這些事務(wù)隨時可能訪問數(shù)據(jù)庫里面的任何數(shù)據(jù),所以這個事務(wù)提交之前,數(shù)據(jù)庫里面它可能用到的回滾記錄都必須保留,這就會導致大量占用存儲空間。
34.buffer pool 是做什么的?
buffer pool 是一塊內(nèi)存區(qū)域,為了「提高數(shù)據(jù)庫的性能」,當數(shù)據(jù)庫操作數(shù)據(jù)的時候,把硬盤上的數(shù)據(jù)加載到 buffer pool,不直接和硬盤打交道,操作的是 buffer pool 里面的數(shù)據(jù),數(shù)據(jù)庫的增刪改查都是在 buffer pool 上進行
buffer pool 里面緩存的數(shù)據(jù)內(nèi)容也是一個個數(shù)據(jù)頁
其中「有三大雙向鏈表」:
「free 鏈表」 用于幫助我們找到空閑的緩存頁 「flush 鏈表」 用于找到臟緩存頁,也就是需要刷盤的緩存頁 「lru 鏈表」 用來淘汰不常被訪問的緩存頁,分為熱數(shù)據(jù)區(qū)和冷數(shù)據(jù)區(qū),冷數(shù)據(jù)區(qū)主要存放那些不常被用到的數(shù)據(jù)
預(yù)讀機制:
Buffer Pool 有一項特技叫預(yù)讀,存儲引擎的接口在被 Server 層調(diào)用時,會在響應(yīng)的同時進行預(yù)判,將下次可能用到的數(shù)據(jù)和索引加載到 Buffer Pool
35.說說你的 Sql 調(diào)優(yōu)思路吧

1.「表結(jié)構(gòu)優(yōu)化」 1.1拆分字段 1.2字段類型的選擇 1.3字段類型大小的限制 1.4合理的增加冗余字段 1.5新建字段一定要有默認值 2.「索引方面」 2.1索引字段的選擇 2.2利用好mysql支持的索引下推,覆蓋索引等功能 2.3唯一索引和普通索引的選擇 3.「查詢語句方面」 3.1避免索引失效 3.2合理的書寫where條件字段順序 3.3小表驅(qū)動大表 3.4可以使用force index()防止優(yōu)化器選錯索引 4.「分庫分表」
往期推薦
我是moon,覺得文章有趣好看,歡迎『點贊』、『在看』、『轉(zhuǎn)發(fā)』三連支持一下,下次見~