
白話說java gc垃圾回收
gc是java區(qū)別于其他好幾門語言(c/c++)的一個代表功能(當(dāng)然也有很多可以自動管理內(nèi)存的語言,如所有的腳本語言,你根本不知道內(nèi)存管理這回事)!
當(dāng)然,之所以要把c/c++和java相比,是因?yàn)閖ava出現(xiàn)的初衷即是對標(biāo)c++的缺點(diǎn)的。不管怎么樣,gc讓程序員gg們不用痛苦地管理內(nèi)存,這是好事!
回歸正題,gc是什么?網(wǎng)上有大片的講解,但大多顯得高深莫測,云里霧里,我想換個角度來講講這事。
小白:Garbage Collect 垃圾回收(內(nèi)存),是一種自動管理內(nèi)存的一種機(jī)制!
下面,我們分幾個問題來討論gc的實(shí)現(xiàn)及原理!
一條主線(如果是你會怎么做?)
1. 什么內(nèi)存可以回收?(回收對象判定)
2. 什么時候回收?(回收時機(jī))
3. 怎么回收?(回收算法)
基本上,我們主要來回答完這幾個問題,gc的事情基本就定了!
我們也可以先用簡單的三句話來回答上面的問題:
1. 沒有用的內(nèi)存就可以回收了;
2. 在保證回收準(zhǔn)確的前提下,隨時可以回收;
3. 用高效算法進(jìn)行回收,保證最小影響業(yè)務(wù)代碼運(yùn)行;
所以,其實(shí)大體思路還是簡單的,但是具體做下來就不那么簡單了。gc功能經(jīng)過幾十年的發(fā)展依然還在完善中,就是最好的證明!
下面我們來細(xì)細(xì)解答這幾個思路!
各表一支(慢慢道來)
1. 什么樣的內(nèi)存可以回收?什么樣的內(nèi)存是沒有用的?可以回收的內(nèi)存,一般來說肯定是沒用的內(nèi)存(有用內(nèi)存將其刪除是高危動作)!
所以,判定什么樣的內(nèi)存是無用內(nèi)存,就是問題的關(guān)鍵!
通常的簡單的,使用引用計(jì)數(shù)器法推斷:給對象添加引用計(jì)數(shù)器,當(dāng)一個地方引用時,將計(jì)數(shù)加1,當(dāng)引用失效時,將計(jì)數(shù)器減1;計(jì)數(shù)器為0,則表示對象不會再被使用了,即是無用內(nèi)存。
如上便是大名鼎鼎的引用計(jì)數(shù)算法。這樣單獨(dú)說它,其實(shí)是沒有問題的,因?yàn)榫褪怯械恼Z言就是這么干的,如AS3.0, python等等!
但是,java卻是沒有采用這種判斷方法,判定對象是否無用的。因?yàn)檫@種算法對java而言,存在一個循環(huán)引用問題,解決不了。
java中是使用可達(dá)性分析算法來判定一個對象是否有用的。
可達(dá)性算法原理為:從 gc roots 作為起始點(diǎn),所有走過的路徑為引用鏈,當(dāng)一個對象到gc roots不可達(dá)時,則證明對象不可達(dá),即對象無引用,可回收。所以,我們只要找出家些不可達(dá)gc roots的對象,將其回收即可。
所以,可達(dá)性分析剩下兩個關(guān)鍵問題:
1. gc roots 在哪里?
2. 分析的起點(diǎn)是 gc roots嗎?還是其他對象?
3. 需要掃描所有路徑嗎?數(shù)量怎么樣?效率怎么樣?
java中規(guī)定以下幾種對象可作為gc roots:
1. 虛擬機(jī)棧中引用的對象(棧幀中的本地變量表中引用的對象);
2. 方法區(qū)中靜態(tài)屬性引用的對象;
3. 方法區(qū)中常量引用的對象;
4. 本地方法棧中jni引用的對象;
即以以上幾種gc roots作為根開始掃描,沒有引用的對象可以清除;
為全路徑掃描,找不到對象為需要刪除的對象;(請查看c++源碼掃描解釋)
2. 什么時候回收?任何安全準(zhǔn)確的時間點(diǎn)進(jìn)行回收?
在確定了哪些對象可以清除后,找個時間點(diǎn)就可以清除了。其實(shí),在可達(dá)性分析后不可達(dá)的對象,也可以繼續(xù)存在:
1. 對象可以finalize()方法中拯救自己一次!(逃逸)
2. 當(dāng)然,gc不是實(shí)時運(yùn)行的,它的觸發(fā)時機(jī)為:當(dāng)新生代空間不夠?qū)⒂|發(fā)一次minor gc,此時幸存下來的對象的年齡則加1;Eden區(qū)minor gc后,進(jìn)入young s1(From)區(qū),再次minor gc還存活的對象年齡加1且被轉(zhuǎn)移到y(tǒng)oung s2(To)區(qū),年齡超出一般15歲以后,就進(jìn)入老年代了;當(dāng)老年代空間也不夠放對象時,將觸發(fā)一次full gc,一般fg都伴隨著一次minor gc。
3. 執(zhí)行內(nèi)存清理時,需要暫停所有線程,否則會存在一致性問題。暫停所有的線程方式有兩種: 1. 搶占式中斷,2. 主動式中斷;對于睡眠線程,則將其設(shè)置為安全區(qū)域。在此安全占或安全區(qū)域(safepoint)內(nèi)才可以進(jìn)行回收!
3. 怎樣回收?
怎樣高效回收內(nèi)存!都有些什么算法?
1. 標(biāo)記-清除算法;白話說就是遍歷所有的GC Roots,然后將所有GC Roots可達(dá)的對象標(biāo)記為存活的對象。然后再將堆中所有沒被標(biāo)記的對象全部清除掉,然后再讓程序恢復(fù)運(yùn)行。優(yōu)點(diǎn)是簡單;缺點(diǎn):1. 兩個算法效率都不高;2. 回收后會產(chǎn)生內(nèi)存碎片;
2. 改進(jìn)1,標(biāo)記-復(fù)制算法;實(shí)現(xiàn)方法方式為:將內(nèi)存分為兩塊,將其中一塊用于存儲,當(dāng)其中一塊好的復(fù)制到另一塊上后,直接清除原來的內(nèi)存;優(yōu)點(diǎn):實(shí)現(xiàn)簡單,運(yùn)行高效;缺點(diǎn)是需要使用一半的內(nèi)存來做備用,浪費(fèi)空間了。這里還涉及到擔(dān)保問題。
3. 改進(jìn)2,標(biāo)記-整理算法;其實(shí)現(xiàn)方式為:找出可清除的區(qū)塊,讓其沿頭移動,從而得到歸整的內(nèi)存區(qū)域;優(yōu)點(diǎn)是:不需要額外的空間即可完成gc;缺點(diǎn)則不一定,主要看這個移動算法是否高效了;
4. 分代收集算法;這里是組合多個基礎(chǔ)算法的優(yōu)點(diǎn)而來的算法,也是當(dāng)下的調(diào)用虛擬機(jī)的算法。比如年輕代使用復(fù)制算法,老年代使用標(biāo)記整理算法,物盡其用!
把三個問題解答完后,我們把gc外圍的東西搞定了,現(xiàn)在讓我們看看具體的收集器吧。
畢竟,原理只是原理,只有具體的收集器對我們才更實(shí)用呢!
4. 都有些什么垃圾收集器呢?
Serial 是歷史悠久的串行收集器;
Serial old 是serial的老年代收集器,采用標(biāo)記整理算法收集;
ParNew 是serial的多線程版本收集器;
Parallel Scavenge 是專注于吞吐量的并行收集器;
Parallel old 是Parallel Scavenge的老年代版本,使用多線程和標(biāo)記整理算法進(jìn)行收集;
CMS Concurrent Mark Sweep, 是一款以獲取最短停頓時間為目標(biāo)的收集器;
G1 Garbage First, 是一款最新的性能最好的垃圾收集器;
如上面幾種垃圾收集器,一般都是以組合的形式進(jìn)行工作的,而不是單個收集器做完所有事情。(當(dāng)然越往后就越融合為一個收集器做完了)總之,其目標(biāo)都是一致的,即以不同的方式收集不同類型的內(nèi)存, 從而達(dá)到最佳收集效果!
其中,serial, serial old, parnew, ps, ps old 基本上就如同前面的一句話描述,雖然其實(shí)現(xiàn)可能很復(fù)雜,但是呈現(xiàn)出來的還是比較簡單的。
我們主要看下 CMS 和 G1 兩個收集器!
CMS, 是第一款真正的并發(fā)收集器。
G1, 籌備了10年才推出第一個正式版本,可見其難度一斑!
CMS收集器是一款追求獲得盡量短的停頓時間為目標(biāo)的收集器,它是基于標(biāo)記清除算法操作的;
它的運(yùn)作主要分為4個步驟:
1. 初始標(biāo)記;(標(biāo)記gc roots能直接關(guān)聯(lián)到的對象)
2. 并發(fā)標(biāo)記;(對gc roots進(jìn)行tracing,耗時長)
3. 重新標(biāo)記;(修正并發(fā)標(biāo)記期間因用戶程序運(yùn)作而改變的對象的標(biāo)記)
4. 并發(fā)清除;(清除標(biāo)記好的對象空間,耗時長)
這些步驟對于前面幾種收集器來說,往往就兩個步驟,它是復(fù)雜化了的。
它的整體動作過程圖示如下:
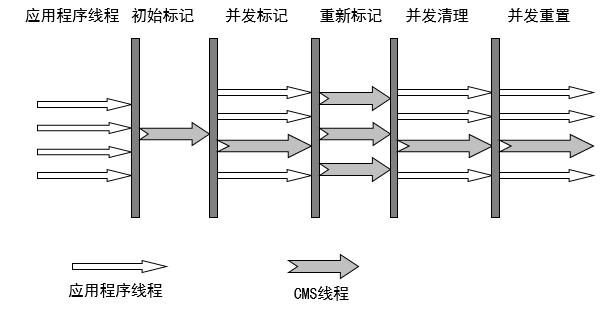
可以看出,初始標(biāo)記過程是單線程的,而后續(xù)幾個動作都是多線程的。其中并發(fā)標(biāo)記和并發(fā)清除是和都是可以和用戶線程一起工作的,而且這兩個過程又是比較耗時的,因此雖然gc一直在工作,但是并沒有導(dǎo)致用戶長時間的停頓。
有個疑問:并發(fā)標(biāo)記的tracing是什么意思?其實(shí)這是個可達(dá)性分析的過程,第一步的初始標(biāo)記僅標(biāo)記路徑,卻仍不知道哪些內(nèi)存是可回收的,所以需要在并發(fā)標(biāo)記過程中,推算出哪些空間是可回收的!(所以,并發(fā)標(biāo)記往往會涉及大量運(yùn)算?)
cms雖然看起來很好,但是它也有它的缺點(diǎn),主要體現(xiàn)在:
1. 因?yàn)槭桥c用戶線程并發(fā),雖不會導(dǎo)致用戶線程停頓,但是會搶占cpu資源。所以在cpu資源緊缺的場景則肯定不適合cms了;
2. cms收集器無法處理浮動垃圾,可能會因此導(dǎo)致另一次full gc。因?yàn)閏ms在清理期間用戶線程一直在產(chǎn)生垃圾,所以肯定會留下些cms沒有收集到的內(nèi)存,這必須等到下一次gc時才可能回收;而且,由于cms是與用戶線程一起工作的,所以,在做清理的同時必須要預(yù)留下空間給用戶線程使用,所以會收集得更頻繁些,比如超過68%的占用時就觸發(fā)gc;如果在收集期間用戶線程的內(nèi)存不夠用了,就會出現(xiàn)“Concurrent Mode Failure”,虛擬機(jī)會啟用后備預(yù)案來進(jìn)行g(shù)c以獲得足夠空間(serial old),從而導(dǎo)致停頓時間很長問題出現(xiàn);
3. 并發(fā)清除算法會導(dǎo)致內(nèi)存碎片產(chǎn)生,這在遇到大對象分配時,將無法滿足從而會提前觸發(fā)(可能總體空間還很充足)full gc;當(dāng)然cms有個開關(guān)來解決這問題,-XX:+UseCMSCompactAtFullCollection, 它會在要進(jìn)行full gc時開戶碎片整理過程,當(dāng)然它的代價(jià)是導(dǎo)致停頓時間變長;
綜上,我們可以看出cms是個好的收集器,但是它也有自己的短板,如果不顧使用場合地隨便應(yīng)用cms,則可能帶來相反的效果;
最后,我們再來看看G1收集器;
G1收集器是個最新的收集器,其研發(fā)n的周期也預(yù)示了它的難度;粗略地說它是從jdk1.7(7u4)開始面向用戶的。
它有如下優(yōu)勢:
1. 并行與并發(fā);與用戶線程共存;
2. 分代收集;
3. 空間整合;使用 標(biāo)記整理算法和復(fù)制算法,避免了空間碎片問題;
4. 可預(yù)測的停頓;用戶可以指定時間,g1會使停頓時間小于設(shè)定值;
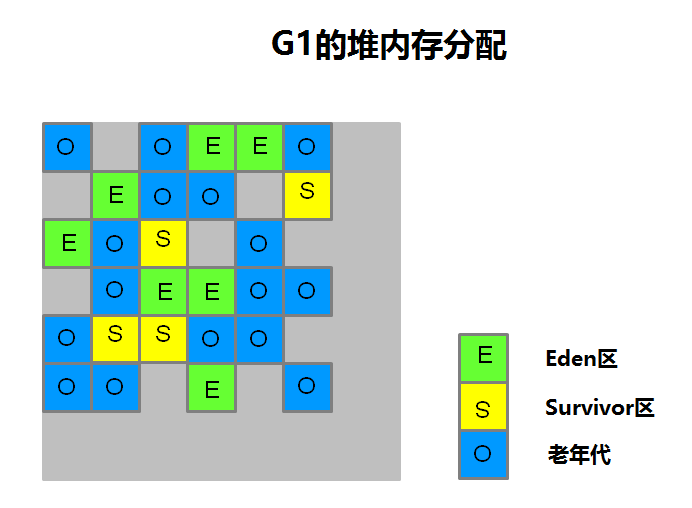
G1的堆內(nèi)存總局與其他收集器不同,它是將整個堆分為n個大小相等的region的布局!在回收垃圾時,g1會跟蹤各個region里的價(jià)值大小,在后臺維護(hù)一個優(yōu)先級列表,每次根據(jù)允許的收集時間,優(yōu)先回收價(jià)值最大的region。
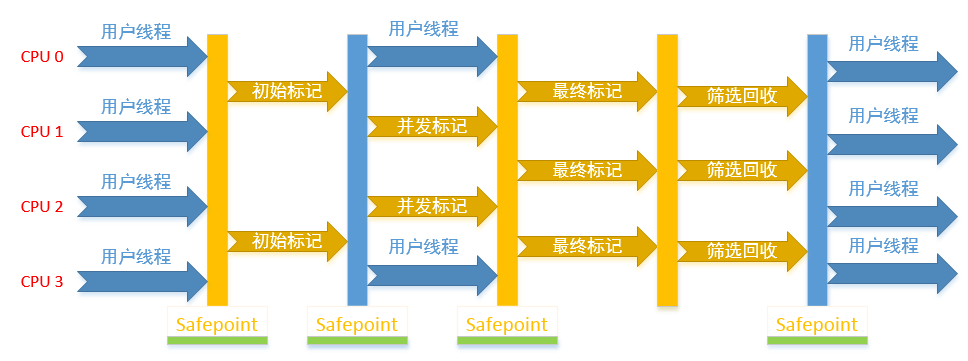
g1運(yùn)作大致分為以下幾個步驟:
1. 初始標(biāo)記;(僅標(biāo)記gc roots能關(guān)聯(lián)到的對象)
2. 并發(fā)標(biāo)記;(可達(dá)性分析)
3. 最終標(biāo)記;(修正并發(fā)標(biāo)記期間的變化,變化被記錄在log中)
4. 篩選回收;(將region回收價(jià)值排序,根據(jù)用戶期望進(jìn)行選擇回收計(jì)劃)
g1的內(nèi)存分區(qū)示意圖如下:(n個region)
其運(yùn)行過程與cms大致相似:
G1收集器在jdk1.7中正式亮像,在jdk1.8中做了很多的完善,相信會是越來越多同學(xué)的選擇的!
本文只是為了講講gc的思路,并非從入門到精通!
除了知道收集器名字和原則,還應(yīng)該要知道怎樣控制它。如果你想調(diào)優(yōu)gc配置,請另查資料!
參考:《深入理解java虛擬機(jī)》

騰訊、阿里、滴滴后臺面試題匯總總結(jié) — (含答案)
面試:史上最全多線程面試題 !
最新阿里內(nèi)推Java后端面試題
JVM難學(xué)?那是因?yàn)槟銢]認(rèn)真看完這篇文章

關(guān)注作者微信公眾號 —《JAVA爛豬皮》
了解更多java后端架構(gòu)知識以及最新面試寶典

看完本文記得給作者點(diǎn)贊+在看哦~~~大家的支持,是作者源源不斷出文的動力
作者:等你歸去來
出處:https://www.cnblogs.com/yougewe/p/10362861.html