
系統(tǒng)設(shè)計(jì)面試:如何設(shè)計(jì)一個(gè) Pastebin
今天分享一下如何設(shè)計(jì)一個(gè)類 Pastebin 的 web 服務(wù),用戶可以存儲(chǔ)純文本,然后獲得一個(gè)隨機(jī)生成的 URL,其他人可以通過這個(gè) URL 來訪問文本內(nèi)容,這很像一個(gè)在線共享粘貼板的服務(wù),如果你還沒有使用過,可以訪問 pastebin.com 來試用。
1.為什么需要 pastebin ?
一開始,pastebin 主要用來分享代碼,程序員寫完代碼后想給別人看,直接把代碼粘貼至 pastebin,然后把 url 發(fā)給其他人,其他人點(diǎn)開鏈接就可以直接看到代碼,代碼的縮進(jìn)格式會(huì)保持不變,代碼評(píng)審人員看起來會(huì)比較舒服。實(shí)際上,任何純屬文本數(shù)據(jù)都可以通過 pastebin 來共享,比如以下應(yīng)用場(chǎng)景:
用做一個(gè)在線的純文本文檔。 突破限制,發(fā)一些長推文。比如 twitter 限制只能發(fā) 140 個(gè)字符的推文,這樣我們將長推文寫在 pastebin 上,然后在 twitter 上發(fā) url 即可。 上傳源代碼用于代碼評(píng)審和合作。 重新發(fā)表一些被主流網(wǎng)站刪除的文章。 垃圾郵件/網(wǎng)站的促銷活動(dòng),因?yàn)閮?nèi)容是一個(gè)鏈接,可以繞過反垃圾、反廣告系統(tǒng)。 分享一些黑色的網(wǎng)站,宣傳一些隱私的活動(dòng)或其他敏感信息,因?yàn)樯傻?url 是不可猜測(cè)的。
我承認(rèn)后面的 4、5、6 的用途有點(diǎn)壞,目前 pastebin 的 FAQ 頁面已禁止發(fā)表以下內(nèi)容:
email 地址或者密碼 登陸信息 被偷的源代碼、數(shù)據(jù) 涉及版權(quán)的信息 銀行卡信息 垃圾廣告信息 個(gè)人隱私
pastebin 的初衷是對(duì)用戶友好的,無需注冊(cè)或者登陸即可使用,而且可以分享超長文本,讓用戶分享文本變得更容易,目前 pastebin 每月有 1700 萬活躍用戶。
2.需求及系統(tǒng)目標(biāo)
我們的 Pastebin 服務(wù)需要滿足以下需求
功能性需求:
用戶可以上傳他們的數(shù)據(jù)并獲得一個(gè)唯一的,可以訪問數(shù)據(jù)的 url。 用戶只能上傳文本。 數(shù)據(jù)和鏈接會(huì)在默認(rèn)的時(shí)間后過期,用戶可以指定過期時(shí)間。 用戶可以指定一個(gè)自定義格式的 url。
非功能需求:
服務(wù)是高可靠、高可用的,用戶上傳的文本數(shù)據(jù)不能丟失,保證可以隨時(shí)訪問上傳的數(shù)據(jù)。 用戶可以實(shí)時(shí)訪問鏈接中的數(shù)據(jù),延遲低。 生成的 url 是不可猜測(cè)的。
擴(kuò)展需求:
數(shù)據(jù)分析需求,比如一個(gè) url 被訪問了多少次。 我們的服務(wù)可以被其他服務(wù)以 REST API 的訪問。
3.一些設(shè)計(jì)考慮
Pastebin 和前文如何設(shè)計(jì)一個(gè)短鏈接系統(tǒng)有著相似的需求,但是也有一些額外的設(shè)計(jì)考慮:
用戶一次提交的文本數(shù)量應(yīng)該限制為多少?我們可以限制用戶提交的 文本總大小不能超過 10 MB,防止服務(wù)被濫用。
是否應(yīng)該限制自定義 url 的大小?由于我們的服務(wù)支持自定義網(wǎng)址,因此用戶可以選擇他們喜歡的任何 URL,但并非必須提供自定義URL。對(duì)自定義網(wǎng)址施加大小限制是合理的,以便我們擁有相對(duì)一致的網(wǎng)址數(shù)據(jù)庫。
4.容量估算和約束
我們的服務(wù)將是讀繁重的,與新生成的文本相比,會(huì)有更多的讀取文本的請(qǐng)求。這里可以假設(shè)讀寫之間的比例為 5:1。
流量估算
Pastebin 服務(wù)的流量不會(huì)類似于 Twitter 或 Facebook,假設(shè)在這里,我們每天將 100 萬個(gè)新文本添加到我們的系統(tǒng)中。這樣,每天的讀操作就是 500 萬次。也就是每秒新增 12 個(gè)文本,58 次訪問:
1M / (24 hours * 3600 seconds) ~= 12 pastes/sec
5M / (24 hours * 3600 seconds) ~= 58 reads/sec
存儲(chǔ)估算
用戶可以提交的內(nèi)容最多為 10 MB,一般使用類 Pastebin 服務(wù)的文本基本是源代碼、配置信息、日志等,這類文本都不大,假設(shè)每一個(gè)文本的平均大小為 10 KB,這樣,系統(tǒng)每天會(huì)消耗 10 GB 的存儲(chǔ)空間來存儲(chǔ)新增的文本:
1M * 10KB => 10 GB/day
如果這些數(shù)據(jù)需要保存 10 年,那么總共需要 36 TB 的存儲(chǔ)空間。每天有 100 萬個(gè)新文本,對(duì)應(yīng) 100 萬個(gè)新的 url,10 年會(huì)產(chǎn)生 36 億個(gè) url,使用 base64 編碼的話,至少需要 6 個(gè)字符,那么 36 億個(gè) url 需要的存儲(chǔ)空間為 22 GB。
3.6B * 6 => 22 GB
22 GB 相比 36 TB 是可以忽略不計(jì)的,考慮到系統(tǒng)要預(yù)留一些存儲(chǔ)防止存儲(chǔ)爆滿,設(shè)計(jì)存儲(chǔ)空間會(huì)比需要的多一些,比如讓系統(tǒng)使用的存儲(chǔ)占比永不超過 70 %,那么我們總共就需要 36/0.7 = 51.4 TB。
帶寬估算
對(duì)于寫操作的頻率為 12次/秒,每次文本平均 10 KB,那么寫操作占用的帶寬約為 120 KB/s。
對(duì)于讀操作,頻率為 58次/秒,讀操作占用服務(wù)器的帶寬約為 58 * 10 KB = 0.6 MB/s。
盡管總?cè)肟诤统隹诓⒉淮螅谠O(shè)計(jì)服務(wù)時(shí)應(yīng)當(dāng)應(yīng)牢記這些數(shù)字。
內(nèi)存估算
我們應(yīng)該緩存一些經(jīng)常被訪問的熱點(diǎn)數(shù)據(jù),根據(jù) 80/20 法則,20% 的數(shù)據(jù)承擔(dān)了 80% 的訪問流量,因此我們緩存這些 20% 的數(shù)據(jù),由于每天有 500 萬次訪問,那么我們需要緩存 500 * 20% = 100 萬的文本數(shù)據(jù),占用內(nèi)存的大小為 100 M * 10 KB = 10 GB。
5.系統(tǒng) API
我們可以使用 SOAP 或 REST API 來開放我們的服務(wù)。以下是用于創(chuàng)建/檢索/刪除粘貼的 API 的樣例:
addPaste(api_dev_key, paste_data, custom_url=None, user_name=None, paste_name=None, expire_date=None)
其中 api_dev_key 是為注冊(cè)用戶生成的一個(gè) key,可用于限流或其他與用戶相關(guān)的業(yè)務(wù)管理。如果調(diào)用成功,函數(shù)返回一個(gè)可用于訪問提交文本(paste)的 url,如果失敗,則返回錯(cuò)誤代碼。
類似的,檢索 API 如下:
getPaste(api_dev_key, api_paste_key)
其中 api_paste_key 標(biāo)識(shí)提交的文本,在數(shù)據(jù)庫中對(duì)應(yīng)著文本的主鍵。
刪除 API 如下:
deletePaste(api_dev_key, api_paste_key)
刪除成功返回 True,失敗則返回 False。
6.數(shù)據(jù)庫設(shè)計(jì)
我們要存儲(chǔ)的數(shù)據(jù)有以下性質(zhì):
我們需要存儲(chǔ)數(shù)十億條記錄。 我們存儲(chǔ)的每個(gè)元數(shù)據(jù)對(duì)象都將很小(小于 100 個(gè)字節(jié))。 我們存儲(chǔ)的文本對(duì)象的大小都可以是中等大小(可以是幾 MB)。 記錄之間沒有關(guān)系,除非我們要存儲(chǔ)哪個(gè)用戶創(chuàng)建了什么粘貼。 查詢?nèi)蝿?wù)比寫入任務(wù)繁重。
數(shù)據(jù)庫架構(gòu):
我們需要兩個(gè)表,一個(gè)表用于存儲(chǔ)有關(guān)粘貼的信息 Paste,另一個(gè)表用用戶相關(guān)的數(shù)據(jù) User。表字段如下
Paste:
pasteId:主鍵 urlHash:代表訪問文本的 url 的字符串 content:存儲(chǔ)文本的內(nèi)容 createAt:創(chuàng)建時(shí)間 expireAt:過期時(shí)間 userId:對(duì)應(yīng)的用戶id
User:
userId:主鍵 name:用戶名/姓名 email:郵箱 createAt:創(chuàng)建日期 lastLogin:上次登陸時(shí)間
7.頂層設(shè)計(jì)
在更高層級(jí)上,我們需要一個(gè)應(yīng)用程序?qū)觼頋M足所有的讀取和寫入請(qǐng)求。應(yīng)用層通過與存儲(chǔ)層進(jìn)行交互來存儲(chǔ)和檢索數(shù)據(jù)。我們可以用數(shù)據(jù)庫來隔離存儲(chǔ)層,一個(gè)數(shù)據(jù)庫存儲(chǔ)每個(gè)文本、用戶等相關(guān)的元數(shù)據(jù),而另一個(gè)數(shù)據(jù)庫存儲(chǔ)文本對(duì)象的內(nèi)容,可以存儲(chǔ)在一些對(duì)象存儲(chǔ)服務(wù)器,例如 Amazon S3。這種數(shù)據(jù)劃分可以對(duì)他們分別進(jìn)行擴(kuò)展。
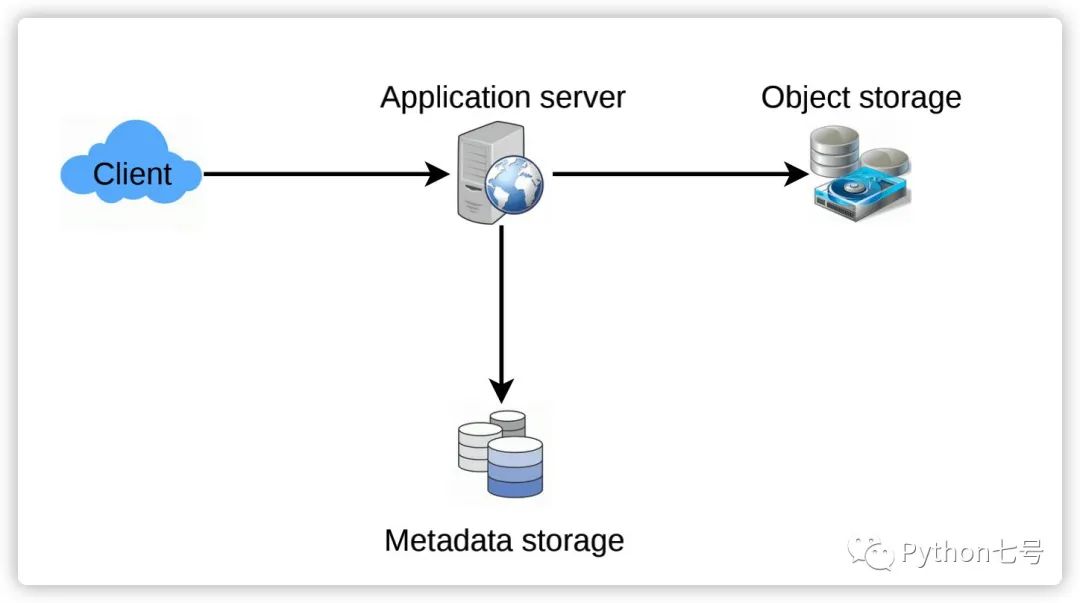
8.模塊設(shè)計(jì)
a.應(yīng)用層
應(yīng)用層通過訪問后端存儲(chǔ)處理所有的請(qǐng)求,那么如何處理一個(gè)寫請(qǐng)求呢?收到寫入請(qǐng)求后,我們的應(yīng)用程序服務(wù)器將生成一個(gè)六個(gè)字母的隨機(jī)字符串,它將用作文本 url 的鍵(如果用戶未提供自定義鍵)。然后,應(yīng)用程序服務(wù)器將文本內(nèi)容和生成的 key 存儲(chǔ)在數(shù)據(jù)庫。成功插入后,服務(wù)器可以將 key 返回給用戶。一種可能的問題是,由于 key 是隨機(jī)生成的字符串,可能會(huì)因?yàn)橹貜?fù)而導(dǎo)致插入失敗,在這種情況下,我們應(yīng)該重新生成一個(gè) key,然后重試,直到不重復(fù)為止,如果用戶提供的自定義 key 已經(jīng)存在于我們的數(shù)據(jù)庫中,同樣提醒用戶重新自定義 key。
上述問題的另一種解決方案是運(yùn)行獨(dú)立的 key 生成服務(wù)(KGS),可以預(yù)先隨機(jī)生成六個(gè)字母字符串,并將其存儲(chǔ)在數(shù)據(jù)庫中(我們稱其為 key 數(shù)據(jù)庫)。每當(dāng)我們要存儲(chǔ)一個(gè)新的文本時(shí),我們就從 KGS 中獲取一個(gè)已經(jīng)生成的 key 并使用它。這種方法將使事情變得非常簡(jiǎn)單和快捷,因?yàn)槲覀儾槐負(fù)?dān)心重復(fù)或碰撞。KGS 將確保插入到 key 數(shù)據(jù)庫中的所有 key 都是唯一的。KGS 可以使用兩個(gè)表存儲(chǔ) key ,一個(gè)用于尚未使用的 key ,另一個(gè)用于所有已使用的 key 。只要 KGS 給應(yīng)用程序服務(wù)器的某些 key ,它可以將這些 key 移到“已使用 key ”表中。KGS 可以隨時(shí)保持內(nèi)存中的某些 key ,以便服務(wù)器在需要時(shí)可以快速提供它們。一旦 KGS 將一些 key 加載到內(nèi)存中,就將它們移動(dòng)到使用過的 key 表中,這樣我們可以確保每個(gè)服務(wù)器都有唯一的 key 。如果 KGS 在使用內(nèi)存中加載的所有 key 之前死亡,我們將浪費(fèi)那些鑰匙。鑒于我們擁有大量 key ,這些小概率的浪費(fèi)是可以接受的。
KGS 存在單點(diǎn)故障嗎?是的。為了解決這個(gè)問題,我們可以有一個(gè) KGS 的備機(jī),只要主服務(wù)器死了,它就可以接管生成并提供 key 。
每個(gè)應(yīng)用服務(wù)器都可以從 key-DB 緩存一些 key 嗎?是的,這肯定可以加快速度。雖然在這種情況下,如果應(yīng)用服務(wù)器在使用所有 key 之前就死了,那么我們最終將丟失這些 key 鍵。這是可以接受的,因?yàn)槲覀冇?680 億個(gè)唯一的六個(gè)字母的鍵,這一點(diǎn)點(diǎn)的浪費(fèi)可以忽略不計(jì)。
如何處理讀取請(qǐng)求?收到讀請(qǐng)求后,應(yīng)用程序服務(wù)層訪問數(shù)據(jù)存儲(chǔ)區(qū)。數(shù)據(jù)存儲(chǔ)區(qū)搜索 key ,如果找到 key ,則返回粘貼的內(nèi)容。否則,將返回錯(cuò)誤代碼。
a.數(shù)據(jù)存儲(chǔ)層
元數(shù)據(jù)比較小,而文本內(nèi)容可能會(huì)比較大,為了便于擴(kuò)展數(shù)據(jù)庫,我們可以將數(shù)據(jù)存儲(chǔ)層分為兩層:
元數(shù)據(jù)數(shù)據(jù)庫:可以使用關(guān)系數(shù)據(jù)庫,例如 MySQL 或分布式鍵值,像 Dynamo 或 Cassandra,占用空間比較小,基本不需要擴(kuò)展。 對(duì)象存儲(chǔ):可以將內(nèi)容存儲(chǔ)在類似于 Amazon S3 的對(duì)象存儲(chǔ)中。每當(dāng)占用空間要達(dá)到內(nèi)容存儲(chǔ)的全部容量時(shí),可以輕松增加存儲(chǔ)空間。
9.清除或數(shù)據(jù)庫清理
請(qǐng)參閱 如何設(shè)計(jì)一個(gè)短鏈接系統(tǒng)
10.數(shù)據(jù)分區(qū)和復(fù)制
請(qǐng)參閱 如何設(shè)計(jì)一個(gè)短鏈接系統(tǒng)
11.緩存和負(fù)載平衡器
請(qǐng)參閱 如何設(shè)計(jì)一個(gè)短鏈接系統(tǒng)
12.安全性和權(quán)限
請(qǐng)參閱 如何設(shè)計(jì)一個(gè)短鏈接系統(tǒng)
最后的話
系統(tǒng)設(shè)計(jì)的思路都是一致的,從需求分析、資源估算、API 設(shè)計(jì)、數(shù)據(jù)庫設(shè)計(jì)、頂層設(shè)計(jì)、分模塊設(shè)計(jì)、數(shù)據(jù)清理、數(shù)據(jù)分區(qū)、緩存、負(fù)載均衡、安全和權(quán)限等步驟,基本上包括了 IT 系統(tǒng)建設(shè)和運(yùn)維的各個(gè)環(huán)節(jié),即要從全局考慮,也不能忽略重要的細(xì)節(jié),系統(tǒng)設(shè)計(jì)能力體現(xiàn)了程序員處理復(fù)雜問題的能力,如果覺得有幫助,請(qǐng)點(diǎn)贊、在看、關(guān)注支持。
推薦閱讀: