圖像分割二十年,盤(pán)點(diǎn)影響力最大的10篇論文

??新智元報(bào)道??
??新智元報(bào)道??
來(lái)源:極市平臺(tái)
編輯:SF
【新智元導(dǎo)讀】圖像分割(image segmentation)技術(shù)是計(jì)算機(jī)視覺(jué)領(lǐng)域的個(gè)重要的研究方向,近些年,圖像分割技術(shù)迅猛發(fā)展,在多個(gè)視覺(jué)研究領(lǐng)域都有著廣泛的應(yīng)用。本文盤(pán)點(diǎn)了近20年來(lái)影響力最大的 10 篇論文。
發(fā)布信息: 2017,16th IEEE International Conference on Computer Vision (ICCV)
論文:https://arxiv.org/abs/1703.06870
代碼:https://github.com/facebookresearch/Detectron
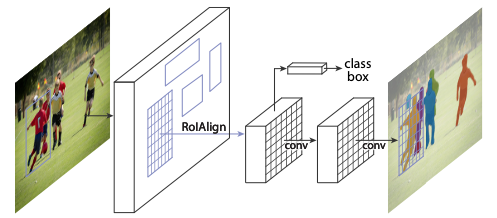
Mask R-CNN作為非常經(jīng)典的實(shí)例分割(Instance segmentation)算法,在圖像分割領(lǐng)域可謂“家喻戶曉”。
Mask R-CNN不僅在實(shí)例分割任務(wù)中表現(xiàn)優(yōu)異,還是一個(gè)非常靈活的框架,可以通過(guò)增加不同的分支完成目標(biāo)分類、目標(biāo)檢測(cè)、語(yǔ)義分割、實(shí)例分割、人體姿勢(shì)識(shí)別等多種不同的任務(wù)。

被引頻次:1937
作者: Vijay Badrinarayanan,Alex Kendall,Roberto Cipolla
發(fā)布信息:2015,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
論文:https://arxiv.org/pdf/1511.00561.pdf
代碼:https://github.com/aizawan/segnet
SegNet是用于進(jìn)行像素級(jí)別圖像分割的全卷積網(wǎng)絡(luò)。SegNet與FCN的思路較為相似,區(qū)別則在于Encoder中Pooling和Decoder的Upsampling使用的技術(shù)。
Decoder進(jìn)行上采樣的方式是Segnet的亮點(diǎn)之一,SegNet主要用于場(chǎng)景理解應(yīng)用,需要在進(jìn)行inference時(shí)考慮內(nèi)存的占用及分割的準(zhǔn)確率。同時(shí),Segnet的訓(xùn)練參數(shù)較少,可以用SGD進(jìn)行end-to-end訓(xùn)練。


被引頻次:2160
作者: Chen Liang-Chieh,Papandreou George,Kokkinos Iasonas等.
發(fā)布信息:2018,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
DeepLabv1:https://arxiv.org/pdf/1412.7062v3.pdf
DeepLabv2:https://arxiv.org/pdf/1606.00915.pdf
DeepLabv3:https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+:https://arxiv.org/pdf/1802.02611.pdf
代碼:https://github.com/tensorflow/models/tree/master/research/deeplab
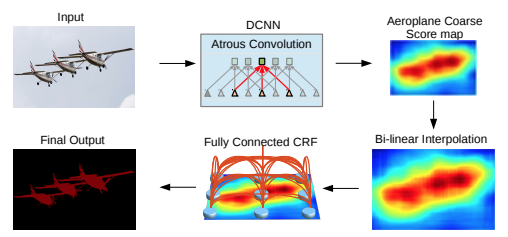
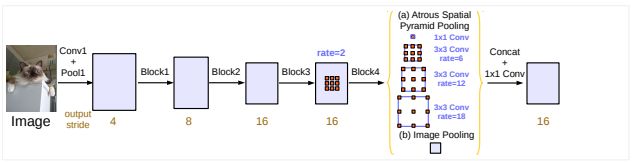
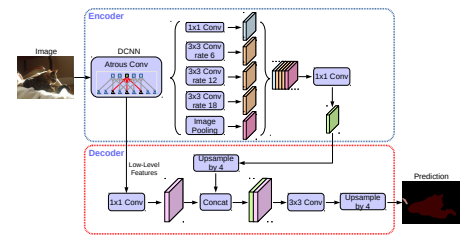
DeepLab系列采用了Dilated/Atrous Convolution的方式擴(kuò)展感受野,獲取更多的上下文信息,避免了DCNN中重復(fù)最大池化和下采樣帶來(lái)的分辨率下降問(wèn)題。
2018年,Chen等人發(fā)布Deeplabv3+,使用編碼器-解碼器架構(gòu)。DeepLabv3+在2012年pascal VOC挑戰(zhàn)賽中獲得89.0%的mIoU分?jǐn)?shù)。
被引頻次:2231
作者: Arbelaez Pablo,Maire Michael,F(xiàn)owlkes Charless等.
發(fā)布信息:2011,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
論文和代碼:https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/resources.html
Contour Detection and Hierarchical Image Segmentation通過(guò)檢測(cè)輪廓來(lái)進(jìn)行分割,以解決不加交互的圖像分割問(wèn)題,是分割領(lǐng)域中非常重要的一篇文章,后續(xù)很多邊緣檢測(cè)算法都利用了該模型。
被引頻次:3302
作者:Felzenszwalb PF,Huttenlocher DP
發(fā)布信息:2004,INTERNATIONAL JOURNAL OF COMPUTER VISION
論文和代碼:http://cs.brown.edu/people/pfelzens/segment/
Graph-Based Segmentation 是經(jīng)典的圖像分割算法,作者Felzenszwalb也是提出DPM算法的大牛。該算法是基于圖的貪心聚類算法,實(shí)現(xiàn)簡(jiǎn)單。目前雖然直接用其做分割的較少,但許多算法都用它作為基石。

被引頻次:4168
作者: Radhakrishna Achanta,Appu Shaji,Kevin Smith,Aurelien Lucchi,Pascal Fua,Sabine Susstrunk.
發(fā)布信息:2012,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
論文和代碼:https://ivrlwww.epfl.ch/supplementary_material/RK_SLICSuperpixels/index.html
SLIC 算法將K-means 算法用于超像素聚類,是一種思想簡(jiǎn)單、實(shí)現(xiàn)方便的算法,SLIC算法能生成緊湊、近似均勻的超像素,在運(yùn)算速度,物體輪廓保持、超像素形狀方面具有較高的綜合評(píng)價(jià),比較符合人們期望的分割效果。

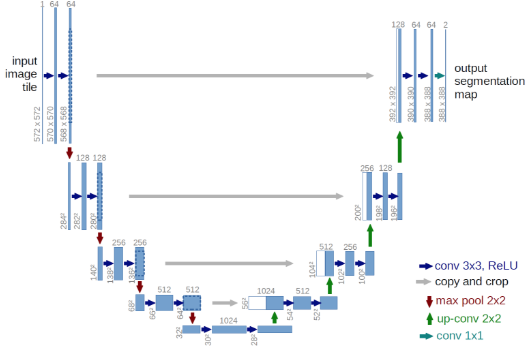
發(fā)布信息:2015,18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI)?
代碼:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
被引頻次:6996
作者: Comaniciu D,Meer P
發(fā)布信息:2002,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
Meanshift是基于像素聚類的代表方法之一,是一種特征空間分析方法。密度估計(jì)(Density Estimation) 和mode 搜索是Meanshift的兩個(gè)核心點(diǎn)。對(duì)于圖像數(shù)據(jù),其分布無(wú)固定模式可循,所以密度估計(jì)必須用非參數(shù)估計(jì),選用的是具有平滑效果的核密度估計(jì)(Kernel density estimation,KDE)。
Meanshift 算法的穩(wěn)定性、魯棒性較好,有著廣泛的應(yīng)用。但是分割時(shí)所包含的語(yǔ)義信息較少,分割效果不夠理想,無(wú)法有效地控制超像素的數(shù)量,且運(yùn)行速度較慢,不適用于實(shí)時(shí)處理任務(wù)。
被引頻次:8056
作者:Shi JB,Malik J
發(fā)布信息:2000,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
論文:https://ieeexplore.ieee.org/abstract/document/1000236
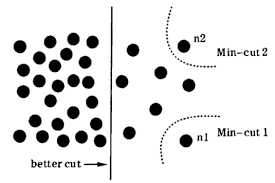
NormalizedCut是基于圖論的分割方法代表之一,與以往利用聚類的方法相比,更加專注于全局解的情況,并且根據(jù)圖像的亮度,顏色,紋理進(jìn)行劃分。
被引頻次:8170
作者: Long Jonathan,Shelhamer Evan,Darrell Trevor
發(fā)布信息:2015,IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
代碼:https://github.com/shelhamer/fcn.berkeleyvision.org
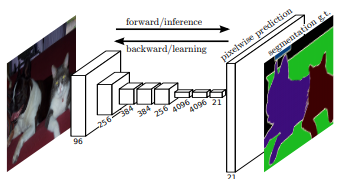
FCN是圖像分割領(lǐng)域里程碑式論文。作為語(yǔ)義分割的開(kāi)山之作,F(xiàn)CN是當(dāng)之無(wú)愧的TOP1。它提出了全卷積網(wǎng)絡(luò)(FCN)的概念,針對(duì)語(yǔ)義分割訓(xùn)練了一個(gè)端到端,點(diǎn)對(duì)點(diǎn)的網(wǎng)絡(luò),它包含了三個(gè)CNN核心思想:
(1)不含全連接層(fc)的全卷積(fully conv)網(wǎng)絡(luò)。可適應(yīng)任意尺寸輸入。
(2)增大數(shù)據(jù)尺寸的反卷積(deconv)層。能夠輸出精細(xì)的結(jié)果。
(3)結(jié)合不同深度層結(jié)果的跳級(jí)(skip)結(jié)構(gòu)。同時(shí)確保魯棒性和精確性。