
實(shí)戰(zhàn)MySql查詢

一、mysql查詢的五種子句
where子句(條件查詢):按照“條件表達(dá)式”指定的條件進(jìn)行查詢。
group by子句(分組):按照“屬性名”指定的字段進(jìn)行分組。group by子句通常和count()、sum()等聚合函數(shù)一起使用。
having子句(篩選):有g(shù)roup by才能having子句,只有滿足“條件表達(dá)式”中指定的條件的才能夠輸出。
order by子句(排序):按照“屬性名”指定的字段進(jìn)行排序。排序方式由“asc”和“desc”兩個(gè)參數(shù)指出,默認(rèn)是按照“asc”來(lái)排序,即升序。
limit(限制結(jié)果集)。
1、where——基礎(chǔ)查詢
where常用運(yùn)算符:
| 運(yùn)算符 | 說(shuō)明 |
| ????????? 比較運(yùn)算符 | |
| < | 小于 |
| <= | 小于或等于 |
| = | 等于 |
| != 或 <> | 不等于 |
| >= | 大于等于 |
| > | 大于 |
| in | 在某集合內(nèi) |
| between | 在某范圍內(nèi) |
| ??????? 邏輯運(yùn)算符 | |
| not 或 ! | 邏輯非 |
| or 或 || | 邏輯或 |
| and 或 && | 邏輯與 |
2、group by 分組
“Group By”從字面意義上理解就是根據(jù)“By”指定的規(guī)則對(duì)數(shù)據(jù)進(jìn)行分組,所謂的分組就是將一個(gè)“數(shù)據(jù)集”劃分成若干個(gè)“小區(qū)域”,然后針對(duì)若干個(gè)“小區(qū)域”進(jìn)行數(shù)據(jù)處理。
select?類別, sum(數(shù)量) as?數(shù)量之和
from?A
group?by?類別注:group by語(yǔ)句中select指定的字段必須是“分組依據(jù)字段”,其他字段若想出現(xiàn)在select中則必須包含在聚合函數(shù)中。
mysql中五種常用的聚合函數(shù):
(1)max(列名):求最大值。
(2)min(列名):求最小值。
(2)sum(列名):求和。
(4)avg(列名):求平均值。
(5)count(列名):統(tǒng)計(jì)記錄的條數(shù)。
3、having
having子句可以讓我們篩選成組后的各種數(shù)據(jù),where子句在聚合前先篩選記錄,也就是說(shuō)作用在group by和having子句前。而 having子句在聚合后對(duì)組記錄進(jìn)行篩選。?
示例:
select?類別, sum(數(shù)量) as?數(shù)量之和 from?A
group?by?類別
having?sum(數(shù)量) > 18示例:Having和Where的聯(lián)合使用方法
select?類別, SUM(數(shù)量)from?A
where?數(shù)量 >8
group?by?類別
having?SUM(數(shù)量) >10where和having的區(qū)別:
作用的對(duì)象不同。WHERE 子句作用于表和視圖,HAVING 子句作用于組。
WHERE 在分組和聚集計(jì)算之前選取輸入行(因此,它控制哪些行進(jìn)入聚集計(jì)算), 而 HAVING 在分組和聚集之后選取分組的行。因此,WHERE 子句不能包含聚集函數(shù);因?yàn)樵噲D用聚集函數(shù)判斷那些行輸入給聚集運(yùn)算是沒(méi)有意義的。相反,HAVING 子句總是包含聚集函數(shù)。(嚴(yán)格說(shuō)來(lái),你可以寫(xiě)不使用聚集的 HAVING 子句, 但這樣做只是白費(fèi)勁。同樣的條件可以更有效地用于 WHERE 階段。)
在上面的例子中,我們可以在 WHERE 里應(yīng)用數(shù)量字段來(lái)限制,因?yàn)樗恍枰奂_@樣比在 HAVING 里增加限制更加高效,因?yàn)槲覀儽苊饬藶槟切┪赐ㄟ^(guò) WHERE 檢查的行進(jìn)行分組和聚集計(jì)算。
綜上所述:
having一般跟在group by之后,執(zhí)行記錄組選擇的一部分來(lái)工作的。where則是執(zhí)行所有數(shù)據(jù)來(lái)工作的。
再者h(yuǎn)aving可以用聚合函數(shù),如having sum(qty)>1000
例子:where + group by + having + 函數(shù) 綜合查詢
練習(xí)表:
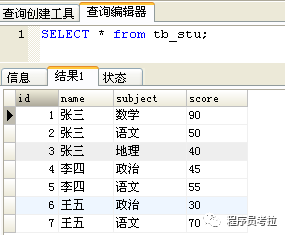
查詢出兩門(mén)及兩門(mén)以上不及格者的平均成績(jī)(注意是所有科目的平均成績(jī))
錯(cuò)誤情況1:題意理解錯(cuò)誤,理解成查出不及格科目的平均成績(jī)。

錯(cuò)誤情況2:count()不正確,SQL錯(cuò)誤。
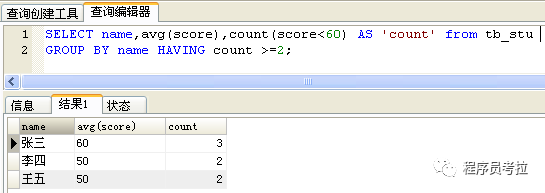
count(a),無(wú)論a是什么,都只是數(shù)一行;count時(shí),每遇到一行,就數(shù)一個(gè)a,跟條件無(wú)關(guān)!
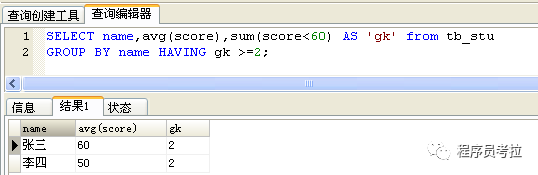
正解:count(score<60)達(dá)不到想要的結(jié)果,并不是條件的問(wèn)題,而是無(wú)論count()里的表達(dá)式是什么都會(huì)數(shù)一行。score<60 返回 1 或 0;所以可以用sum(score<60)來(lái)計(jì)算不及格的科目數(shù)!
4、order by 排序
(1)order by price? //默認(rèn)升序排列
(2)order by price desc //降序排列
(3)order by price asc //升序排列,與默認(rèn)一樣
(4)order by rand() //隨機(jī)排列,效率不高
5、limit
limit [offset,]?Noffset 偏移量,可選,不寫(xiě)則相當(dāng)于limit 0,N
N? 取出條目
示例:取價(jià)格第4-6高的商品
select?good_id,goods_name,goods_price from?goods order?by?good_price desc?limit?3,3;總結(jié):
select子句順序
子句 | 說(shuō)明 | 是否必須使用 |
select | 要返回的列或表示式 | 是 |
form | 從中檢索數(shù)據(jù)的表 | 僅在從表選擇數(shù)據(jù)時(shí)使用 |
where | 行級(jí)過(guò)濾 | 否 |
group by | 分組說(shuō)明 | 僅在按組計(jì)算聚集時(shí)使用 |
having | 組級(jí)過(guò)濾 | 否 |
order by | 輸出排序順序 | 否 |
limit | 要檢索的行數(shù) | 否 |
二、mysql子查詢
1、where型子查詢(把內(nèi)層查詢結(jié)果當(dāng)作外層查詢的比較條件)
(1)查詢id最大的一件商品(使用排序+分頁(yè)實(shí)現(xiàn))
SELECT?goods_id,goods_name,shop_price FROM?goods ORDER?BY?goods_id DESC?LIMIT?1;(2)查詢id最大的一件商品(使用where子查詢實(shí)現(xiàn))
SELECT?goods_id,goods_name,shop_price FROM?goods WHERE?goods_id = (SELECT?MAX(goods_id) FROM?goods);(3)查詢每個(gè)類別下id最大的商品(使用where子查詢實(shí)現(xiàn))
SELECT?goods_id,goods_name,cat_id,shop_price FROM?goods WHERE?goods_id IN?(SELECT?MAX(goods_id) FROM?goods GROUP?BY?cat_id);2、from型子查詢(把內(nèi)層的查詢結(jié)果當(dāng)成臨時(shí)表,供外層sql再次查詢。查詢結(jié)果集可以當(dāng)成表看待。臨時(shí)表要使用一個(gè)別名。)
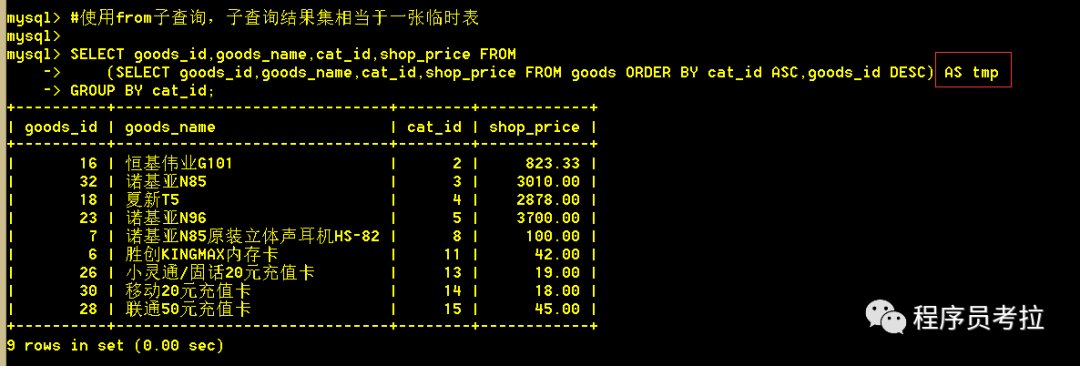
(1)查詢每個(gè)類別下id最大的商品(使用from型子查詢)
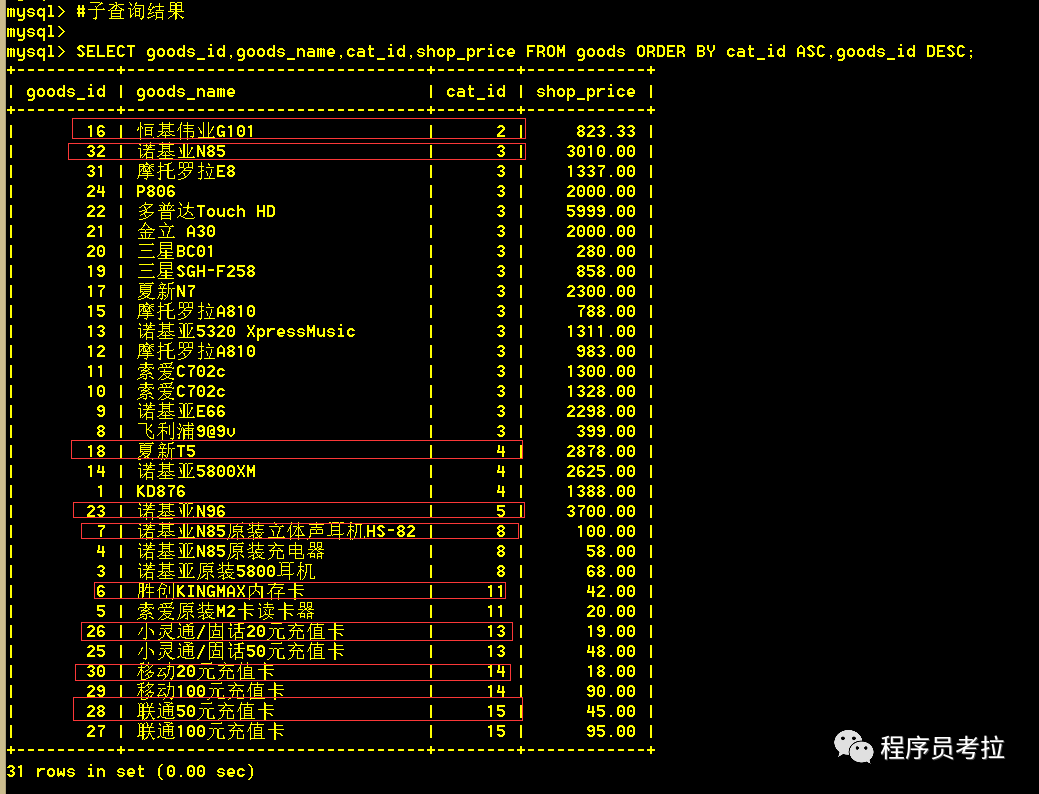
SELECT?goods_id,goods_name,cat_id,shop_price FROM
(SELECT?goods_id,goods_name,cat_id,shop_price FROM?goods ORDER?BY?cat_id ASC,goods_id DESC) AS?tmp
GROUP?BY?cat_id;子查詢查出的結(jié)果集看第二張圖,可以看到每個(gè)類別的第一條的商品id都為該類別下的最大值。然后將這個(gè)結(jié)果集作為一張臨時(shí)表,巧妙的使用group by 查詢出每個(gè)類別下的第一條記錄,即為每個(gè)類別下商品id最大。
3、exists型子查詢(把外層sql的結(jié)果,拿到內(nèi)層sql去測(cè)試,如果內(nèi)層的sql成立,則該行取出。內(nèi)層查詢是exists后的查詢。)
(1)從類別表中取出其類別下有商品的類別(如果該類別下沒(méi)有商品,則不取出)[使用where子查詢]
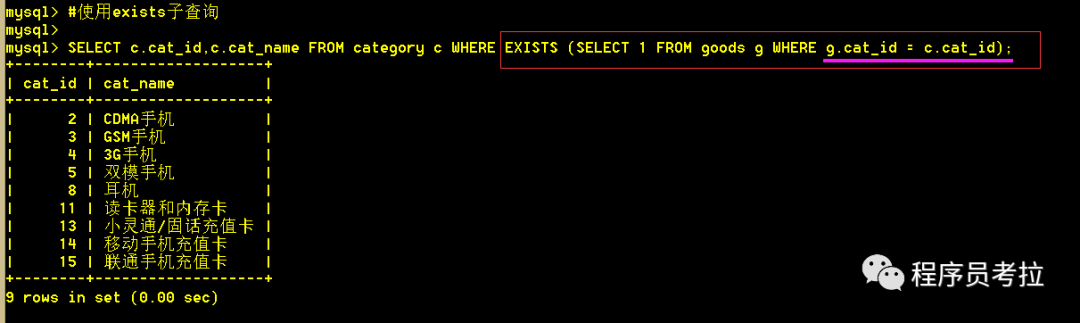
SELECT?c.cat_id,c.cat_name FROM?category?c WHERE?c.cat_id IN?(SELECT?g.cat_id FROM?goods g GROUP?BY?g.cat_id);(2)從類別表中取出其類別下有商品的類別(如果該類別下沒(méi)有商品,則不取出)[使用exists子查詢]
SELECT?c.cat_id,c.cat_name FROM?category?c WHERE?EXISTS?(SELECT?1?FROM?goods g WHERE?g.cat_id = c.cat_id);exists子查詢,如果exists后的內(nèi)層查詢能查出數(shù)據(jù),則表示存在;為空則不存在。
三、連接查詢
學(xué)習(xí)連接查詢,先了解下"笛卡爾積",看下百度給出的解釋:

?????
在數(shù)據(jù)庫(kù)中,一張表就是一個(gè)集合,每一行就是集合中的一個(gè)元素。表之間作聯(lián)合查詢即是作笛卡爾乘積,比如A表有5條數(shù)據(jù),B表有8條數(shù)據(jù),如果不作條件篩選,那么兩表查詢就有 5 X 8 = 40 條數(shù)據(jù)。
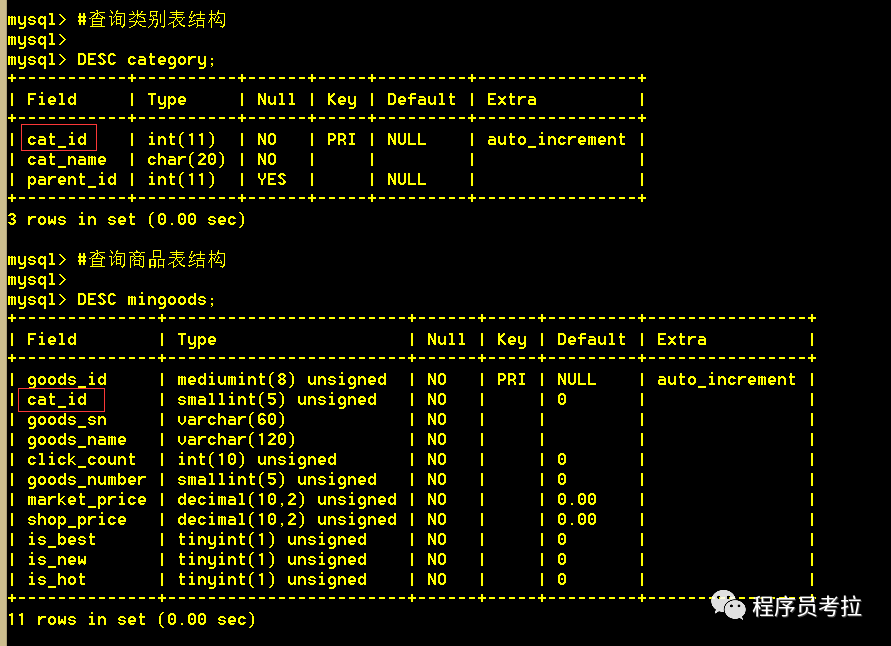
先看下用到的測(cè)試表基本信息:我們要實(shí)現(xiàn)的功能就是查詢商品的時(shí)候,從類別表將商品類別名稱關(guān)聯(lián)查詢出來(lái)。
行數(shù):類別表14條,商品表4條。

結(jié)構(gòu):商品表和類別表都有一個(gè)cat_id
1、全相乘(不是全連接、連接查詢),全相乘是作笛卡爾積
兩表全相乘,就是直接從兩張表里查詢;從查詢的截圖看出,總共查出了 4 X 14 = 56 條記錄,這些記錄是笛卡爾乘積的結(jié)果,即兩兩組合;
但我們要的是每個(gè)商品信息顯示類別名稱而已,這里卻查出了56條記錄,其中有52條記錄都是無(wú)效的數(shù)據(jù),全相乘的查詢效率低。
SELECT?goods_id,goods_name,cat_name FROM?mingoods,category;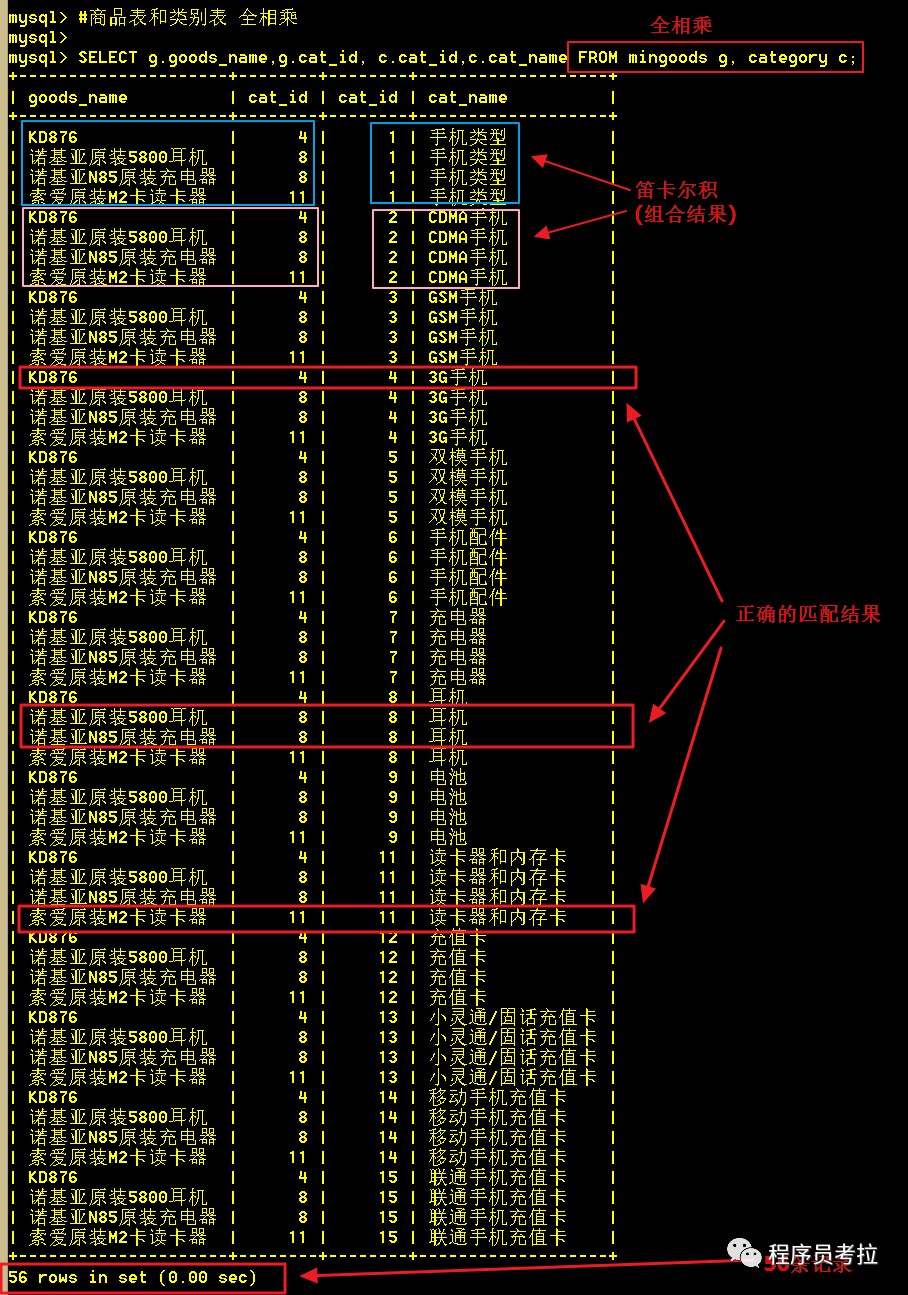
如果在兩張表里有相同字段,做聯(lián)合查詢的時(shí)候,要區(qū)別表名,否則會(huì)報(bào)錯(cuò)誤(模糊不清)。
SELECT?goods_name,cat_id,cat_name FROM?mingoods,category;

???????
添加條件,使兩表關(guān)聯(lián)查詢,這樣查出來(lái)就是商品和類別一一對(duì)應(yīng)了。雖然這里查出來(lái)4條記錄,但是全相乘效率低,全相乘會(huì)在內(nèi)存中生成一個(gè)非常大的數(shù)據(jù)(臨時(shí)表),因?yàn)橛泻芏嗖槐匾臄?shù)據(jù)。
??
如果一張表有10000條數(shù)據(jù),另一張表有10000條數(shù)據(jù),兩表全相乘就是100W條數(shù)據(jù),是非常消耗內(nèi)存的。而且,全相乘不能好好的利用索引,因?yàn)槿喑松梢粡埮R時(shí)表,臨時(shí)表里是沒(méi)有索引的,大大降低了查詢效率。
SELECT?g.goods_name,g.cat_id AS?g_cat_id, c.cat_id AS?c_cat_id, c.cat_name FROM?mingoods g, category?c WHERE?g.cat_id = c.cat_id;
2、左連接查詢 left join ... on ...
語(yǔ)法:
select?A.filed, [A.filed2, .... ,]?B.filed, [B.filed4...,]?fromas?A??left?joinas?B?on假設(shè)有A、B兩張表,左連接查詢即 A表在左不動(dòng),B表在右滑動(dòng),A表與B表通過(guò)一個(gè)關(guān)系來(lái)關(guān)聯(lián)行,B表去匹配A表。
2.1、先來(lái)看看on后的條件恒為真的情況
SELECT?g.goods_name,g.cat_id, c.cat_id ,c.cat_name FROM?mingoods g LEFT?JOIN?category?c ON?1;?????
跟全相乘相比,從截圖可以看出,總記錄數(shù)仍然不變,還是 4 X 14 = 56 條記錄。但這次是商品表不動(dòng),類別表去匹配,因?yàn)槊看味紴檎妫詫⑺械挠涗浂疾槌鰜?lái)了。左連接,其實(shí)就可以看成左表是主表,右表是從表。
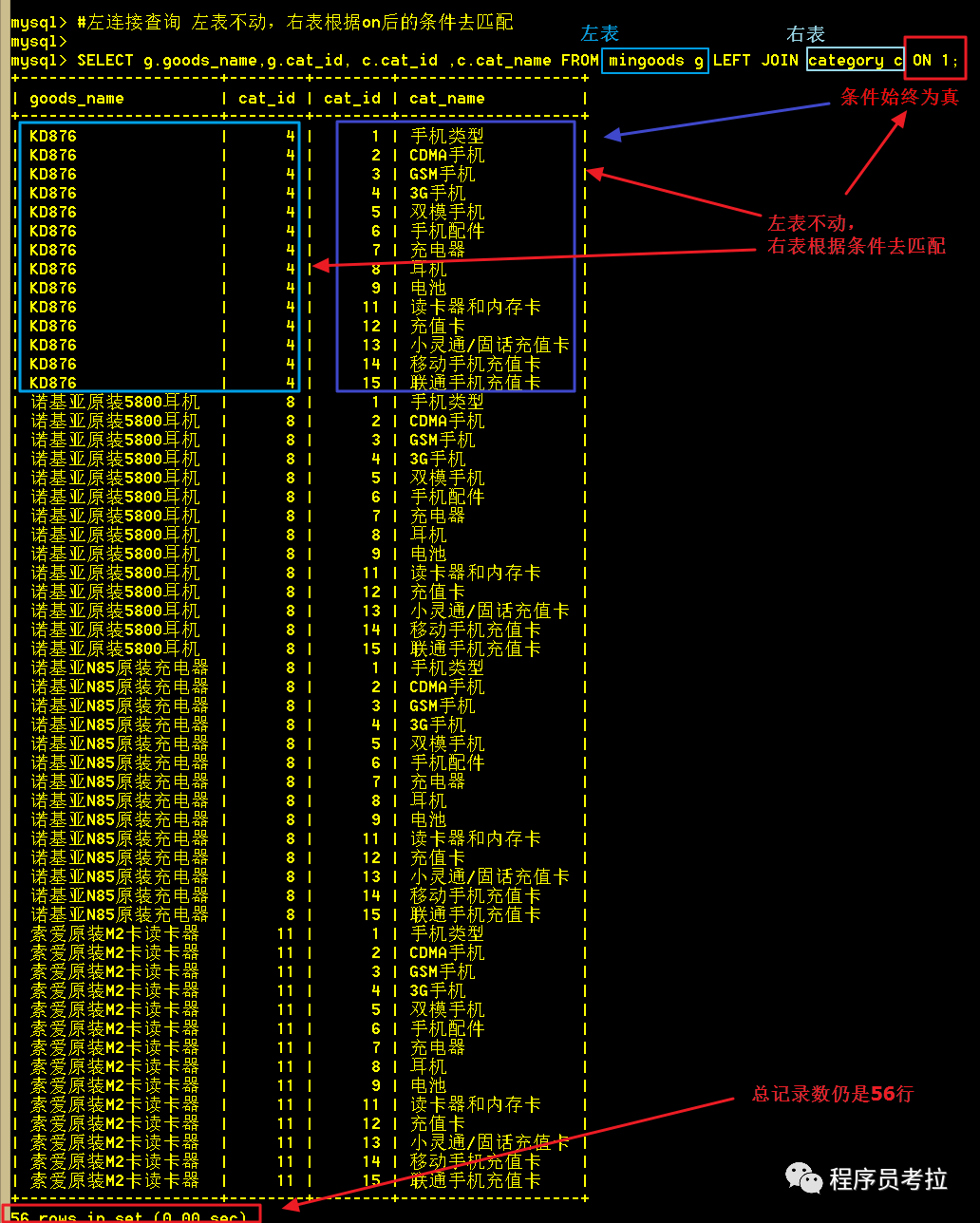
2.2 、根據(jù)cat_id使兩表關(guān)聯(lián)行
SELECT?g.goods_name,g.cat_id,c.cat_id,c.cat_name FROM?mingoods g LEFT?JOIN?category?c ON?g.cat_id = c.cat_id;使用左連接查詢達(dá)到了同樣的效果,但是不會(huì)有其它冗余數(shù)據(jù),查詢速度快,消耗內(nèi)存小,而且使用了索引。左連接查詢效率相比于全相乘的查詢效率快了10+倍以上。
左連接時(shí),mingoods表(左表)不動(dòng),category表(右表)根據(jù)條件去一條條匹配,雖說(shuō)category表也是讀取一行行記錄,然后判斷cat_id是否跟mingoods表的相同,但是,左連接使用了索引,cat_id建立了索引的話,查詢速度非常快,所以整體效率相比于全相乘要快得多,全相乘沒(méi)有使用索引。

2.3、查詢出第四個(gè)類別下的商品,要求顯示商品名稱
SELECT?g.goods_name,g.cat_id,c.cat_name,g.shop_price FROM?goods g LEFT?JOIN?category?c ON?g.cat_id = c.cat_id WHERE?g.cat_id = 4;
2.4 、對(duì)于左連接查詢,如果右表中沒(méi)有滿足條件的行,則默認(rèn)填充NULL。
SELECT?g.goods_name,g.cat_id AS?g_cat_id, c.cat_id AS?c_cat_id,c.cat_id FROM?mingoods g LEFT?JOIN?mincategory c ON?g.cat_id = c.cat_id;
3、右連接查詢 right join ... on ...
語(yǔ)法:
select?A.field1,A.field2,..., B.field3,B.field4??fromA?right?joinB?on右連接查詢跟左連接查詢類似,只是右連接是以右表為主表,會(huì)將右表所有數(shù)據(jù)查詢出來(lái),而左表則根據(jù)條件去匹配,如果左表沒(méi)有滿足條件的行,則左邊默認(rèn)顯示NULL。左右連接是可以互換的。
SELECT?g.goods_name,g.cat_id AS?g_cat_id, c.cat_id AS?c_cat_id,c.cat_name FROM?mingoods g RIGHT?JOIN?mincategory c ON?g.cat_id = c.cat_id;
4、內(nèi)連接查詢 inner join ... on ...
語(yǔ)法:
select?A.field1,A.field2,.., B.field3, B.field4?fromA?inner?joinB?on內(nèi)連接查詢,就是取左連接和右連接的交集,如果兩邊不能匹配條件,則都不取出。
SELECT?g.goods_name,g.cat_id, c.* from?mingoods g INNER?JOIN?mincategory c ON?g.cat_id = c.cat_id;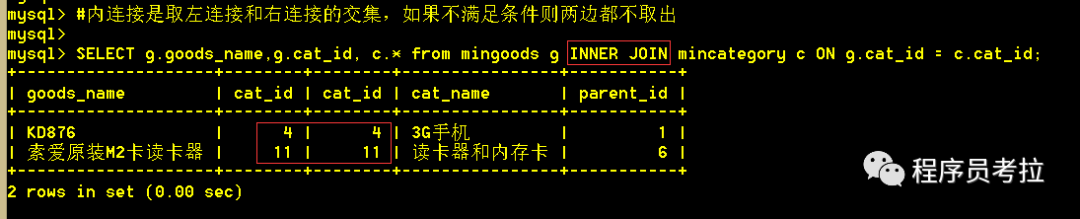
5、全連接查詢 full join ... on ...
語(yǔ)法:
select?... fromfull joinon全連接會(huì)將兩個(gè)表的所有數(shù)據(jù)查詢出來(lái),不滿足條件的為NULL。
全連接查詢跟全相乘查詢的區(qū)別在于,如果某個(gè)項(xiàng)不匹配,全相乘不會(huì)查出來(lái),全連接會(huì)查出來(lái),而連接的另一邊則為NULL。
6、聯(lián)合查詢 union
語(yǔ)法:
select?A.field1 as?f1, A.field2 as?f2 fromA union?(select?B.field3 as?f1, field4 as?f2 fromB)union是求兩個(gè)查詢的并集。union合并的是結(jié)果集,不區(qū)分來(lái)自于哪一張表,所以可以合并多張表查詢出來(lái)的數(shù)據(jù)。
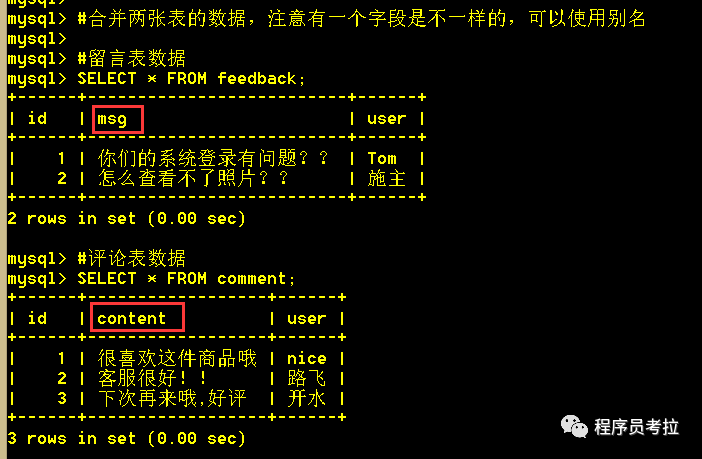
6.1、將兩張表的數(shù)據(jù)合并查詢出來(lái)
SELECT?id, content, user?FROM?comment?UNION?(SELECT?id, msg AS?content, user?FROM?feedback);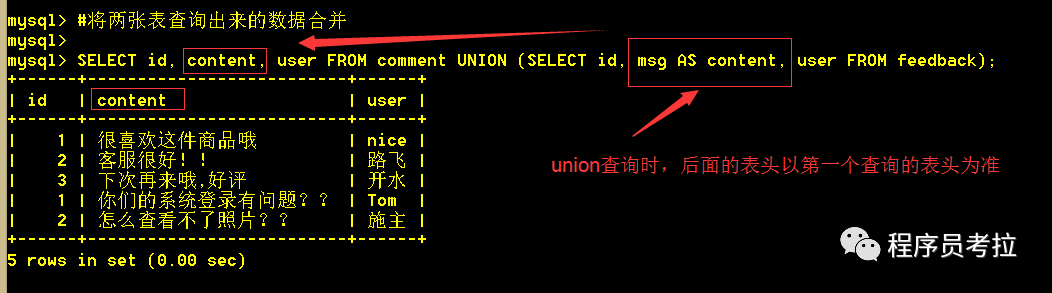
6.2、union查詢,列名不一致時(shí),以第一條sql語(yǔ)句的列名對(duì)齊
SELECT?id, content, user?FROM?comment?UNION?(SELECT?id, msg, user?FROM?feedback);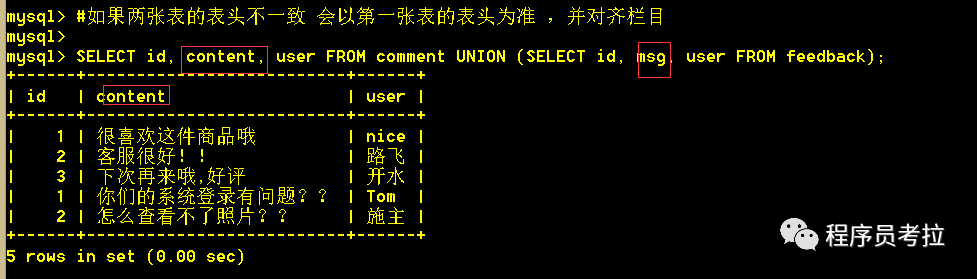
6.3、使用union查詢會(huì)將重復(fù)的行過(guò)濾掉
SELECT?content,user?FROM?comment?UNION?(SELECT?msg, user?FROM?feedback);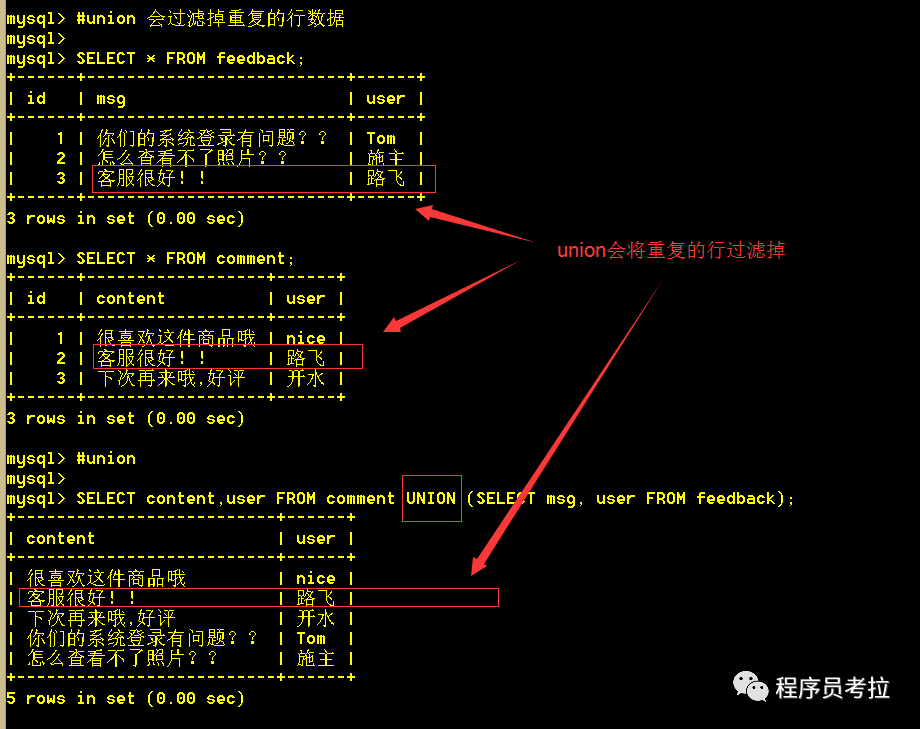
6.4、使用union all查詢所有,重復(fù)的行不會(huì)被過(guò)濾
SELECT?content,user?FROM?comment?UNION?ALL (SELECT?msg, user?FROM?feedback);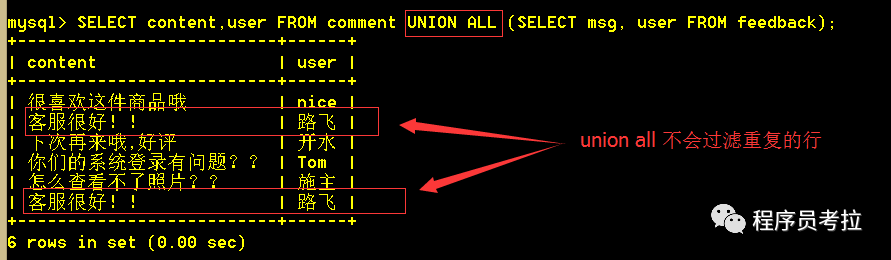
6.5、union查詢,如果列數(shù)不相等,會(huì)報(bào)列數(shù)不相等錯(cuò)誤

6.6、union 后的結(jié)果集還可以再做篩選
SELECT?id,content,user?FROM?comment?UNION?ALL (SELECT?id, msg, user?FROM?feedback) ORDER?BY?id?DESC;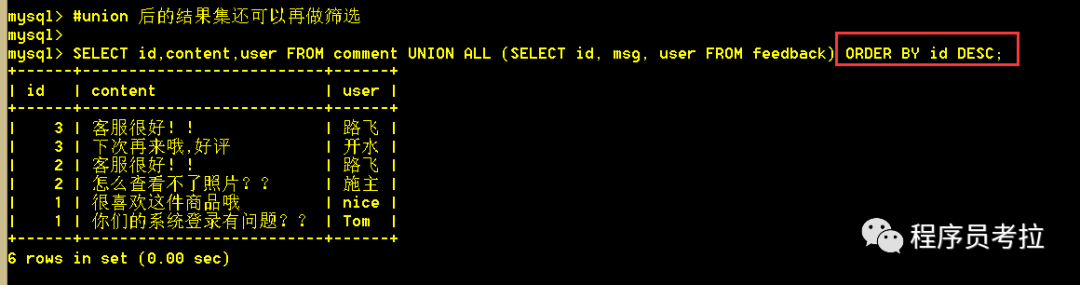
? ? ??
union查詢時(shí),order by放在內(nèi)層sql中是不起作用的;因?yàn)閡nion查出來(lái)的結(jié)果集再排序,內(nèi)層的排序就沒(méi)有意義了;因此,內(nèi)層的order by排序,在執(zhí)行期間,被mysql的代碼分析器給優(yōu)化掉了。
(SELECT?id,content,user?FROM?comment?ORDER?BY?id?DESC) UNION?ALL (SELECT?id, msg, user?FROM?feedback ORDER?BY?id?DESC);
order by 如果和limit一起使用,就顯得有意義了,就不會(huì)被優(yōu)化掉。
( SELECT?goods_name,cat_id,shop_price FROM?goods WHERE?cat_id = 3?ORDER?BY?shop_price DESC?LIMIT?3?)
UNION
( SELECT?goods_name,cat_id,shop_price FROM?goods WHERE?cat_id = 4?ORDER?BY?shop_price DESC?LIMIT?2?);
6.7、練習(xí)
SELECT?name, SUM(money) FROM?( ( SELECT?* FROM?A ) UNION?ALL ( SELECT?* FROM?B ) ) tmp GROUP?BY?name;

連接查詢總結(jié):
1、在數(shù)據(jù)庫(kù)中,一張表就是一個(gè)集合,每一行就是集合中的一個(gè)元素。連接查詢即是作笛卡爾積,比如A表有1W條數(shù)據(jù),B表有1W條數(shù)據(jù),那么兩表查詢就有 1W X 1W = 100W 條數(shù)據(jù)
2、如果在兩張表里有相同字段,做聯(lián)合查詢的時(shí)候,要區(qū)別表名,否則會(huì)報(bào)錯(cuò)誤(ambiguous 模糊不清)
3、全相乘效率低,全相乘會(huì)在內(nèi)存中生成一個(gè)非常大的數(shù)據(jù)(臨時(shí)表),因?yàn)橛泻芏嗖槐匾臄?shù)據(jù)。
?如果一張表有10000條數(shù)據(jù),另一張表有10000條數(shù)據(jù),兩表全相乘就是100W條數(shù)據(jù),是非常消耗內(nèi)存的。
而且,全相乘不能好好的利用索引,因?yàn)槿喑松梢粡埮R時(shí)表,臨時(shí)表里是沒(méi)有索引的,大大降低了查詢效率。
4、左連接查詢時(shí),以左表為主表,會(huì)將左表所有數(shù)據(jù)查詢出來(lái);左表不動(dòng),右表根據(jù)條件去一條條匹配,如果沒(méi)有滿足條件的記錄,則右邊返回NULL。
右連接查詢值,以右表為主表,會(huì)將右表所有數(shù)據(jù)查詢出來(lái),右表不動(dòng),左表則根據(jù)條件去匹配,如果左表沒(méi)有滿足條件的行,則左邊返回NULL。
左右連接是可以互換的:A left join B ?== ?B right join A (都是以A為主表) 。
左右連接既然可以互換,出于移植兼容性方面的考慮,盡量使用左連接。
5、連接查詢時(shí),雖說(shuō)也是讀取一行行記錄,然后判斷是否滿足條件,但是,連接查詢使用了索引,條件列建立了索引的話,查詢速度非常快,所以整體效率相比于全相乘要快得多,全相乘是沒(méi)有使用索引的。
使用連接查詢,查詢速度快,消耗內(nèi)存小,而且使用了索引。連接查詢效率相比于全相乘的查詢效率快了10+倍以上。
6、內(nèi)連接查詢,就是取左連接和右連接的交集,如果兩邊不能匹配條件,則都不取出。
7、MySql可以用union(聯(lián)合查詢)來(lái)查出左連接和右連接的并集。
union查詢會(huì)過(guò)濾重復(fù)的行,union all 不會(huì)過(guò)濾重復(fù)的行。
union查詢時(shí),union之間的sql列數(shù)必須相等,列名以第一條sql的列為準(zhǔn);列類型可以不一樣,但沒(méi)太大意義。
union查詢時(shí),order by放在內(nèi)層sql中是不起作用的;因?yàn)閡nion查出來(lái)的結(jié)果集再排序,內(nèi)層的排序就沒(méi)有意義了;因此,內(nèi)層的order by排序,在執(zhí)行期間,被mysql的代碼分析器給優(yōu)化掉了。
?但是,order by 如果和limit一起使用,就顯得有意義了,會(huì)影響最終結(jié)果集,就不會(huì)被優(yōu)化掉。order by會(huì)根據(jù)最終是否會(huì)影響結(jié)果集而選擇性的優(yōu)化。
注:union和union all的區(qū)別,union會(huì)去掉重復(fù)的記錄,在結(jié)果集合并后悔對(duì)新產(chǎn)生的結(jié)果集進(jìn)行排序運(yùn)算,效率稍低,union all直接合并結(jié)果集,如果確定沒(méi)有重復(fù)記錄,建議使用union all。
8、 LEFT JOIN 是 LEFT OUTER JOIN 的縮寫(xiě),同理,RIGHT JOIN 是 RIGHT OUTER JOIN 的縮寫(xiě);JOIN 是 INNER JOIN 的縮寫(xiě)。
關(guān)聯(lián)查詢
1、使用join關(guān)鍵字關(guān)聯(lián)查詢
(1)、內(nèi)連接(inner join)
連接兩張表,連接條件使用on關(guān)鍵字,內(nèi)連接只會(huì)顯示匹配的數(shù)據(jù)記錄。
eg:查詢學(xué)生姓名、科目、分?jǐn)?shù)
select?a.name 姓名,b.subject 科目,b.score 分?jǐn)?shù) from?student a inner?join?score b on?a.id = b.sid;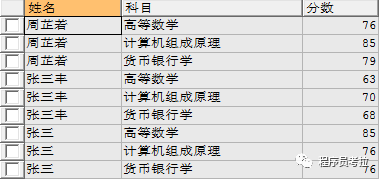
(2)、左連接(left join)
返回左表中所有記錄以及右表中符合連接條件的所有記錄。
eg:?使用左連接查詢學(xué)生姓名、科目、分?jǐn)?shù)
select?a.name 姓名,b.subject 科目,b.score 分?jǐn)?shù) from?student a left?join?score b on?a.id = b.sid;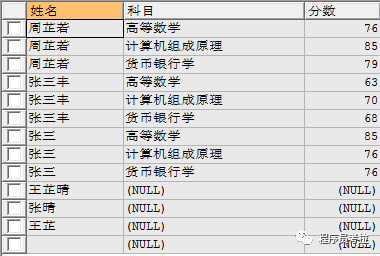
(3)、右連接(right join)
返回右表中所有記錄以及左表中符合連接條件的所有記錄。
eg:使用右連接查詢學(xué)生姓名、科目、分?jǐn)?shù)
select?a.name 姓名,b.subject 科目,b.score 分?jǐn)?shù) from?student a right?join?score b on?a.id = b.sid;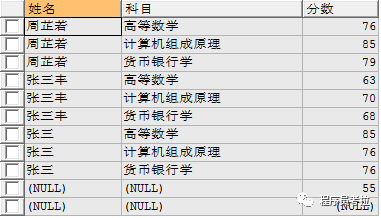
注:內(nèi)外連接區(qū)別:內(nèi)連接只會(huì)顯示匹配的數(shù)據(jù)記錄,外連接例如左連接會(huì)把左邊表中所有記錄顯示出來(lái),即使在右邊表中沒(méi)有匹配記錄也會(huì)顯示左表的數(shù)據(jù),右連接反之。
2、使用表和表之間相同id關(guān)聯(lián)查詢
這種關(guān)聯(lián)方式和內(nèi)連接一樣,只會(huì)顯示出匹配的數(shù)據(jù)
select?a.name 姓名,b.subject 科目,b.score 分?jǐn)?shù) from?student a,score b where?a.id = b.sid;原文鏈接:cnblogs.com/xiaoxi/p/6734025.html