
Python-文字識別
共 656字,需瀏覽 2分鐘
·
2022-02-09 17:41
首先還是要安裝tesseract OCR,即Optical Character Recognition,光學(xué)字符識別,谷歌開發(fā)的,在免費(fèi)庫中還是非常友好的,應(yīng)用場景比較多,比如在爬取數(shù)據(jù)時(shí)可以識別驗(yàn)證碼等,我是因?yàn)橛幸淮笈鷴呙栉募枰D(zhuǎn)換成Excel,研究了一下,中間也遇到了很多問題,接下來可以帶大家入個門。
第一步需要下載tesseract OCR安裝包(百度網(wǎng)上很多資源,如果搜到CSDN分析的文章里邊的下載地址還是比較靠譜的,如果懶得百度可以后臺私信無償發(fā)你),還是注意安裝位置,后邊要設(shè)置環(huán)境變量

第二步下載語言包,可以搜索已經(jīng)訓(xùn)練好的現(xiàn)成的語言包(GitHub官方搜索下載,如果下載不下來可以百度或者后臺私信無償發(fā))下載后解壓好,放在安裝好的文件夾下
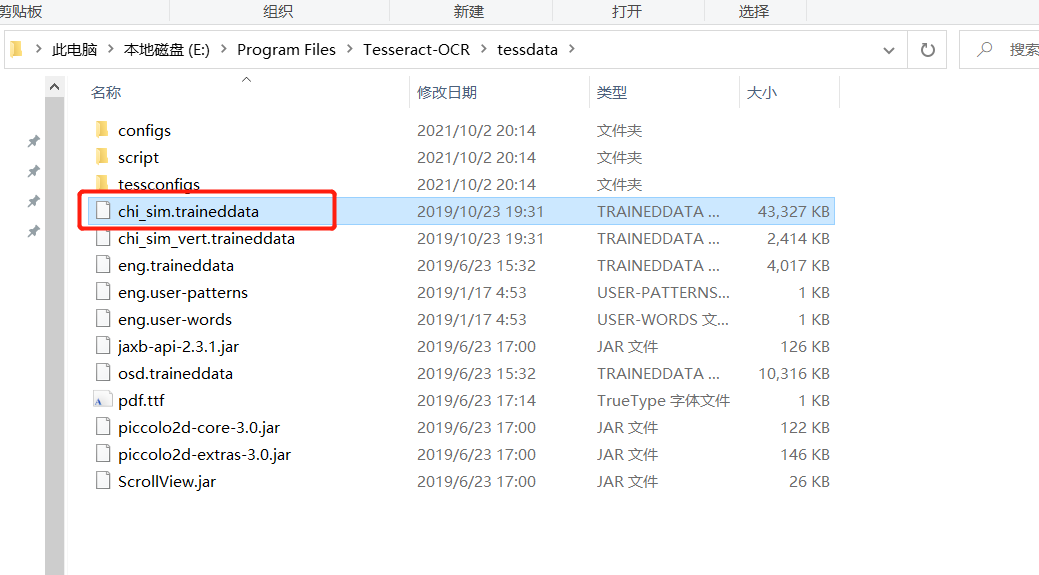
第三步配置環(huán)境變量,右擊我的電腦,屬性,高級系統(tǒng)設(shè)置,直接上圖以下是我安裝的位置
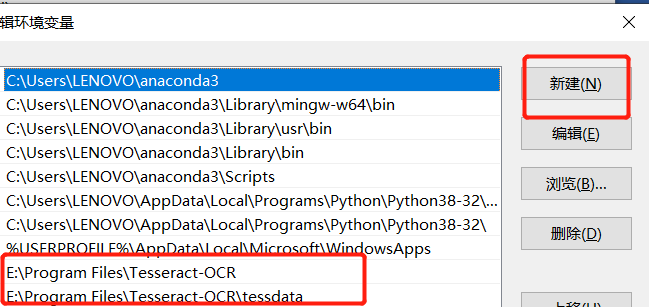
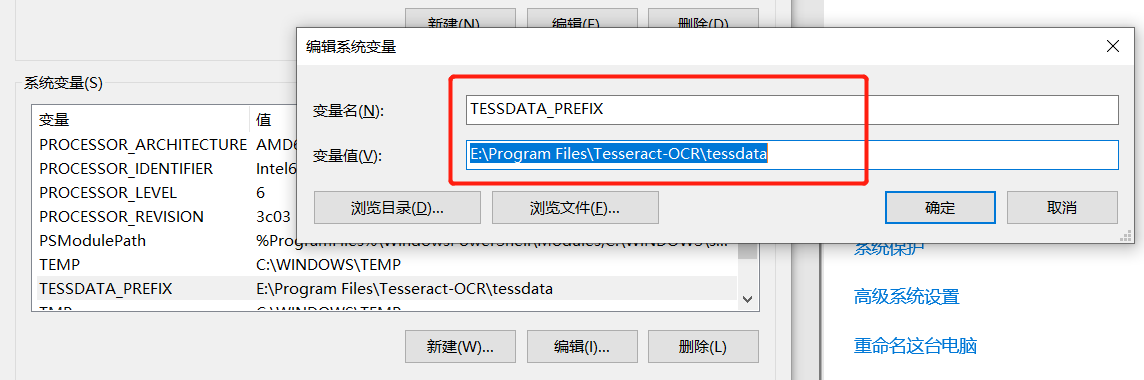
另外系統(tǒng)變量也加上
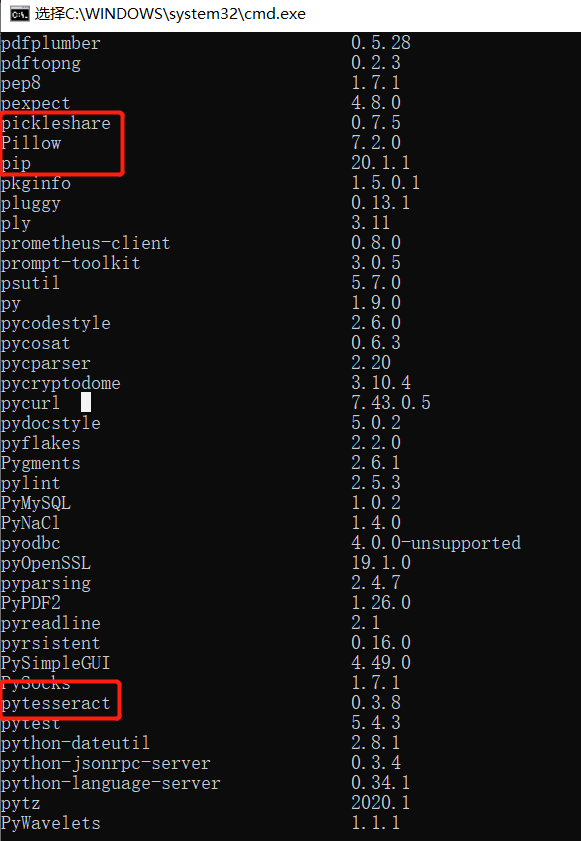
第四步安裝Python的兩個庫(打開cmd 輸入:pip install pytesseract和pip install pillow)如果安裝成功,可以輸入pip list
,可以看到下圖的安裝包。
最后的最后打開jupyter notebook,或者你的pycharm
輸入代碼,就成了
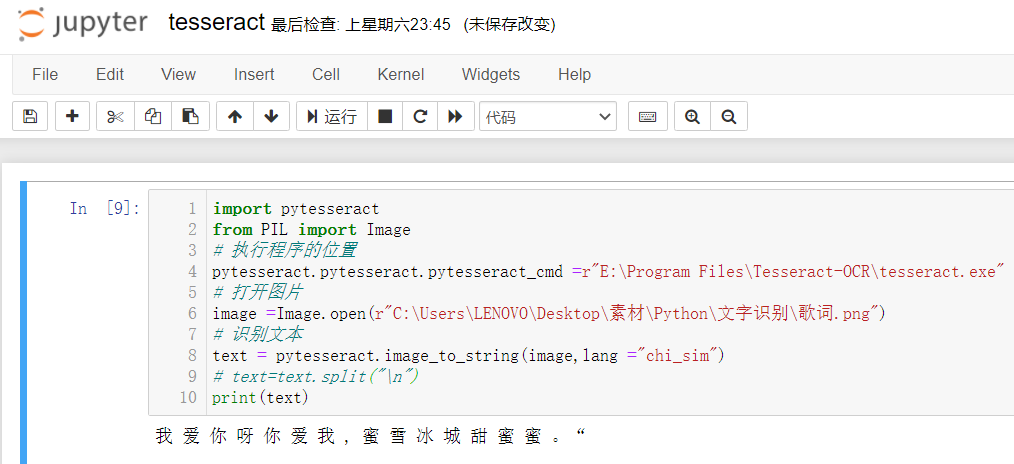
不過筆者掃描件都是表格,tesseract,識別失敗,最后用Python調(diào)用百度AI做的的識別,但是表格線和文字都黏在一起了,效果并不理想,如果清晰地表格和文字應(yīng)該是沒問題的,以后有空再把代碼分享出來。
VX“生活是個啥”“degreeoffree910”