
最近寫了寫Python
關(guān)注、星標(biāo)下方公眾號,和你一起成長
大家好,日拱一卒,我是寶器。
今天我們繼續(xù)來聊伯克利的公開課CS61A,這一次是這門課的第二個大作業(yè)。
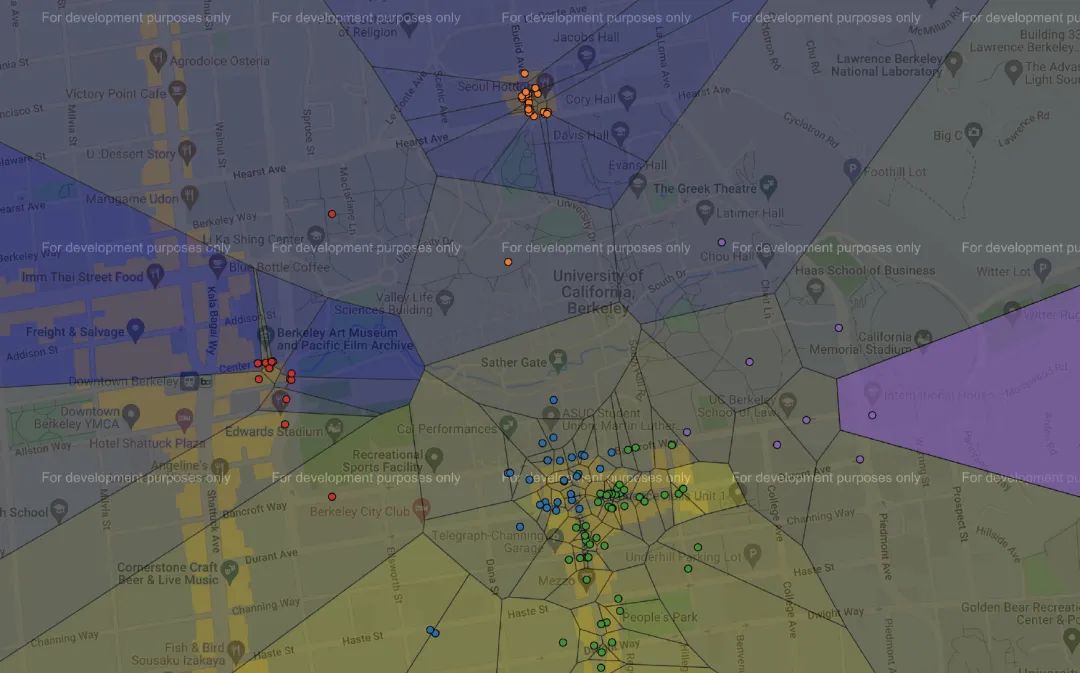
本項(xiàng)目會手把手帶著你使用機(jī)器學(xué)習(xí)算法,對伯克利附近的餐館根據(jù)用戶的評價(jià)進(jìn)行聚類,并在網(wǎng)頁當(dāng)中展示。
最后的效果大概是這樣的:
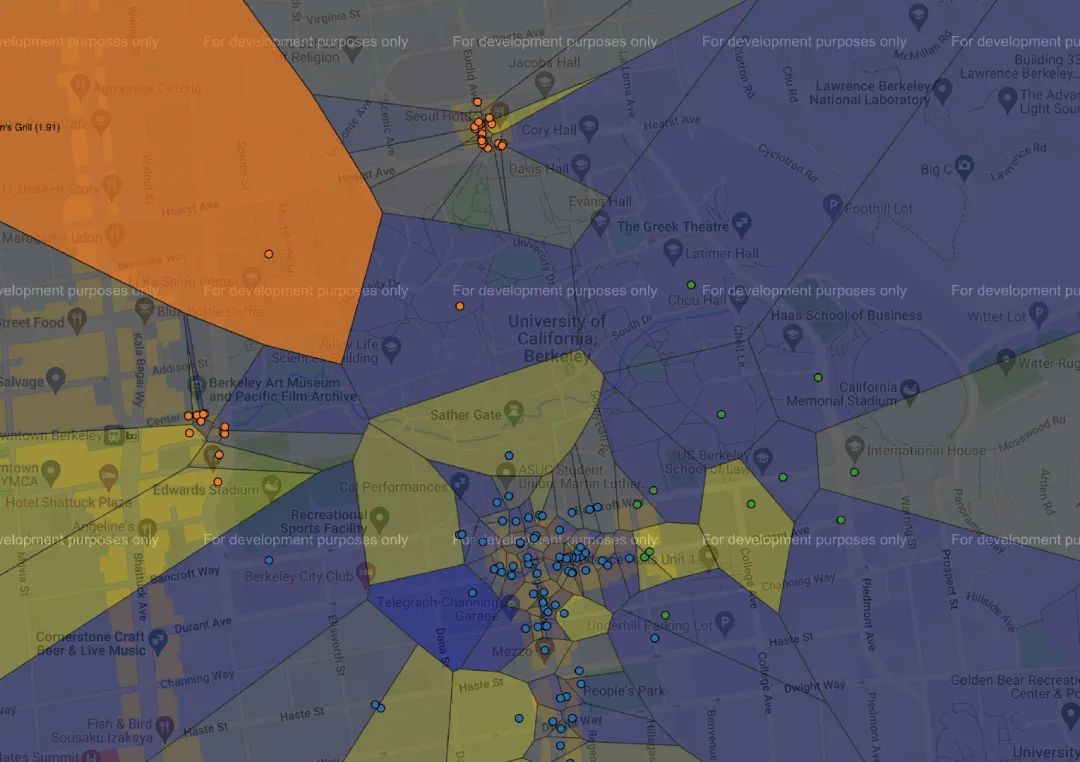
雖然項(xiàng)目當(dāng)中用到的機(jī)器學(xué)習(xí)和Python的知識都比較基礎(chǔ),但整個項(xiàng)目最后的呈現(xiàn)效果還是震撼到了我。這真是我見過最酷炫的Python作業(yè)了。
老師替我們完成了所有數(shù)據(jù)搜集和網(wǎng)頁展示的部分,我們要實(shí)現(xiàn)的是其中的核心邏輯。
項(xiàng)目網(wǎng)址:https://inst.eecs.berkeley.edu/~cs61a/sp18/proj/maps/#problem-6-2-pt
項(xiàng)目采用的都是Yelp中的真實(shí)數(shù)據(jù),Yelp可以理解成海外版的大眾點(diǎn)評。圖中的每一個點(diǎn)表示一家餐館,顏色代表了類別,類別是需要我們通過機(jī)器學(xué)習(xí)的聚類算法去實(shí)現(xiàn)的。所以項(xiàng)目當(dāng)中也會涉及一些基礎(chǔ)的機(jī)器學(xué)習(xí)知識。
完整的項(xiàng)目代碼可以點(diǎn)擊最下方【閱讀原文】跳轉(zhuǎn)我的GitHub。
階段0 工具方法
Problem 0
實(shí)現(xiàn)utils.py,即一些項(xiàng)目需要經(jīng)常使用的工具函數(shù)。
Problem 0.1 Using list comprehensions
list comprehension是如下形式的語法:
[?for??in??if?]
比如我們想要生成10以內(nèi)所有偶數(shù)的平方,我們可以這樣操作:
>>>?[x?*?x?for?x?in?range(10)?if?x?%?2?==?0]
[0,?4,?16,?36,?64]
從已有的list當(dāng)中根據(jù)filter_fn進(jìn)行過濾,過濾之后調(diào)用map_fn進(jìn)行映射之后,獲得新的list。
需要保證代碼只有一行,并且使用了list comprehension.
def?map_and_filter(s,?map_fn,?filter_fn):
????"""Returns?a?new?list?containing?the?results?of?calling?map_fn?on?each
????element?of?sequence?s?for?which?filter_fn?returns?a?true?value.
????>>>?square?=?lambda?x:?x?*?x
????>>>?is_odd?=?lambda?x:?x?%?2?==?1
????>>>?map_and_filter([1,?2,?3,?4,?5],?square,?is_odd)
????[1,?9,?25]
????"""
????#?BEGIN?Question?0
????return?[map_fn(x)?for?x?in?s?if?filter_fn(x)]
????#?END?Question?0
Problem 0.2: Using min
min函數(shù)接收一個list,返回其中最小的元素。但它同樣可以接收一個匿名函數(shù)key,用來自定義元素的排序。這個匿名函數(shù)key只能有一個輸入,它會被list中的每一個元素調(diào)用,它返回的結(jié)果將會用來進(jìn)行比較。
參考如下例子:
>>>?min([-1,?0,?1])?#?no?key?argument;?smallest?input
-1
>>>?min([-1,?0,?1],?key=lambda?x:?x*x)?#?input?with?the?smallest?square
0
我們需要實(shí)現(xiàn)key_of_min_value函數(shù),它的輸入是一個字典d。返回字典中value最小的key。
要求只能使用一行代碼,并且使用min函數(shù)。
字典在min函數(shù)當(dāng)中作用的元素都是key,所以我們實(shí)現(xiàn)一個匿名函數(shù)通過key查找value即可。
def?key_of_min_value(d):
????"""Returns?the?key?in?a?dict?d?that?corresponds?to?the?minimum?value?of?d.
????>>>?letters?=?{'a':?6,?'b':?5,?'c':?4,?'d':?5}
????>>>?min(letters)
????'a'
????>>>?key_of_min_value(letters)
????'c'
????"""
????#?BEGIN?Question?0
????return?min(d,?key=lambda?x:?d[x])
????#?END?Question?0
Problem 1
實(shí)現(xiàn)mean函數(shù),輸入是一個list,返回list的均值。要求使用assert保證序列不為空。
def?mean(s):
????"""Returns?the?arithmetic?mean?of?a?sequence?of?numbers?s.
????>>>?mean([-1,?3])
????1.0
????>>>?mean([0,?-3,?2,?-1])
????-0.5
????"""
????#?BEGIN?Question?1
????assert?len(s)?>?0,?'empty?list'
????return?sum(s)?/?len(s)
????#?END?Question?1
階段1 數(shù)據(jù)抽象
Problem 2
實(shí)現(xiàn)abstractions.py文件中restaurant的構(gòu)造和選擇函數(shù)。
make_restaurant函數(shù): 返回一個餐館,它由5個字段組成:name(a string)location(a list containing latitude and longitude)categories(a list of strings)price(a number)reviews(a list of review data abstractions created bymake_review)restaurant_name: 返回restaurant名稱restaurant_location: 返回restaurant位置restaurant_categories: 返回restaurant類別restaurant_price: 返回restaurant價(jià)格restaurant_ratings: 返回restaurant評分
我們只需要仿照文件中的樣例進(jìn)行實(shí)現(xiàn)即可:
def?make_restaurant(name,?location,?categories,?price,?reviews):
????"""Return?a?restaurant?data?abstraction?containing?the?name,?location,
????categories,?price,?and?reviews?for?that?restaurant."""
????#?BEGIN?Question?2
????"***?YOUR?CODE?HERE?***"
????return?[name,?location,?categories,?price,?reviews]
????#?END?Question?2
def?restaurant_name(restaurant):
????"""Return?the?name?of?the?restaurant,?which?is?a?string."""
????#?BEGIN?Question?2
????"***?YOUR?CODE?HERE?***"
????return?restaurant[0]
????#?END?Question?2
def?restaurant_location(restaurant):
????"""Return?the?location?of?the?restaurant,?which?is?a?list?containing
????latitude?and?longitude."""
????#?BEGIN?Question?2
????"***?YOUR?CODE?HERE?***"
????return?restaurant[1]
????#?END?Question?2
def?restaurant_categories(restaurant):
????"""Return?the?categories?of?the?restaurant,?which?is?a?list?of?strings."""
????#?BEGIN?Question?2
????"***?YOUR?CODE?HERE?***"
????return?restaurant[2]
????#?END?Question?2
def?restaurant_price(restaurant):
????"""Return?the?price?of?the?restaurant,?which?is?a?number."""
????#?BEGIN?Question?2
????"***?YOUR?CODE?HERE?***"
????return?restaurant[3]
????#?END?Question?2
def?restaurant_ratings(restaurant):
????"""Return?a?list?of?ratings,?which?are?numbers?from?1?to?5,?of?the
????restaurant?based?on?the?reviews?of?the?restaurant."""
????#?BEGIN?Question?2
????"***?YOUR?CODE?HERE?***"
????return?[review_rating(r)?for?r?in?restaurant[4]]
????#?END?Question?2
實(shí)現(xiàn)結(jié)束之后,你可以運(yùn)行命令python3 recommend.py -u來查看指定用戶評分過的店。如運(yùn)行如下命令之后,打開網(wǎng)頁內(nèi)容為:
python3?recommend.py?-u?one_cluster
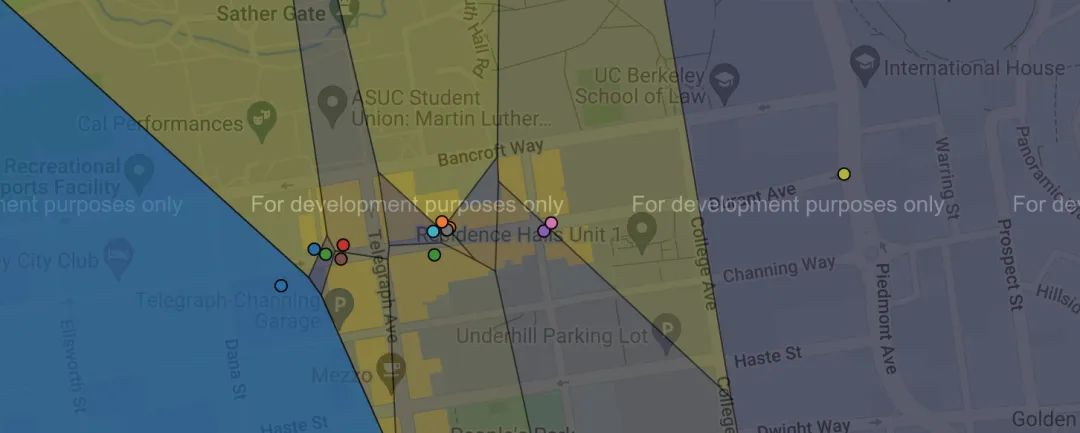
階段2 無監(jiān)督學(xué)習(xí)
在這個階段我們需要使用無監(jiān)督學(xué)習(xí)中的聚類算法,將比較接近的餐館聚成一類。
我們使用的是k-means算法,它是一個經(jīng)典的無監(jiān)督聚類算法。它可以將一堆數(shù)據(jù)按照距離,聚集成k個類別。它的算法原理非常簡單,初始化時會從數(shù)據(jù)當(dāng)中隨意選擇k個點(diǎn)作為類簇(類別中心)。然后重復(fù)執(zhí)行兩個步驟,直到類簇不再發(fā)生變化:
根據(jù)距離類簇距離的遠(yuǎn)近,將樣本點(diǎn)分成k個類別 將k個類別中的點(diǎn)的坐標(biāo)取平均,得到新的類簇
在實(shí)現(xiàn)算法的過程當(dāng)中,可能會遇到一些術(shù)語,這里做出解釋:
location: 餐廳的坐標(biāo),可以表示成經(jīng)緯度的集合:(latitude, longitude) centroid: 某個類別的中心坐標(biāo)(所有點(diǎn)的坐標(biāo)均值) restaurant: 餐廳信息的抽象,定義在 abstractions.py文件中cluster: 聚集在同一個類別的餐廳list user: 用戶信息的抽象,定義在 abstractions.py文件中review: 評分信息的抽象, 定義在 abstractions.py文件中feature function: 特征函數(shù),單個參數(shù)函數(shù)。以餐廳為輸入,返回一個浮點(diǎn)值,比如打分的均值或者是價(jià)格的均值
Problem 3
實(shí)現(xiàn)find_closest函數(shù),輸入一個坐標(biāo)location和centroid集合(類簇坐標(biāo)),返回距離location最近的centroid。
需要使用utils.py中的distance函數(shù)來計(jì)算兩個location的距離,如果兩個centroid等距離,返回序號較小的那個。
#?distance函數(shù)
def?distance(pos1,?pos2):
????"""Returns?the?Euclidean?distance?between?pos1?and?pos2,?which?are?pairs.
????>>>?distance([1,?2],?[4,?6])
????5.0
????"""
????return?sqrt((pos1[0]?-?pos2[0])?**?2?+?(pos1[1]?-?pos2[1])?**?2)
仿照剛剛min函數(shù)的使用方法,我們可以只需要一行代碼就可以搞定:
def?find_closest(location,?centroids):
????"""Return?the?centroid?in?centroids?that?is?closest?to?location.
????If?multiple?centroids?are?equally?close,?return?the?first?one.
????>>>?find_closest([3.0,?4.0],?[[0.0,?0.0],?[2.0,?3.0],?[4.0,?3.0],?[5.0,?5.0]])
????[2.0,?3.0]
????"""
????#?BEGIN?Question?3
????"***?YOUR?CODE?HERE?***"
????return?min(centroids,?key=lambda?x:?distance(location,?x))
????#?END?Question?3
Problem 4
實(shí)現(xiàn)group_by_centroid函數(shù),輸入是restaurant的list和centroids的list,返回cluster的數(shù)組。
每一個cluster是一個restaurant的list,這些restaurant有一個共同點(diǎn),它們距離某一個特定的centroid比其他的centroid更近。可以無視返回clusters中的順序。
如果一家restaurant距離多個centroid相同距離,選擇序號最小的那個。
提示:使用提供的
group_by_first函數(shù)實(shí)現(xiàn)
group_by_first函數(shù)代碼如下:
def?group_by_first(pairs):
????"""Return?a?list?of?pairs?that?relates?each?unique?key?in?the?[key,?value]
????pairs?to?a?list?of?all?values?that?appear?paired?with?that?key.
????Arguments:
????pairs?--?a?sequence?of?pairs
????>>>?example?=?[?[1,?2],?[3,?2],?[2,?4],?[1,?3],?[3,?1],?[1,?2]?]
????>>>?group_by_first(example)
????[[2,?3,?2],?[2,?1],?[4]]
????"""
????keys?=?[]
????for?key,?_?in?pairs:
????????if?key?not?in?keys:
????????????keys.append(key)
????return?[[y?for?x,?y?in?pairs?if?x?==?key]?for?key?in?keys]
這段函數(shù)的輸入是一個pair的list,pair是一個
我們的目的是將restaurant根據(jù)距離最近的centroid進(jìn)行分類,有了group_by_first函數(shù)之后,我們可以生成[[restaurant, centroid]]形式的數(shù)據(jù),調(diào)用group_by_first完成目標(biāo)。
def?group_by_centroid(restaurants,?centroids):
????"""Return?a?list?of?clusters,?where?each?cluster?contains?all?restaurants
????nearest?to?a?corresponding?centroid?in?centroids.?Each?item?in
????restaurants?should?appear?once?in?the?result,?along?with?the?other
????restaurants?closest?to?the?same?centroid.
????"""
????#?BEGIN?Question?4
????"***?YOUR?CODE?HERE?***"
????pairs?=?[[find_closest(restaurant_location(r),?centroids),?r]?for?r?in?restaurants]
????return?group_by_first(pairs)
????#?END?Question?4
Problem 5
實(shí)現(xiàn)find_centroid函數(shù),根據(jù)cluster中點(diǎn)的坐標(biāo)均值計(jì)算中心點(diǎn)。
提示:使用utils中的mean函數(shù)實(shí)現(xiàn)邏輯
def?find_centroid(cluster):
????"""Return?the?centroid?of?the?locations?of?the?restaurants?in?cluster."""
????#?BEGIN?Question?5
????"***?YOUR?CODE?HERE?***"
????latitudes,?longitudes?=?[],?[]
????for?c?in?cluster:
????????loc?=?restaurant_location(c)
????????latitudes.append(loc[0])
????????longitudes.append(loc[1])
????return?[mean(latitudes),?mean(longitudes)]
????#?END?Question?5
Problem 6
實(shí)現(xiàn)k_means函數(shù)完成kmeans算法,代碼中已經(jīng)實(shí)現(xiàn)了算法中的第一個步驟。follow接下來的步驟完成while語句:
將 restaurant聚類,每一個類簇中的restaurant最接近的centroid一樣根據(jù)聚類的結(jié)果,更新 centroids
提示:可以使用
group_by_centroid和find_centroid函數(shù)
其實(shí)只要理解了group_by_centroid和find_centroid函數(shù)的邏輯,以及kmeans的算法原理之后,不難實(shí)現(xiàn)。代碼如下:
def?k_means(restaurants,?k,?max_updates=100):
????"""Use?k-means?to?group?restaurants?by?location?into?k?clusters."""
????assert?len(restaurants)?>=?k,?'Not?enough?restaurants?to?cluster'
????old_centroids,?n?=?[],?0
????#?Select?initial?centroids?randomly?by?choosing?k?different?restaurants
????centroids?=?[restaurant_location(r)?for?r?in?sample(restaurants,?k)]
????while?old_centroids?!=?centroids?and?n?????????old_centroids?=?centroids
????????#?BEGIN?Question?6
????????"***?YOUR?CODE?HERE?***"
????????pairs?=?group_by_centroid(restaurants,?centroids)
????????centroids?=?[find_centroid(l)?for?l?in?pairs]
????????#?END?Question?6
????????n?+=?1
????return?centroids
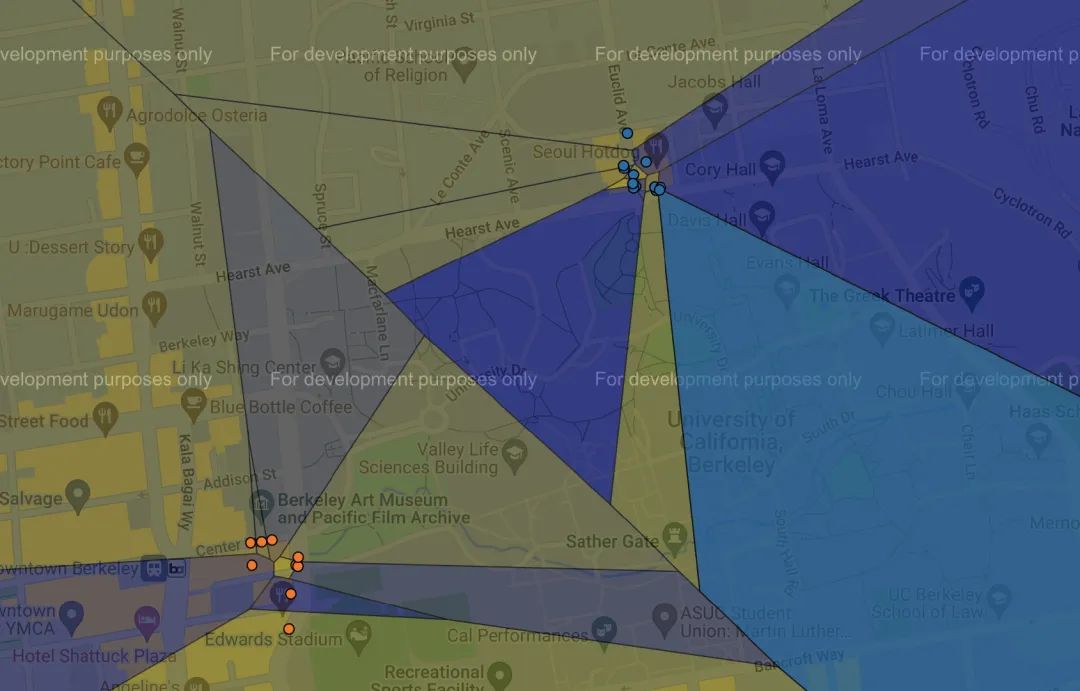
我們可以使用如下命令測試:
python3?recommend.py?-k?2
結(jié)果如下:
階段3 有監(jiān)督學(xué)習(xí)
在這個階段,我們要預(yù)測用戶對于一個餐廳的打分。我們需要使用機(jī)器學(xué)習(xí)中的有監(jiān)督學(xué)習(xí)算法,來預(yù)測用戶對于一家沒有去過的餐廳的打分。簡單來說,就是從已有的用戶打分的數(shù)據(jù)當(dāng)中訓(xùn)練一個模型,讓模型能夠根據(jù)歷史數(shù)據(jù)做出盡可能精準(zhǔn)的預(yù)測。
當(dāng)完成這個階段之后,你的可視化結(jié)果將會包含所有的餐廳,而非只有用戶有過打分的餐廳。
要預(yù)測打分,需要使用最小二乘法訓(xùn)練線性回歸模型,這是機(jī)器學(xué)習(xí)領(lǐng)域一個常用的回歸模型。它可以學(xué)習(xí)一些特征和待預(yù)測結(jié)果之間的線性關(guān)聯(lián),從而做出預(yù)測。
算法讀入一系列的輸入和輸出的pair,返回一個斜線,使得它距離所有樣本點(diǎn)的距離的平方和最小。
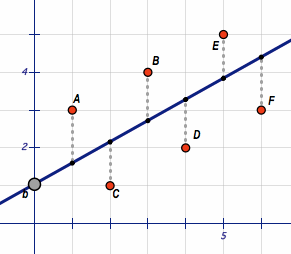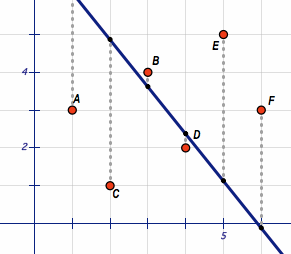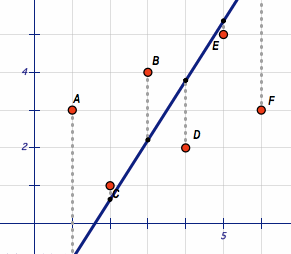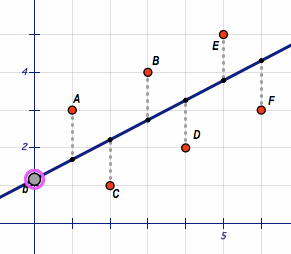
Problem 7
實(shí)現(xiàn)find_predictor函數(shù),輸入一個user,一系列restaurant和一個特征提取函數(shù)feature_fn。
函數(shù)返回兩個值:predictor和一個r_squared值。使用最小二乘法來計(jì)算predictor和r_squared。這個方法描述如下:
計(jì)算precitor中的系數(shù)a和b,它表示一個線性函數(shù):y = a + bx。r_squared衡量模型和原始數(shù)據(jù)的精確度。
我們可以使用如下的公式計(jì)算三個值::
Sxx = Σi (xi - mean(x))2 Syy = Σi (yi - mean(y))2 Sxy = Σi (xi - mean(x) (yi - mean(y)
計(jì)算出這三個值之后,我們可以代入如下公式計(jì)算出a和b以及r_squared:
b = Sxy / Sxx a = mean(y) - b * mean(x) R2 = Sxy2 / (Sxx Syy)
提示:可以使用
mean和zip函數(shù)
其實(shí)算法的實(shí)現(xiàn)沒有難度,公式已經(jīng)給我們寫好了,我們只需要按照公式實(shí)現(xiàn)即可。
比較麻煩的其實(shí)是這個公式的推導(dǎo),需要基于最小二乘法和線性回歸模型,大家感興趣可以去補(bǔ)一下這部分內(nèi)容。
def?find_predictor(user,?restaurants,?feature_fn):
????"""Return?a?rating?predictor?(a?function?from?restaurants?to?ratings),
????for?a?user?by?performing?least-squares?linear?regression?using?feature_fn
????on?the?items?in?restaurants.?Also,?return?the?R^2?value?of?this?model.
????Arguments:
????user?--?A?user
????restaurants?--?A?sequence?of?restaurants
????feature_fn?--?A?function?that?takes?a?restaurant?and?returns?a?number
????"""
????reviews_by_user?=?{review_restaurant_name(review):?review_rating(review)
???????????????????????for?review?in?user_reviews(user).values()}
????xs?=?[feature_fn(r)?for?r?in?restaurants]
????ys?=?[reviews_by_user[restaurant_name(r)]?for?r?in?restaurants]
????#?BEGIN?Question?7
????x_mean?=?mean(xs)
????sxx?=?sum([(x?-?x_mean)**2?for?x?in?xs])
????y_mean?=?mean(ys)
????syy?=?sum([(y?-?y_mean)**2?for?y?in?ys])
????sxy?=?sum([(x?-?x_mean)*(y?-?y_mean)?for?x,?y?in?zip(xs,?ys)])
????b?=?sxy?/?sxx??#?REPLACE?THIS?LINE?WITH?YOUR?SOLUTION
????a?=?y_mean?-?b?*?x_mean
????r_squared?=?sxy?*?sxy?/?(sxx?*?syy)
????#?END?Question?7
????def?predictor(restaurant):
????????return?b?*?feature_fn(restaurant)?+?a
????return?predictor,?r_squared
Problem 8
實(shí)現(xiàn)best_predictor函數(shù),輸入user和restaurant的list,以及feature_fns的list。
它使用每一個特征函數(shù)來計(jì)算predictor,并且返回r_squared最高的predictor。
所有的predictor都是基于用戶有過評論的餐廳列表學(xué)習(xí)的,所以我們需要使用reviewed函數(shù)來進(jìn)行過濾,這個函數(shù)在之前已經(jīng)實(shí)現(xiàn)。
提示:
max函數(shù)也可以接收一個key參數(shù),和min一樣
使用我們剛才開發(fā)的find_predictor函數(shù),通過返回的r_squared找出最大的predictor即可。
def?best_predictor(user,?restaurants,?feature_fns):
????"""Find?the?feature?within?feature_fns?that?gives?the?highest?R^2?value
????for?predicting?ratings?by?the?user;?return?a?predictor?using?that?feature.
????Arguments:
????user?--?A?user
????restaurants?--?A?list?of?restaurants
????feature_fns?--?A?sequence?of?functions?that?each?takes?a?restaurant
????"""
????reviewed?=?user_reviewed_restaurants(user,?restaurants)
????#?BEGIN?Question?8
????"***?YOUR?CODE?HERE?***"
????dt?=?{}
????for?feature_fn?in?feature_fns:
????????predictor,?r_squared?=?find_predictor(user,?reviewed,?feature_fn)
????????dt[predictor]?=?r_squared
????return?max(dt,?key=lambda?x:?dt[x])
????#?END?Question?8
Problem 9
實(shí)現(xiàn)rate_all函數(shù),入?yún)橐粋€user和一個restaurant的list,以及feature_fns的list。它返回一個dictionary,它的key是restaurant的名稱,它的value是評分(rating)。
如果restaurant之前用戶評分過,直接使用歷史評分,否則使用predictor進(jìn)行預(yù)測。predictor已經(jīng)使用feature_fns獲得。
提示:你可以使用
abstractions.py中的user_rating函數(shù)
邏輯并不復(fù)雜,我們枚舉一下restaurant,判斷它是否出現(xiàn)在了用戶評論的列表中,如果沒有則使用predictor進(jìn)行預(yù)測,否則使用user_rating函數(shù)獲取評分。
def?rate_all(user,?restaurants,?feature_fns):
????"""Return?the?predicted?ratings?of?restaurants?by?user?using?the?best
????predictor?based?on?a?function?from?feature_fns.
????Arguments:
????user?--?A?user
????restaurants?--?A?list?of?restaurants
????feature_fns?--?A?sequence?of?feature?functions
????"""
????predictor?=?best_predictor(user,?ALL_RESTAURANTS,?feature_fns)
????reviewed?=?user_reviewed_restaurants(user,?restaurants)
????#?BEGIN?Question?9
????"***?YOUR?CODE?HERE?***"
????return?{restaurant_name(r):?user_rating(user,?restaurant_name(r))?if?r?in?reviewed?else?predictor(r)?for?r?in?restaurants}
????#?END?Question?9
實(shí)現(xiàn)之后, 我們可以使用如下命令測試:
python3?recommend.py?-u?likes_southside?-k?5?-p
結(jié)果如下:
Problem 10
實(shí)現(xiàn)search函數(shù),它的輸入是一個query,它是string類型,表示一個類別。返回所有擁有這個類別的restaurant。
提示:我們可以使用list comprehension
每一個restaurant都有categories屬性,是若干category的list。我們只需要判斷category是否在categories當(dāng)中即可。
def?search(query,?restaurants):
????"""Return?each?restaurant?in?restaurants?that?has?query?as?a?category.
????Arguments:
????query?--?A?string
????restaurants?--?A?sequence?of?restaurants
????"""
????#?BEGIN?Question?10
????"***?YOUR?CODE?HERE?***"
????return?[r?for?r?in?restaurants?if?query?in?restaurant_categories(r)]
????#?END?Question?10
實(shí)現(xiàn)完成之后,可以使用如下命令測試:
python3?recommend.py?-u?likes_expensive?-k?2?-p?-q?Sandwiches
結(jié)果如下:
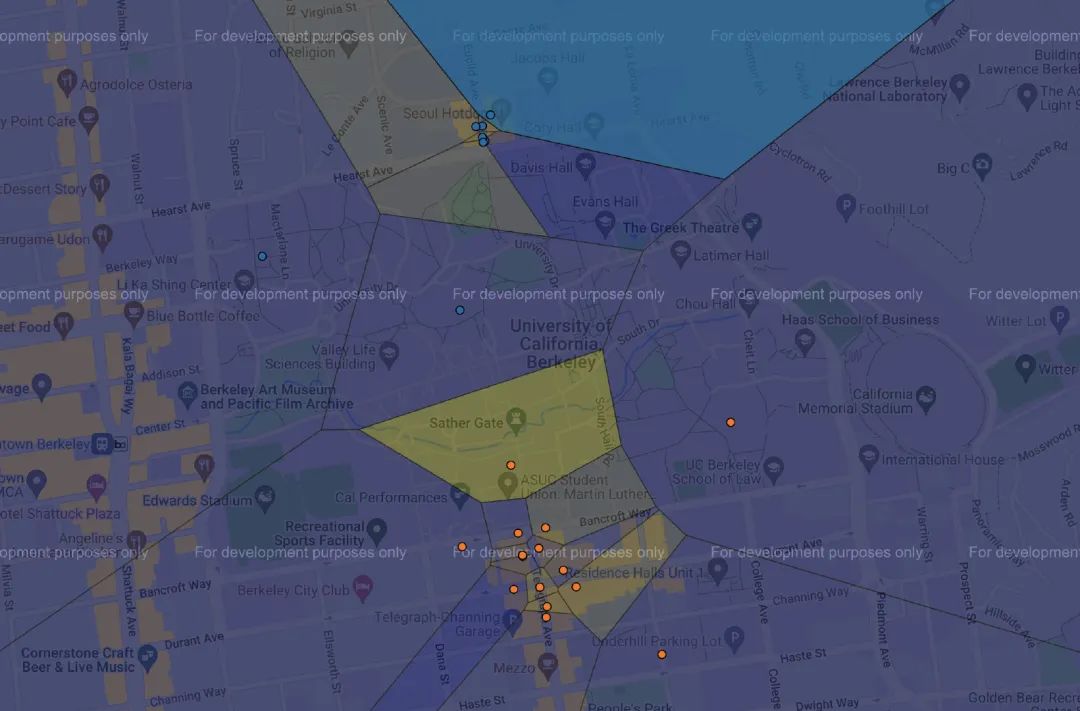
如果你愿意,還可以自行在users文件夾當(dāng)中創(chuàng)建屬于你的評分?jǐn)?shù)據(jù)來進(jìn)行演示。
只不過由于我們并不在伯克利,對于伯克利附近的餐廳就更一無所知了,所以也就無從說起……
雖然這個項(xiàng)目看起來很大很復(fù)雜,但實(shí)際上我整個編碼只用了一兩個小時,整體的體驗(yàn)非常好。雖然ui頁面不是我們寫的,但是調(diào)試的時候,看到酷炫的結(jié)果,還是非常非常有成就感。而且整體的代碼質(zhì)量很不錯,非常值得學(xué)習(xí)。

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」