
Impala 應(yīng)用 | Impala 在騰訊金融大數(shù)據(jù)場景中的應(yīng)用

導(dǎo)讀:在騰訊金融場景,我們每天都會產(chǎn)生大量的數(shù)據(jù),為了提升分析的交互性,讓決策更加敏捷,我們引入了Impala來解決我們的分析需求。所以,本文將和大家分享Impala在騰訊金融大數(shù)據(jù)場景中的應(yīng)用架構(gòu),Impala的原理,落地過程的案例和優(yōu)化以及總結(jié)思考。
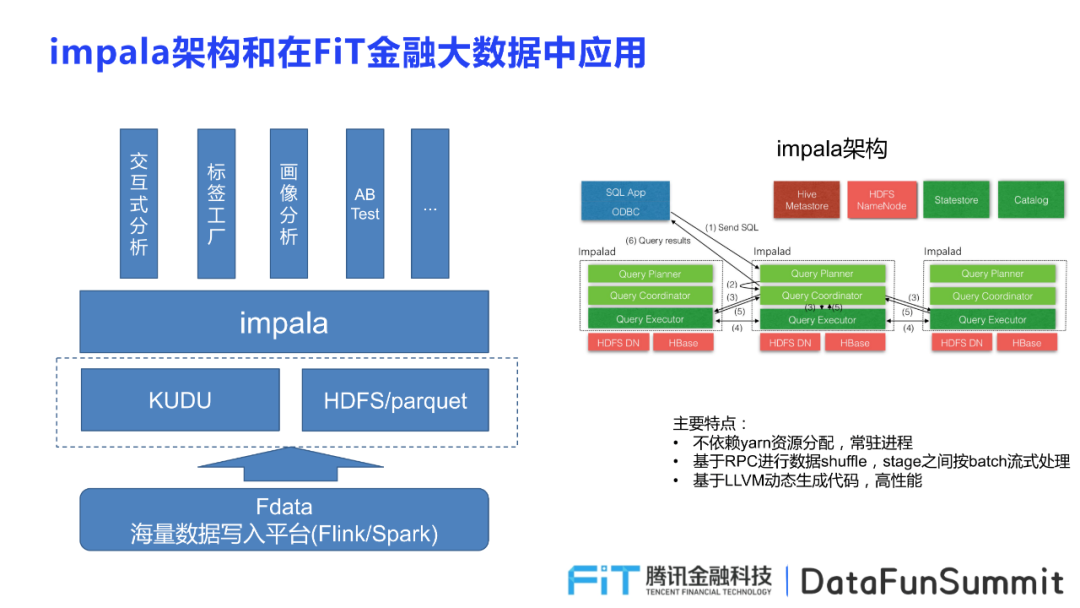
首先介紹Impala的整體架構(gòu),幫助大家從宏觀角度理解整個(gè)Impala系統(tǒng),掌握框架上的知識和概念。
Impala存儲的方式分為兩種分別是Kudu和HDFS,其中Kudu實(shí)時(shí)點(diǎn)擊流的場景,HDFS存儲大多數(shù)據(jù)。
Impala應(yīng)用包括以下幾類:
交互式分析:主要指對用戶進(jìn)行多維數(shù)據(jù)分析,進(jìn)行數(shù)據(jù)建構(gòu);
標(biāo)簽工廠:允許業(yè)務(wù)人員根據(jù)不同用戶屬性和事件屬性進(jìn)行標(biāo)簽的構(gòu)建,生成各具特性的標(biāo)簽集合,供業(yè)務(wù)具體使用;
畫像分析:生成用戶包并將其提供給業(yè)務(wù)人員,允許其查看用戶的標(biāo)簽,為具體的業(yè)務(wù)工作提供參考;
ABTest:在ABtest中,提供數(shù)據(jù)分析支撐,提高運(yùn)行速度,增添效率。
Impala的主要特點(diǎn):Impala是在Hadoop大數(shù)據(jù)的框架中構(gòu)建查詢引擎,并主要依賴Hive和HDFS的組建,并通過Fdata將海量數(shù)據(jù)寫入平臺,從而為業(yè)務(wù)方提供高效便捷的數(shù)據(jù)查詢功能。
不依賴yam資源分配,常駐進(jìn)程;
基于RPC進(jìn)行數(shù)據(jù)shuffle,stage之間按batch流式處理;
基于LLVM動態(tài)生成代碼,高性能。
在從宏觀角度整體了解了Impala的架構(gòu)之后,接下來,為大家介紹Impala的兩個(gè)重要原理,分別是并發(fā)原理和基于CBO的表關(guān)聯(lián)優(yōu)化原理。
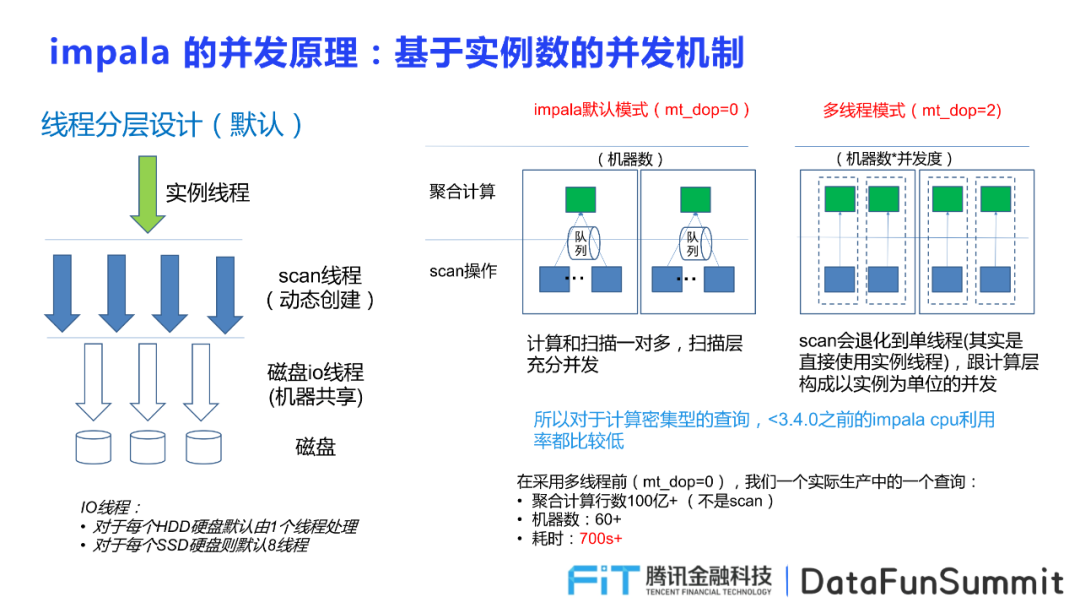
1.?線程的分層
主要包括三類,分別是實(shí)例線程,數(shù)據(jù)掃描scan線程(解壓縮),io線程。在impala的默認(rèn)模式下,實(shí)現(xiàn)了計(jì)算和掃描一對多,掃描層充分開發(fā),但在多線程模式下,在掃描層化為單線程直接使用實(shí)例線程,跟計(jì)算層構(gòu)成以實(shí)例為單位的開發(fā)。
2.?遇到的兩個(gè)問題
① 高并發(fā)下抖動嚴(yán)重,原因出現(xiàn)在RPC相關(guān)的EXCHANGE:因?yàn)樵诟卟l(fā)狀態(tài)下,數(shù)據(jù)由sender端push給Receiver端,且Receiver端由BatchQueue進(jìn)行接受,一旦隊(duì)列滿了或者deferred不為空,就會傳輸給deferredRPCS,因此極容易導(dǎo)致隊(duì)列堆積。
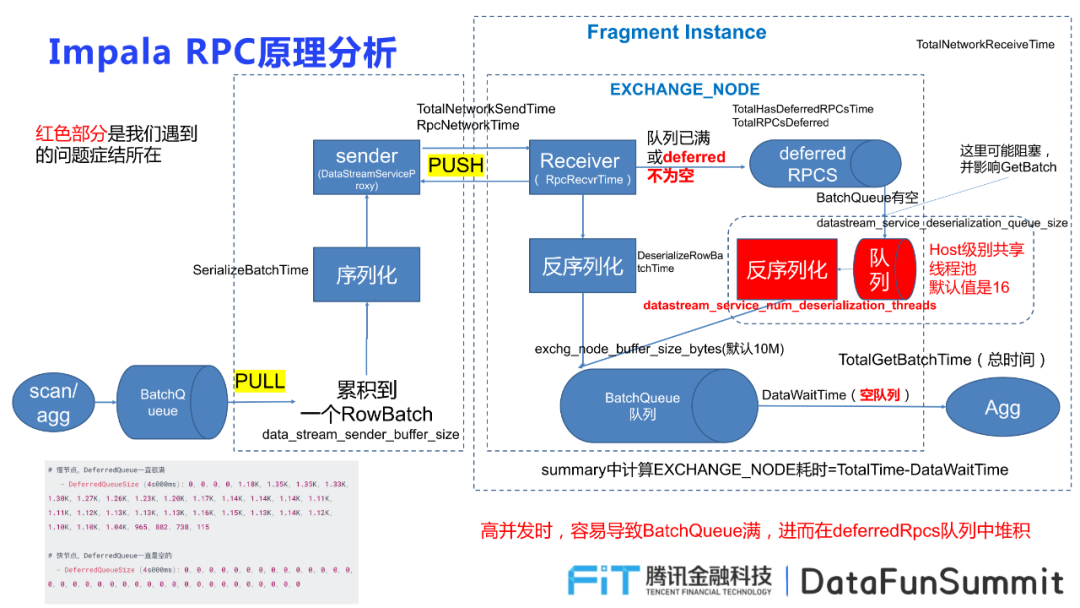
解決方式,首先將參數(shù):
datastream_service_num_deserialization_threads
進(jìn)行調(diào)整,因?yàn)闄C(jī)器CPU超線程數(shù)為96,所以將該參數(shù)調(diào)整到80,成功地提高了在高并發(fā)狀態(tài)下地穩(wěn)定性,提高了數(shù)據(jù)查詢地有效性。
② Cast to string問題,導(dǎo)致并發(fā)不增反降,對查詢效率帶來極大的影響。
3.?并發(fā)特性的制約因素
并發(fā)的最小顆粒度為文件,因此當(dāng)表字段比較少,且按照文件大小生成文件,將導(dǎo)致在同一個(gè)文件中所包含的行數(shù)增多,并發(fā)度降低;若選擇將文件拆開提高并行度,但獲取的數(shù)據(jù)量變小,導(dǎo)致磁盤的io效率降低。因此從這兩方面來說,均制約了Impala的并發(fā)。

1.?基本工作
運(yùn)用Impala表關(guān)聯(lián)優(yōu)化原理,首要是統(tǒng)計(jì)信息的采集規(guī)則的制定,包括行數(shù),字段的選擇,以及join類型的選擇,是broadcast,partition,順序的選擇,是大表在左還是小表在左;
基于平均分布對每個(gè)關(guān)聯(lián)子表的數(shù)據(jù)量進(jìn)行預(yù)估,并判斷大小表從而選擇合理的順序。

2.?三個(gè)問題
① Outer join出現(xiàn)數(shù)據(jù)傾斜,采取軸心表策略控制join的順序,提升效率。
比如因?yàn)閮杀碜隽藘纱蔚膃xchange,所以A表join B表之后重新exchange導(dǎo)致大量NULL數(shù)據(jù)傾斜,對于這一問題采取的解決方案是軸心表策略,從join的順序上控制數(shù)據(jù)的問題。該策略是基于RBO規(guī)則的,首先結(jié)合CBO預(yù)估子查詢的數(shù)據(jù)量,以某個(gè)子查詢?yōu)檩S心,將其他的查詢以這個(gè)表作為首位進(jìn)行排列,并采用straight_join控制join的順序,從而順利解決該問題。并且在優(yōu)化前后,效率得到了一個(gè)極大地提升。

② 多個(gè)表group不一致導(dǎo)致多余的exchange,不同地子查詢有不同地groupby順序,頻繁地交換數(shù)據(jù)產(chǎn)出地順序,帶來大量數(shù)據(jù)冗余,降低了后續(xù)相關(guān)數(shù)據(jù)查詢地效率,因此解決這個(gè)問題需要保證多個(gè)表在執(zhí)行g(shù)roup?by順序一致,才能有效減少exchange地次數(shù),從而提高效率
③ 平均分布假設(shè)引發(fā)的預(yù)估偏差導(dǎo)致broadcast join,因?yàn)閕mpala在實(shí)踐查詢之前,會基于平均分布假設(shè)預(yù)估生成表地?cái)?shù)據(jù)量,但一旦產(chǎn)生偏差,就會導(dǎo)致broadcast join地發(fā)生,從而影響該次查詢的效率。
3.?廣泛應(yīng)用
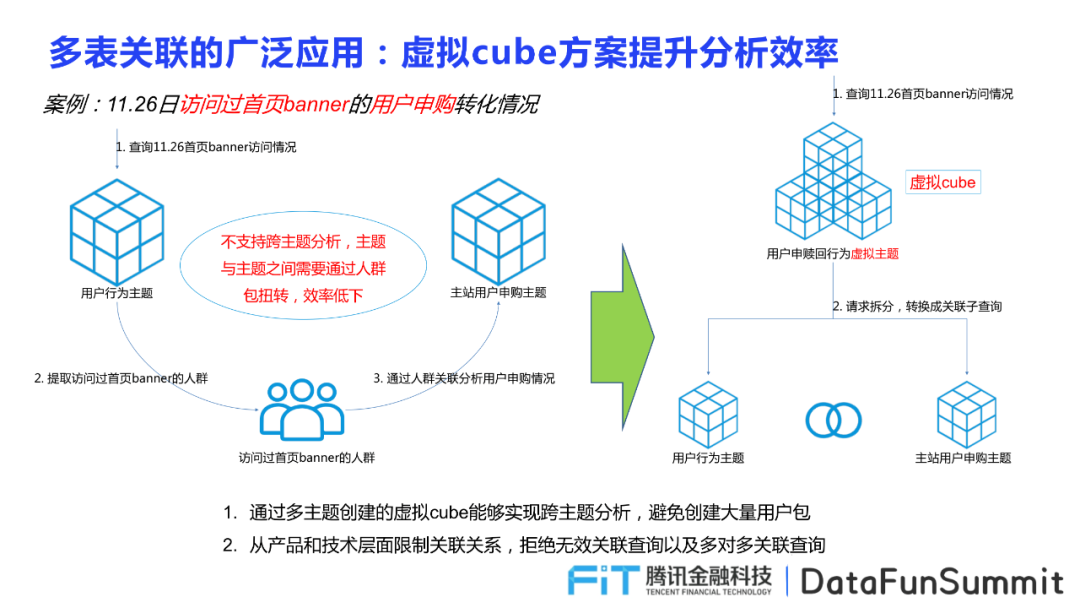
針對跨主題分析的情況,采用多表關(guān)聯(lián)的虛擬cube方案,避免創(chuàng)建大量用戶包,并嘗試從產(chǎn)品和技術(shù)層面限制關(guān)聯(lián)關(guān)系,減少無效關(guān)聯(lián)查詢和多對多關(guān)聯(lián)查詢。
比如需要查詢11.26日訪問過首頁banner的用戶申購轉(zhuǎn)化情況,首先需要根據(jù)訪問11.26首頁banner的用戶數(shù)據(jù),生成用戶行為主題,隨后提取所有訪問過首頁banner的人群,通過人群關(guān)聯(lián)分析整個(gè)用戶申購的情況,申城主站用戶申購的主題。這一過程反映了原來的分析模型不支持主題分析,主題和主題之間需要通過人群包進(jìn)行轉(zhuǎn)化,效率低下。
但在運(yùn)用了impala的多表關(guān)聯(lián)功能之后,可以將用戶申贖回行為的虛擬主題這以請求進(jìn)行拆分,轉(zhuǎn)換成關(guān)聯(lián)子查詢,分為用戶行為主題和主站用戶申購主題,極大的提高了效率,也避免了人群包的使用,減少數(shù)據(jù)量的處理。
除了以上介紹的兩個(gè)基本原理,Impala的存儲層實(shí)現(xiàn)的原理和應(yīng)用在整個(gè)Impala中也是不可忽視的,接下來為大家介紹的就是其存儲層的相關(guān)理論和運(yùn)用。
1.?原理
交互式分析引擎的實(shí)現(xiàn)思路分為進(jìn)行預(yù)計(jì)算,提前計(jì)算出所有可能維度組合的結(jié)果,或通過即時(shí)計(jì)算包括建立倒排索引和列式存儲統(tǒng)計(jì)信息。其中倒排索引是指對匹配的結(jié)果進(jìn)行鏈表歸并或bitmap處理,將每一列獨(dú)立存儲,并在符合olap每次只分析部分列的需求,同時(shí)利用統(tǒng)計(jì)信息減少io的消耗。在并發(fā)度不那么高的背景下,多采用列式存儲的原理,因其采用單行組的形式對數(shù)據(jù)進(jìn)行存儲,可以減少io次數(shù),從而提升QPS。下圖為列式存儲的抽象表示:

對于性能差異的原因,通過一個(gè)例子能夠很好的理解,比如一個(gè)分區(qū)存儲150G,供727個(gè)文件,平均每個(gè)文件211M,一共273列,平均每一列774k。impala再讀取的過程中會向scanRange對象中填充讀取一個(gè)內(nèi)存塊,所以若每次只讀一列,只需要一次io,但如果分散再多個(gè)行組中就需要多次io,尤其是如果行組太多就同行存無異。因此在一個(gè)parquet文件與hdfs的block大小一致,并且僅包含一個(gè)row group,可以最大限度地提高QPS和運(yùn)行效率,避免大量行組導(dǎo)致效率低下地問題。
2.?數(shù)據(jù)過濾
Impala的存儲層有良好的數(shù)據(jù)過濾體系,主要分三步從行組級統(tǒng)計(jì)信息、pageIndex、字典信息三個(gè)方面進(jìn)行最大化的數(shù)據(jù)過濾,減少io次數(shù)。其中前兩步都需要考慮profile中的指標(biāo),行組中每個(gè)列地統(tǒng)計(jì)信息包括最大值或最小值等等。第三步字典信息中對于profile重點(diǎn)阿指標(biāo)只對encode類型進(jìn)行考慮,包括PLAIN DICTIONARY等并只使用與總數(shù)小于4萬地情況。
并考慮采取全局排序、hash分區(qū)后排序、z-order排序三種方式對數(shù)據(jù)過濾過程進(jìn)行優(yōu)化,提高處理效率和穩(wěn)定性。
3.?應(yīng)用
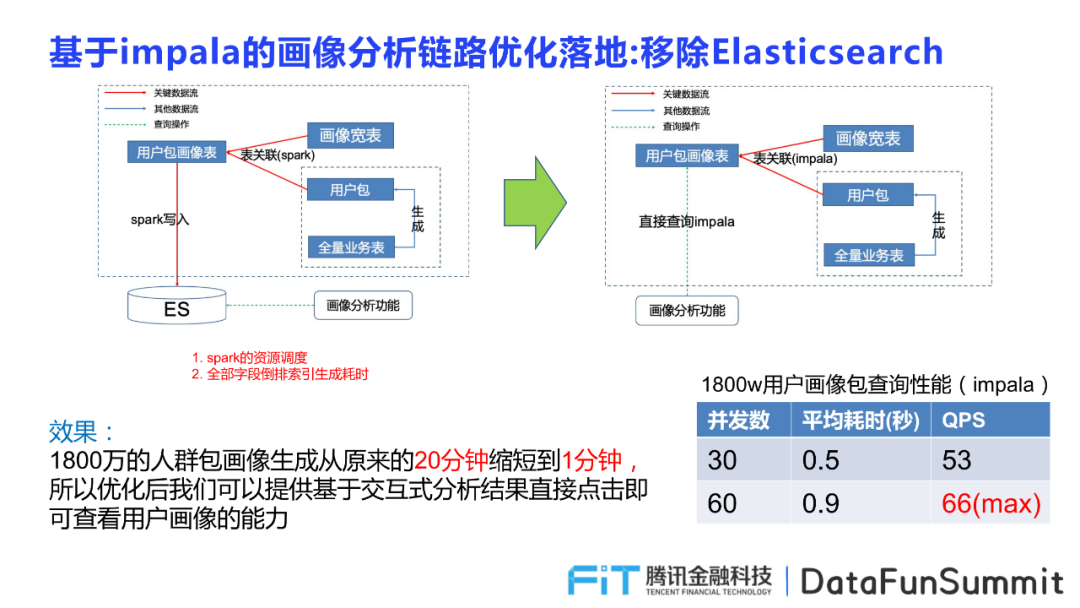
優(yōu)化前的畫像分析需要運(yùn)用spark進(jìn)行資源調(diào)度,并對全部字段生成倒排索引消耗大量時(shí)間,在引入Impala優(yōu)化后,可以直接進(jìn)行畫像分析。Impala通過用戶包畫像表直接表關(guān)聯(lián)到畫像寬度和依據(jù)用戶包和全量業(yè)務(wù)表生成的集合表,提供畫像分析功能的使用。基于這一層次x優(yōu)化落地的功能效果也十分顯著,例如針對1800萬人群包畫像生成時(shí)間從20分鐘縮短成1分鐘,并支持基于交互式結(jié)果的直接查看用戶畫像的能力,性能和功能都得到了極大的提升。
在了解完Impala的整體架構(gòu),處理邏輯的原理和存儲層的相關(guān)理論之后,相信大家都對Impala有了一個(gè)更加深入的認(rèn)識,接下來就為大家提供一些思路的總結(jié)。
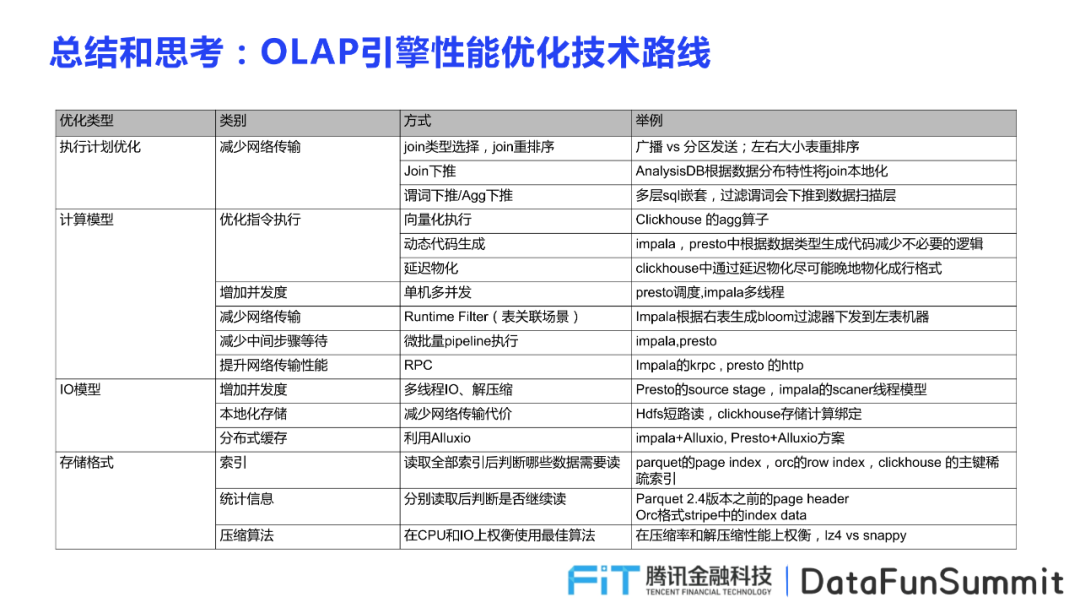
1.?OLAP引擎性能優(yōu)化技術(shù)路線
下面是對OLAP引擎性能優(yōu)化技術(shù)路線的一個(gè)總結(jié),這對于深入到某個(gè)具體的引擎做深度優(yōu)化,提升性能是很好的參考思路。向量化、動態(tài)代碼生成這兩種方式是比較傳統(tǒng)的思路,其中動態(tài)代碼生成最大化減少對類型的分支判斷,減少指令,提升計(jì)算性能。
2.?Impala性能相關(guān)優(yōu)化思路總結(jié)
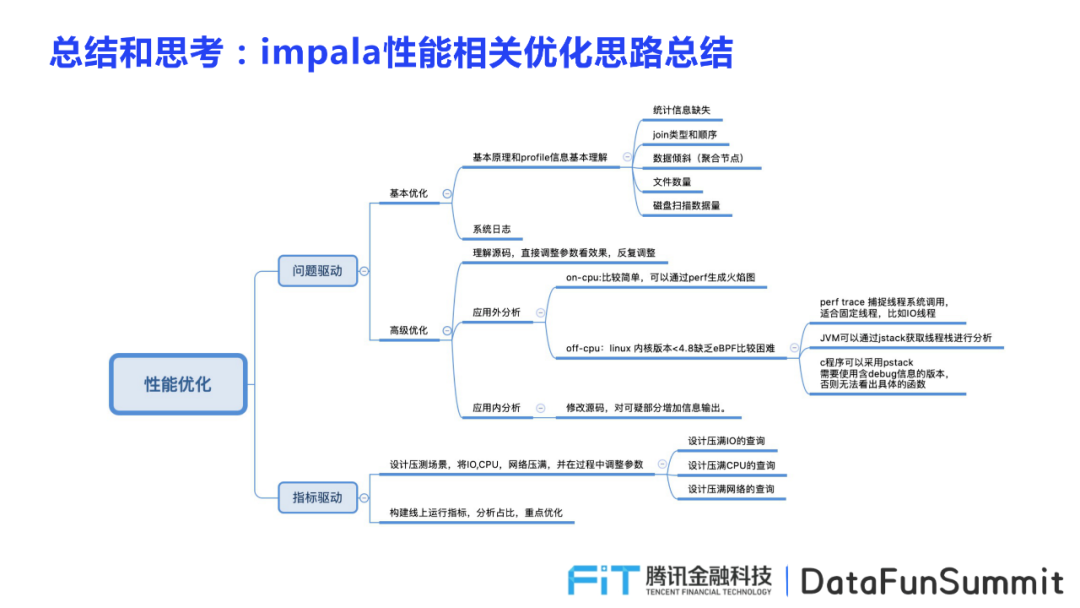
性能優(yōu)化思路分為問題驅(qū)動和指標(biāo)驅(qū)動。其中問題驅(qū)動包括基本優(yōu)化和高級優(yōu)化兩類,基本優(yōu)化需要從基本原理和profile信息進(jìn)行基本理解,并優(yōu)化系統(tǒng)日志兩部分;高級優(yōu)化首先需要理解源碼,反復(fù)直接調(diào)整參數(shù)看優(yōu)化效果,同時(shí)考慮從應(yīng)用外分析和應(yīng)用內(nèi)分析。
指標(biāo)驅(qū)動則通過設(shè)計(jì)壓力測試場景進(jìn)行優(yōu)化,將IO,CPU,網(wǎng)絡(luò)壓滿,并看在這些狀況下,系統(tǒng)查詢行為表現(xiàn)如何,在不斷實(shí)踐過程中調(diào)整參數(shù),并構(gòu)建線上運(yùn)行指標(biāo),分析占比,重點(diǎn)優(yōu)化各項(xiàng)重要指標(biāo),從而對impala性能進(jìn)行一個(gè)好的優(yōu)化。
在文末分享、點(diǎn)贊、在看,給個(gè)3連擊唄~
分享嘉賓:

??分享、點(diǎn)贊、在看,給個(gè)3連擊唄!??