
ODTK:來自NVIDIA的旋轉(zhuǎn)框物體檢測工具箱
點擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

作者:Jonathan Howe, James Skinner
編譯:ronghuaiyang 來源:AI公園
旋轉(zhuǎn)框相比矩形框可以更好的擬合物體,同時標(biāo)注起來比分割要方便的多,使用來自NVIDIA的ODTK可以方便的訓(xùn)練,實施和部署旋轉(zhuǎn)框物體檢測模型,同時具備多種擴展功能。

利用深度神經(jīng)網(wǎng)絡(luò)(DNNs)和卷積神經(jīng)網(wǎng)絡(luò)(CNNs)對圖像進行目標(biāo)檢測和分類是一個研究很廣泛的領(lǐng)域。對于一些應(yīng)用,這些人工智能方法被認(rèn)為是足夠可靠的,在生產(chǎn)中使用基本不需要干預(yù)。流行的方法包括YOLO、SSD、Faster-RCNN、MobileNet、RetinaNet等。
在大多數(shù)應(yīng)用環(huán)境中,圖像是從一個以自己為中心的視角收集的(比如手機攝像頭),大多數(shù)目標(biāo)是垂直對齊的(一個人)或水平對齊的(一輛車)。這意味著圖像中的大部分物體可以認(rèn)為是軸向的,可以用四個包圍框參數(shù)來描述:xmin、ymin、width和height。
但是,在許多情況下,物體或特征不與圖像軸對齊。在這種情況下,這四個參數(shù)不能很好地描述物體輪廓。

例如,嘗試使用四個邊界框參數(shù)來描述一個旋轉(zhuǎn)了45度的正方形。邊界框的面積是你試圖描述的正方形面積的兩倍。自己計算一下吧!
對于矩形物體,或者任何高長寬比的物體(又高又瘦,又矮又胖),差別甚至更大。因此,需要一個額外的參數(shù)來減少目標(biāo)的面積和描述它的邊界框之間的差異, 物體相對于垂直軸的角度,θ 。現(xiàn)在你可以用xmin,ymin,width,height和θ來描述一個目標(biāo)的邊框。
在現(xiàn)實世界中,有些目標(biāo)不能被描述為一個簡單的矩形,需要更多的參數(shù)。添加角度參數(shù)有助于描述其位置和輪廓,比軸對齊框更精確。

旋轉(zhuǎn)物體和特征的檢測的應(yīng)用包括遙感(圖1)、 “in the wild” 文本檢測、醫(yī)學(xué)和工業(yè)檢測。當(dāng)你使用軸對齊的邊框來訓(xùn)練模型背景時,每個旋轉(zhuǎn)的目標(biāo)都會包含一些特征,從而降低了模型從背景圖像中區(qū)分感興趣的目標(biāo)的能力。此外,如果目標(biāo)是近距離的,例如停車場的汽車,背景和附近的目標(biāo)也包括在目標(biāo)實例中。
其結(jié)果是,當(dāng)一群目標(biāo)中存在相同或類似類別時,檢測器可能會高估或低估目標(biāo)的數(shù)量。對于依賴于精確值的應(yīng)用,這顯然不是最優(yōu)的。旋轉(zhuǎn)框可以緩解這些問題,并提供更高的精度和召回率。例如,圖3中圍繞人物的軸對齊框包含了很多天空和一些摩托車。旋轉(zhuǎn)框里包含了更少的天空和幾乎沒有摩托車。
旋轉(zhuǎn)目標(biāo)檢測模型和方法
常用的檢測旋轉(zhuǎn)物體的DNN方法可分為兩類:
-
從分割蒙版計算旋轉(zhuǎn)框 -
直接推斷旋轉(zhuǎn)框
對于第一種方法,分割掩模通常使用Mask-RCNN計算,這是一個基于Faster-RCNN的網(wǎng)絡(luò),在分類和軸對齊的包圍框之外還有一個額外的分割頭。與Faster-RCNN一樣,Mask-RCNN是一個兩級檢測器,它能推斷出建議區(qū)域,然后在檢測結(jié)果中細(xì)化。
雖然這種方法可以對軸對齊目標(biāo)進行高精度的推斷,但這種兩階段方法的性能(每秒處理圖像)相對較低。此外,使用推斷分割掩模計算旋轉(zhuǎn)的包圍框,通常使用后處理和OpenCV等標(biāo)準(zhǔn)包,會產(chǎn)生不準(zhǔn)確和虛假的結(jié)果。
第二種方法,直接推斷旋轉(zhuǎn)框,更有吸引力。與分割掩碼方法不同,不需要增加低效率和通常會降低精度的后處理。另外,大多數(shù)直接推斷旋轉(zhuǎn)框的方法都是單階段檢測器,而不是像Faster-RCNN這樣的多階段檢測器。
關(guān)于這個主題的學(xué)術(shù)論文很少,公開的repos就更少了。為了在一次檢測中推斷旋轉(zhuǎn)框,許多技術(shù)依賴于比較ground truth和錨(有時稱為先驗框)。對于軸對齊的檢測器,錨的大小、長寬比和比例在進行訓(xùn)練之前由用戶定義。
訓(xùn)練期間,如果計算的anchor框和gt框之間的IOU高于0.5,那么這個anchor就用來回歸這個和這個gt之間的差別(Δxmin,Δymin,Δwidth,Δheight)。對于軸對齊框,IoU計算非常簡單,可以使用NVIDIA GPU以端到端方式加速。下面的PyTorch例子顯示了軸對齊框和anchor之間IoU的計算:
inter = torch.prod((xy2 - xy1 + 1).clamp(0), 2)
boxes_area = torch.prod(boxes[:, 2:] - boxes[:, :2] + 1, 1)
anchors_area = torch.prod(anchors[:, 2:] - anchors[:, :2] + 1, 1)
overlap = inter / (anchors_area[:, None] + boxes_area - inter)
在這個代碼示例中:
-
boxes是ground truth的注解 -
anchors是錨框 -
xy2和xy1分別是標(biāo)注框和anchor中左上角最大的和右下角最小的角的坐標(biāo) -
inter是boxes和anchors的重疊區(qū)域面積 -
boxes_area和anchors_area分別是ground truth和錨框的面積 -
overlap是IoU
對于旋轉(zhuǎn)框,情況就不同了。首先,為額外的參數(shù)angle指定一個或多個值,這增加一個anchor的參數(shù)。圖4顯示了圖像特征空間中的單個位置上軸對齊的錨框(藍(lán)色),具有三種比例和三種縱橫比。旋轉(zhuǎn)的錨框(紅色和藍(lán)色)在三個旋轉(zhuǎn)角度上使用相同的比例和長寬比來顯示:-π/6, 0 and π/6其次,最重要的是,IoU的計算不能像前面所示的軸對齊框那樣簡單地進行。
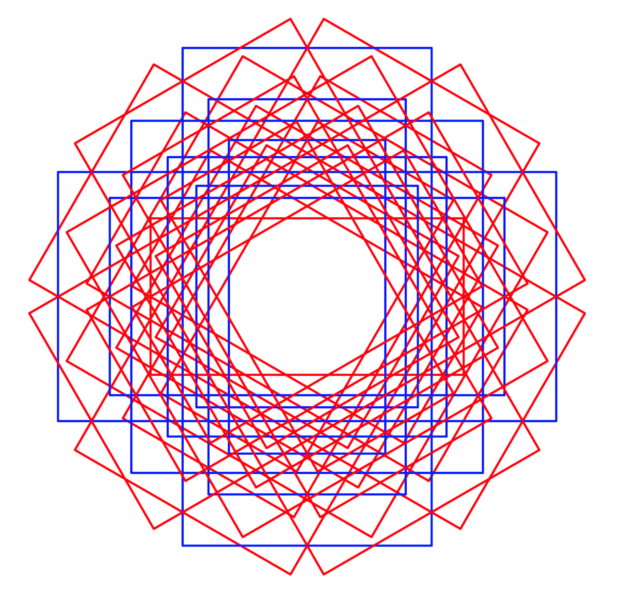
旋轉(zhuǎn)框的IOU計算
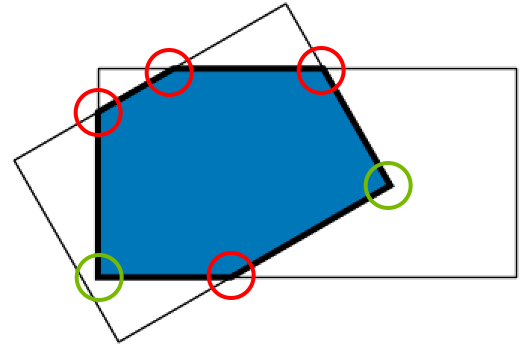
圖5顯示了旋轉(zhuǎn)框交叉點要比軸對齊的框交叉點復(fù)雜得多。當(dāng)兩個旋轉(zhuǎn)框重疊時,會構(gòu)建出一個新的多邊形(不一定是四邊形),由紅色和綠色的頂點描述。紅色的頂點表示兩個框的邊相交的地方,而綠色的頂點包含在兩個框內(nèi)。你必須能夠為所有的框都計算出這些點,然后執(zhí)行IoU計算。
大多數(shù)論文依賴于框的光柵化(例如,創(chuàng)建一個圖像或mask)來計算這個新的多邊形,然后計算IoU。這是一種低效且不準(zhǔn)確的方法,因為框所占據(jù)的空間必須離散化以進行所有的比較。需要使用精確的分析解決方案來最大化效率和準(zhǔn)確性。
為了解決這個問題,我們轉(zhuǎn)向幾何方法,順序切割是一種遞歸方法,使用一個比較框定義初始多邊形。對于每條邊,它計算與第二個被比較框的邊是否有交集。如果是這樣,這些頂點就會被保留下來,并形成新的邊,然后這些邊會再次與被比較的方框進行比較,直到?jīng)]有邊剩下為止。偽代碼如下:
Intersection of two rotated boxes / polygons (p1, p2):
1. Initialize the box_intersection, setting it as the vertices of p1.
2. For each edge (specified by the line equation ax + by + c = 0) of p2, find line intersection with box intersection using homogeneous coordinates where;
intersectionx = (p1.b*p2.c - p1.c*p2.b) / w
intersectiony = (p1.c*p2.a - p1.a*p2.c) / w
where; w = p1.a*p2.b - p1.b*p2.a
2a. If intersection occurs on the edge, add it to temp_intersection.
2b. If intersection occurs within the boundary of two edge calculations, add it to temp_intersection.
3. Set box_intersection = temp_intersection.
4. Repeat from 2. until no more edges.
如果在比較兩個框時存在一個有兩條邊以上的多邊形,現(xiàn)在可以計算IoU,否則,IoU為零。再一次,為精確計算,其中不規(guī)則多邊形的面積是由以下公式給出:
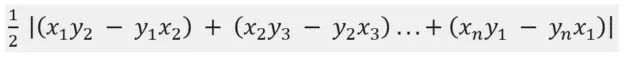
然后,IoU通過分割多邊形區(qū)域來計算,正如前面計算的框和錨的區(qū)域的IoU。
與與之對應(yīng)的軸對齊方法相比,這種遞歸方法更加復(fù)雜。但是,與光柵化框和錨相比,它的計算要求更少,也不那么麻煩。
IoU必須在每幅圖像上計算,因為它是通過DNN前向傳播的。在訓(xùn)練過程中,IoU用于度量損失,在推理過程中,IoU需要進行非最大抑制(NMS)。因此,函數(shù)必須盡可能快。
這是通過使用grid-striding在CUDA core的多個GPU線程上并行地進行每次比較來實現(xiàn)的。
Grid-striding可以讓你在GPU設(shè)備上以靈活的方式并行執(zhí)行這些計算,而不是按順序計算所有的ground truth box到anchor box的比較(每個圖像batch的計算量從100ks到數(shù)百萬)。
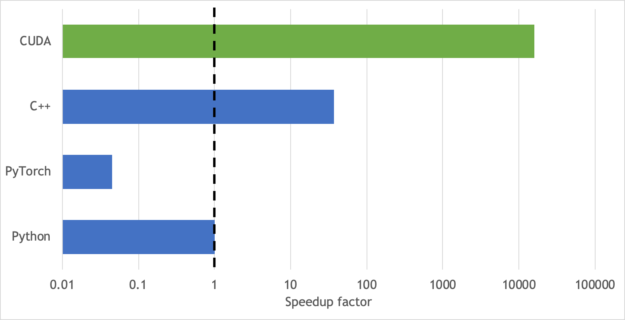
圖6展示了在CUDA core(綠色條)上的實現(xiàn)和在cpu上執(zhí)行順序計算(藍(lán)色條)時的加速圖。CUDA core比Python提供了10k的加速,比PyTorch提供了100k的加速,比c++提供了500的加速。這個圖沒有考慮GPU到CPU之間的數(shù)據(jù)傳輸時間,如果旋轉(zhuǎn)IoU計算在GPU設(shè)備上在模型訓(xùn)練期間執(zhí)行。在訓(xùn)練和推斷過程中,將所有的數(shù)據(jù)和計算都保存在GPU上,這進一步增加了GPU和CPU性能的差異,如圖6所示。
IoU計算好了之后,如果絕對角度不是必需的,你可以最小化(Δxmin, Δymin, Δwidth, Δheight, Δθ)。如果絕對角度和方向需要已知(文本框取向、車輛方向/軸承等等),這些信息在gt中是一致的,可以最小化(Δxmin, Δymin, Δwidth, Δheight, Δsin(θ), Δcos(θ)),捕獲絕對角度差異的θ投影到單位圓上。
所有特性(軸對齊和旋轉(zhuǎn)框檢測)在NVIDIA物體檢測工具包:https://github.com/NVIDIA/retinanet-examples (ODTK)中都可以使用。
使用ODTK
NVIDIA擁有一套豐富的工具來加速目標(biāo)檢測模型的訓(xùn)練和推斷。開源ODTK是一個如何同時使用所有這些工具的例子。使用RetinaNet演示檢測pipeline是作為現(xiàn)代物體檢測器的一個很好的例子。
ODTK演示了如何集成5個NVIDIA工具:
-
Mixed precision training,我們在FP32保留一個網(wǎng)絡(luò)權(quán)重的主副本,但我們在FP16計算更新每批。這使得訓(xùn)練時的速度提高了3倍。我們使用NVIDIA APEX庫實現(xiàn)自動混合精度(AMP)。
-
NVIDIA數(shù)據(jù)加載庫 (DALI)將預(yù)處理(圖像resize和歸一化)移動到GPU。這可以將訓(xùn)練和推理速度提高到1.2到1.5倍,這取決于你選擇哪種骨干。
-
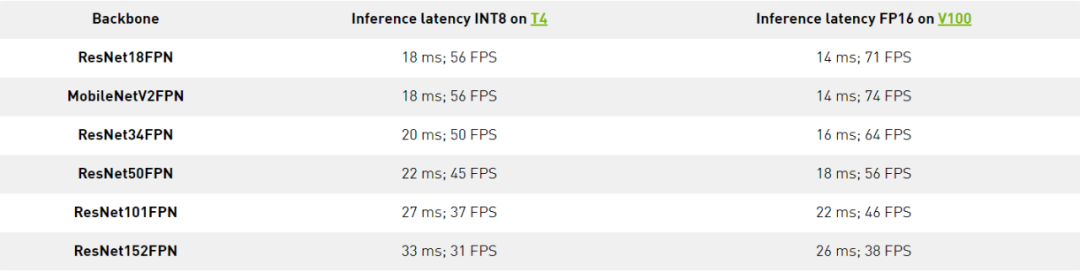
NVIDIA TensorRT 創(chuàng)建高度優(yōu)化的推理引擎,在FP32, FP16,和INT8精度上都可以使用。這些引擎可以在推理期間提供顯著的加速(比如5x)。ODTK還可以生成ONNX文件,提供更大的框架靈活性。
-
NVIDIA DeepStream SDK 是英偉達(dá)智能視頻分析解決方案(IVA)。它是非常高效的,因為DeepStream將視頻數(shù)據(jù)的整個pipeline保持在GPU中。NVIDIA提供了一個解析器,以便可以在DeepStream pipeline中使用ODTK推理引擎(使用TensorRT生成)。
-
NVIDIA Triton Inference Server是TensorRT模型的另一種服務(wù)方式。Triton推斷服務(wù)器可以注冊O(shè)DTK PyTorch、ONNX和TensorRT模型,Triton客戶端可以請求該服務(wù)器。如果你使用靜態(tài)圖像而不是視頻流,此方法可能更適合。
準(zhǔn)備數(shù)據(jù)
ODTK使用COCO目標(biāo)檢測格式,但我們修改了邊框,使其包含theta參數(shù)。首先使用[xmin, ymin, width, height]參數(shù)構(gòu)建邊框(圖7,左)。然后,將框逆時針旋轉(zhuǎn)theta 弧度,在本例中為-0.209。如果旋轉(zhuǎn)的方框包含了圖片框之外的區(qū)域,沒有關(guān)系。

許多數(shù)據(jù)集(例如COCO和ISPRS)都帶有分割掩碼。這些掩碼可以轉(zhuǎn)換為旋轉(zhuǎn)框。
使用shapely minimum_rotated_rectangle函數(shù)創(chuàng)建旋轉(zhuǎn)矩形,并將四個角輸入函數(shù)以生成邊框值。calc_bearing是一個用arctan求θ的簡單函數(shù)。你必須把函數(shù)封裝起來以確保w和h是正的,并且theta在-pi/2到pi/2或者-pi到pi的范圍內(nèi)。
def _corners2rotatedbbox(corners):
centre = np.mean(np.array(corners), 0)
theta = calc_bearing(corners[0], corners[1])
rotation = np.array([[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]])
out_points = np.matmul(corners - centre, rotation) + centre
x, y = list(out_points[0,:])
w, h = list(out_points[2, :] - out_points[0, :])
return [x, y, w, h, theta]
訓(xùn)練,推理,導(dǎo)出ODTK模型
ODTK位于最新的NVIDIA NGC PyTorch容器中。這確保安裝了正確版本的PyTorch和其他先決條件。
git clone https://github.com/nvidia/retinanet-examples
docker build -t odtk:latest retinanet-examples/
docker run --gpus all --rm --ipc=host -it -v/your/data/dir:/data odtk:latest
現(xiàn)在,訓(xùn)練ODTK用于旋轉(zhuǎn)檢測。在這篇文章中,我們使用了ResNet50PFN主干。下面的命令每7000次迭代生成一個驗證分?jǐn)?shù)。
odtk train model.pth --backbone ResNet50FPN \
--images /data/train/ --annotations /data/train.json \
--val-images /data/val --val-annotations /data/val.json --rotated-bbox
你可以使用PyTorch來推理模型:
odtk infer model.pth --images /data/test --output detections.json
但是,如果首先導(dǎo)出到TensorRT(這里是FP16),可以獲得更快的推斷性能,但是INT8精度也可用。
odtk export model.pth engine.plan
你可以使用odtk推斷命令、Triton服務(wù)器或編寫一個c++推斷應(yīng)用程序進行推斷。
對比例子

圖8顯示了在ISPRS波茨坦數(shù)據(jù)集上訓(xùn)練的軸對齊和旋轉(zhuǎn)框模型的例子,這些例子是從在使用ResNet18主干的COCO數(shù)據(jù)集上預(yù)訓(xùn)練的軸對齊模型上進行微調(diào)的。這兩個模型在相同的訓(xùn)練和驗證數(shù)據(jù)集上進行訓(xùn)練直到收斂(90k迭代)。
從推理圖像可以看出,旋轉(zhuǎn)模型比軸對齊模型更符合ground truth。當(dāng)使用軸對齊模型時,會出現(xiàn)每輛車有多個檢測結(jié)果的情況,但對于旋轉(zhuǎn)框模型則不是這樣。
與軸對齊模型相比,旋轉(zhuǎn)框模型獲得了更高的平均IoU:0.60對0.29。由于軸對齊模型得到的IoU較低,IoU≥0.5時的標(biāo)準(zhǔn)COCO平均精度計算值在模型之間存在差異:0.86和0.01。你必須為這個比較使用一個更公平的度量,一個可以用來比較推斷的結(jié)果與ground truth框的匹配程度的度量。
在這篇文章中,我們使用了在Cityscapes dataset challenge中定義的實例級語義標(biāo)記度量。精度和召回率是按類和像素級別計算的。當(dāng)使用這些指標(biāo)時,旋轉(zhuǎn)模型的精度和召回率分別為0.77和0.76,軸對齊模型的精度和召回率分別為0.37和0.55。旋轉(zhuǎn)檢測比軸對齊模型可以更清楚地匹配ground truth。

總結(jié)
可以嘗試使用ODTK檢測自己數(shù)據(jù)集中的旋轉(zhuǎn)目標(biāo)。你會發(fā)現(xiàn)它直接訓(xùn)練,驗證,實施,并提供模型服務(wù),最大話GPU資源的效率。并持續(xù)為高性能,端到端掩模訓(xùn)練和推理,多邊形檢測,和高效的多目標(biāo)跟蹤集成進行調(diào)優(yōu)。

英文原文:https://developer.nvidia.com/blog/detecting-rotated-objects-using-the-odtk/
下載1:速查表
在「AI算法與圖像處理」公眾號后臺回復(fù):速查表,即可下載21張 AI相關(guān)的查找表,包括 python基礎(chǔ),線性代數(shù),scipy科學(xué)計算,numpy,kears,tensorflow等等
下載2 CVPR2020
在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR2020,即可下載1467篇CVPR 2020論文 個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
覺得有趣就點亮在看吧
