
主流分布式文件系統(tǒng)對(duì)比
300本計(jì)算機(jī)編程的經(jīng)典書(shū)籍下載
AI全套:Python3+TensorFlow打造人臉識(shí)別智能小程序
最新人工智能資料-Google工程師親授 Tensorflow-入門(mén)到進(jìn)階
黑馬頭條項(xiàng)目 - Java Springboot2.0(視頻、資料、代碼和講義)14天完整版
作者:張軻1983
來(lái)源:https://www.jianshu.com/p/fc0aa34606ce
一、概述
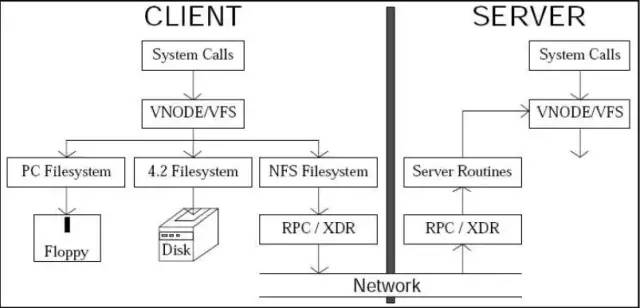
二、過(guò)去的樣子
三、對(duì)分布式文件系統(tǒng)的要求
對(duì)一個(gè)分布式文件系統(tǒng)而言,有一些特性是必須要滿足的,否則就無(wú)法有競(jìng)爭(zhēng)力。主要如下:
應(yīng)該符合 POSIX 的文件接口標(biāo)準(zhǔn),使該系統(tǒng)易于使用,同時(shí)對(duì)于用戶的遺留系統(tǒng)也無(wú)需改造; 對(duì)用戶透明,能夠像使用本地文件系統(tǒng)那樣直接使用; 持久化,保證數(shù)據(jù)不會(huì)丟失; 具有伸縮性,當(dāng)數(shù)據(jù)壓力逐漸增長(zhǎng)時(shí)能順利擴(kuò)容; 具有可靠的安全機(jī)制,保證數(shù)據(jù)安全; 數(shù)據(jù)一致性,只要文件內(nèi)容不發(fā)生變化,什么時(shí)候去讀,得到的內(nèi)容應(yīng)該都是一樣的。
支持的空間越大越好; 支持的并發(fā)訪問(wèn)請(qǐng)求越多越好; 性能越快越好; 硬件資源的利用率越高越合理,就越好。
四、架構(gòu)模型
從業(yè)務(wù)模型和邏輯架構(gòu)上,分布式文件系統(tǒng)需要這幾類(lèi)組件:
存儲(chǔ)組件:負(fù)責(zé)存儲(chǔ)文件數(shù)據(jù),它要保證文件的持久化、副本間數(shù)據(jù)一致、數(shù)據(jù)塊的分配 / 合并等等;
接口組件:提供接口服務(wù)給應(yīng)用使用,形態(tài)包括 SDK(Java/C/C++ 等)、CLI 命令行終端、以及支持 FUSE 掛載機(jī)制。
而在部署架構(gòu)上,有著“中心化”和“無(wú)中心化”兩種路線分歧,即是否把“管理組件”作為分布式文件系統(tǒng)的中心管理節(jié)點(diǎn)。兩種路線都有很優(yōu)秀的產(chǎn)品,下面分別介紹它們的區(qū)別。
1、有中心節(jié)點(diǎn)
以 GFS 為代表,中心節(jié)點(diǎn)負(fù)責(zé)文件定位、維護(hù)文件 meta 信息、故障檢測(cè)、數(shù)據(jù)遷移等管理控制的職能,下圖是 GFS 的架構(gòu)圖:
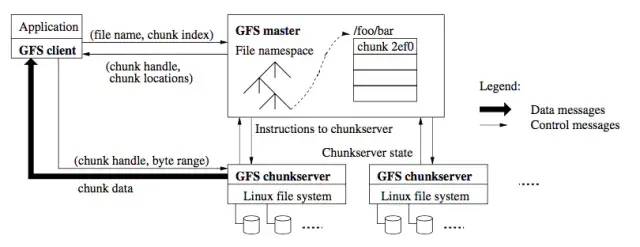
該圖中GFS master 即為 GFS 的中心節(jié)點(diǎn),GF chunkserver 為 GFS 的存儲(chǔ)節(jié)點(diǎn)。其操作路徑如下:
Client 向中心節(jié)點(diǎn)請(qǐng)求“查詢某個(gè)文件的某部分?jǐn)?shù)據(jù)”; 中心節(jié)點(diǎn)返回文件所在的位置 (哪臺(tái) chunkserver 上的哪個(gè)文件) 以及字節(jié)區(qū)間信息; Client 根據(jù)中心節(jié)點(diǎn)返回的信息,向?qū)?yīng)的 chunk server 直接發(fā)送數(shù)據(jù)讀取的請(qǐng)求; chunk server 返回?cái)?shù)據(jù)。
在這種方案里,一般中心節(jié)點(diǎn)并不參與真正的數(shù)據(jù)讀寫(xiě),而是將文件 meta 信息返回給 Client 之后,即由 Client 與數(shù)據(jù)節(jié)點(diǎn)直接通信。其主要目的是降低中心節(jié)點(diǎn)的負(fù)載,防止其成為瓶頸。這種有中心節(jié)點(diǎn)的方案,在各種存儲(chǔ)類(lèi)系統(tǒng)中得到了廣泛應(yīng)用,因?yàn)橹行墓?jié)點(diǎn)易控制、功能強(qiáng)大。
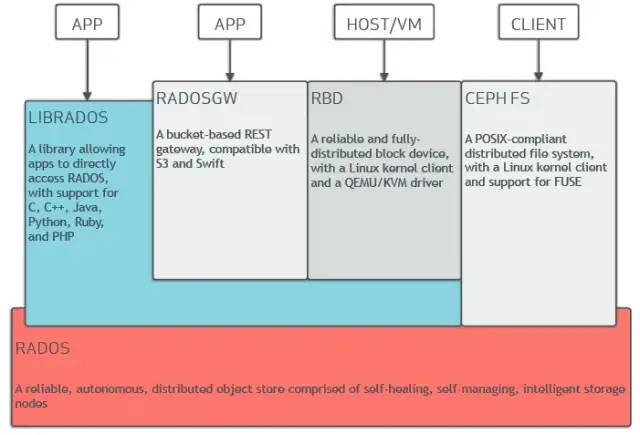
2、無(wú)中心節(jié)點(diǎn)
以ceph為代表,每個(gè)節(jié)點(diǎn)都是自治的、自管理的,整個(gè) ceph 集群只包含一類(lèi)節(jié)點(diǎn),如下圖 (最下層紅色的 RADOS 就是 ceph 定義的“同時(shí)包含 meta 數(shù)據(jù)和文件數(shù)據(jù)”的節(jié)點(diǎn))。
五、持久化
對(duì)于文件系統(tǒng)來(lái)說(shuō),持久化是根本,只要 Client 收到了 Server 保存成功的回應(yīng)之后,數(shù)據(jù)就不應(yīng)該丟失。這主要是通過(guò)多副本的方式來(lái)解決,但在分布式環(huán)境下,多副本有這幾個(gè)問(wèn)題要面對(duì)。
如何保證每個(gè)副本的數(shù)據(jù)是一致的? 如何分散副本,以使災(zāi)難發(fā)生時(shí),不至于所有副本都被損壞? 怎么檢測(cè)被損壞或數(shù)據(jù)過(guò)期的副本,以及如何處理? 該返回哪個(gè)副本給 Client?
同步寫(xiě)入是保證副本數(shù)據(jù)一致的最直接的辦法。當(dāng) Client 寫(xiě)入一個(gè)文件的時(shí)候,Server 會(huì)等待所有副本都被成功寫(xiě)入,再返回給 Client。
這種方式簡(jiǎn)單、有保障,唯一的缺陷就是性能會(huì)受到影響。假設(shè)有 3 個(gè)副本,如果每個(gè)副本需要N秒,則可能會(huì)阻塞 Client 3N 秒的時(shí)間,有幾種方式,可以對(duì)其進(jìn)行優(yōu)化:
并行寫(xiě):由一個(gè)副本作為主副本,并行發(fā)送數(shù)據(jù)給其他副本; 鏈?zhǔn)綄?xiě):幾個(gè)副本組成一個(gè)鏈 (chain),并不是等內(nèi)容都接受到了再往后傳播,而是像流一樣,邊接收上游傳遞過(guò)來(lái)的數(shù)據(jù),一邊傳遞給下游。
還有一種方式是采用 CAP 中所說(shuō)的 W+R>N 的方式,比如 3 副本 (N=3) 的情況,W=2,R=2,即成功寫(xiě)入 2 個(gè)就認(rèn)為成功,讀的時(shí)候也要從 2 個(gè)副本中讀。這種方式通過(guò)犧牲一定的讀成本,來(lái)降低寫(xiě)成本,同時(shí)增加寫(xiě)入的可用性。這種方式在分布式文件系統(tǒng)中用地比較少。
2、如何分散副本,以使災(zāi)難發(fā)生時(shí),不至于所有副本都被損壞?
這主要避免的是某機(jī)房或某城市發(fā)生自然環(huán)境故障的情況,所以有一個(gè)副本應(yīng)該分配地比較遠(yuǎn)。它的副作用是會(huì)帶來(lái)這個(gè)副本的寫(xiě)入性能可能會(huì)有一定的下降,因?yàn)樗x Client 最遠(yuǎn)。所以如果在物理?xiàng)l件上無(wú)法保證夠用的網(wǎng)絡(luò)帶寬的話,則讀寫(xiě)副本的策略上需要做一定考慮。
可以參考同步寫(xiě)入只寫(xiě) 2 副本、較遠(yuǎn)副本異步寫(xiě)入的方式,同時(shí)為了保證一致性,讀取的時(shí)候又要注意一些,避免讀取到異步寫(xiě)入副本的過(guò)時(shí)數(shù)據(jù)。
3、怎么檢測(cè)被損壞或數(shù)據(jù)過(guò)期的副本,以及如何處理?
如果有中心節(jié)點(diǎn),則數(shù)據(jù)節(jié)點(diǎn)定期和中心節(jié)點(diǎn)進(jìn)行通信,匯報(bào)自己的數(shù)據(jù)塊的相關(guān)信息,中心節(jié)點(diǎn)將其與自己維護(hù)的信息進(jìn)行對(duì)比。如果某個(gè)數(shù)據(jù)塊的 checksum 不對(duì),則表明該數(shù)據(jù)塊被損壞了;如果某個(gè)數(shù)據(jù)塊的 version 不對(duì),則表明該數(shù)據(jù)塊過(guò)期了。
如果沒(méi)有中心節(jié)點(diǎn),以 ceph 為例,它在自己的節(jié)點(diǎn)集群中維護(hù)了一個(gè)比較小的 monitor 集群,數(shù)據(jù)節(jié)點(diǎn)向這個(gè) monitor 集群匯報(bào)自己的情況,由其來(lái)判定是否被損壞或過(guò)期。
當(dāng)發(fā)現(xiàn)被損壞或過(guò)期副本,將它從 meta 信息中移除,再重新創(chuàng)建一份新的副本就好了,移除的副本在隨后的回收機(jī)制中會(huì)被收回。
4、該返回哪個(gè)副本給 Client?
這里的策略就比較多了,比如 round-robin、速度最快的節(jié)點(diǎn)、成功率最高的節(jié)點(diǎn)、CPU 資源最空閑的節(jié)點(diǎn)、甚至就固定選第一個(gè)作為主節(jié)點(diǎn),也可以選擇離自己最近的一個(gè),這樣對(duì)整體的操作完成時(shí)間會(huì)有一定節(jié)約。
六、伸縮性
1、存儲(chǔ)節(jié)點(diǎn)的伸縮
當(dāng)在集群中加入一臺(tái)新的存儲(chǔ)節(jié)點(diǎn),則它主動(dòng)向中心節(jié)點(diǎn)注冊(cè),提供自己的信息,當(dāng)后續(xù)有創(chuàng)建文件或者給已有文件增加數(shù)據(jù)塊的時(shí)候,中心節(jié)點(diǎn)就可以分配到這臺(tái)新節(jié)點(diǎn)了,比較簡(jiǎn)單。但有一些問(wèn)題需要考慮。
如何盡量使各存儲(chǔ)節(jié)點(diǎn)的負(fù)載相對(duì)均衡? 怎樣保證新加入的節(jié)點(diǎn),不會(huì)因短期負(fù)載壓力過(guò)大而崩塌? 如果需要數(shù)據(jù)遷移,那如何使其對(duì)業(yè)務(wù)層透明?
首先要有評(píng)價(jià)存儲(chǔ)節(jié)點(diǎn)負(fù)載的指標(biāo)。有多種方式,可以從磁盤(pán)空間使用率考慮,也可以從磁盤(pán)使用率 +CPU 使用情況 + 網(wǎng)絡(luò)流量情況等做綜合判斷。一般來(lái)說(shuō),磁盤(pán)使用率是核心指標(biāo)。
其次在分配新空間的時(shí)候,優(yōu)先選擇資源使用率小的存儲(chǔ)節(jié)點(diǎn);而對(duì)已存在的存儲(chǔ)節(jié)點(diǎn),如果負(fù)載已經(jīng)過(guò)載、或者資源使用情況不均衡,則需要做數(shù)據(jù)遷移。
2)怎樣保證新加入的節(jié)點(diǎn),不會(huì)因短期負(fù)載壓力過(guò)大而崩塌?
當(dāng)系統(tǒng)發(fā)現(xiàn)當(dāng)前新加入了一臺(tái)存儲(chǔ)節(jié)點(diǎn),顯然它的資源使用率是最低的,那么所有的寫(xiě)流量都路由到這臺(tái)存儲(chǔ)節(jié)點(diǎn)來(lái),那就可能造成這臺(tái)新節(jié)點(diǎn)短期負(fù)載過(guò)大。因此,在資源分配的時(shí)候,需要有預(yù)熱時(shí)間,在一個(gè)時(shí)間段內(nèi),緩慢地將寫(xiě)壓力路由過(guò)來(lái),直到達(dá)成新的均衡。
3)如果需要數(shù)據(jù)遷移,那如何使其對(duì)業(yè)務(wù)層透明?
在有中心節(jié)點(diǎn)的情況下,這個(gè)工作比較好做,中心節(jié)點(diǎn)就包辦了——判斷哪臺(tái)存儲(chǔ)節(jié)點(diǎn)壓力較大,判斷把哪些文件遷移到何處,更新自己的 meta 信息,遷移過(guò)程中的寫(xiě)入怎么辦,發(fā)生重命名怎么辦。無(wú)需上層應(yīng)用來(lái)處理。
如果沒(méi)有中心節(jié)點(diǎn),那代價(jià)比較大,在系統(tǒng)的整體設(shè)計(jì)上,也是要考慮到這種情況,比如ceph,它要采取邏輯位置和物理位置兩層結(jié)構(gòu),對(duì)Client暴露的是邏輯層 (pool 和 place group),這個(gè)在遷移過(guò)程中是不變的,而下層物理層數(shù)據(jù)塊的移動(dòng),只是邏輯層所引用的物理塊的地址發(fā)生了變化,在Client看來(lái),邏輯塊的位置并不會(huì)發(fā)生改變。
2、中心節(jié)點(diǎn)的伸縮
如果有中心節(jié)點(diǎn),還要考慮它的伸縮性。由于中心節(jié)點(diǎn)作為控制中心,是主從模式,那么在伸縮性上就受到比較大的限制,是有上限的,不能超過(guò)單臺(tái)物理機(jī)的規(guī)模。我們可以考慮各種手段,盡量地抬高這個(gè)上限。有幾種方式可以考慮:
以大數(shù)據(jù)塊的形式來(lái)存儲(chǔ)文件——比如 HDFS 的數(shù)據(jù)塊的大小是 64M,ceph 的的數(shù)據(jù)塊的大小是 4M,都遠(yuǎn)遠(yuǎn)超過(guò)單機(jī)文件系統(tǒng)的 4k。它的意義在于大幅減少 meta data 的數(shù)量,使中心節(jié)點(diǎn)的單機(jī)內(nèi)存就能夠支持足夠多的磁盤(pán)空間 meta 信息。 中心節(jié)點(diǎn)采取多級(jí)的方式——頂級(jí)中心節(jié)點(diǎn)只存儲(chǔ)目錄的 meta data,其指定某目錄的文件去哪臺(tái)次級(jí)總控節(jié)點(diǎn)去找,然后再通過(guò)該次級(jí)總控節(jié)點(diǎn)找到文件真正的存儲(chǔ)節(jié)點(diǎn); 中心節(jié)點(diǎn)共享存儲(chǔ)設(shè)備——部署多臺(tái)中心節(jié)點(diǎn),但它們共享同一個(gè)存儲(chǔ)外設(shè) / 數(shù)據(jù)庫(kù),meta 信息都放在這里,中心節(jié)點(diǎn)自身是無(wú)狀態(tài)的。這種模式下,中心節(jié)點(diǎn)的請(qǐng)求處理能力大為增強(qiáng),但性能會(huì)受一定影響。iRODS 就是采用這種方式。
七、高可用性
1、中心節(jié)點(diǎn)的高可用
中心節(jié)點(diǎn)的高可用,不僅要保證自身應(yīng)用的高可用,還得保證 meta data 的數(shù)據(jù)高可用。
meta data 的高可用主要是數(shù)據(jù)持久化,并且需要備份機(jī)制保證不丟。一般方法是增加一個(gè)從節(jié)點(diǎn),主節(jié)點(diǎn)的數(shù)據(jù)實(shí)時(shí)同步到從節(jié)點(diǎn)上。也有采用共享磁盤(pán),通過(guò) raid1 的硬件資源來(lái)保障高可用。顯然增加從節(jié)點(diǎn)的主備方式更易于部署。
meta data 的數(shù)據(jù)持久化策略有以下幾種方式:
直接保存到存儲(chǔ)引擎上,一般是數(shù)據(jù)庫(kù)。直接以文件形式保存到磁盤(pán)上,也不是不可以,但因?yàn)?meta 信息是結(jié)構(gòu)化數(shù)據(jù),這樣相當(dāng)于自己研發(fā)出一套小型數(shù)據(jù)庫(kù)來(lái),復(fù)雜化了。 保存日志數(shù)據(jù)到磁盤(pán)文件 (類(lèi)似 MySQL 的 binlog 或 Redis 的 aof),系統(tǒng)啟動(dòng)時(shí)在內(nèi)存中重建成結(jié)果數(shù)據(jù),提供服務(wù)。修改時(shí)先修改磁盤(pán)日志文件,然后更新內(nèi)存數(shù)據(jù)。這種方式簡(jiǎn)單易用。
當(dāng)前內(nèi)存服務(wù) + 日志文件持久化是主流方式。一是純內(nèi)存操作,效率很高,日志文件的寫(xiě)也是順序?qū)懀欢遣灰蕾?lài)外部組件,獨(dú)立部署。
為了解決日志文件會(huì)隨著時(shí)間增長(zhǎng)越來(lái)越大的問(wèn)題,以讓系統(tǒng)能以盡快啟動(dòng)和恢復(fù),需要輔助以內(nèi)存快照的方式——定期將內(nèi)存 dump 保存,只保留在 dump 時(shí)刻之后的日志文件。這樣當(dāng)恢復(fù)時(shí),從最新一次的內(nèi)存 dump 文件開(kāi)始,找其對(duì)應(yīng)的 checkpoint 之后的日志文件開(kāi)始重播。
2、存儲(chǔ)節(jié)點(diǎn)的高可用
在前面“持久化”章節(jié),在保證數(shù)據(jù)副本不丟失的情況下,也就保證了其的高可用性。另外,分布式系列面試題和答案全部整理好了,微信搜索互聯(lián)網(wǎng)架構(gòu)師,在后臺(tái)發(fā)送:2T,可以在線閱讀。
八、性能優(yōu)化和緩存一致性
這些年隨著基礎(chǔ)設(shè)施的發(fā)展,局域網(wǎng)內(nèi)千兆甚至萬(wàn)兆的帶寬已經(jīng)比較普遍,以萬(wàn)兆計(jì)算,每秒傳輸大約 1250M 字節(jié)的數(shù)據(jù),而 SATA 磁盤(pán)的讀寫(xiě)速度這些年基本達(dá)到瓶頸,在 300-500M/s 附近,也就是純讀寫(xiě)的話,網(wǎng)絡(luò)已經(jīng)超過(guò)了磁盤(pán)的能力,不再是瓶頸了,像 NAS 網(wǎng)絡(luò)磁盤(pán)這些年也開(kāi)始普及起來(lái)。
但這并不代表,沒(méi)有必要對(duì)讀寫(xiě)進(jìn)行優(yōu)化,畢竟網(wǎng)絡(luò)讀寫(xiě)的速度還是遠(yuǎn)慢于內(nèi)存的讀寫(xiě)。常見(jiàn)的優(yōu)化方法主要有:
內(nèi)存中緩存文件內(nèi)容; 預(yù)加載數(shù)據(jù)塊,以避免客戶端等待; 合并讀寫(xiě)請(qǐng)求,也就是將單次請(qǐng)求做些積累,以批量方式發(fā)送給 Server 端。
會(huì)出現(xiàn)更新丟失的現(xiàn)象。當(dāng)多個(gè) Client 在一個(gè)時(shí)間段內(nèi),先后寫(xiě)入同一個(gè)文件時(shí),先寫(xiě)入的 Client 可能會(huì)丟失其寫(xiě)入內(nèi)容,因?yàn)榭赡軙?huì)被后寫(xiě)入的 Client 的內(nèi)容覆蓋掉; 數(shù)據(jù)可見(jiàn)性問(wèn)題。Client 讀取的是自己的緩存,在其過(guò)期之前,如果別的 Client 更新了文件內(nèi)容,它是看不到的;也就是說(shuō),在同一時(shí)間,不同 Client 讀取同一個(gè)文件,內(nèi)容可能不一致。
這類(lèi)問(wèn)題有幾種方法:
文件只讀不改:一旦文件被 create 了,就只能讀不能修改。這樣 Client 端的緩存,就不存在不一致的問(wèn)題; 通過(guò)鎖:用鎖的話還要考慮不同的粒度。寫(xiě)的時(shí)候是否允許其他 Client 讀? 讀的時(shí)候是否允許其他 Client 寫(xiě)? 這是在性能和一致性之間的權(quán)衡,作為文件系統(tǒng)來(lái)說(shuō),由于對(duì)業(yè)務(wù)并沒(méi)有約束性,所以要做出合理的權(quán)衡,比較困難,因此最好是提供不同粒度的鎖,由業(yè)務(wù)端來(lái)選擇。但這樣的副作用是,業(yè)務(wù)端的使用成本抬高了。
九、安全性
由于分布式文件存儲(chǔ)系統(tǒng),肯定是一個(gè)多客戶端使用、多租戶的一個(gè)產(chǎn)品,而它又存儲(chǔ)了可能是很重要的信息,所以安全性是它的重要部分。
主流文件系統(tǒng)的權(quán)限模型有以下這么幾種:
DAC:全稱(chēng)是 Discretionary Access Control,就是我們熟悉的 Unix 類(lèi)權(quán)限框架,以 user-group-privilege 為三級(jí)體系,其中 user 就是 owner,group 包括 owner 所在 group 和非 owner 所在的 group、privilege 有 read、write 和 execute。這套體系主要是以 owner 為出發(fā)點(diǎn),owner 允許誰(shuí)對(duì)哪些文件具有什么樣的權(quán)限。 MAC:全稱(chēng)是 Mandatory Access Control,它是從資源的機(jī)密程度來(lái)劃分。比如分為“普通”、“機(jī)密”、“絕密”這三層,每個(gè)用戶可能對(duì)應(yīng)不同的機(jī)密閱讀權(quán)限。這種權(quán)限體系起源于安全機(jī)構(gòu)或軍隊(duì)的系統(tǒng)中,會(huì)比較常見(jiàn)。它的權(quán)限是由管理員來(lái)控制和設(shè)定的。Linux 中的 SELinux 就是 MAC 的一種實(shí)現(xiàn),為了彌補(bǔ) DAC 的缺陷和安全風(fēng)險(xiǎn)而提供出來(lái)。關(guān)于 SELinux 所解決的問(wèn)題可以參考 What is SELinux? RBAC:全稱(chēng)是 Role Based Access Control,是基于角色 (role) 建立的權(quán)限體系。角色擁有什么樣的資源權(quán)限,用戶歸到哪個(gè)角色,這對(duì)應(yīng)企業(yè) / 公司的組織機(jī)構(gòu)非常合適。RBAC 也可以具體化,就演變成 DAC 或 MAC 的權(quán)限模型。
市面上的分布式文件系統(tǒng)有不同的選擇,像 ceph 就提供了類(lèi)似 DAC 但又略有區(qū)別的權(quán)限體系,Hadoop 自身就是依賴(lài)于操作系統(tǒng)的權(quán)限框架,同時(shí)其生態(tài)圈內(nèi)有 Apache Sentry 提供了基于 RBAC 的權(quán)限體系來(lái)做補(bǔ)充。
十、其他
1、空間分配
有連續(xù)空間和鏈表空間兩種。連續(xù)空間的優(yōu)勢(shì)是讀寫(xiě)快,按順序即可,劣勢(shì)是造成磁盤(pán)碎片,更麻煩的是,隨著連續(xù)的大塊磁盤(pán)空間被分配滿而必須尋找空洞時(shí),連續(xù)分配需要提前知道待寫(xiě)入文件的大小,以便找到合適大小的空間,而待寫(xiě)入文件的大小,往往又是無(wú)法提前知道的 (比如可編輯的 word 文檔,它的內(nèi)容可以隨時(shí)增大);
而鏈表空間的優(yōu)勢(shì)是磁盤(pán)碎片很少,劣勢(shì)是讀寫(xiě)很慢,尤其是隨機(jī)讀,要從鏈表首個(gè)文件塊一個(gè)一個(gè)地往下找。
為了解決這個(gè)問(wèn)題,出現(xiàn)了索引表——把文件和數(shù)據(jù)塊的對(duì)應(yīng)關(guān)系也保存一份,存在索引節(jié)點(diǎn)中 (一般稱(chēng)為 i 節(jié)點(diǎn)),操作系統(tǒng)會(huì)將 i 節(jié)點(diǎn)加載到內(nèi)存,從而程序隨機(jī)尋找數(shù)據(jù)塊時(shí),在內(nèi)存中就可以完成了。通過(guò)這種方式來(lái)解決磁盤(pán)鏈表的劣勢(shì),如果索引節(jié)點(diǎn)的內(nèi)容太大,導(dǎo)致內(nèi)存無(wú)法加載,還有可能形成多級(jí)索引結(jié)構(gòu)。
2、文件刪除
實(shí)時(shí)刪除還是延時(shí)刪除? 實(shí)時(shí)刪除的優(yōu)勢(shì)是可以快速釋放磁盤(pán)空間;延時(shí)刪除只是在刪除動(dòng)作執(zhí)行的時(shí)候,置個(gè)標(biāo)識(shí)位,后續(xù)在某個(gè)時(shí)間點(diǎn)再來(lái)批量刪除,它的優(yōu)勢(shì)是文件仍然可以階段性地保留,最大程度地避免了誤刪除,缺點(diǎn)是磁盤(pán)空間仍然被占著。在分布式文件系統(tǒng)中,磁盤(pán)空間都是比較充裕的資源,因此幾乎都采用邏輯刪除,以對(duì)數(shù)據(jù)可以進(jìn)行恢復(fù),同時(shí)在一段時(shí)間之后 (可能是 2 天或 3 天,這參數(shù)一般都可配置),再對(duì)被刪除的資源進(jìn)行回收。
怎么回收被刪除或無(wú)用的數(shù)據(jù)? 可以從文件的 meta 信息出發(fā)——如果 meta 信息的“文件 - 數(shù)據(jù)塊”映射表中包含了某個(gè)數(shù)據(jù)塊,則它就是有用的;如果不包含,則表明該數(shù)據(jù)塊已經(jīng)是無(wú)效的了。所以,刪除文件,其實(shí)是刪除 meta 中的“文件 - 數(shù)據(jù)塊”映射信息 (如果要保留一段時(shí)間,則是把這映射信息移到另外一個(gè)地方去)。
3、面向小文件的分布式文件系統(tǒng)
有很多這樣的場(chǎng)景,比如電商——那么多的商品圖片、個(gè)人頭像,比如社交網(wǎng)站——那么多的照片,它們具有的特性,可以簡(jiǎn)單歸納下:
每個(gè)文件都不大; 數(shù)量特別巨大; 讀多寫(xiě)少; 不會(huì)修改。
針對(duì)這種業(yè)務(wù)場(chǎng)景,主流的實(shí)現(xiàn)方式是仍然是以大數(shù)據(jù)塊的形式存儲(chǔ),小文件以邏輯存儲(chǔ)的方式存在,即文件 meta 信息記錄其是在哪個(gè)大數(shù)據(jù)塊上,以及在該數(shù)據(jù)塊上的 offset 和 length 是多少,形成一個(gè)邏輯上的獨(dú)立文件。這樣既復(fù)用了大數(shù)據(jù)塊系統(tǒng)的優(yōu)勢(shì)和技術(shù)積累,又減少了 meta 信息。
4、文件指紋和去重
文件指紋就是根據(jù)文件內(nèi)容,經(jīng)過(guò)算法,計(jì)算出文件的唯一標(biāo)識(shí)。如果兩個(gè)文件的指紋相同,則文件內(nèi)容相同。在使用網(wǎng)絡(luò)云盤(pán)的時(shí)候,發(fā)現(xiàn)有時(shí)候上傳文件非常地快,就是文件指紋發(fā)揮作用。云盤(pán)服務(wù)商通過(guò)判斷該文件的指紋,發(fā)現(xiàn)之前已經(jīng)有人上傳過(guò)了,則不需要真的上傳該文件,只要增加一個(gè)引用即可。在文件系統(tǒng)中,通過(guò)文件指紋可以用來(lái)去重、也可以用來(lái)判斷文件內(nèi)容是否損壞、或者對(duì)比文件副本內(nèi)容是否一致,是一個(gè)基礎(chǔ)組件。
文件指紋的算法也比較多,有熟悉的 md5、sha256、也有 google 專(zhuān)門(mén)針對(duì)文本領(lǐng)域的 simhash 和 minhash 等。
十一、總結(jié)
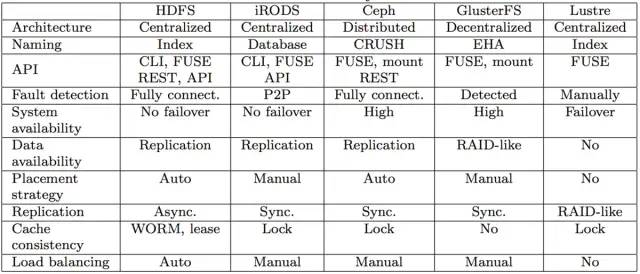
從這里也可以看到,選擇其實(shí)很多,并不是 GFS 論文中的方式就是最好的。在不同的業(yè)務(wù)場(chǎng)景中,也可以有更多的選擇策略。最后,關(guān)注公眾號(hào)互聯(lián)網(wǎng)架構(gòu)師,在后臺(tái)回復(fù):2T,可以獲取我整理的 Java 分布式系列面試題和答案,非常齊全。
全棧架構(gòu)社區(qū)交流群
「全棧架構(gòu)社區(qū)」建立了讀者架構(gòu)師交流群,大家可以添加小編微信進(jìn)行加群。歡迎有想法、樂(lè)于分享的朋友們一起交流學(xué)習(xí)。
看完本文有收獲?請(qǐng)轉(zhuǎn)發(fā)分享給更多人
往期資源:
2019最新Python視頻:從入門(mén)到Swiper項(xiàng)目實(shí)戰(zhàn)
2019年Android應(yīng)用程序開(kāi)發(fā)
2019重磅高級(jí)資源:Java并發(fā)編程原理和實(shí)戰(zhàn)
最新黑馬大數(shù)據(jù)資源:深入解析docker容器化技術(shù)
最新Java后端實(shí)戰(zhàn)視頻:SSM框架在線商城系統(tǒng)
2019最新黑客技術(shù)之Windows網(wǎng)絡(luò)安全精講