
萬萬沒想到,TF-IDF是這么計(jì)算的!
一、了解tf-idf
對(duì)于文本處理,tf-idf的使用已經(jīng)非常普遍,在sklearn等知名的機(jī)器學(xué)習(xí)開源庫中都提供了直接的調(diào)用,然而很多人并沒有搞清楚TF-IDF是怎么算出來的,也就無法對(duì)這種計(jì)算方法進(jìn)行針對(duì)性的改進(jìn)了。我之前也是稀里糊涂的,在各種開源庫隨手可得的Python年代“調(diào)包需謹(jǐn)慎”,不能讓自己成為只會(huì)調(diào)包的人,我們內(nèi)功還是需要修煉的,計(jì)算之前,我們先了解下tf-idf的基本定義。
tf(term frequency:指的是某一個(gè)給定的詞語在該文件中出現(xiàn)的次數(shù),這個(gè)數(shù)字通常會(huì)被歸一化(一般是詞頻除以該文件總詞數(shù)),以防止它偏向長(zhǎng)的文件。
idf (inverse document frequency):反應(yīng)了一個(gè)詞在所有文本(整個(gè)文檔)中出現(xiàn)的頻率,如果一個(gè)詞在很多的文本中出現(xiàn),那么它的idf值應(yīng)該低,而反過來如果一個(gè)詞在比較少的文本中出現(xiàn),那么它的idf值應(yīng)該高。
一個(gè)詞語的重要性隨著它在文件中出現(xiàn)的次數(shù)成正比增加,但同時(shí)會(huì)隨著它在語料庫中出現(xiàn)的頻率成反比下降。
下面我們看看大多數(shù)情況下,tf-idf 的定義:
TF的計(jì)算公式如下:
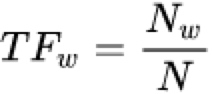
其中![]() 是在某一文本中詞條w出現(xiàn)的次數(shù),
是在某一文本中詞條w出現(xiàn)的次數(shù),![]() 是該文本總詞條數(shù)。
是該文本總詞條數(shù)。
IDF的計(jì)算公式:
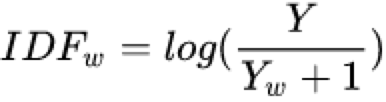
其中Y是語料庫的文檔總數(shù),Yw是包含詞條w的文檔數(shù),分母加一是為了避免![]() 未出現(xiàn)在任何文檔中從而導(dǎo)致分母為
未出現(xiàn)在任何文檔中從而導(dǎo)致分母為![]() 的情況。
的情況。
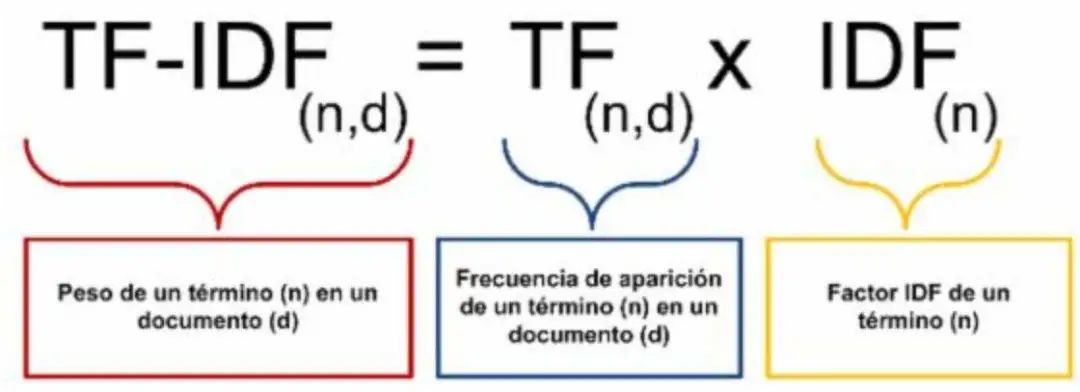
TF-IDF的就是將TF和IDF相乘
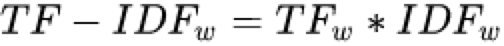
從以上計(jì)算公式便可以看出,某一特定文件內(nèi)的高詞語頻率,以及該詞語在整個(gè)文件集合中的低文件頻率,可以產(chǎn)生出高權(quán)重的TF-IDF。因此,TF-IDF傾向于過濾掉常見的詞語,保留重要的詞語。
二、手算tf-idf
現(xiàn)在我們來看看,tf-idf到底怎么計(jì)算的,和我們手算的能不能對(duì)上。
在sklearn中,tf與上述定義一致,我們看看idf在sklearn中的定義,可以看到,分子分母都加了1,做了更多的平滑處理
smooth_idf=False
idf(t) = log [ n / df(t) ] + 1
smooth_idf=True
idf(t) = log [ (1 + n) / (1 + df(t)) ] + 1
下面我們手把手的計(jì)算出TF-IDF的值,使用的是sklearn官方的案例:
corpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?']#初始化vector = TfidfVectorizer()#tf-idf計(jì)算tfidf = vector.fit_transform(corpus)#直接打印,得到的是一個(gè)稀疏矩陣,第1位表示文檔編號(hào),第二位代表詞的編號(hào)print(tfidf)(0, 1) 0.46979138557992045(0, 2) 0.5802858236844359(0, 6) 0.38408524091481483(0, 3) 0.38408524091481483(0, 8) 0.38408524091481483(1, 5) 0.5386476208856763(1, 1) 0.6876235979836938(1, 6) 0.281088674033753(1, 3) 0.281088674033753(1, 8) 0.281088674033753(2, 4) 0.511848512707169(2, 7) 0.511848512707169(2, 0) 0.511848512707169(2, 6) 0.267103787642168(2, 3) 0.267103787642168(2, 8) 0.267103787642168(3, 1) 0.46979138557992045(3, 2) 0.5802858236844359(3, 6) 0.38408524091481483(3, 3) 0.38408524091481483(3, 8) 0.38408524091481483
通過vocabulary_屬性,可以查看每個(gè)詞對(duì)應(yīng)的數(shù)字編號(hào),就可以與上面的矩陣對(duì)應(yīng)起來了
vector.vocabulary_{'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1,'second': 5, 'and': 0, 'third': 7, 'one': 4}
通過上面的字典和矩陣可以知道,第一個(gè)文檔'This is the first document'的tf-idf 值如下
(0, 1) 0.46979138557992045 document(0, 2) 0.58028582368443590 first(0, 6) 0.38408524091481483 the(0, 3) 0.38408524091481483 is(0, 8) 0.38408524091481483 this
document ? first ? ? ? ? ? the ? ? ? ? ? ? is ? ? ? ? ? ? this
0.46979 ? ? ?0.58028 ? ? ?0.384085 ? 0.38408 ?0.384085
我們手動(dòng)計(jì)算來驗(yàn)證下:
tf 計(jì)算
對(duì)于第一個(gè)文檔,有5個(gè)不同的詞,每個(gè)詞的詞頻為:tf= 1/5
idf計(jì)算
document:log((1+N)/(1+N(document)))+1=??log((1+4)/(1+3))+1?=?1.2231435first???:log((1+N)/(1+N(first)))+1???=??log((1+4)/(1+2))+1?=?1.5108256the?????:log((1+N)/(1+N(the?)))+1????=??log((1+4)/(1+4))+1?=?1.0is??????:log((1+N)/(1+N(is?)))+1?????=??log((1+4)/(1+4))+1?=?1.0this????:log((1+N)/(1+N(this)))+1????=??log((1+4)/(1+4))+1?=?1.0

tf-idf計(jì)算
1.2231435*1/5 = 0.244628691.5108256*1/5 = 0.302165121.0*1/5 = 0.21.0*1/5 = 0.21.0*1/5 = 0.2
得到我們手工計(jì)算的tf-idf值

和我們sklearn計(jì)算的
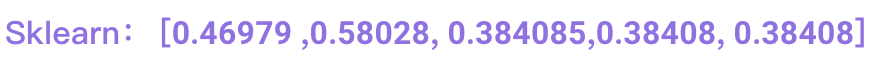
答案并不對(duì),哪里出了問題呢?我們仔細(xì)看看原來的代碼,因?yàn)閟klearn做了歸一化,我們按同樣的方法進(jìn)行歸一化計(jì)算如下:
計(jì)算每個(gè)tf-idf 的平方根
(0.24462869**2 + 0.30216512**2 + 0.2**2 + 0.2**2 + 0.2**2)**0.5= 0.5207177313
對(duì)每個(gè)值除以平方根
0.24462869/0.5207177313244965 = 0.46979135774340350.30216512/0.5207177313244965 = 0.58028582823829230.20000000/0.5207177313244965 = 0.38408524997080550.20000000/0.5207177313244965 = 0.38408524997080550.20000000/0.5207177313244965 = 0.3840852499708055
這樣一看,就和我們的sklearn計(jì)算的一致了,到此,我們也算是學(xué)會(huì)了計(jì)算tf-idf值了,加深了對(duì)該方法的理解,以便于后期的算法調(diào)用,心里有貨,才不懼未知。