
為什么不要輕易使用 Chrome 復(fù)制的 XPath?

作者:kingname
來(lái)源:未聞Code
有一些同學(xué)在寫爬蟲的時(shí)候,喜歡在Chrome 開發(fā)者工具里面直接復(fù)制 XPath,如下圖所示:
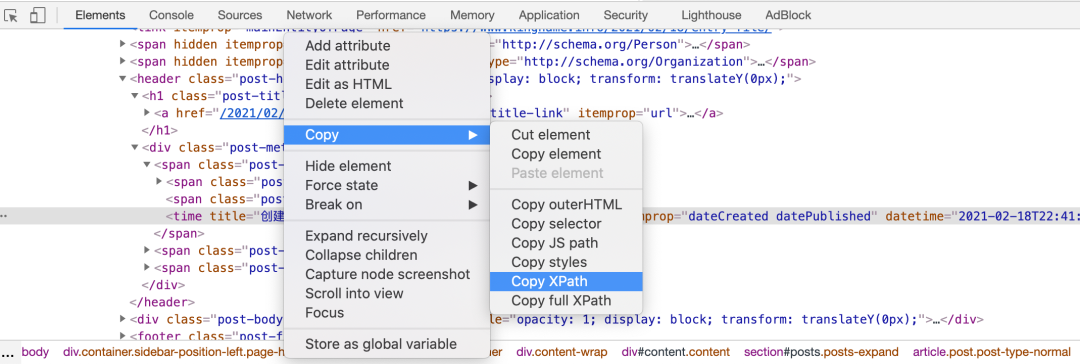
他們覺(jué)得這樣復(fù)制出來(lái)的 XPath 雖然長(zhǎng)了點(diǎn),但是工作一切正常,所以頻繁使用。
但我希望大家不要過(guò)于依賴這個(gè)功能。因?yàn)樗o出的結(jié)果僅作參考,有時(shí)候并不能讓你提取出數(shù)據(jù)。我們來(lái)看一個(gè)例子。
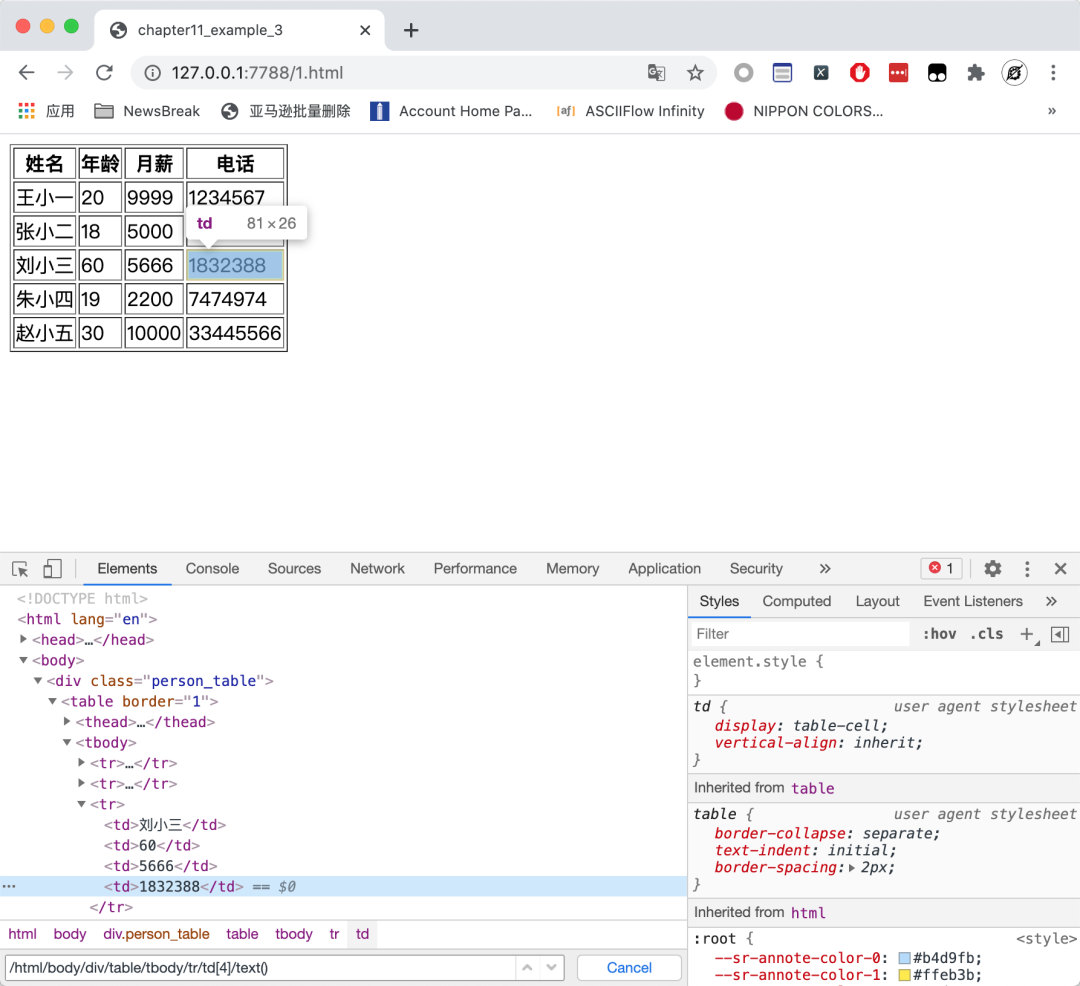
這是一個(gè)非常簡(jiǎn)單的HTML 頁(yè)面,頁(yè)面中有一個(gè)表格,表格有一列叫做電話。我現(xiàn)在想把這里面的5個(gè)電話提取出來(lái)。如果直接使用 Chrome 的復(fù)制 XPath 的功能,我們可以得到下面這個(gè) XPath:
/html/body/div/table/tbody/tr[3]/td[4]
這實(shí)際上對(duì)應(yīng)了劉小三這一行的電話字段。那么,我們?nèi)サ?code style="font-size: 14px;overflow-wrap: break-word;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: 'Operator Mono', Consolas, Monaco, Menlo, monospace;word-break: break-all;">tr后面的數(shù)字,似乎就能覆蓋到所有行了:
/html/body/div/table/tbody/tr/td[4]/text()
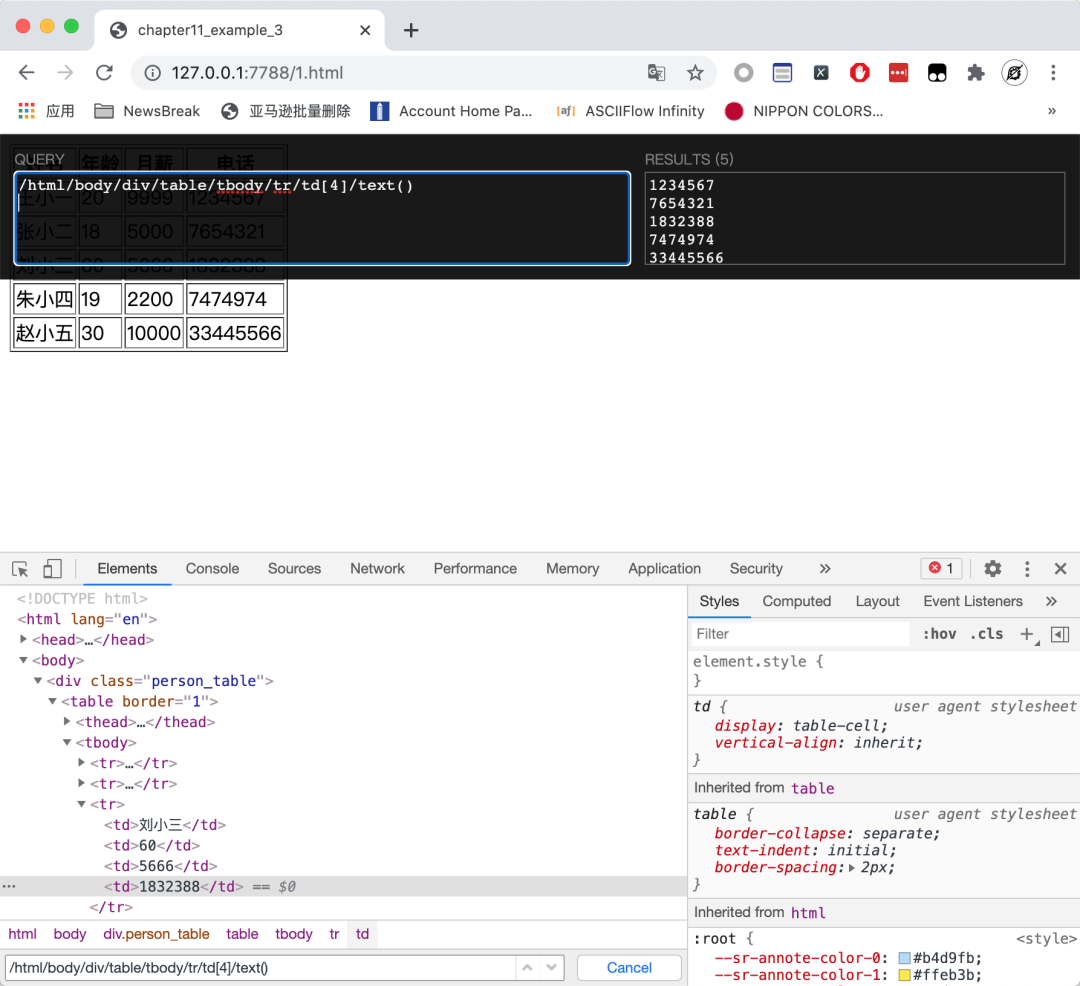
在 XPath Helper 上面運(yùn)行看看效果,確實(shí)提取出了所有的電話號(hào)碼,如下圖所示:
但如果你使用 requests 來(lái)爬這個(gè)網(wǎng)頁(yè),然后使用 XPath 提取電話號(hào)碼,你就會(huì)發(fā)現(xiàn)什么都提取不到,如下圖所示:

你可能會(huì)想,這應(yīng)該是異步加載導(dǎo)致的問(wèn)題。表格里面的數(shù)據(jù)是通過(guò) Ajax 后臺(tái)加載的,不在網(wǎng)頁(yè)源代碼里面。
那么我們打印看看網(wǎng)頁(yè)的源代碼:
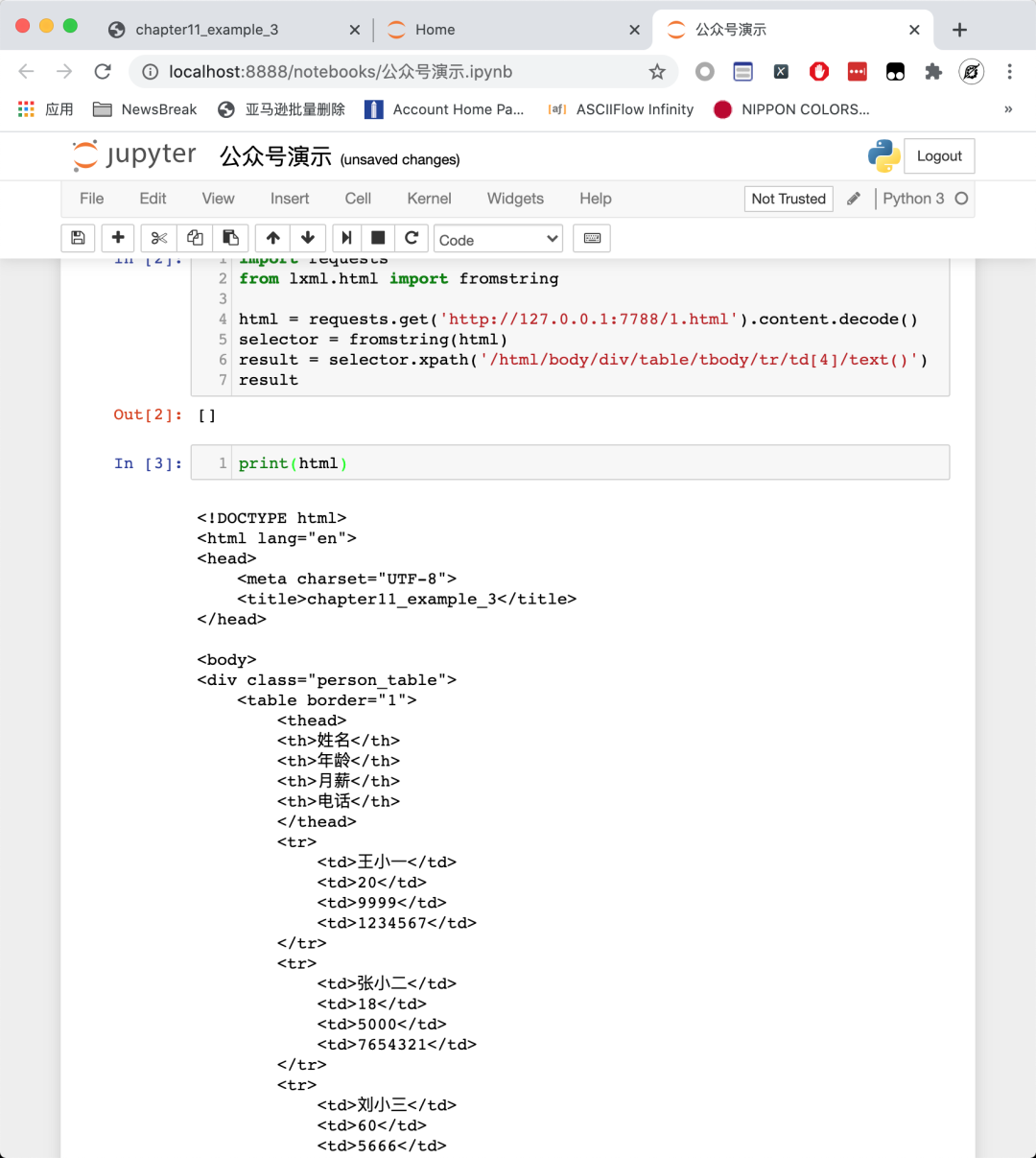
大家可以看到,數(shù)據(jù)就在網(wǎng)頁(yè)源代碼里面,那為什么我們?cè)贑hrome 上面通過(guò) XPath Helper 就能提取數(shù)據(jù),而用 requests 就無(wú)法提取數(shù)據(jù)?
實(shí)際上,如果大家仔細(xì)觀察從 Chrome 中復(fù)制出來(lái)的 XPath,就會(huì)發(fā)現(xiàn)它里面有一個(gè)tbody節(jié)點(diǎn)。但是我們的網(wǎng)頁(yè)源代碼是沒(méi)有這個(gè)節(jié)點(diǎn)的。
這就要說(shuō)到 Chrome 開發(fā)者工具里面顯示的 HTML 代碼,跟網(wǎng)頁(yè)真正的源代碼之間的區(qū)別了。很多人分不清楚這兩者的區(qū)別,所以導(dǎo)致寫出的 XPath 匹配不到數(shù)據(jù)。
當(dāng)我們說(shuō)到網(wǎng)頁(yè)源代碼的時(shí)候,我們指的是在網(wǎng)頁(yè)上右鍵,選擇“顯示網(wǎng)頁(yè)源代碼”按鈕所查看到的 HTML 代碼,如下圖所示:
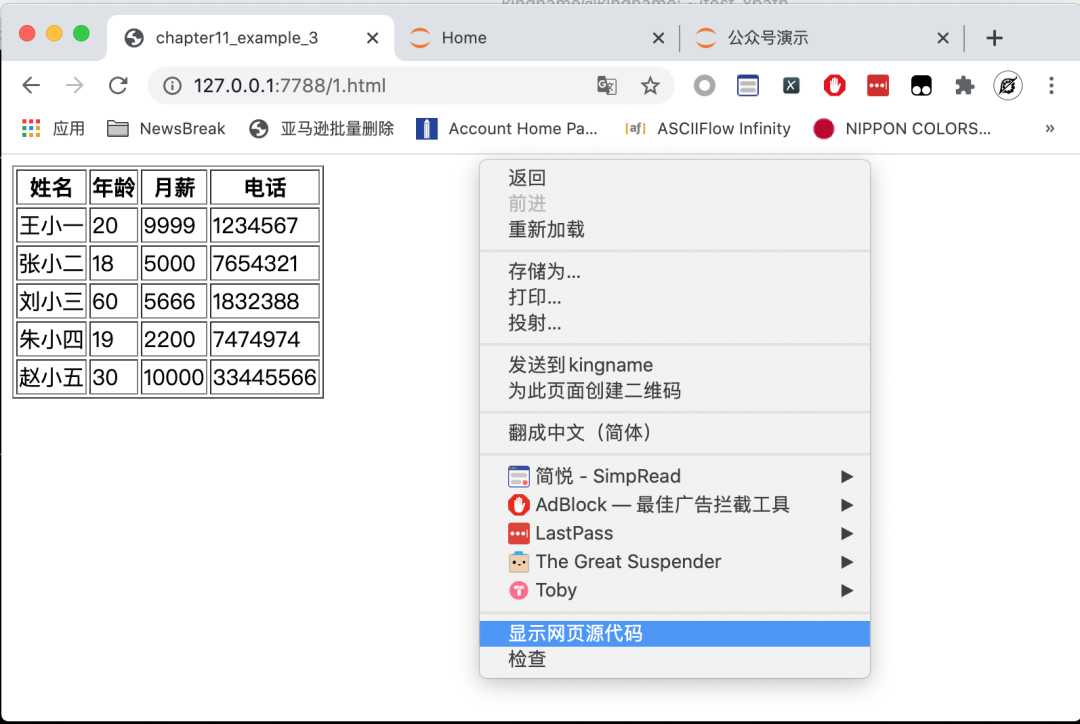
這個(gè)查看源代碼的頁(yè)面長(zhǎng)成下圖所示的這樣:

注意地址欄,是以view-source:開頭的。這才是網(wǎng)頁(yè)真真正正的源代碼。
而Chrome 的開發(fā)者工具里面的Element標(biāo)簽所顯示的源代碼,長(zhǎng)成下面這樣:
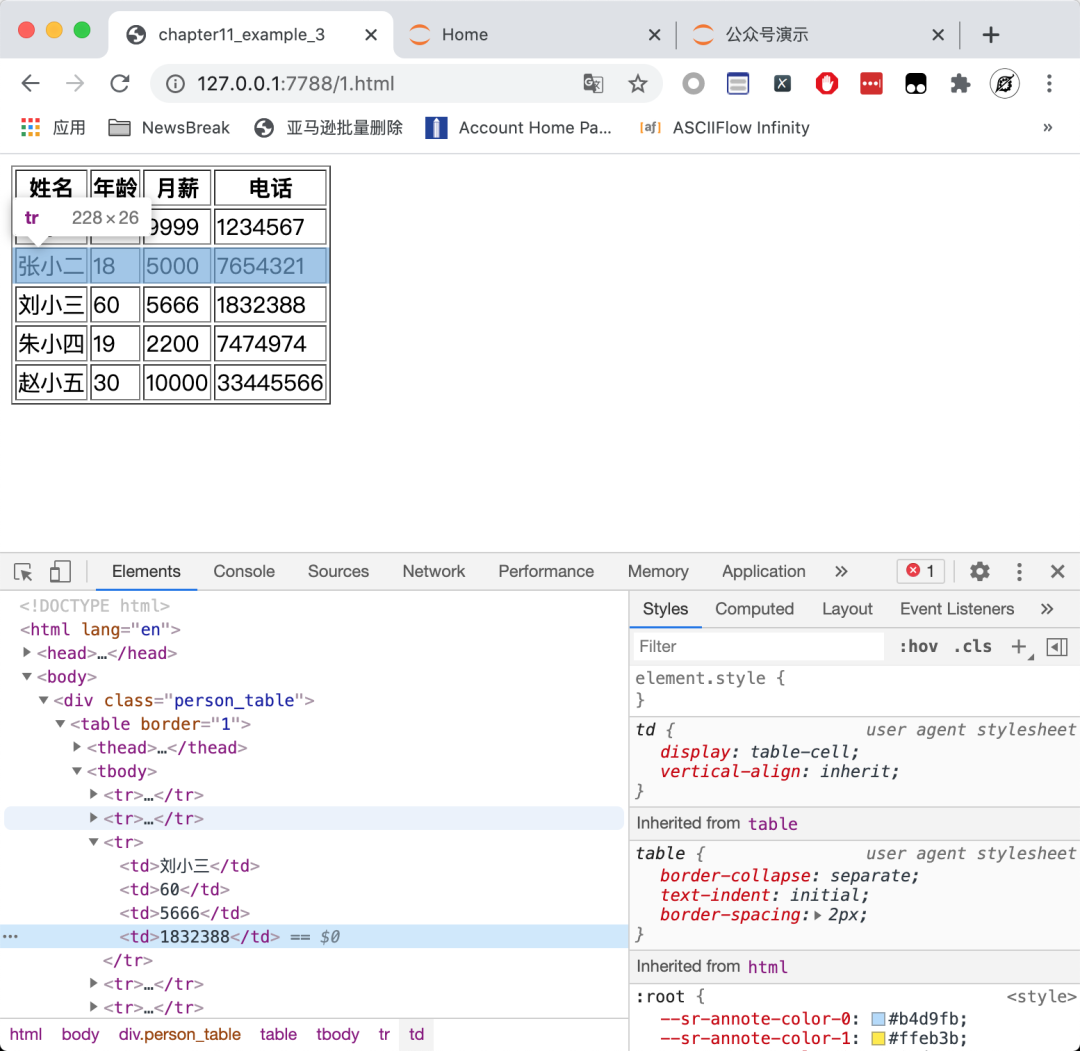
這兩個(gè)地方的HTML代碼可能是不一樣的,而且在現(xiàn)代化的網(wǎng)站中,這兩個(gè)地方的 HTML大概率是不一樣的。當(dāng)我們使用 requests 或者 Scrapy 時(shí),拿到的是第一種情況的源代碼,這才是網(wǎng)頁(yè)真正的源代碼。而在開發(fā)者工具里面的 HTML 代碼,是經(jīng)過(guò) Chrome 瀏覽器修飾甚至大幅度增刪后的 HTML 代碼。當(dāng)網(wǎng)站有異步加載時(shí),JavaScript 可以輕易在這里增加、刪除非常多的內(nèi)容。即使網(wǎng)站沒(méi)有異步加載,如果網(wǎng)站原始的 HTML 代碼編寫不夠規(guī)范,或者存在一些錯(cuò)漏,那么 Chrome 瀏覽器會(huì)自動(dòng)糾錯(cuò)和調(diào)整。
以本文的例子來(lái)說(shuō),在 HTML 的官方規(guī)范里面,表格的正文確實(shí)應(yīng)該包在<tbody></tbody>標(biāo)簽里面。但現(xiàn)在大多數(shù)情況下,前端開發(fā)者都會(huì)省略這個(gè)標(biāo)簽,所以真正的源代碼里面是沒(méi)有這個(gè)標(biāo)簽的。而 Chrome 會(huì)自動(dòng)識(shí)別到這種情況,然后自動(dòng)加上這個(gè)標(biāo)簽,所以在開發(fā)者工具里面看到的 HTML 代碼是有這個(gè)標(biāo)簽的。
當(dāng)你寫爬蟲的時(shí)候,不僅僅是 Chrome 開發(fā)者工具里面復(fù)制的 XPath 僅作參考,甚至這個(gè)開發(fā)者工具里面顯示的 HTML 代碼也是僅作參考。你應(yīng)該首先檢查你需要的數(shù)據(jù)是不是在真正的源代碼里面,然后再來(lái)確定是寫 XPath 還是抓接口。如果是寫 XPath,那么更應(yīng)該以這個(gè)真正的源代碼為準(zhǔn),而不是開發(fā)者工具里面的 HTML 代碼。

還不過(guò)癮?試試它們
▲Python最佳代碼實(shí)踐:性能、內(nèi)存和可用性!
▲長(zhǎng)文干貨:多圖詳解 10 大高性能開發(fā)核心技術(shù)