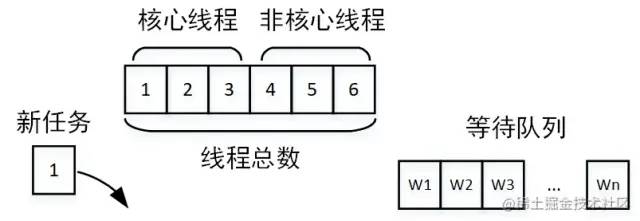
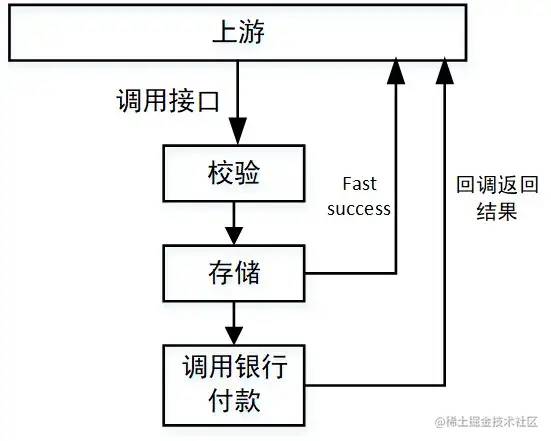
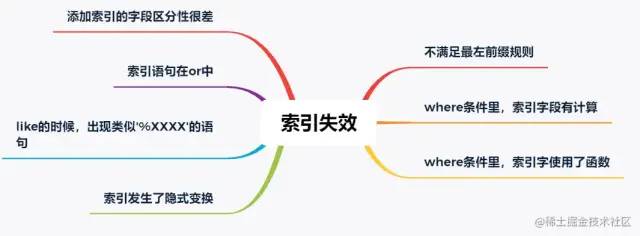
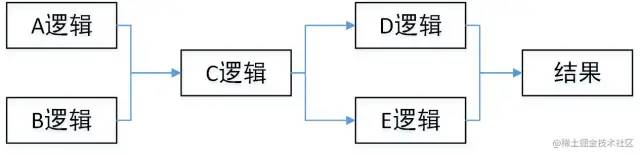
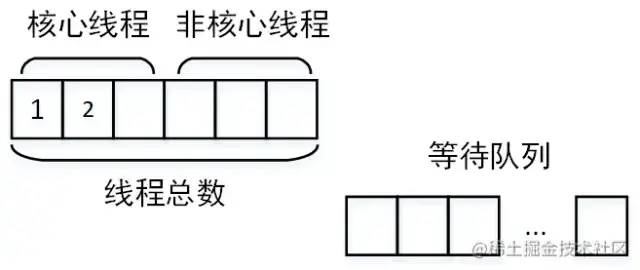
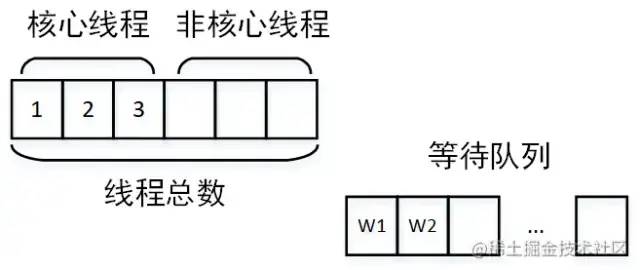
juejin.cn/post/7043423820543164453 背景 我負(fù)責(zé)的系統(tǒng)到2021年初完成了功能上的建設(shè),開(kāi)始進(jìn)入到推廣階段。隨著推廣的逐步深入,收到了很多好評(píng)的同時(shí)也收到了很多對(duì)性能的吐槽。剛剛收到吐槽的時(shí)候,我們的心情是這樣的: 當(dāng)越來(lái)越多對(duì)性能的吐槽反饋到我們這里的時(shí)候,我們意識(shí)到,接口性能的問(wèn)題的優(yōu)先級(jí)必須提高了。然后我們就跟蹤了1周的接口性能監(jiān)控,這個(gè)時(shí)候我們的心情是這樣的: 有20多個(gè)慢接口,5個(gè)接口響應(yīng)時(shí)間超過(guò)5s,1個(gè)超過(guò)10s,其余的都在2s以上,穩(wěn)定性不足99.8%。作為一個(gè)優(yōu)秀的后端程序員,這個(gè)數(shù)據(jù)肯定是不能忍的,我們馬上就進(jìn)入了漫長(zhǎng)的接口優(yōu)化之路。本文就是對(duì)我們漫長(zhǎng)工作歷程的一個(gè)總結(jié)。 哪些問(wèn)題會(huì)引起接口性能問(wèn)題? 這個(gè)問(wèn)題的答案非常多,需要根據(jù)自己的業(yè)務(wù)場(chǎng)景具體分析。這里做一個(gè)不完全的總結(jié): 機(jī)器問(wèn)題(fullGC,機(jī)器重啟,線(xiàn)程打滿(mǎn)) 問(wèn)題解決 本文列進(jìn)的慢查詢(xún)問(wèn)題默認(rèn)都是基于 MySQL。 所謂的深度分頁(yè)問(wèn)題,涉及到mysql分頁(yè)的原理。通常情況下,mysql的分頁(yè)是這樣寫(xiě)的: select name ,code from student limit 100 ,20 含義當(dāng)然就是從student表里查100到120這20條數(shù)據(jù),mysql會(huì)把前120條數(shù)據(jù)都查出來(lái),拋棄前100條,返回20條。當(dāng)分頁(yè)所以深度不大的時(shí)候當(dāng)然沒(méi)問(wèn)題,隨著分頁(yè)的深入,sql可能會(huì)變成這樣: select name ,code from student limit 1000000 ,20 這個(gè)時(shí)候,mysql會(huì)查出來(lái)1000020條數(shù)據(jù),拋棄1000000條,如此大的數(shù)據(jù)量,速度一定快不起來(lái)。那如何解決呢?一般情況下,最好的方式是增加一個(gè)條件: select name ,code from student where id >1000000 limit 20 這樣,mysql會(huì)走主鍵索引,直接連接到1000000處,然后查出來(lái)20條數(shù)據(jù)。但是這個(gè)方式需要接口的調(diào)用方配合改造,把上次查詢(xún)出來(lái)的最大id以參數(shù)的方式傳給接口提供方,會(huì)有溝通成本(調(diào)用方:老子不改!)。 這個(gè)是最容易解決的問(wèn)題,我們可以通過(guò) show create table xxxx(表名)查看某張表的索引。具體加索引的語(yǔ)句網(wǎng)上太多了,不再贅述。不過(guò)順便提一嘴,加索引之前,需要考慮一下這個(gè)索引是不是有必要加,如果加索引的字段區(qū)分度非常低,那即使加了索引也不會(huì)生效。另外,加索引的alter操作,可能引起鎖表,執(zhí)行sql的時(shí)候一定要在低峰期(血淚史!!!!) 這個(gè)是慢查詢(xún)最不好分析的情況,雖然mysql提供了explain來(lái)評(píng)估某個(gè)sql的查詢(xún)性能,其中就有使用的索引。但是為啥索引會(huì)失效呢?mysql卻不會(huì)告訴咱,需要咱自己分析。大體上,可能引起索引失效的原因有這幾個(gè)(可能不完全): 需要特別提出的是,關(guān)于字段區(qū)分性很差的情況,在加索引的時(shí)候就應(yīng)該進(jìn)行評(píng)估。如果區(qū)分性很差,這個(gè)索引根本就沒(méi)必要加。區(qū)分性很差是什么意思呢,舉幾個(gè)例子,比如: 某個(gè)字段只可能有3個(gè)值,那這個(gè)字段的索引區(qū)分度就很低。 再比如,某個(gè)字段值非常集中,90%都是1,剩下10%可能是2,3,4.... 進(jìn)一步的,那如果不符合上面所有的索引失效的情況,但是mysql還是不使用對(duì)應(yīng)的索引,是為啥呢?這個(gè)跟mysql的sql優(yōu)化有關(guān),mysql會(huì)在sql優(yōu)化的時(shí)候自己選擇合適的索引,很可能是mysql自己的選擇算法算出來(lái)使用這個(gè)索引不會(huì)提升性能,所以就放棄了。這種情況,可以使用force index 關(guān)鍵字強(qiáng)制使用索引(建議修改前先實(shí)驗(yàn)一下,是不是真的會(huì)提升查詢(xún)效率): select name ,code from student force index (XXXXXX) where name = '天才' 我把join過(guò)多 和子查詢(xún)過(guò)多放在一起說(shuō)了。一般來(lái)說(shuō),不建議使用子查詢(xún),可以把子查詢(xún)改成join來(lái)優(yōu)化。同時(shí),join關(guān)聯(lián)的表也不宜過(guò)多,一般來(lái)說(shuō)2-3張表還是合適的。具體關(guān)聯(lián)幾張表比較安全是需要具體問(wèn)題具體分析的,如果各個(gè)表的數(shù)據(jù)量都很少,幾百條幾千條,那么關(guān)聯(lián)的表的可以適當(dāng)多一些,反之則需要少一些。 另外需要提到的是,在大多數(shù)情況下join是在內(nèi)存里做的,如果匹配的量比較小,或者join_buffer設(shè)置的比較大,速度也不會(huì)很慢。但是,當(dāng)join的數(shù)據(jù)量比較大的時(shí)候,mysql會(huì)采用在硬盤(pán)上創(chuàng)建臨時(shí)表的方式進(jìn)行多張表的關(guān)聯(lián)匹配,這種顯然效率就極低,本來(lái)磁盤(pán)的IO就不快,還要關(guān)聯(lián)。 一般遇到這種情況的時(shí)候就建議從代碼層面進(jìn)行拆分,在業(yè)務(wù)層先查詢(xún)一張表的數(shù)據(jù),然后以關(guān)聯(lián)字段作為條件查詢(xún)關(guān)聯(lián)表形成map,然后在業(yè)務(wù)層進(jìn)行數(shù)據(jù)的拼裝。一般來(lái)說(shuō),索引建立正確的話(huà),會(huì)比join快很多,畢竟內(nèi)存里拼接數(shù)據(jù)要比網(wǎng)絡(luò)傳輸和硬盤(pán)IO快得多。 這種問(wèn)題,如果只看代碼的話(huà)不太容易排查,最好結(jié)合監(jiān)控和數(shù)據(jù)庫(kù)日志一起分析。如果一個(gè)查詢(xún)有in,in的條件加了合適的索引,這個(gè)時(shí)候的sql還是比較慢就可以高度懷疑是in的元素過(guò)多。一旦排查出來(lái)是這個(gè)問(wèn)題,解決起來(lái)也比較容易,不過(guò)是把元素分個(gè)組,每組查一次。想再快的話(huà),可以再引入多線(xiàn)程。 進(jìn)一步的,如果in的元素量大到一定程度還是快不起來(lái),這種最好還是有個(gè)限制 select id from student where id in (1 ,2 ,3 ...... 1000 ) limit 200 當(dāng)然了,最好是在代碼層面做個(gè)限制 if (ids.size() > 200) { 這種問(wèn)題,單純代碼的修修補(bǔ)補(bǔ)一般就解決不了了,需要變動(dòng)整個(gè)的數(shù)據(jù)存儲(chǔ)架構(gòu)。或者是對(duì)底層mysql分表或分庫(kù)+分表;或者就是直接變更底層數(shù)據(jù)庫(kù),把mysql轉(zhuǎn)換成專(zhuān)門(mén)為處理大數(shù)據(jù)設(shè)計(jì)的數(shù)據(jù)庫(kù)。這種工作是個(gè)系統(tǒng)工程,需要嚴(yán)密的調(diào)研、方案設(shè)計(jì)、方案評(píng)審、性能評(píng)估、開(kāi)發(fā)、測(cè)試、聯(lián)調(diào),同時(shí)需要設(shè)計(jì)嚴(yán)密的數(shù)據(jù)遷移方案、回滾方案、降級(jí)措施、故障處理預(yù)案。除了以上團(tuán)隊(duì)內(nèi)部的工作,還可能有跨系統(tǒng)溝通的工作,畢竟做了重大變更,下游系統(tǒng)的調(diào)用接口的方式有可能會(huì)需要變化。 出于篇幅的考慮,這個(gè)不再展開(kāi)了,筆者有幸完整參與了一次億級(jí)別數(shù)據(jù)量的數(shù)據(jù)庫(kù)分表工作,對(duì)整個(gè)過(guò)程的復(fù)雜性深有體會(huì),后續(xù)有機(jī)會(huì)也會(huì)分享出來(lái)。 業(yè)務(wù)邏輯復(fù)雜 這種情況,一般都循環(huán)調(diào)用同一段代碼,每次循環(huán)的邏輯一致,前后不關(guān)聯(lián)。比如說(shuō),我們要初始化一個(gè)列表,預(yù)置12個(gè)月的數(shù)據(jù)給前端: List<Model> list = new ArrayList<>(); 這種顯然每個(gè)月的數(shù)據(jù)計(jì)算相互都是獨(dú)立的,我們完全可以采用多線(xiàn)程方式進(jìn)行: // 建立一個(gè)線(xiàn)程池,注意要放在外面,不要每次執(zhí)行代碼就建立一個(gè),具體線(xiàn)程池的使用就不展開(kāi)了 如果不是類(lèi)似上面循環(huán)調(diào)用,而是一次次的順序調(diào)用,而且調(diào)用之間沒(méi)有結(jié)果上的依賴(lài),那么也可以用多線(xiàn)程的方式進(jìn)行,例如: A a = doA();return doResult(d, e); CompletableFuture<A> futureA = CompletableFuture.supplyAsync(() -> doA());// 等a b 兩個(gè)任務(wù)都執(zhí)行完成 // 等d e兩個(gè)任務(wù)都執(zhí)行完成 return doResult(futureD.join(),futureE.join()); 這樣A B 兩個(gè)邏輯可以并行執(zhí)行,D E兩個(gè)邏輯可以并行執(zhí)行,最大執(zhí)行時(shí)間取決于哪個(gè)邏輯更慢。 線(xiàn)程池設(shè)計(jì)不合理 有的時(shí)候,即使我們使用了線(xiàn)程池讓任務(wù)并行處理,接口的執(zhí)行效率仍然不夠快,這種情況可能是怎么回事呢? 這種情況首先應(yīng)該懷疑是不是線(xiàn)程池設(shè)計(jì)的不合理。我覺(jué)得這里有必要回顧一下線(xiàn)程池的三個(gè)重要參數(shù):核心線(xiàn)程數(shù)、最大線(xiàn)程數(shù)、等待隊(duì)列。這三個(gè)參數(shù)是怎么打配合的呢?當(dāng)線(xiàn)程池創(chuàng)建的時(shí)候,如果不預(yù)熱線(xiàn)程池,則線(xiàn)程池中線(xiàn)程為0。當(dāng)有任務(wù)提交到線(xiàn)程池,則開(kāi)始創(chuàng)建核心線(xiàn)程。 當(dāng)核心線(xiàn)程全部被占滿(mǎn),如果再有任務(wù)到達(dá),則讓任務(wù)進(jìn)入等待隊(duì)列開(kāi)始等待。 如果隊(duì)列也被占滿(mǎn),則開(kāi)始創(chuàng)建非核心線(xiàn)程運(yùn)行。 如果線(xiàn)程總數(shù)達(dá)到最大線(xiàn)程數(shù),還是有任務(wù)到達(dá),則開(kāi)始根據(jù)線(xiàn)程池拋棄規(guī)則開(kāi)始拋棄。 根據(jù)線(xiàn)程池拋棄規(guī)則拋棄任務(wù) 那么這個(gè)運(yùn)行原理與接口運(yùn)行時(shí)間有什么關(guān)系呢? 核心線(xiàn)程設(shè)置過(guò)小:核心線(xiàn)程設(shè)置過(guò)小則沒(méi)有達(dá)到并行的效果 線(xiàn)程池公用,別的業(yè)務(wù)的任務(wù)執(zhí)行時(shí)間太長(zhǎng),占用了核心線(xiàn)程,另一個(gè)業(yè)務(wù)的任務(wù)到達(dá)就直接進(jìn)入了等待隊(duì)列 任務(wù)太多,以至于占滿(mǎn)了線(xiàn)程池,大量任務(wù)在隊(duì)列中等待 在排查的時(shí)候,只要找到了問(wèn)題出現(xiàn)的原因,那么解決方式也就清楚了,無(wú)非就是調(diào)整線(xiàn)程池參數(shù),按照業(yè)務(wù)拆分線(xiàn)程池等等。 鎖設(shè)計(jì)不合理 鎖設(shè)計(jì)不合理一般有兩種:鎖類(lèi)型使用不合理 or 鎖過(guò)粗。 鎖類(lèi)型使用不合理的典型場(chǎng)景就是讀寫(xiě)鎖。也就是說(shuō),讀是可以共享的,但是讀的時(shí)候不能對(duì)共享變量寫(xiě);而在寫(xiě)的時(shí)候,讀寫(xiě)都不能進(jìn)行。在可以加讀寫(xiě)鎖的時(shí)候,如果我們加成了互斥鎖,那么在讀遠(yuǎn)遠(yuǎn)多于寫(xiě)的場(chǎng)景下,效率會(huì)極大降低。 鎖過(guò)粗則是另一種常見(jiàn)的鎖設(shè)計(jì)不合理的情況,如果我們把鎖包裹的范圍過(guò)大,則加鎖時(shí)間會(huì)過(guò)長(zhǎng),例如: public synchronized void doSome () 這塊邏輯一共處理了三部分,計(jì)算、上傳結(jié)果、發(fā)送消息。顯然上傳結(jié)果和發(fā)送消息是完全可以不加鎖的,因?yàn)檫@個(gè)跟共享變量根本不沾邊。因此完全可以改成: public void doSome () null ;synchronized (this ) {機(jī)器問(wèn)題(fullGC,機(jī)器重啟,線(xiàn)程打滿(mǎn)) 造成這個(gè)問(wèn)題的原因非常多,筆者就遇到了定時(shí)任務(wù)過(guò)大引起fullGC,代碼存在線(xiàn)程泄露引起RSS內(nèi)存占用過(guò)高進(jìn)而引起機(jī)器重啟等待諸多原因。需要結(jié)合各種監(jiān)控和具體場(chǎng)景具體分析,進(jìn)而進(jìn)行大事務(wù)拆分、重新規(guī)劃線(xiàn)程池等等工作 萬(wàn)金油解決方式 萬(wàn)金油這個(gè)形容詞是從我們單位某位老師那里學(xué)來(lái)的,但是筆者覺(jué)得非常貼切。這些萬(wàn)金油解決方式往往能解決大部分的接口緩慢的問(wèn)題,而且也往往是我們解決接口效率問(wèn)題的最終解決方案。當(dāng)我們實(shí)在是沒(méi)有辦法排查出問(wèn)題,或者實(shí)在是沒(méi)有優(yōu)化空間的時(shí)候,可以嘗試這種萬(wàn)金油的方式。 緩存是一種空間換取時(shí)間的解決方案,是在高性能存儲(chǔ)介質(zhì)上(例如:內(nèi)存、SSD硬盤(pán)等)存儲(chǔ)一份數(shù)據(jù)備份。當(dāng)有請(qǐng)求打到服務(wù)器的時(shí)候,優(yōu)先從緩存中讀取數(shù)據(jù)。如果讀取不到,則再?gòu)挠脖P(pán)或通過(guò)網(wǎng)絡(luò)獲取數(shù)據(jù)。由于內(nèi)存或SSD相比硬盤(pán)或網(wǎng)絡(luò)IO的效率高很多,則接口響應(yīng)速度會(huì)變快非常多。緩存適合于應(yīng)用在數(shù)據(jù)讀遠(yuǎn)遠(yuǎn)大于數(shù)據(jù)寫(xiě),且數(shù)據(jù)變化不頻繁的場(chǎng)景中。從技術(shù)選型上看,有這些: 緩存中間件:redis、tair或memcached 當(dāng)然,memcached現(xiàn)在用的很少了,因?yàn)橄啾扔?code style="font-size: 14px;word-wrap: break-word;margin: 0 2px;background-color: rgba(27,31,35,.05);font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;word-break: break-all;color: #3594F7;background: RGBA(59, 170, 250, .1);padding: 0 2px;border-radius: 2px;height: 21px;line-height: 22px;">redis他不占優(yōu)勢(shì)。tair則是阿里開(kāi)發(fā)的一個(gè)分布式緩存中間件,他的優(yōu)勢(shì)是理論上可以在不停服的情況下,動(dòng)態(tài)擴(kuò)展存儲(chǔ)容量,適用于大數(shù)據(jù)量緩存存儲(chǔ)。相比于單機(jī)redis緩存當(dāng)然有優(yōu)勢(shì),而他與可擴(kuò)展Redis集群的對(duì)比則需要進(jìn)一步調(diào)研。 進(jìn)一步的,當(dāng)前緩存的模型一般都是key-value模型。如何設(shè)計(jì)key以提高緩存的命中率是個(gè)大學(xué)問(wèn),好的key設(shè)計(jì)和壞的key設(shè)計(jì)所提升的性能差別非常大。而且,key設(shè)計(jì)是沒(méi)有一定之規(guī)的,需要結(jié)合具體的業(yè)務(wù)場(chǎng)景去分析。各個(gè)大公司分享出來(lái)的相關(guān)文章,緩存設(shè)計(jì)基本上是最大篇幅。 這種方式往往是業(yè)務(wù)上的解決方式,在訂單或者付款系統(tǒng)中應(yīng)用的比較多。舉個(gè)例子:當(dāng)我們付款的時(shí)候,需要調(diào)用一個(gè)專(zhuān)門(mén)的付款系統(tǒng)接口,該系統(tǒng)經(jīng)過(guò)一系列驗(yàn)證、存儲(chǔ)工作后還要調(diào)用銀行接口以執(zhí)行付款。由于付款這個(gè)動(dòng)作要求十分嚴(yán)謹(jǐn),銀行側(cè)接口執(zhí)行可能比較緩慢,進(jìn)而拖累整個(gè)付款接口性能。這個(gè)時(shí)候我們就可以采用fast success的方式:當(dāng)必要的校驗(yàn)和存儲(chǔ)完成后,立即返回success,同時(shí)告訴調(diào)用方一個(gè)中間態(tài)“付款中”。而后調(diào)用銀行接口,當(dāng)獲得支付結(jié)果后再調(diào)用上游系統(tǒng)的回調(diào)接口返回付款的最終結(jié)果“成果”or“失敗”。這樣就可以異步執(zhí)行付款過(guò)程,提升付款接口效率。當(dāng)然,為了防止多業(yè)務(wù)方接入的時(shí)候回調(diào)接口不統(tǒng)一,可以把結(jié)果拋進(jìn)kafka,讓調(diào)用方監(jiān)聽(tīng)自己的結(jié)果。 結(jié)語(yǔ) 本文是筆者對(duì)工作中遇到的性能優(yōu)化問(wèn)題的一個(gè)簡(jiǎn)單的總結(jié),可能有不完備的地方,歡迎大家討論交流。 
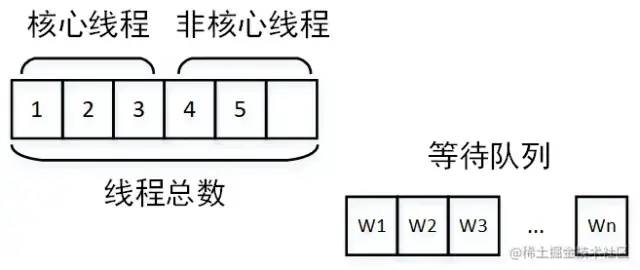 創(chuàng)建非核心線(xiàn)程運(yùn)行
創(chuàng)建非核心線(xiàn)程運(yùn)行