
2021年了,你還在手寫SQL嗎?

??憶往昔歲月
“你還記得第一份實(shí)習(xí),是做什么嗎?”
我的第一份算法實(shí)習(xí)工作,是處理數(shù)據(jù)。準(zhǔn)確地說,是每天手敲30句+SQL,從對話數(shù)據(jù)庫中分析用戶高頻問題、接通率等信息。
手寫SQL是重復(fù)性很強(qiáng)的工作,一不小心容易出錯(cuò),最初的兩個(gè)月每天為此忙得焦頭爛額。
剛剛?cè)腴TNLP的我天真地想著,“要是模型可以自動生成SQL該多好呀”!
碩士期間,有幸在實(shí)驗(yàn)室從事了半年多Text2SQL的科研工作。2021年,我很高興地看到Text2SQL技術(shù),即通過算法將人的自然語言轉(zhuǎn)換為數(shù)據(jù)庫查詢語言SQL,在部分場景中落地應(yīng)用已經(jīng)成為了現(xiàn)實(shí)。
??談?wù)勛詣訉慡QL的背景
Text2SQL起源于上世紀(jì)90年代,是自然語言處理語義解析領(lǐng)域的子任務(wù),核心目標(biāo)是打破人與結(jié)構(gòu)化數(shù)據(jù)之間的壁壘,讓普通用戶可以通過自然語言描述完成復(fù)雜數(shù)據(jù)庫的查詢工作。
例如我有一張“歌手”相關(guān)的表格,歌迷和狗仔隊(duì)們 想知道:
想知道:
Q:“周杰倫和林俊杰最近的演唱會是什么時(shí)候?”
Text2SQL模型自動將問題轉(zhuǎn)換為SQL語言:
A:“SELECT 近期演唱會 FROM singer WHERE 姓名 = 周杰倫 OR 姓名 = 林俊杰”
再返回查詢結(jié)果:“北京-01.08”和“上海-04.28”
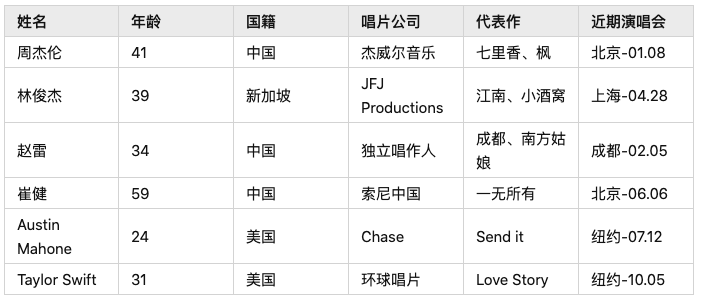
簡單的說,以前想從數(shù)據(jù)庫里拿數(shù)據(jù)或者分析內(nèi)容,用戶要純手工實(shí)現(xiàn)。有了Text2SQL,相當(dāng)于我雇了一個(gè)不花錢不會累的員工(ai模型),只要發(fā)布命令(Text),它就會幫我寫好SQL。

??聊聊技術(shù)實(shí)現(xiàn)
明白了背景,我們來聊聊技術(shù)實(shí)現(xiàn)問題。和分類、匹配等很多NLP任務(wù)類似,Text2SQL也經(jīng)歷了從早期規(guī)則匹配,到現(xiàn)在借助深度學(xué)習(xí)技術(shù)的發(fā)展歷程,濃縮了一代又一代科學(xué)家們的心血。
具體實(shí)現(xiàn)方式有很多,為了節(jié)省時(shí)間,我?guī)痛蠹页槌隽艘恍┐硇缘姆椒ā?br>
模版與規(guī)則匹配
早期的SQL生成方法主要通過基于統(tǒng)計(jì)的模版與規(guī)則匹配方式。
SQL查詢是一種有很強(qiáng)范式的編程語言,典型特征是可以拆分為“SELECT”和“WHERE”兩個(gè)片段。再細(xì)分一下,幾乎90%的SQL語句都可以抽象成如下的模版片段:

AGG表示聚合函數(shù),COLUMN表示需要查詢的目標(biāo)列,WOP表示多個(gè)條件之間的關(guān)聯(lián)規(guī)則“與/或”,三元組 [COLUMN, OP, VALUE] 構(gòu)成了查詢條件,分別代表?xiàng)l件列、條件操作符、從問題中抽取出的文本片段。*表示目標(biāo)列和查詢條件不止一個(gè)!
有了SQL模版,可以先通過統(tǒng)計(jì)方法從語料中挖掘出一些高頻實(shí)體,如人名、地名等,再根據(jù)規(guī)則填充到模版相應(yīng)片段即可。來看一個(gè)具體??:
Q:價(jià)格低于20W的汽車有哪些品牌?
先將問題分詞,方便后續(xù)處理:“價(jià)格 / 低于 / 20W / 的 / 汽車 / 有 / 哪些 / 品牌 ?”
通過預(yù)定義規(guī)則,很快可以識別 “低于”代表“<”操作符;“低于20W”代表“< 20W”;通過簡單數(shù)據(jù)預(yù)處理,還原出條件片段“< 20000”。
通過詞性分析和語料統(tǒng)計(jì),識別出“價(jià)格”,“20W”,“汽車”是有實(shí)際意義的實(shí)體。最終通過類似的模版:“$[低于/高于]$的$有哪些?”還原出真實(shí)SQL:
A:SELECT 品牌 FROM 汽車 WHERE 價(jià)格 < 20000
這里的條件三元組是 [“價(jià)格”, “<”, “20000”],目標(biāo)列為“品牌”,聚合函數(shù)為空。
當(dāng)然通過規(guī)則+模版的方式難以窮盡所有自然語言表達(dá),只能處理這種簡單的例子。深度學(xué)習(xí)技術(shù)的出現(xiàn),讓鹽究員們看到了Text2SQL大放光彩的曙光。
端到端多任務(wù)架構(gòu)
為了充分利用神經(jīng)網(wǎng)絡(luò)的特征抽取能力和SQL的語法特點(diǎn),共享編碼器+多任務(wù)解碼的Seq2Seq架構(gòu)是一種有效的解決方法。
共享編碼器一般是用詞向量或預(yù)訓(xùn)練語言模型,對query、table和column進(jìn)行聯(lián)合編碼,捕捉其中隱含的鏈接關(guān)系。其中后兩項(xiàng)(表名和列名)統(tǒng)稱為數(shù)據(jù)庫模式。例如使用BERT等語言模型時(shí),習(xí)慣將輸入拼接為 “[CLS] query [SEP] table [SEP] column1 [SEP] column2 [SEP] .... [SEP]”這樣的長序列,經(jīng)過多層Transformer編碼,不同table和column對于問題query會有不同權(quán)重的相關(guān)性。
解碼器根據(jù)SQL語法特點(diǎn),設(shè)計(jì)多個(gè)不同的子網(wǎng)絡(luò)。例如,針對上一小節(jié)的SQL模版,可以設(shè)計(jì)6個(gè)子任務(wù)分別預(yù)測查詢目標(biāo)列、目標(biāo)列的聚合函數(shù)等SQL片段,最終拼接出完整SQL。
多任務(wù)架構(gòu)的優(yōu)點(diǎn)在于針對不同SQL片段,可以設(shè)計(jì)有效的損失函數(shù);同時(shí)在訓(xùn)練過程中子任務(wù)的準(zhǔn)確率可以實(shí)時(shí)監(jiān)控,便于落地。對此方法感興趣的讀者,可以閱讀國防科大的論文M-SQL[1],它在天池NL2SQL[2]中文公開賽上獲得了第一名。
端到端抽象語法樹解碼
這種方法的編碼器與前一節(jié)類似,但是在解碼時(shí)將SQL視作一棵抽象語法樹,樹中各個(gè)結(jié)點(diǎn)是SQL的關(guān)鍵字(SELECT、WHERE、AND...)或者表名和列名的候選值。生成SQL的過程相當(dāng)于從樹的根結(jié)點(diǎn)對語法樹做一次深度優(yōu)先搜索。
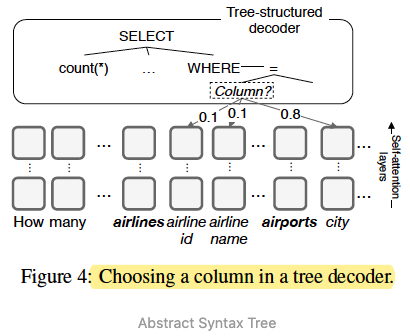
以節(jié)點(diǎn)“SELECT”為例,“SELECT”節(jié)點(diǎn)往下可能包含3個(gè)葉子節(jié)點(diǎn):“Column”、“AGG”、“Distinct”,分別代表“選取某一列”、“增加聚合操作”、“對列去重”。從“SELECT”節(jié)點(diǎn)向下搜索相當(dāng)于是3分類任務(wù),根據(jù)真實(shí)路徑和搜索路徑依次計(jì)算各個(gè)節(jié)點(diǎn)的交叉熵并求和,作為總損失。
抽象語法樹的思想避免了設(shè)計(jì)各種各樣的子網(wǎng)絡(luò),對于涉及跨表查詢、嵌套查詢的復(fù)雜數(shù)據(jù)集有很好的效果。在領(lǐng)域內(nèi)權(quán)威比賽Spider上取得優(yōu)異成績的頂會模型IRNet[3]、Rat-SQL[4],都充分借鑒了語法樹思想。
其實(shí)語法樹不僅僅可以生成SQL,還可以生成各種各樣好玩的目標(biāo)序列,例如Python/Java等編程語言,音樂音符等等。CMU的這篇論文[5]從文本生成了Python。
??Text2SQL資源大禮包
筆者在Text2SQL領(lǐng)域踩坑半年有余,為避免重復(fù)性勞動,我將收集到的資料打包成了一個(gè)開源項(xiàng)目,主要包含Text2SQL語義解析數(shù)據(jù)集、解決方案、參考論文等。歡迎小伙伴們前來??
項(xiàng)目還在持續(xù)更新中。對于該領(lǐng)域的部分頂會論文,我加入了自己的解讀(BRIDGE:萬萬沒想到,BERT學(xué)會寫SQL了)。
??落地商用的真相
雖然近年該方向在ACL/EMNLP等頂會上出了很多paper,幾個(gè)知名比賽各家研究院刷的不亦樂乎,不過在我看來Text2SQL實(shí)際商用僅處于初級階段。
究其原因,是準(zhǔn)確率還不夠高,無法完全滿足用戶預(yù)期。自然語言有很大的熵值,即便同一句話都可以有多種不同理解。同時(shí)實(shí)際場景中,用戶查詢內(nèi)容往往涉及多張表格,查詢條件可能非常復(fù)雜。語義歧義性、跨表查詢、嵌套查詢等難點(diǎn)給模型生成準(zhǔn)確無誤的SQL帶來很大挑戰(zhàn)。

所以當(dāng)前階段,大家看到了Text2SQL應(yīng)用的曙光,但是還未開始大規(guī)模推廣;更多時(shí)候是結(jié)合人工干預(yù)與糾錯(cuò),作為對話系統(tǒng)的一個(gè)子模塊。
回到標(biāo)題上來,2021年了,你還在手寫SQL嗎?相信看完本文讀者們心里已經(jīng)有了答案。對于WikiSQL、TableQA等簡單的單表數(shù)據(jù)集,模型已經(jīng)完全可以cover。但是在現(xiàn)實(shí)復(fù)雜場景中,還有很長的研究道路要走。
Text2SQL依然是一個(gè)很有研究意義的課題,是自然語言處理跨出文本走向多模態(tài)的典型代表。相信未來還會有Text2Music、Text2Moive等新技術(shù)誕生,更好地服務(wù)于人類社會。

推 薦 閱 讀
算法工程師如何順利畢業(yè)? 2021年,我終于決定入門GCN 動手學(xué)正則表達(dá)式(含Python代碼實(shí)踐) 在家也能輕松訪問公司內(nèi)網(wǎng)的秘密|穿透! Github13K!相似搜索百寶箱,文本匹配入門必備!
參 考 資 料
[1] M-SQL:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9146825
[2] NL2SQL中文挑戰(zhàn)賽:https://tianchi.aliyun.com/competition/entrance/231716/rankingList
[3] Jiaqi Guo, Zecheng Zhan, et al. Towards complex text-to-SQL in cross-domain database with intermediate representation[C]
[4] Bailin Wang, Richard Shin, et al. RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers[C]
[5] Pengcheng Yin, Graham Neubig. A Syntactic Neural Model for General-Purpose Code Generation[C]
原創(chuàng)不易,有收獲的話請幫忙點(diǎn)擊分享、點(diǎn)贊、在看??