
第二彈!爬蟲(chóng)批量下載高清大圖
前言
在上一篇寫文沒(méi)高質(zhì)量配圖?教你python爬蟲(chóng)繞過(guò)限制一鍵搜索下載圖蟲(chóng)創(chuàng)意圖片!!中,我們?cè)谖吹卿浀那闆r下實(shí)現(xiàn)了圖蟲(chóng)創(chuàng)意無(wú)水印高清小圖的批量下載。雖然小圖能夠在一些移動(dòng)端可能展示的還行,但是放到pc端展示圖片太小效果真的是很一般!建議閱讀本文查看上一篇文章,在具體實(shí)現(xiàn)不做太多介紹,只講個(gè)分析思路。
當(dāng)然,本文可能技術(shù)要求不是特別高,但可以當(dāng)作一個(gè)下圖工具使用。也歡迎討論交流!
環(huán)境:python3+pycharm+requests+re+BeatifulSoup+json

這個(gè)確實(shí)也屬實(shí)有一些勉強(qiáng),不少童鞋私信問(wèn)我有木有下載大圖的源碼,我說(shuō)可能會(huì)有,現(xiàn)在分享給大家。
當(dāng)然對(duì)于一個(gè)圖片平臺(tái)來(lái)說(shuō),高質(zhì)量圖片下載可能是其核心業(yè)務(wù),并且我看了一下,那些高質(zhì)量大圖下載起來(lái)很貴!所以筆者并沒(méi)有嘗試付費(fèi)下載然后查看大圖的地址,因?yàn)檫@個(gè)可以猜想成功率很低,并且成本比較高,退而求其次,筆者采取以下幾種方法。
對(duì)圖蟲(chóng)平臺(tái)初步分析之后,得到以下觀點(diǎn):
原版高質(zhì)量無(wú)水印圖片下載太貴,由于沒(méi)付費(fèi)下載沒(méi)有找到高質(zhì)量圖的高清無(wú)水印原圖真實(shí)地址。沒(méi)有辦法(能力) 下載原版高清無(wú)水印。并且筆者也能猜測(cè)這個(gè)是一個(gè)網(wǎng)站的核心業(yè)務(wù)肯定也會(huì)層層設(shè)套。不會(huì)輕易獲得,所以并沒(méi)有對(duì)付費(fèi)高清高質(zhì)量無(wú)水印圖片窮追不舍。
但是高質(zhì)量展示圖在預(yù)覽時(shí)候的是可以查看帶有水印的高清圖的(帶著圖蟲(chóng)創(chuàng)意水印)。
網(wǎng)站有一些免費(fèi)的高清大圖圖片可以獲取到。雖然這個(gè)
不是精選圖,但是質(zhì)量也還可以!
下載免費(fèi)共享大圖
在圖蟲(chóng)創(chuàng)意有個(gè)板塊的圖片是免費(fèi)開(kāi)放的。在共享圖片專欄。的圖片可以搜索下載。
https://stock.tuchong.com/topic?topicId=37 圖蟲(chóng)創(chuàng)意url地址

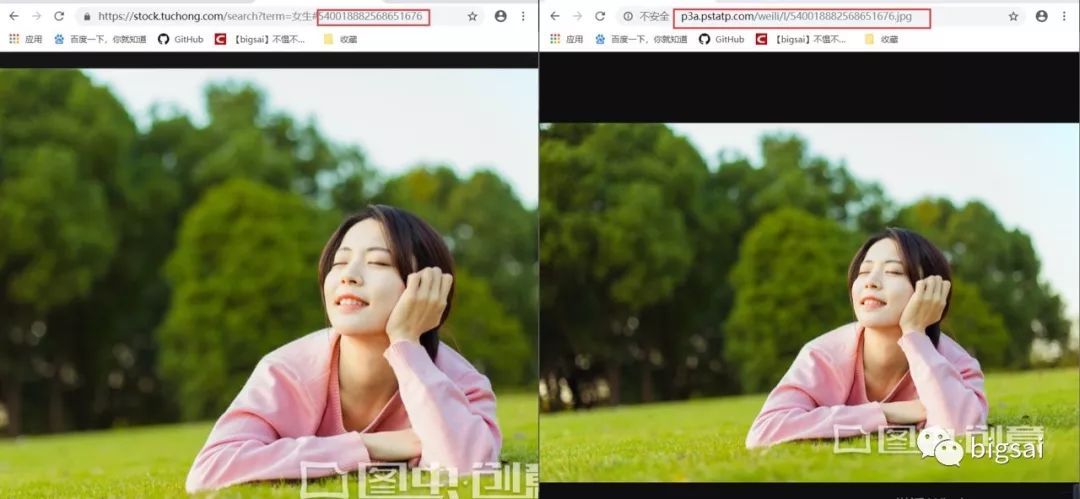
找到一張圖片點(diǎn)進(jìn)去,檢查地址你可以直接訪問(wèn)得到。而有相關(guān)因素的就是一個(gè)圖片服務(wù)器域名+圖片id組成的圖片url地址。也就是我們要批量找到這些圖片的id。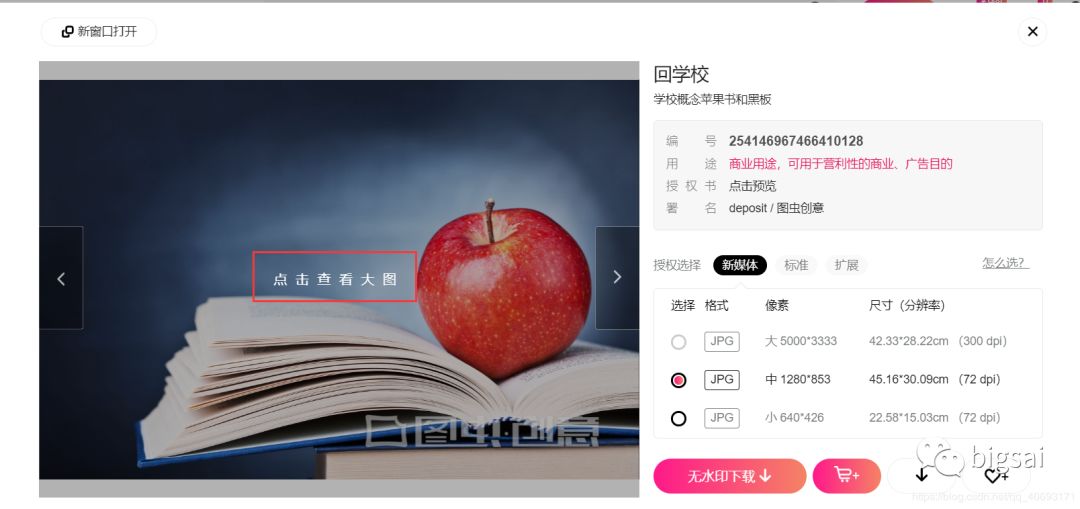
在搜索界面查看源碼,發(fā)現(xiàn)這個(gè)和前面的分析如出一轍,它的圖片id藏在js里面。我們只需通過(guò)正則解析。拿到id然后拼湊url即可完成所有圖片地址,這個(gè)解析方式和上文基本完全一致,只不過(guò)是瀏覽器的URL和js的位置有相對(duì)的變化只需小量修改,然后直接爬蟲(chóng)下載保存即可!而這個(gè)搜索html的url就是https://stock.tuchong.com/free/search/?term=+搜索內(nèi)容。這個(gè)下載內(nèi)容的實(shí)現(xiàn)在上一篇已經(jīng)分析過(guò)。請(qǐng)自行查看或看下文代碼!這樣

下載帶水印的精選圖
好的圖片都在優(yōu)選圖片專欄。然而這部分圖片我們可以免費(fèi)獲取帶水印的圖片。
在登錄賬號(hào)之后點(diǎn)開(kāi)的圖片預(yù)覽,當(dāng)你點(diǎn)開(kāi)預(yù)覽的時(shí)候是可以看得到圖片的。每張圖片對(duì)應(yīng)一個(gè)唯一ID,這個(gè)地址可以獲得但是比較麻煩。我們嘗試能不能獲得一個(gè)簡(jiǎn)單通用的url地址呢?
經(jīng)過(guò)嘗試發(fā)現(xiàn)這個(gè)圖片的url可以在我們上面的免費(fèi)高清大圖url地址共用!也就是我們可以得到這個(gè)ID通過(guò)上個(gè)url來(lái)批量獲取下載圖片!下載圖片的方法一致不需要重復(fù)造輪子。而id的獲取方法我們?cè)谙螺d高清小圖就已經(jīng)詳細(xì)介紹過(guò)了也是一樣的。那么分析就已經(jīng)成功了,代碼將在后面給出,這樣我們可以下載帶水印的高清大圖了!
##js的解析規(guī)則:
#----
js=soup.select('script') js=js[4]
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js內(nèi)容
#-------
代碼與總結(jié)
import requests
from urllib import parse
from bs4 import BeautifulSoup
import re
import json
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Cookie': 'wluuid=66; ',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-encoding': 'gzip, deflate, br',
'Accept-language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'connection': 'keep-alive'
, 'Host': 'stock.tuchong.com',
'Upgrade-Insecure-Requests': '1'
}
def mkdir(path):
import os# 引入模塊
path = path.strip()# 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符號(hào)
isExists = os.path.exists(path) # 判斷路徑是否存在 # 存在 True # 不存在 False
if not isExists: # 判斷結(jié)果
os.makedirs(path)# 如果不存在則創(chuàng)建目錄 # 創(chuàng)建目錄操作函數(shù)
return True#print (path + ' 創(chuàng)建成功')
else:
# 如果目錄存在則不創(chuàng)建,并提示目錄已存在
#print(path + ' 目錄已存在')
return False
def downloadimage(imageid,imgname):##下載大圖和帶水印的高質(zhì)量大圖
url = 'https://weiliicimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
url2 = 'https://icweiliimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
b=False
r = requests.get(url)
print(r.status_code)
if(r.status_code!=200):
r=requests.get(url2)
with open(imgname+'.jpg', 'wb') as f:
f.write(r.content)
print(imgname+" 下載成功")
def getText(text,free):
texturl = parse.quote(text)
url="https://stock.tuchong.com/"+free+"search?term="+texturl+"&use=0"
print(url)
req=requests.get(url,headers=header)
soup=BeautifulSoup(req.text,'lxml')
js=soup.select('script')
path=''
if not free.__eq__(''):
js=js[1]
path='無(wú)水印/'
else:
js=js[4]
path='圖蟲(chóng)創(chuàng)意/'
print(js)
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js內(nèi)容
print(va)
va = va.replace('{', '{').replace('}', '},,')
print(va)
va = va.split(',,,')
print(va)
index = 1
for data in va:
try:
dict = json.loads(data)
print(dict)
imgname='img2/'+path+text+'/'+dict['title']+str(index)
index+=1
mkdir('img2/'+path+text)
imgid=dict['imageId']
downloadimage(imgid,imgname)
except Exception as e:
print(e)
if __name__ == '__main__':
num=input("高質(zhì)量大圖帶水印輸入1,普通不帶水印輸入2:")
num=int(num)
free=''
if num==2:
free='free/'
text = input('輸入關(guān)鍵詞:')
getText(text,free)
這樣,整個(gè)流程就完成了,對(duì)于目錄方面,我也對(duì)圖蟲(chóng)有水印的和沒(méi)水印的進(jìn)行了區(qū)分,供大家使用。在使用方面,先輸入1或2(1代表有水印高質(zhì)量圖,2代表共享圖),在輸入關(guān)鍵詞即可批量下載。


-- end --
喜歡就三連呀
點(diǎn)擊"閱讀原文"可跳轉(zhuǎn)至我的博客。
關(guān)注 Stephen,一起學(xué)習(xí),一起成長(zhǎng)。