
【Python】11招對(duì)比Pandas雙列求和
公眾號(hào):尤而小屋
作者:Peter
編輯:Peter
大家好,我是Peter~
本文介紹的是通過(guò)11種方法來(lái)對(duì)比Pandas中DataFrame兩列的求和
direct_add for_iloc iloc_sum iat apply(指定字段) apply(針對(duì)整個(gè)DataFrame) numpy_array iterrows zip assign sum

數(shù)據(jù)模擬
為了效果明顯,模擬了一份5萬(wàn)條的數(shù)據(jù),4個(gè)字段:
import pandas as pd
import numpy as np
data = pd.DataFrame({
"A":np.random.uniform(1,1000,50000),
"B":np.random.uniform(1,1000,50000),
"C":np.random.uniform(1,1000,50000),
"D":np.random.uniform(1,1000,50000)
})
data

11種函數(shù)
下面是通過(guò)11種不同的函數(shù)來(lái)實(shí)現(xiàn)A、C兩列的數(shù)據(jù)相加求和E列
方法1:直接相加
把df的兩列直接相加
In [3]:
def fun1(df):
df["E"] = df["A"] + df["C"]
方法2:for+iloc定位
for語(yǔ)句 + iloc方法的遍歷循環(huán)
In [4]:
def fun2(df):
for i in range(len(df)):
df["E"] = df.iloc[i,0] + df.iloc[i, 2] # iloc[i,0]定位A列的數(shù)據(jù)
方法3:iloc + sum
iloc方法針對(duì)全部行指定列的求和:
0:第一列A 2:第三列C
In [5]:
def fun3(df):
df["E"] = df.iloc[:,[0,2]].sum(axis=1) # axis=1表示在列上操作
方法3:iat定位
for語(yǔ)句 + iat定位,類(lèi)比于for + iloc
In [6]:
def fun4(df):
for i in range(len(df)):
df["E"] = df.iat[i,0] + df.iat[i, 2]
apply函數(shù)(只讀兩列)
apply方法 ,僅僅取出AC兩列
In [7]:
def fun5(df):
df["E"] = df[["A","C"]].apply(lambda x: x["A"] + x["C"], axis=1)
apply函數(shù)(全部df)
針對(duì)前部的DataFrame使用apply方法
In [8]:
def fun6(df):
df["E"] = df.apply(lambda x: x["A"] + x["C"], axis=1)
numpy數(shù)組
使用numpy數(shù)組解決
In [9]:
def fun7(df):
df["E"] = df["A"].values + df["C"].values
iterrows迭代
iterrows()迭代每行的數(shù)據(jù)
In [10]:
def fun8(df):
for _, rows in df.iterrows():
rows["E"] = rows["A"] + rows["C"]
zip函數(shù)
通過(guò)zip函數(shù)現(xiàn)將AC兩列的數(shù)據(jù)進(jìn)行壓縮
In [11]:
def fun9(df):
df["E"] = [i+j for i,j in zip(df["A"], df["C"])]
assign函數(shù)
通過(guò)派生函數(shù)assign生成新的字段E
In [12]:
def fun10(df):
df.assign(E = df["A"] + df["C"])
sum函數(shù)
在指定的A、C兩列上使用sum函數(shù)
In [13]:
def fun11(df):
df["E"] = df[["A","C"]].sum(axis=1)
結(jié)果
調(diào)用11種函數(shù),比較它們的速度:


統(tǒng)計(jì)每種方法下的均值,并整理成相同的us:
| 方法 | 結(jié)果 | 統(tǒng)一(us) |
|---|---|---|
| 直接相加 | 626us | 626 |
| for + iloc | 9.61s | 9610000 |
| iloc + sum | 1.42ms | 1420 |
| iat | 9.2s | 9200000 |
| apply(只取指定列) | 666ms | 666000 |
| apply(全部列) | 697ms | 697000 |
| numpy | 216us | 216 |
| iterrows | 3.29s | 3290000 |
| zip | 17.9ms | 17900 |
| assign | 888us | 888 |
| sum(axis=1) | 1.33ms | 1330 |
result = pd.DataFrame({"methods":["direct_add","for_iloc","iloc_sum","iat","apply_part","apply_all",
"numpy_arry","iterrows","zip","assign","sum"],
"time":[626,9610000,1420,9200000,666000,697000,216,3290000,17900,888,1330]})
result
進(jìn)行降序后的可視化:
result.sort_values("time",ascending=False,inplace=True)
import plotly_express as px
fig = px.bar(result, x="methods", y="time", color="time")
fig.show()
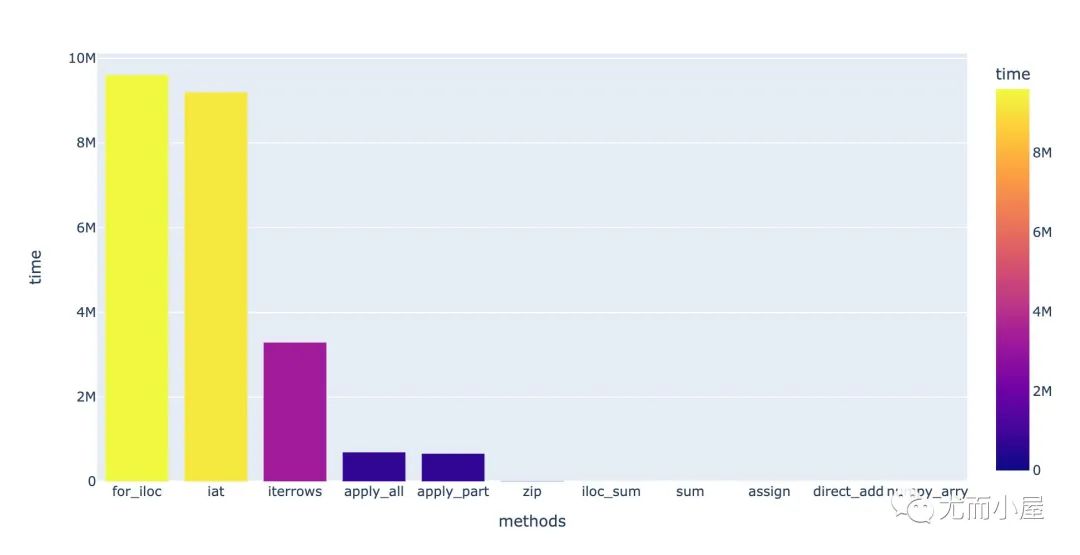
從結(jié)果中能夠看到:
for循環(huán)是最耗時(shí)的,使用numpy數(shù)組最省時(shí)間,相差4萬(wàn)多倍;主要是因?yàn)镹umpy數(shù)組使用的向量化操作 sum函數(shù)(指定軸axis=1)對(duì)效果的提升很明顯
總結(jié):循環(huán)能省則省,盡可能用Pandas或者numpy的內(nèi)置函數(shù)來(lái)解決。
往期精彩回顧
評(píng)論
圖片
表情