LLVM之父Chris Lattner:編譯器的黃金時(shí)代

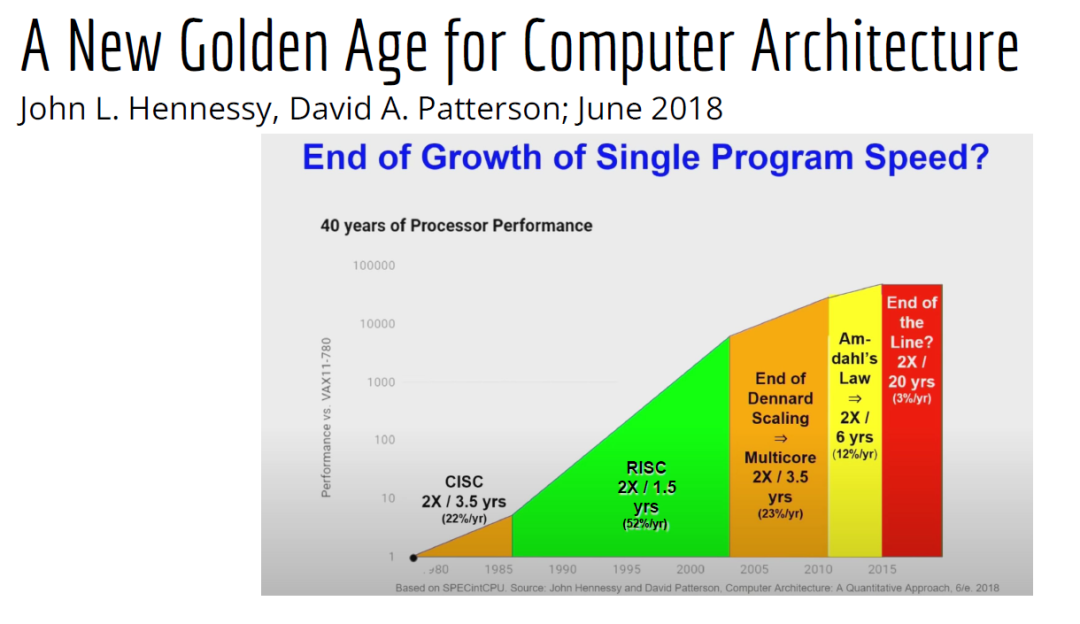
為什么需要下一代編譯器和編程語言
傳統(tǒng)編譯器的設(shè)計(jì)和挑戰(zhàn)

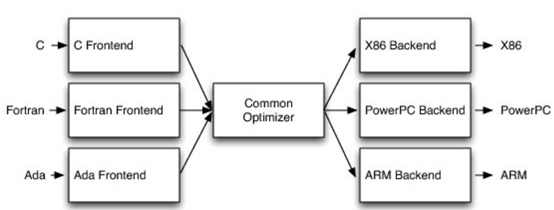
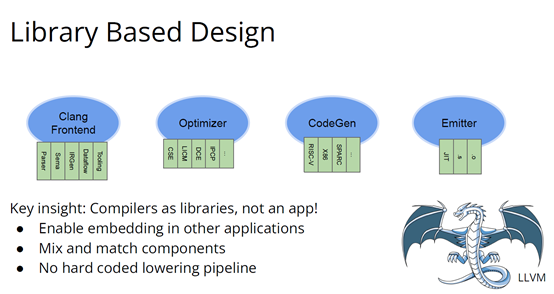
構(gòu)建適用專用領(lǐng)域的架構(gòu)
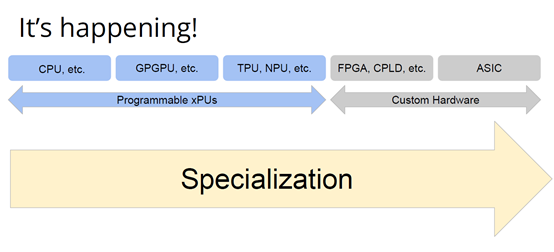
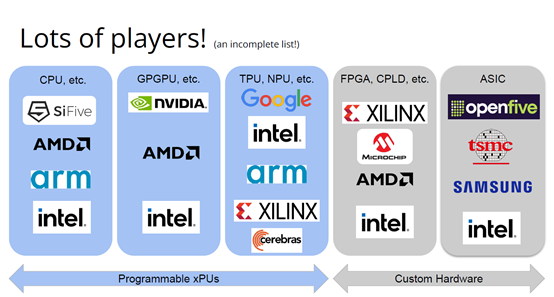


加速器的本質(zhì)和演進(jìn)
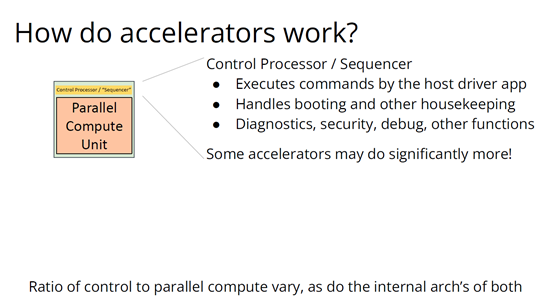

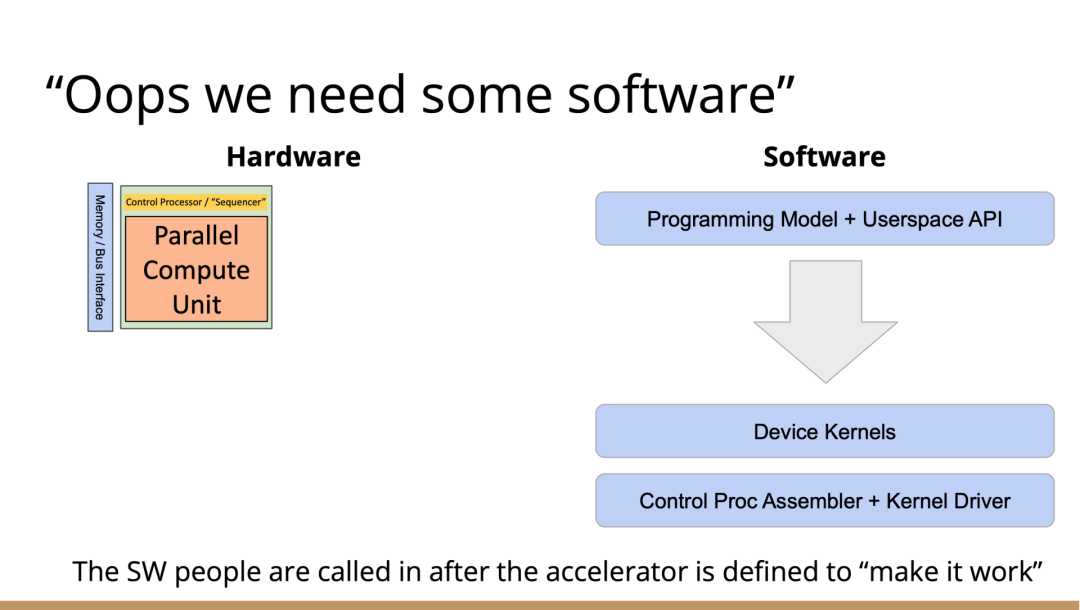
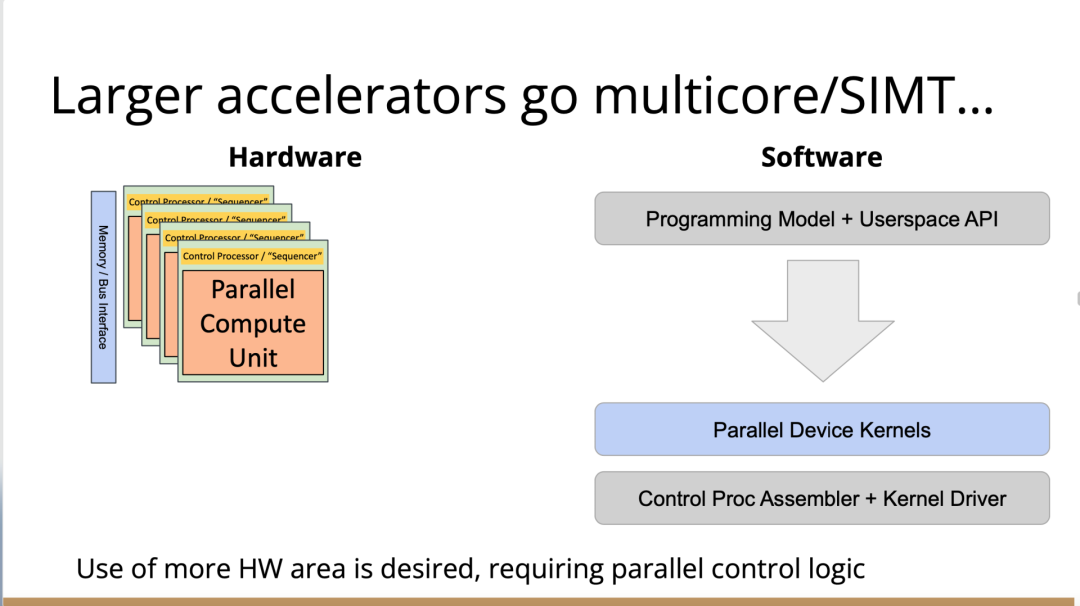
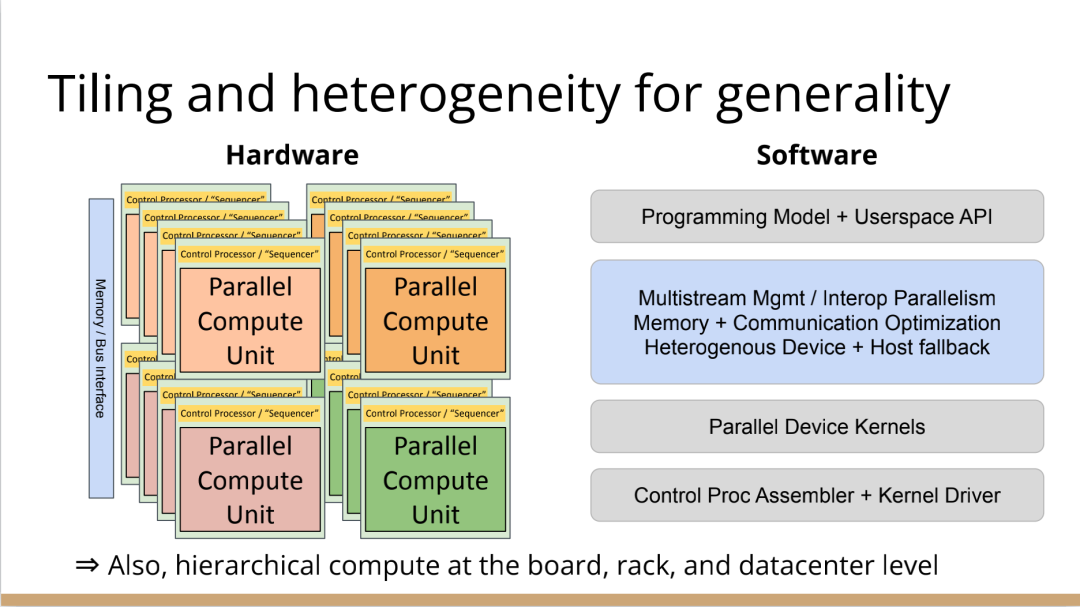
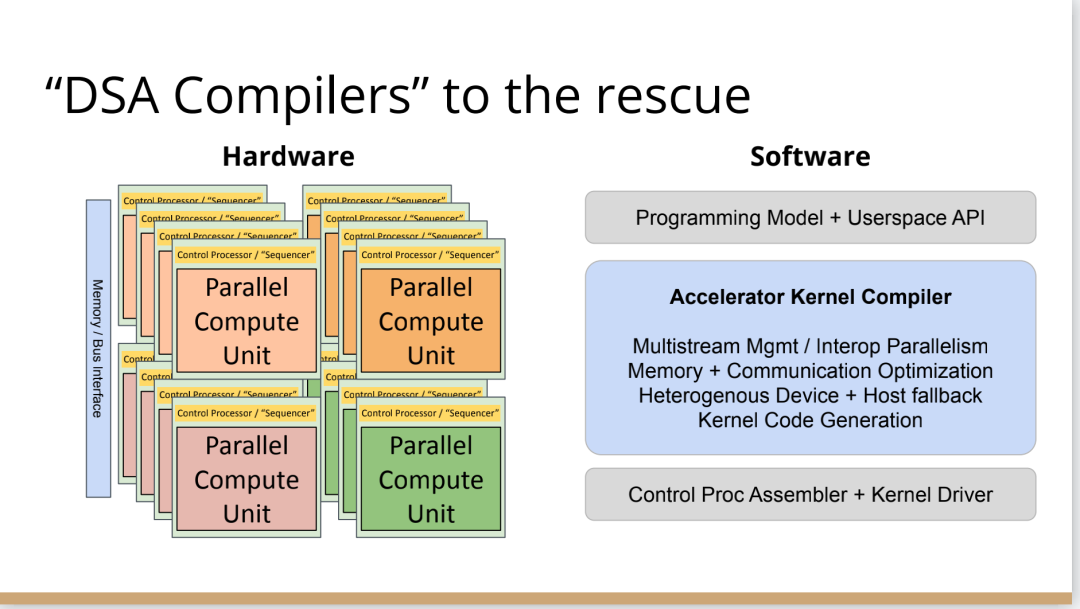
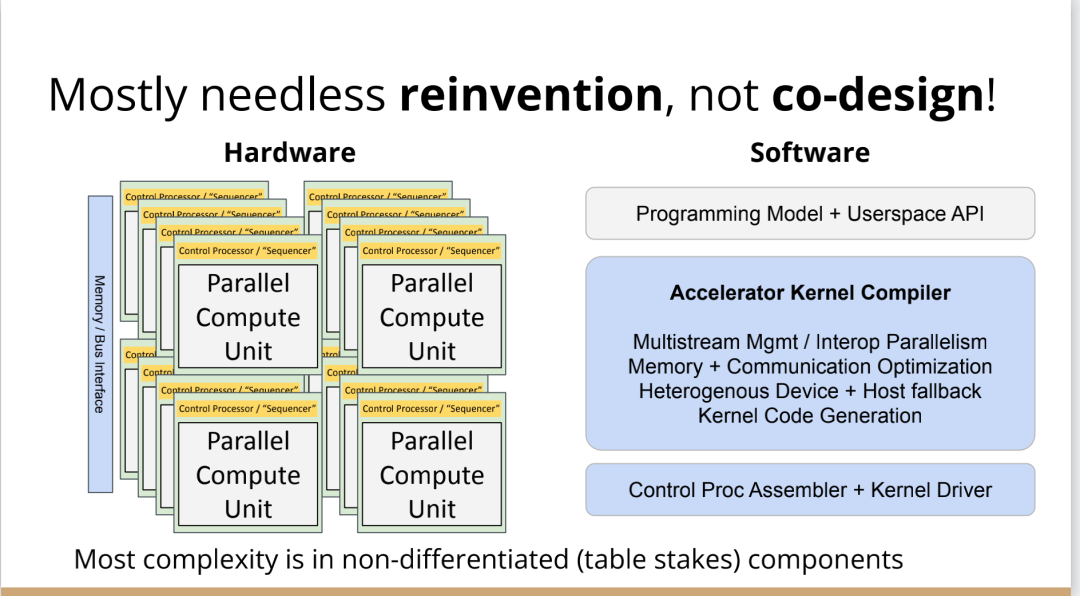





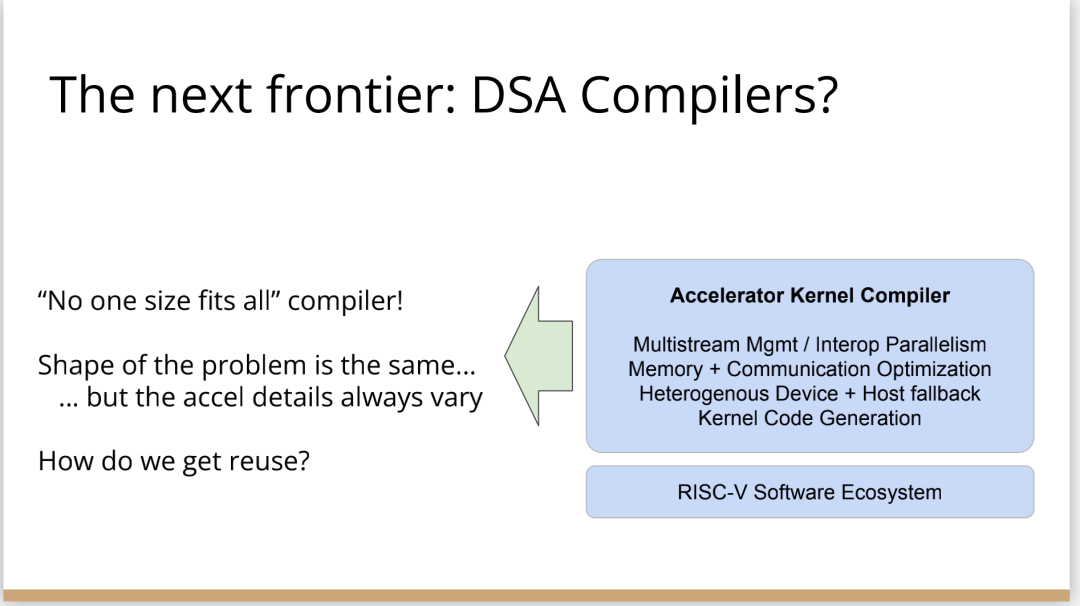

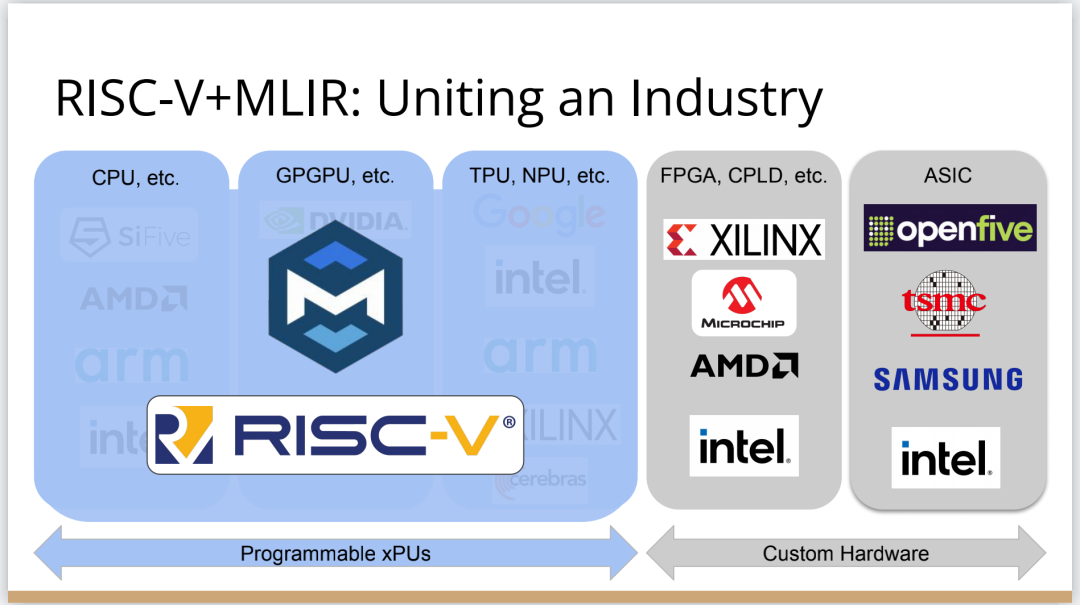
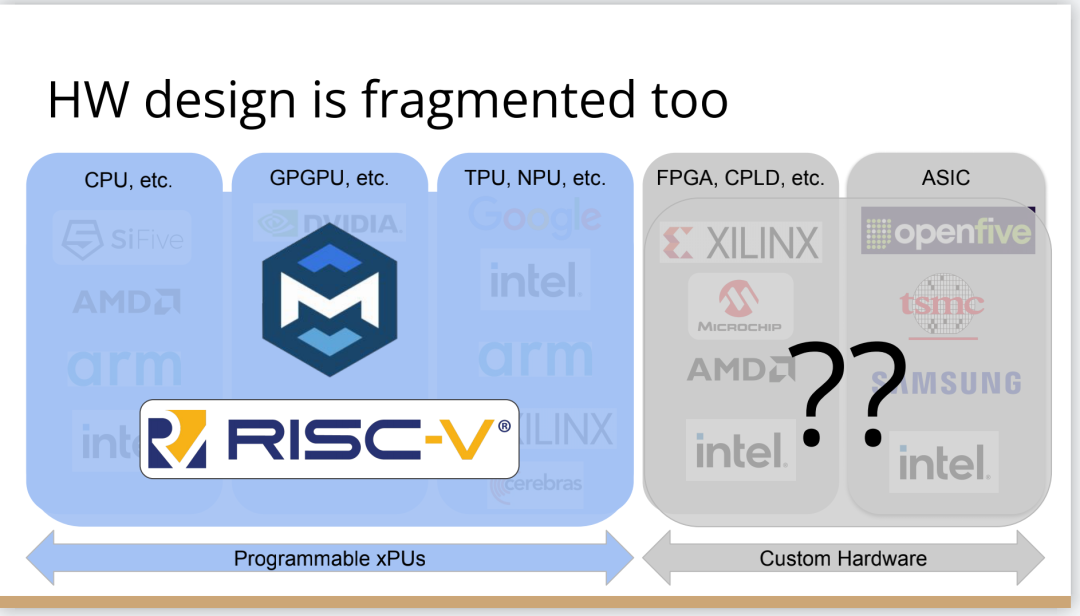
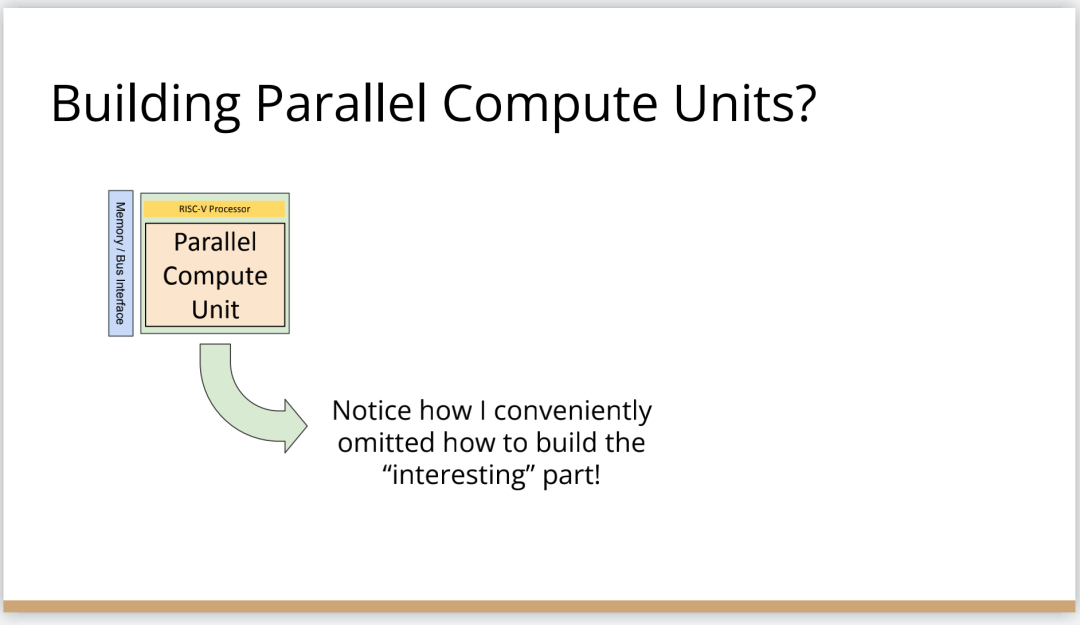
編譯器的創(chuàng)新機(jī)會(huì)





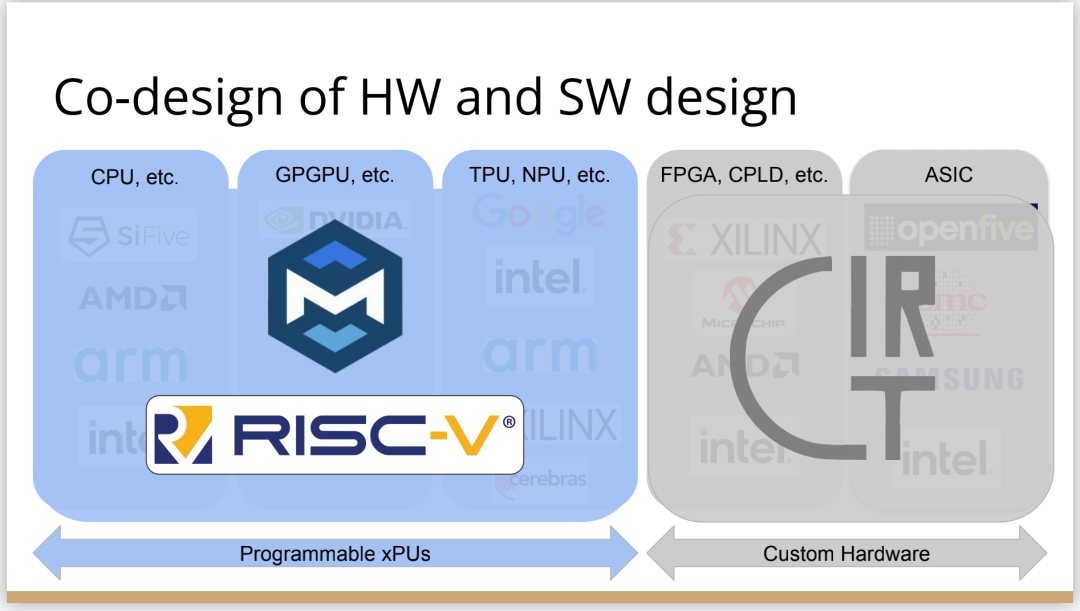
總結(jié)
評(píng)論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP為什么需要下一代編譯器和編程語言
傳統(tǒng)編譯器的設(shè)計(jì)和挑戰(zhàn)
構(gòu)建適用專用領(lǐng)域的架構(gòu)
加速器的本質(zhì)和演進(jìn)
編譯器的創(chuàng)新機(jī)會(huì)
總結(jié)
<b id="afajh"><abbr id="afajh"></abbr></b>