
面試官:如何寫(xiě)出讓 CPU 跑得更快的代碼?


點(diǎn)擊「閱讀原文」查看良許原創(chuàng)精品視頻。
點(diǎn)擊「閱讀原文」查看良許原創(chuàng)精品視頻。
前言
代碼都是由 CPU 跑起來(lái)的,我們代碼寫(xiě)的好與壞就決定了 CPU 的執(zhí)行效率,特別是在編寫(xiě)計(jì)算密集型的程序,更要注重 CPU 的執(zhí)行效率,否則將會(huì)大大影響系統(tǒng)性能。
CPU 內(nèi)部嵌入了 CPU Cache(高速緩存),它的存儲(chǔ)容量很小,但是離 CPU 核心很近,所以緩存的讀寫(xiě)速度是極快的,那么如果 CPU 運(yùn)算時(shí),直接從 CPU Cache 讀取數(shù)據(jù),而不是從內(nèi)存的話(huà),運(yùn)算速度就會(huì)很快。
但是,大多數(shù)人不知道 CPU Cache 的運(yùn)行機(jī)制,以至于不知道如何才能夠?qū)懗瞿軌蚺浜?CPU Cache 工作機(jī)制的代碼,一旦你掌握了它,你寫(xiě)代碼的時(shí)候,就有新的優(yōu)化思路了。
那么,接下來(lái)我們就來(lái)看看,CPU Cache 到底是什么樣的,是如何工作的呢,又該寫(xiě)出讓 CPU 執(zhí)行更快的代碼呢?

正文
CPU Cache 有多快?
你可能會(huì)好奇為什么有了內(nèi)存,還需要 CPU Cache?根據(jù)摩爾定律,CPU 的訪(fǎng)問(wèn)速度每 18 個(gè)月就會(huì)翻倍,相當(dāng)于每年增長(zhǎng) 60% 左右,內(nèi)存的速度當(dāng)然也會(huì)不斷增長(zhǎng),但是增長(zhǎng)的速度遠(yuǎn)小于 CPU,平均每年只增長(zhǎng) 7% 左右。于是,CPU 與內(nèi)存的訪(fǎng)問(wèn)性能的差距不斷拉大。
到現(xiàn)在,一次內(nèi)存訪(fǎng)問(wèn)所需時(shí)間是 200~300 多個(gè)時(shí)鐘周期,這意味著 CPU 和內(nèi)存的訪(fǎng)問(wèn)速度已經(jīng)相差 200~300 多倍了。
為了彌補(bǔ) CPU 與內(nèi)存兩者之間的性能差異,就在 CPU 內(nèi)部引入了 ?CPU Cache,也稱(chēng)高速緩存。
CPU Cache 通常分為大小不等的三級(jí)緩存,分別是 L1 Cache、L2 Cache 和 L3 Cache。
由于 CPU Cache 所使用的材料是 SRAM,價(jià)格比內(nèi)存使用的 DRAM 高出很多,在當(dāng)今每生產(chǎn) 1 MB 大小的 CPU Cache 需要 7 美金的成本,而內(nèi)存只需要 0.015 美金的成本,成本方面相差了 466 倍,所以 CPU Cache 不像內(nèi)存那樣動(dòng)輒以 GB 計(jì)算,它的大小是以 KB 或 MB 來(lái)計(jì)算的。
在 Linux 系統(tǒng)中,我們可以使用下圖的方式來(lái)查看各級(jí) CPU Cache 的大小,比如我這手上這臺(tái)服務(wù)器,離 CPU 核心最近的 L1 Cache 是 32KB,其次是 L2 Cache 是 256KB,最大的 L3 Cache 則是 3MB。

其中,L1 Cache 通常會(huì)分為「數(shù)據(jù)緩存」和「指令緩存」,這意味著數(shù)據(jù)和指令在 L1 Cache 這一層是分開(kāi)緩存的,上圖中的 index0 也就是數(shù)據(jù)緩存,而 index1 則是指令緩存,它兩的大小通常是一樣的。
另外,你也會(huì)注意到,L3 Cache 比 L1 Cache 和 L2 Cache 大很多,這是因?yàn)?L1 Cache 和 L2 Cache 都是每個(gè) CPU 核心獨(dú)有的,而 L3 Cache 是多個(gè) CPU 核心共享的。
程序執(zhí)行時(shí),會(huì)先將內(nèi)存中的數(shù)據(jù)加載到共享的 L3 Cache 中,再加載到每個(gè)核心獨(dú)有的 L2 Cache,最后進(jìn)入到最快的 L1 Cache,之后才會(huì)被 CPU 讀取。它們之間的層級(jí)關(guān)系,如下圖:
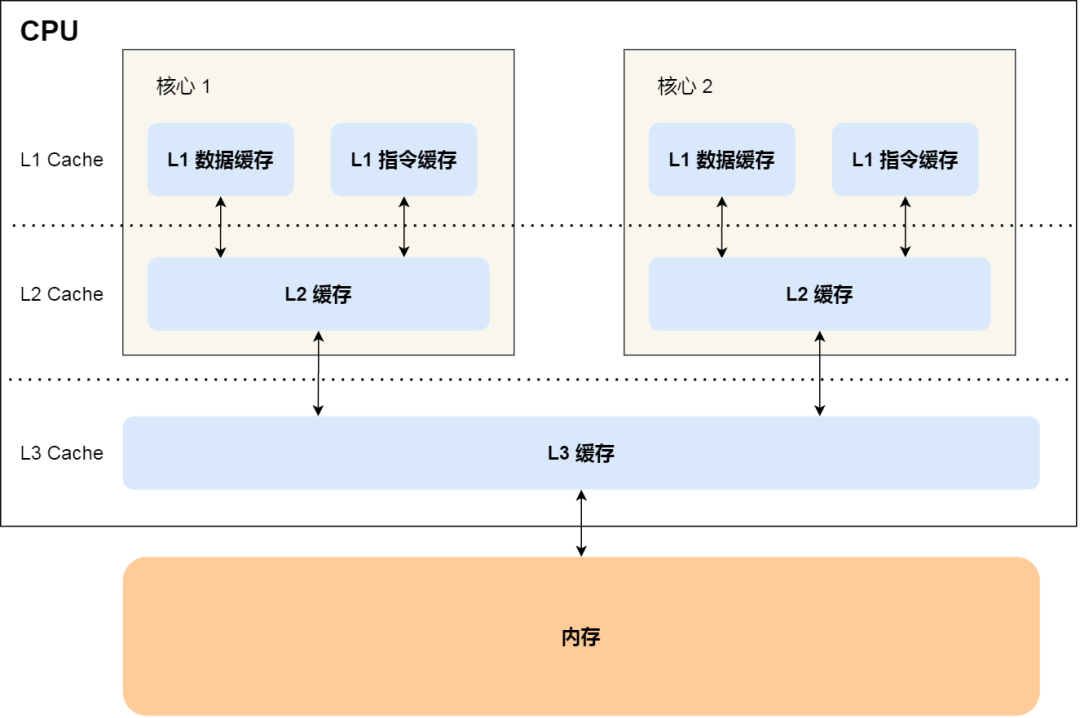
越靠近 CPU 核心的緩存其訪(fǎng)問(wèn)速度越快,CPU 訪(fǎng)問(wèn) L1 Cache 只需要 2~4 個(gè)時(shí)鐘周期,訪(fǎng)問(wèn) L2 Cache 大約 10~20 個(gè)時(shí)鐘周期,訪(fǎng)問(wèn) L3 Cache 大約 20~60 個(gè)時(shí)鐘周期,而訪(fǎng)問(wèn)內(nèi)存速度大概在 200~300 個(gè) 時(shí)鐘周期之間。如下表格:
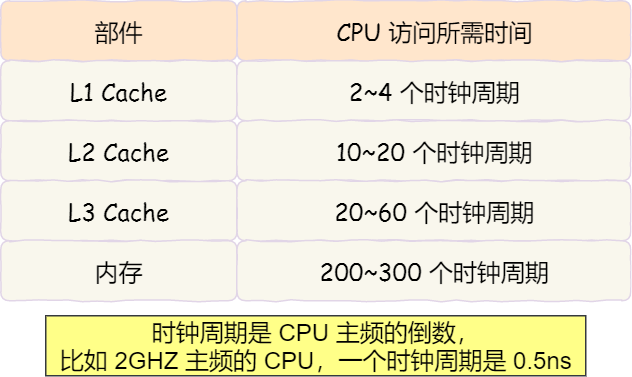
所以,CPU 從 L1 Cache 讀取數(shù)據(jù)的速度,相比從內(nèi)存讀取的速度,會(huì)快 100 多倍。
CPU Cache 的數(shù)據(jù)結(jié)構(gòu)和讀取過(guò)程是什么樣的?
CPU Cache 的數(shù)據(jù)是從內(nèi)存中讀取過(guò)來(lái)的,它是以一小塊一小塊讀取數(shù)據(jù)的,而不是按照單個(gè)數(shù)組元素來(lái)讀取數(shù)據(jù)的,在 CPU Cache 中的,這樣一小塊一小塊的數(shù)據(jù),稱(chēng)為 Cache Line(緩存塊)。
你可以在你的 Linux 系統(tǒng),用下面這種方式來(lái)查看 CPU 的 Cache Line,你可以看我服務(wù)器的 L1 Cache Line 大小是 64 字節(jié),也就意味著 L1 Cache 一次載入數(shù)據(jù)的大小是 64 字節(jié)。

比如,有一個(gè) int array[100] 的數(shù)組,當(dāng)載入 array[0] 時(shí),由于這個(gè)數(shù)組元素的大小在內(nèi)存只占 4 字節(jié),不足 64 字節(jié),CPU 就會(huì)順序加載數(shù)組元素到 array[15],意味著 array[0]~array[15] 數(shù)組元素都會(huì)被緩存在 CPU Cache 中了,因此當(dāng)下次訪(fǎng)問(wèn)這些數(shù)組元素時(shí),會(huì)直接從 CPU Cache 讀取,而不用再?gòu)膬?nèi)存中讀取,大大提高了 CPU 讀取數(shù)據(jù)的性能。
事實(shí)上,CPU 讀取數(shù)據(jù)的時(shí)候,無(wú)論數(shù)據(jù)是否存放到 Cache 中,CPU 都是先訪(fǎng)問(wèn) Cache,只有當(dāng) Cache 中找不到數(shù)據(jù)時(shí),才會(huì)去訪(fǎng)問(wèn)內(nèi)存,并把內(nèi)存中的數(shù)據(jù)讀入到 Cache 中,CPU 再?gòu)?CPU Cache 讀取數(shù)據(jù)。
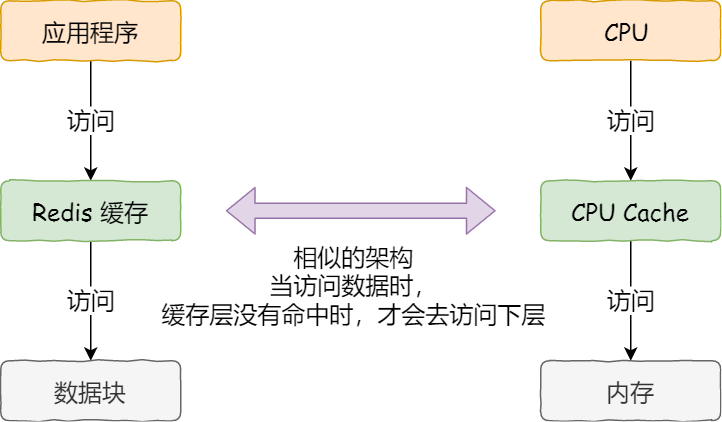
這樣的訪(fǎng)問(wèn)機(jī)制,跟我們使用「內(nèi)存作為硬盤(pán)的緩存」的邏輯是一樣的,如果內(nèi)存有緩存的數(shù)據(jù),則直接返回,否則要訪(fǎng)問(wèn)龜速一般的硬盤(pán)。
那 CPU 怎么知道要訪(fǎng)問(wèn)的內(nèi)存數(shù)據(jù),是否在 Cache 里?如果在的話(huà),如何找到 Cache 對(duì)應(yīng)的數(shù)據(jù)呢?我們從最簡(jiǎn)單、基礎(chǔ)的直接映射 Cache(Direct Mapped Cache) 說(shuō)起,來(lái)看看整個(gè) CPU Cache 的數(shù)據(jù)結(jié)構(gòu)和訪(fǎng)問(wèn)邏輯。
前面,我們提到 CPU 訪(fǎng)問(wèn)內(nèi)存數(shù)據(jù)時(shí),是一小塊一小塊數(shù)據(jù)讀取的,具體這一小塊數(shù)據(jù)的大小,取決于 coherency_line_size 的值,一般 64 字節(jié)。在內(nèi)存中,這一塊的數(shù)據(jù)我們稱(chēng)為內(nèi)存塊(Bock),讀取的時(shí)候我們要拿到數(shù)據(jù)所在內(nèi)存塊的地址。
對(duì)于直接映射 Cache 采用的策略,就是把內(nèi)存塊的地址始終「映射」在一個(gè) CPU Line(緩存塊) 的地址,至于映射關(guān)系實(shí)現(xiàn)方式,則是使用「取模運(yùn)算」,取模運(yùn)算的結(jié)果就是內(nèi)存塊地址對(duì)應(yīng)的 CPU Line(緩存塊) 的地址。
舉個(gè)例子,內(nèi)存共被劃分為 32 個(gè)內(nèi)存塊,CPU Cache 共有 8 個(gè) CPU Line,假設(shè) CPU 想要訪(fǎng)問(wèn)第 15 號(hào)內(nèi)存塊,如果 15 號(hào)內(nèi)存塊中的數(shù)據(jù)已經(jīng)緩存在 CPU Line 中的話(huà),則是一定映射在 7 號(hào) CPU Line 中,因?yàn)?15 % 8 的值是 7。
機(jī)智的你肯定發(fā)現(xiàn)了,使用取模方式映射的話(huà),就會(huì)出現(xiàn)多個(gè)內(nèi)存塊對(duì)應(yīng)同一個(gè) CPU Line,比如上面的例子,除了 15 號(hào)內(nèi)存塊是映射在 7 號(hào) CPU Line 中,還有 7 號(hào)、23 號(hào)、31 號(hào)內(nèi)存塊都是映射到 7 號(hào) CPU Line 中。
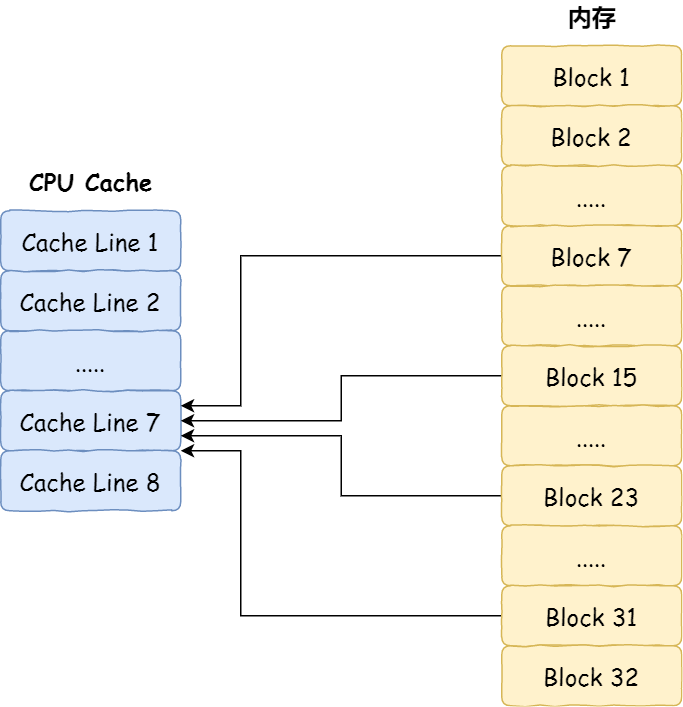
因此,為了區(qū)別不同的內(nèi)存塊,在對(duì)應(yīng)的 CPU Line 中我們還會(huì)存儲(chǔ)一個(gè)組標(biāo)記(Tag)。這個(gè)組標(biāo)記會(huì)記錄當(dāng)前 CPU Line 中存儲(chǔ)的數(shù)據(jù)對(duì)應(yīng)的內(nèi)存塊,我們可以用這個(gè)組標(biāo)記來(lái)區(qū)分不同的內(nèi)存塊。
除了組標(biāo)記信息外,CPU Line 還有兩個(gè)信息:
一個(gè)是,從內(nèi)存加載過(guò)來(lái)的實(shí)際存放數(shù)據(jù)(Data)。
另一個(gè)是,有效位(Valid bit),它是用來(lái)標(biāo)記對(duì)應(yīng)的 CPU Line 中的數(shù)據(jù)是否是有效的,如果有效位是 0,無(wú)論 CPU Line 中是否有數(shù)據(jù),CPU 都會(huì)直接訪(fǎng)問(wèn)內(nèi)存,重新加載數(shù)據(jù)。
CPU 在從 CPU Cache 讀取數(shù)據(jù)的時(shí)候,并不是讀取 CPU Line 中的整個(gè)數(shù)據(jù)塊,而是讀取 CPU 所需要的一個(gè)數(shù)據(jù)片段,這樣的數(shù)據(jù)統(tǒng)稱(chēng)為一個(gè)字(Word)。那怎么在對(duì)應(yīng)的 CPU Line 中數(shù)據(jù)塊中找到所需的字呢?答案是,需要一個(gè)偏移量(Offset)。
因此,一個(gè)內(nèi)存的訪(fǎng)問(wèn)地址,包括組標(biāo)記、CPU Line 索引、偏移量這三種信息,于是 CPU 就能通過(guò)這些信息,在 CPU Cache 中找到緩存的數(shù)據(jù)。而對(duì)于 CPU Cache 里的數(shù)據(jù)結(jié)構(gòu),則是由索引 + 有效位 + 組標(biāo)記 + 數(shù)據(jù)塊組成。

如果內(nèi)存中的數(shù)據(jù)已經(jīng)在 CPU Cahe 中了,那 CPU 訪(fǎng)問(wèn)一個(gè)內(nèi)存地址的時(shí)候,會(huì)經(jīng)歷這 4 個(gè)步驟:
根據(jù)內(nèi)存地址中索引信息,計(jì)算在 CPU Cahe 中的索引,也就是找出對(duì)應(yīng)的 CPU Line 的地址;
找到對(duì)應(yīng) CPU Line 后,判斷 CPU Line 中的有效位,確認(rèn) CPU Line 中數(shù)據(jù)是否是有效的,如果是無(wú)效的,CPU 就會(huì)直接訪(fǎng)問(wèn)內(nèi)存,并重新加載數(shù)據(jù),如果數(shù)據(jù)有效,則往下執(zhí)行;
對(duì)比內(nèi)存地址中組標(biāo)記和 CPU Line 中的組標(biāo)記,確認(rèn) CPU Line 中的數(shù)據(jù)是我們要訪(fǎng)問(wèn)的內(nèi)存數(shù)據(jù),如果不是的話(huà),CPU 就會(huì)直接訪(fǎng)問(wèn)內(nèi)存,并重新加載數(shù)據(jù),如果是的話(huà),則往下執(zhí)行;
根據(jù)內(nèi)存地址中偏移量信息,從 CPU Line 的數(shù)據(jù)塊中,讀取對(duì)應(yīng)的字。
到這里,相信你對(duì)直接映射 Cache 有了一定認(rèn)識(shí),但其實(shí)除了直接映射 Cache 之外,還有其他通過(guò)內(nèi)存地址找到 CPU Cache 中的數(shù)據(jù)的策略,比如全相連 Cache (Fully Associative Cache)、組相連 Cache (Set Associative Cache)等,這幾種策策略的數(shù)據(jù)結(jié)構(gòu)都比較相似,我們理解流直接映射 Cache 的工作方式,其他的策略如果你有興趣去看,相信很快就能理解的了。
如何寫(xiě)出讓 CPU 跑得更快的代碼?
我們知道 CPU 訪(fǎng)問(wèn)內(nèi)存的速度,比訪(fǎng)問(wèn) CPU Cache 的速度慢了 100 多倍,所以如果 CPU 所要操作的數(shù)據(jù)在 CPU Cache 中的話(huà),這樣將會(huì)帶來(lái)很大的性能提升。訪(fǎng)問(wèn)的數(shù)據(jù)在 CPU Cache 中的話(huà),意味著緩存命中,緩存命中率越高的話(huà),代碼的性能就會(huì)越好,CPU 也就跑的越快。
于是,「如何寫(xiě)出讓 CPU 跑得更快的代碼?」這個(gè)問(wèn)題,可以改成「如何寫(xiě)出 CPU 緩存命中率高的代碼?」。
在前面我也提到, L1 Cache 通常分為「數(shù)據(jù)緩存」和「指令緩存」,這是因?yàn)?CPU 會(huì)別處理數(shù)據(jù)和指令,比如 1+1=2 這個(gè)運(yùn)算,+ 就是指令,會(huì)被放在「指令緩存」中,而輸入數(shù)字 1 則會(huì)被放在「數(shù)據(jù)緩存」里。
因此,我們要分開(kāi)來(lái)看「數(shù)據(jù)緩存」和「指令緩存」的緩存命中率。
如何提升數(shù)據(jù)緩存的命中率?
假設(shè)要遍歷二維數(shù)組,有以下兩種形式,雖然代碼執(zhí)行結(jié)果是一樣,但你覺(jué)得哪種形式效率最高呢?為什么高呢?

經(jīng)過(guò)測(cè)試,形式一 array[i][j] ?執(zhí)行時(shí)間比形式二 array[j][i] 快好幾倍。
之所以有這么大的差距,是因?yàn)槎S數(shù)組 array 所占用的內(nèi)存是連續(xù)的,比如長(zhǎng)度 N 的指是 2 的話(huà),那么內(nèi)存中的數(shù)組元素的布局順序是這樣的:

形式一用 array[i][j] ?訪(fǎng)問(wèn)數(shù)組元素的順序,正是和內(nèi)存中數(shù)組元素存放的順序一致。當(dāng) CPU 訪(fǎng)問(wèn) array[0][0] 時(shí),由于該數(shù)據(jù)不在 Cache 中,于是會(huì)「順序」把跟隨其后的 3 個(gè)元素從內(nèi)存中加載到 CPU Cache,這樣當(dāng) CPU 訪(fǎng)問(wèn)后面的 3 個(gè)數(shù)組元素時(shí),就能在 CPU Cache 中成功地找到數(shù)據(jù),這意味著緩存命中率很高,緩存命中的數(shù)據(jù)不需要訪(fǎng)問(wèn)內(nèi)存,這便大大提高了代碼的性能。
而如果用形式二的 array[j][i] 來(lái)訪(fǎng)問(wèn),則訪(fǎng)問(wèn)的順序就是:

你可以看到,訪(fǎng)問(wèn)的方式跳躍式的,而不是順序的,那么如果 N 的數(shù)值很大,那么操作 array[j][i] 時(shí),是沒(méi)辦法把 array[j+1][i] 也讀入到 CPU Cache 中的,既然 array[j+1][i] 沒(méi)有讀取到 CPU Cache,那么就需要從內(nèi)存讀取該數(shù)據(jù)元素了。很明顯,這種不連續(xù)性、跳躍式訪(fǎng)問(wèn)數(shù)據(jù)元素的方式,可能不能充分利用到了 CPU Cache 的特性,從而代碼的性能不高。
那訪(fǎng)問(wèn) array[0][0] 元素時(shí),CPU 具體會(huì)一次從內(nèi)存中加載多少元素到 CPU Cache 呢?這個(gè)問(wèn)題,在前面我們也提到過(guò),這跟 CPU Cache Line 有關(guān),它表示 CPU Cache 一次性能加載數(shù)據(jù)的大小,可以在 Linux 里通過(guò) coherency_line_size 配置查看 它的大小,通常是 64 個(gè)字節(jié)。
也就是說(shuō),當(dāng) CPU 訪(fǎng)問(wèn)內(nèi)存數(shù)據(jù)時(shí),如果數(shù)據(jù)不在 CPU Cache 中,則會(huì)一次性會(huì)連續(xù)加載 64 字節(jié)大小的數(shù)據(jù)到 CPU Cache,那么當(dāng)訪(fǎng)問(wèn) array[0][0] 時(shí),由于該元素不足 64 字節(jié),于是就會(huì)往后順序讀取 array[0][0]~array[0][15] 到 CPU Cache 中。順序訪(fǎng)問(wèn)的 array[i][j] 因?yàn)槔昧诉@一特點(diǎn),所以就會(huì)比跳躍式訪(fǎng)問(wèn)的 array[j][i] 要快。
因此,遇到這種遍歷數(shù)組的情況時(shí),按照內(nèi)存布局順序訪(fǎng)問(wèn),將可以有效的利用 CPU Cache 帶來(lái)的好處,這樣我們代碼的性能就會(huì)得到很大的提升,
如何提升指令緩存的命中率?
提升數(shù)據(jù)的緩存命中率的方式,是按照內(nèi)存布局順序訪(fǎng)問(wèn),那針對(duì)指令的緩存該如何提升呢?
我們以一個(gè)例子來(lái)看看,有一個(gè)元素為 0 到 100 之間隨機(jī)數(shù)字組成的一維數(shù)組:

接下來(lái),對(duì)這個(gè)數(shù)組做兩個(gè)操作:

第一個(gè)操作,循環(huán)遍歷數(shù)組,把小于 50 的數(shù)組元素置為 0;
第二個(gè)操作,將數(shù)組排序;
那么問(wèn)題來(lái)了,你覺(jué)得先遍歷再排序速度快,還是先排序再遍歷速度快呢?
在回答這個(gè)問(wèn)題之前,我們先了解 CPU 的分支預(yù)測(cè)器。對(duì)于 if 條件語(yǔ)句,意味著此時(shí)至少可以選擇跳轉(zhuǎn)到兩段不同的指令執(zhí)行,也就是 if 還是 else 中的指令。那么,如果分支預(yù)測(cè)可以預(yù)測(cè)到接下來(lái)要執(zhí)行 if 里的指令,還是 else 指令的話(huà),就可以「提前」把這些指令放在指令緩存中,這樣 CPU 可以直接從 Cache 讀取到指令,于是執(zhí)行速度就會(huì)很快。
當(dāng)數(shù)組中的元素是隨機(jī)的,分支預(yù)測(cè)就無(wú)法有效工作,而當(dāng)數(shù)組元素都是順序的,分支預(yù)測(cè)器會(huì)動(dòng)態(tài)地根據(jù)歷史命中數(shù)據(jù)對(duì)未來(lái)進(jìn)行預(yù)測(cè),這樣命中率就會(huì)很高。
因此,先排序再遍歷速度會(huì)更快,這是因?yàn)榕判蛑螅瑪?shù)字是從小到大的,那么前幾次循環(huán)命中 if < 50 的次數(shù)會(huì)比較多,于是分支預(yù)測(cè)就會(huì)緩存 if 里的 array[i] = 0 指令到 Cache 中,后續(xù) CPU 執(zhí)行該指令就只需要從 Cache 讀取就好了。
如果你肯定代碼中的 if 中的表達(dá)式判斷為 true 的概率比較高,我們可以使用顯示分支預(yù)測(cè)工具,比如在 C/C++ 語(yǔ)言中編譯器提供了 likely 和 unlikely 這兩種宏,如果 if 條件為 ture 的概率大,則可以用 likely 宏把 if 里的表達(dá)式包裹起來(lái),反之用 unlikely 宏。

實(shí)際上,CPU 自身的動(dòng)態(tài)分支預(yù)測(cè)已經(jīng)是比較準(zhǔn)的了,所以只有當(dāng)非常確信 CPU 預(yù)測(cè)的不準(zhǔn),且能夠知道實(shí)際的概率情況時(shí),才建議使用這兩種宏。
如果提升多核 CPU 的緩存命中率?
在單核 CPU,雖然只能執(zhí)行一個(gè)進(jìn)程,但是操作系統(tǒng)給每個(gè)進(jìn)程分配了一個(gè)時(shí)間片,時(shí)間片用完了,就調(diào)度下一個(gè)進(jìn)程,于是各個(gè)進(jìn)程就按時(shí)間片交替地占用 CPU,從宏觀上看起來(lái)各個(gè)進(jìn)程同時(shí)在執(zhí)行。
而現(xiàn)代 CPU 都是多核心的,進(jìn)程可能在不同 CPU 核心來(lái)回切換執(zhí)行,這對(duì) CPU Cache 不是有利的,雖然 L3 Cache 是多核心之間共享的,但是 L1 和 L2 Cache 都是每個(gè)核心獨(dú)有的,如果一個(gè)進(jìn)程在不同核心來(lái)回切換,各個(gè)核心的緩存命中率就會(huì)受到影響,相反如果進(jìn)程都在同一個(gè)核心上執(zhí)行,那么其數(shù)據(jù)的 L1 和 L2 Cache 的緩存命中率可以得到有效提高,緩存命中率高就意味著 CPU 可以減少訪(fǎng)問(wèn) 內(nèi)存的頻率。
當(dāng)有多個(gè)同時(shí)執(zhí)行「計(jì)算密集型」的線(xiàn)程,為了防止因?yàn)榍袚Q到不同的核心,而導(dǎo)致緩存命中率下降的問(wèn)題,我們可以把線(xiàn)程綁定在某一個(gè) CPU 核心上,這樣性能可以得到非常可觀的提升。
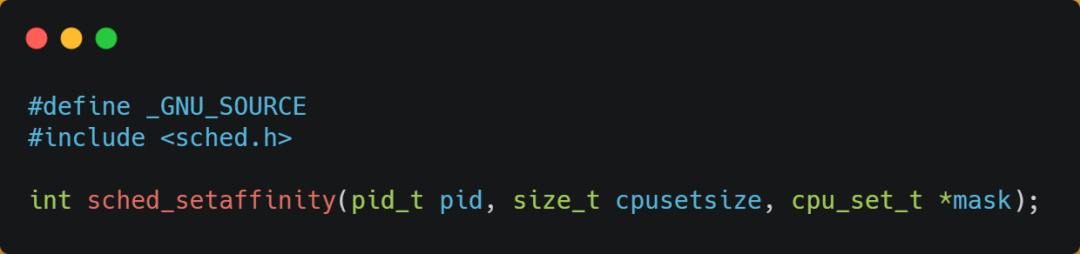
在 Linux 上提供了 sched_setaffinity 方法,來(lái)實(shí)現(xiàn)將線(xiàn)程綁定到某個(gè) CPU 核心這一功能。
總結(jié)
由于隨著計(jì)算機(jī)技術(shù)的發(fā)展,CPU 與 內(nèi)存的訪(fǎng)問(wèn)速度相差越來(lái)越多,如今差距已經(jīng)高達(dá)好幾百倍了,所以 CPU 內(nèi)部嵌入了 CPU Cache 組件,作為內(nèi)存與 CPU 之間的緩存層,CPU Cache 由于離 CPU 核心很近,所以訪(fǎng)問(wèn)速度也是非常快的,但由于所需材料成本比較高,它不像內(nèi)存動(dòng)輒幾個(gè) GB 大小,而是僅有幾十 KB 到 MB 大小。
當(dāng) CPU 訪(fǎng)問(wèn)數(shù)據(jù)的時(shí)候,先是訪(fǎng)問(wèn) CPU Cache,如果緩存命中的話(huà),則直接返回?cái)?shù)據(jù),就不用每次都從內(nèi)存讀取速度了。因此,緩存命中率越高,代碼的性能越好。
但需要注意的是,當(dāng) CPU 訪(fǎng)問(wèn)數(shù)據(jù)時(shí),如果 CPU Cache 沒(méi)有緩存該數(shù)據(jù),則會(huì)從內(nèi)存讀取數(shù)據(jù),但是并不是只讀一個(gè)數(shù)據(jù),而是一次性讀取一塊一塊的數(shù)據(jù)存放到 CPU Cache 中,之后才會(huì)被 CPU 讀取。
內(nèi)存地址映射到 CPU Cache 地址里的策略有很多種,其中比較簡(jiǎn)單是直接映射 Cache,它巧妙的把內(nèi)存地址拆分成「索引 + 組標(biāo)記 + 偏移量」的方式,使得我們可以將很大的內(nèi)存地址,映射到很小的 CPU Cache 地址里。
要想寫(xiě)出讓 CPU 跑得更快的代碼,就需要寫(xiě)出緩存命中率高的代碼,CPU L1 Cache 分為數(shù)據(jù)緩存和指令緩存,因而需要分別提高它們的緩存命中率:
對(duì)于數(shù)據(jù)緩存,我們?cè)诒闅v數(shù)據(jù)的時(shí)候,應(yīng)該按照內(nèi)存布局的順序操作,這是因?yàn)?CPU Cache 是根據(jù) CPU Cache Line 批量操作數(shù)據(jù)的,所以順序地操作連續(xù)內(nèi)存數(shù)據(jù)時(shí),性能能得到有效的提升;
對(duì)于指令緩存,有規(guī)律的條件分支語(yǔ)句能夠讓 CPU 的分支預(yù)測(cè)器發(fā)揮作用,進(jìn)一步提高執(zhí)行的效率;
另外,對(duì)于多核 CPU 系統(tǒng),線(xiàn)程可能在不同 CPU 核心來(lái)回切換,這樣各個(gè)核心的緩存命中率就會(huì)受到影響,于是要想提高進(jìn)程的緩存命中率,可以考慮把線(xiàn)程綁定 CPU 到某一個(gè) CPU 核心。
推薦閱讀:
吳恩達(dá)給 74 歲老父親發(fā)證了!8 年完成 146 門(mén)課程!
只需 25 美元,算力提升 3 倍:樹(shù)莓派 4 計(jì)算模組上線(xiàn)
Linux中一個(gè)高效的資源監(jiān)控器–Bpytop
5T技術(shù)資源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,單片機(jī),樹(shù)莓派,等等。在公眾號(hào)內(nèi)回復(fù)「1024」,即可免費(fèi)獲取!!