
vivo 公司 Kubernetes 集群 Ingress 網(wǎng)關(guān)實踐
vivo 人工智能計算平臺小組從 2018 年底開始建設(shè) AI 計算平臺至今,已經(jīng)在 kubernetes 集群、以及離線的深度學(xué)習(xí)模型訓(xùn)練等方面,積累了眾多寶貴的開發(fā)、運維經(jīng)驗,并逐步打造出穩(wěn)定的基礎(chǔ)容器平臺 - AI 容器平臺(VContainer)。為了支撐公司 AI 在線業(yè)務(wù)的發(fā)展,滿足公司對算力資源的高效調(diào)度管控需求,需要將在線業(yè)務(wù),主要包括 C 端、推理等業(yè)務(wù),由原來的虛擬機或物理機遷移至 AI 容器平臺。于是小組從 2020 年初開始,基于在線業(yè)務(wù)的需求對 AI 容器平臺進行進一步建設(shè),并將平臺與公司的 CMDB、CICD 等基礎(chǔ)模塊進行打通,使在線業(yè)務(wù)能夠順利從虛擬機、物理機遷移至 AI 容器平臺。
kubernetes 將業(yè)務(wù)運行環(huán)境的容器組抽象為 Pod 資源對象,并提供各種各樣的 workload(deployment、statefulset、daemonset 等)來部署 Pod,同時也提供多種資源對象來解決 Pod 之間網(wǎng)絡(luò)通信問題,其中,Service 解決 kubernetes 集群內(nèi)部網(wǎng)絡(luò)通信問題 (東西向流量),Ingress 則通過集群網(wǎng)關(guān)形式解決 kubernetes 集群外訪問 集群內(nèi)服務(wù)的網(wǎng)絡(luò)通信問題 (南北向流量)。
kubernetes Ingress 資源對象定義了集群內(nèi)外網(wǎng)絡(luò)通信的路由協(xié)議規(guī)范,目前有多個 Ingress 控制器實現(xiàn)了 Ingress 協(xié)議規(guī)范,其中 Nginx Ingress 是最常用的 Ingress 控制器。Nginx Ingress 有 2 種實現(xiàn),其一由 kubernetes 社區(qū)提供,另外一個是 Nginx Inc 公司提供的,我們采用是 kubernetes 官方社區(qū)提供的 ingress-nginx。
ingress-nginx 包含 2 個組件:ingress controller 通過 watch kubernetes 集群各種資源(ingress、endpoint、configmap 等)最終將 ingress 定義的路由規(guī)則轉(zhuǎn)換為 nginx 配置;nginx 將集群外部的 HTTP 訪問請求轉(zhuǎn)發(fā)到對應(yīng)的業(yè)務(wù) Pod。

1.nginx 所有轉(zhuǎn)發(fā)邏輯都是根據(jù) nginx.conf 配置來執(zhí)行的,ingress controller 會 watch kubernetesapiserver 各種資源對象,綜合起來形成最終的 nginx.conf 配置;
2.ingress 資源對象:生成 nginx 中 server host、location path 配置,以及根據(jù) ingress annotation 生成服務(wù)維度的 nginx 配置;
3.configmap 資源對象:生成全局維度的 nginx 配置信息;
4.endpoint 資源對象:根據(jù) Pod IP 動態(tài)變更 nginx upstream ip 信息。
其中針對 ingress nginx upstream 有 2 種路由方案:
方案一:上圖 紅色箭頭所示方案:nginx upstream 設(shè)置 Pod IP。由于 Pod IP 不固定,nginx 基于 ngx-lua 模塊將實時監(jiān)聽到的 Pod IP 動態(tài)更新到 upstream,nginx 會直接將 HTTP 請求轉(zhuǎn)發(fā)到業(yè)務(wù) Pod,這是目前 ingress nginx 默認方案;
方案二:上圖 黑色箭頭所示方案:nginx upstream 設(shè)置 Service name。由于 Service name 保持不變,nginx 直接使用 kubernetes 集群已有的 Service 通信機制,請求流量會經(jīng)過 kube-proxy 生成的 iptables,此時 nginx 無需動態(tài)更新 upstream,這是 ingress nginx 早期方案。
由于 ngx-lua 動態(tài)更新 upstream 這個方案非常穩(wěn)定,以及 kubernetes Service 通過 iptables 通信的網(wǎng)絡(luò)延時、DNAT 和 conntrack 的復(fù)雜性,我們采用了方案一。
kubernetes ingress-nginx 控制器基于 kubernetes 容器化部署,官方提供多種部署方案。
方案細節(jié)詳見官方文檔:
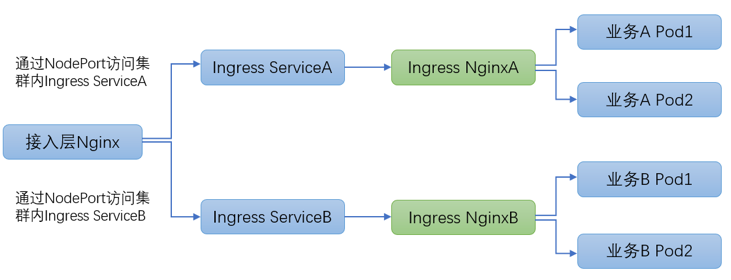
此方案中 ingress 控制器通過 deployment 部署,通過 NodePort service 暴露服務(wù),公司接入層 Nginx 通過 NodePort 訪問集群內(nèi) ingress 服務(wù),每個業(yè)務(wù)都獨立部署完全隔離的 ingress 集群。
方案優(yōu)點:每個服務(wù)可以獨立部署 ingress 集群,ingress 集群彼此完全隔離。
方案缺點:
(1)接入層 Nginx 需要通過 NodePort 方式訪問集群內(nèi) ingress 服務(wù),NodePort 會繞經(jīng) kubernetes 內(nèi)部的 iptables 負載均衡,涉及 DNAT、conntrack 內(nèi)核機制,存在端口資源耗盡風(fēng)險,網(wǎng)絡(luò)延時較高并且復(fù)雜性非常高,穩(wěn)定性較差。
(2)每個業(yè)務(wù)都獨立部署 ingress 集群,由于 ingress 必須高可用部署多副本,由此在部署諸多長尾小業(yè)務(wù)時會極大浪費集群資源。
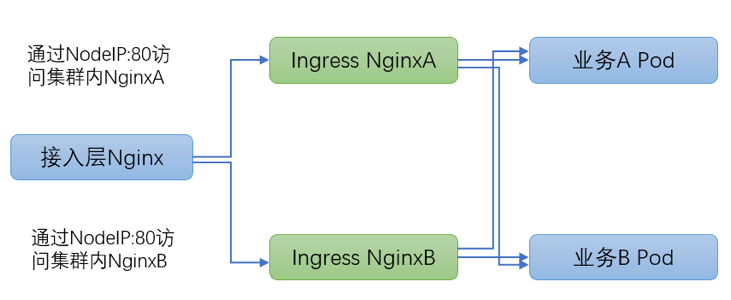
方案細節(jié)詳見官方文檔:
此方案中 ingress 控制器通過 daemonset 部署,并且采用宿主機網(wǎng)絡(luò),每個 node 機器只部署 1 個 ingresspod,并且 ingress pod 獨占 node 整機資源。
方案優(yōu)點:
(1)ingress pod 使用宿主機網(wǎng)絡(luò),網(wǎng)絡(luò)通信繞過 iptables、DNAT、conntrack 眾多內(nèi)核組件邏輯,網(wǎng)絡(luò)延時低并且復(fù)雜性大為降低,穩(wěn)定性較好;
(2)多業(yè)務(wù)共享 ingress 集群,極大節(jié)省集群資源。
方案缺點:
(1)多業(yè)務(wù)共享 ingress 集群,由于隔離不徹底可能會互相干擾造成影響;
(2)ingress daemonset 部署需要提前規(guī)劃 node 節(jié)點,增刪 ingress nginx 控制器之后需要更新接入層 Nginx upstream 信息。
經(jīng)過仔細考量和對比兩種部署方案之后,我們采用方案二,針對方案二存在的兩個問題,我們提供了針對性解決方案。
針對缺點 1,我們提供了 ingress 集群隔離方案,詳見 3.3 章節(jié)。
針對缺點 2,我們提供 ingress 一鍵部署腳本、并且結(jié)合公司接入層 Nginx 變更工單實現(xiàn)流程自動化。
kubernetes 集群部署業(yè)務(wù)時,某些場景下需要將 ingress 隔離部署,例如預(yù)發(fā)環(huán)境和生產(chǎn)環(huán)境的業(yè)務(wù)流量需要嚴格區(qū)分開,某些大流量業(yè)務(wù)、重保核心業(yè)務(wù)也需要進行隔離。
ingress nginx 官方提供多集群部署方案,詳見官方文檔:
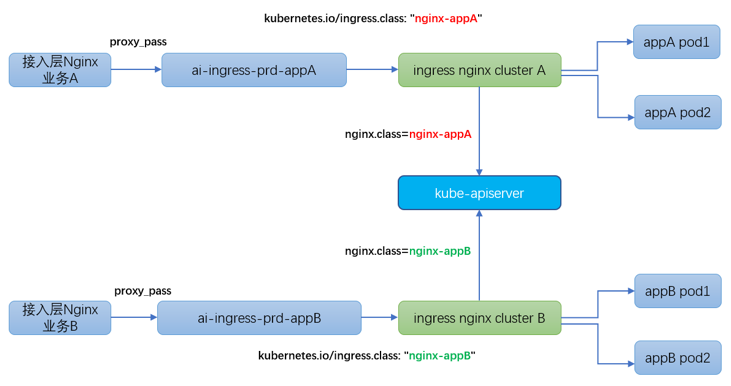
事實上,多業(yè)務(wù)共享 ingress 集群的原因在于 ingresscontroller 在監(jiān)聽 kubernetes apiserver 時 拉取了所有 ingress 資源對象,沒有做過濾和區(qū)分。所幸 ingress nginx 官方提供“kubernetes.io/ingress.class”機制將 ingress 資源對象進行歸類。
最終達到的效果是:
ingress controllerA 僅僅只 watch"屬于業(yè)務(wù) A 的 ingress 資源對象"
nginx controllerB 僅僅只 watch “屬于業(yè)務(wù) A 的 ingress 資源對象”
我們在 3.2 章節(jié) daemonset + hostNetwork 部署方案的基礎(chǔ)之上,結(jié)合 ingress 集群隔離部署方案,最終實現(xiàn)了 ingress 集群的高可用、高性能、簡單易維護、特殊業(yè)務(wù)可隔離的部署架構(gòu)。
ingress-nginx 集群作為 kubernetes 集群內(nèi)外通信的流量網(wǎng)關(guān),需要優(yōu)化性能滿足業(yè)務(wù)需求,我們在 nginx 和內(nèi)核配置層面做了相應(yīng)的優(yōu)化工作。
ingress-nginx 物理機執(zhí)行 top 命令發(fā)現(xiàn)每個 CPU 的 si 指標不均衡,針對此問題 我們開啟了網(wǎng)卡多隊列機制 以及中斷優(yōu)化。
開啟網(wǎng)卡多隊列:
ethtool -l eth0 // 查看網(wǎng)卡可以支持的多隊列配置ethtool -L eth0 combined 8 // 開啟網(wǎng)卡多隊列機制
中斷打散優(yōu)化:
service irqbalance stop // 首先關(guān)閉irqbalance系統(tǒng)服務(wù)sh set_irq_affinity -X all eth0 // Intel提供中斷打散腳本:https://github.com/majek/ixgbe/blob/master/scripts/set_irq_affinity
我們針對內(nèi)核參數(shù)也做了優(yōu)化工作以提升 nginx 性能,主要基于 nginx 官方提供的性能優(yōu)化方案:https://www.nginx.com/blog/tuning-nginx/
(1)調(diào)整連接隊列大小
nginx 進程監(jiān)聽 socket 套接字的 連接隊列大小默認為 511 ,在高并發(fā)場景下 默認的隊列大小不足以快速處理業(yè)務(wù)流量洪峰,連接隊列過小會造成隊列溢出、部分請求無法建立 TCP 連接,因此我們調(diào)整了 nginx 進程連接隊列大小。
sysctl -w net.core.somaxconn=32768nginx 進程充當反向代理時 會作為客戶端與 upstream 服務(wù)端建立 TCP 連接,此時會占用臨時端口,Linux 默認的端口使用范圍是 32768-60999,在高并發(fā)場景下,默認的源端口過少會造成端口資源耗盡,nginx 無法與 upstream 服務(wù)端建立連接,因此我們調(diào)整了默認端口使用范圍。
sysctl -w net.ipv4.ip_local_port_range="1024 65000"nginx 進程充當反向代理時 會作為服務(wù)端與接入層 nginx 建立 TCP 連接,同時作為客戶端與 upstream 服務(wù)端建立 TCP 連接,即 1 個 HTTP 請求在 nginx 側(cè)會耗用 2 條連接,也就占用 2 個文件描述符。在高并發(fā)場景下,為了同時處理海量請求,我們調(diào)整了最大文件描述符數(shù)限制。
sysctl -w fs.file-max=1048576nginx 進程充當反向代理時 會作為客戶端與 upstream 服務(wù)端建立 TCP 連接,連接會超時回收和主動釋放,nginx 側(cè)作為 TCP 連接釋放的發(fā)起方,會存在 TIME_WAIT 狀態(tài)的 TCP 連接,這種狀態(tài)的 TCP 連接會長時間 (2MSL 時長) 占用端口資源,當 TIME_WAIT 連接過多時 會造成 nginx 無法與 upstream 建立連接。
處理 TIME_WAIT 連接通常有 2 種解決辦法:
net.ipv4.tcp_tw_reuse:復(fù)用TIME_WAIT狀態(tài)的socket用于新建連接net.ipv4.tcp_tw_recycle:快速回收TIME_WAIT狀態(tài)連接
由于 tcp_tw_recycle 的高危性,4.12 內(nèi)核已經(jīng)廢棄此選項,tcp_tw_reuse 則相對安全,nginx 作為 TCP 連接的發(fā)起方,因此啟用此選項。
sysctl -w net.ipv4.tcp_tw_reuse=1以上內(nèi)核參數(shù)都使用 kubernetes 提供的 initContainer 機制進行設(shè)置。
initContainers:
initContainers:- name: sysctlimage: alpine:3.10securityContext:privileged: truecommand:- sh- -c- sysctl -w net.core.somaxconn=32768; sysctl -w net.ipv4.ip_local_port_range='1024 65000'; sysctl -w fs.file-max=1048576; sysctl -w net.ipv4.tcp_tw_reuse=1
nginx 作為服務(wù)端與接入層 nginx 建立 TCP 連接,同時作為客戶端與 upstream 服務(wù)端建立 TCP 連接,由此兩個方向的 TCP 連接數(shù)都需要調(diào)優(yōu)。
(1)nginx 充當服務(wù)端,調(diào)整 keep-alive 連接超時和最大請求數(shù)
ingress-nginx 使用 keep-alive 選項設(shè)置 接入層 nginx 和 ingress nginx 之間的連接超時時間(默認超時時間為 75s)。
使用 keep-alive-requests 選項設(shè)置 接入層 nginx 和 ingress nginx 之間 單個連接可承載的最大請求數(shù)(默認情況下單連接處理 100 個請求之后就會斷開釋放)。
在高并發(fā)場景下,我們調(diào)整了這兩個選項值,對應(yīng)到 ingress-nginx 全局 configmap 配置。
keep-alive: "75"keep-alive-requests: "10000"
(2)nginx 充當客戶端,調(diào)整 upstream-keepalive 連接超時和最大空閑連接數(shù)
ingress-nginx 使用 upstream-keepalive-connections 選項 設(shè)置 ingress nginx 和 upstream pod 之間 最大空閑連接緩存數(shù)(默認情況下最多緩存 32 個空閑連接)。
使用 upstream-keepalive-timeout 選項 設(shè)置 ingress nginx 和 upstream pod 之間的連接超時時間(默認超時時間為 60s)。
使用 upstream-keepalive-requests 選項 設(shè)置 ingress nginx 和 upstream pod 之間 單個連接可承載的最大請求數(shù)(默認情況下單連接處理 100 個請求之后就會斷開釋放)。
在高并發(fā)場景下,我們也調(diào)整了這 3 個選項值,使得 nginx 盡可能快速處理 HTTP 請求(盡量少釋放并重建 TCP 連接),同時控制 nginx 內(nèi)存使用量。
upstream-keepalive-connections: "200"upstream-keepalive-requests: "10000"upstream-keepalive-timeout: "100"
ingress nginx 與 upstream pod 建立 TCP 連接并進行通信,其中涉及 3 個超時配置,我們也相應(yīng)進行調(diào)優(yōu)。
proxy-connect-timeout 選項 設(shè)置 nginx 與 upstream pod 連接建立的超時時間,ingress nginx 默認設(shè)置為 5s,由于在 nginx 和業(yè)務(wù)均在內(nèi)網(wǎng)同機房通信,我們將此超時時間縮短到 1s。
proxy-read-timeout 選項 設(shè)置 nginx 與 upstream pod 之間讀操作的超時時間,ingress nginx 默認設(shè)置為 60s,當業(yè)務(wù)方服務(wù)異常導(dǎo)致響應(yīng)耗時飆漲時,異常請求會長時間夯住 ingress 網(wǎng)關(guān),我們在拉取所有服務(wù)正常請求的 P99.99 耗時之后,將網(wǎng)關(guān)與 upstream pod 之間讀寫超時均縮短到 3s,使得 nginx 可以及時掐斷異常請求,避免長時間被夯住。
proxy-connect-timeout: "1"proxy-read-timeout: "3"proxy-send-timeout: "3"
如果某個業(yè)務(wù)需要單獨調(diào)整讀寫超時,可以設(shè)置
ingress annotation(nginx.ingress.kubernetes.io/proxy-read-timeout 和 nginx.ingress.kubernetes.io/proxy-send-timeout)進行調(diào)整。
ingress-nginx 作為 kubernetes 集群內(nèi)外通信的流量網(wǎng)關(guān),而且多服務(wù)共享 ingress 集群,因此 ingress 集群必須保證極致的高可用性,我們在穩(wěn)定性建設(shè)方面做了大量工作,未來會持續(xù)提升 ingress 集群穩(wěn)定性。
接入層 nginx 將 ingress nginx worker IP 作為 upstream,早期接入層 nginx 使用默認的被動健康檢查機制,當 kubernetes 集群某個服務(wù)異常時,這種健康檢查機制會影響其他正常業(yè)務(wù)請求。
例如:接入層 nginx 將請求轉(zhuǎn)發(fā)到 ingress nginx 集群的 2 個實例。
upstream ingress-backend {server 10.192.168.1 max_fails=3 fail_timeout=30s;server 10.192.168.2 max_fails=3 fail_timeout=30s;}
如果某個業(yè)務(wù) A 出現(xiàn)大量 HTTP error,接入層 nginx 在默認的健康檢查機制之下會將 ingress nginx 實例屏蔽,但是此時業(yè)務(wù) B 的請求是正常的,理應(yīng)被 ingress nginx 正常轉(zhuǎn)發(fā)。
針對此問題,我們配合接入層 nginx 使用 nginx_upstream_check_module 模塊來做主動健康檢查,使用 /healthz 接口來反饋 ingress-nginx 運行的健康狀況,這種情況下接入層 nginx 不依賴于實際業(yè)務(wù)請求做 upstream ip 健康檢查,因此 kubernetes 集群每個業(yè)務(wù)請求彼此獨立,不會互相影響。
upstream ingress-backend {server 10.192.168.1 max_fails=0 fail_timeout=10s;server 10.192.168.2 max_fails=0 fail_timeout=10s;check interval=1000 rise=2 fall=2 timeout=1000 type=http default_down=false;check_keepalive_requests 1;check_http_send "GET /healthz HTTP/1.0\r\n\r\n";check_http_expect_alive http_2xx;zone ingress-backend 1M;}
ingress nginx 社區(qū)活躍,版本迭代較快,我們也在持續(xù)跟蹤社區(qū)最新進展,因此不可避免涉及 ingress nginx 自身的部署更新。在 ingress nginx 控制器部署更新的過程中必須保證流量完全無損。
接入層 nginx 基于 openresty 開發(fā)了 upstream 動態(tài)注冊和解綁接口,在此之上,我們結(jié)合 kubernetes 提供的 Pod lifecycle 機制,確保在解綁 ingress nginx ip 之后進行實際的更新部署操作,確保在 ingress nginx 新實例健康檢查通過之后動態(tài)注冊到接入層 nginx。
ingress nginx 提供 main-snippet、http-snippet 和 location-snippet 機制使得上層應(yīng)用可以自定義官方仍未支持的 nginx 配置,但是默認情況下,ingress nginx 不會校驗這些自定義配置的正確性,如果某個應(yīng)用自定義了錯誤的 nginx 配置,nginx 讀取該錯誤配置之后 reload 操作會失敗,控制器 pod 會一直 crash 并不斷重啟。由于一個應(yīng)用使用了錯誤的 ingress 配置導(dǎo)致整個 ingress 集群受損,這種問題非常嚴重,所幸 ingress nginx 官方提供了相應(yīng)的 vadatingwebhook 來主動校驗應(yīng)用的 ingress 配置,如果配置錯誤就直接攔截,由此保護了 ingress 集群的穩(wěn)定。
containers:- args:- --validating-webhook=:9090- --validating-webhook-certificate=/usr/local/certificates/validating-webhook.pem- --validating-webhook-key=/usr/local/certificates/validating-webhook-key.pem
ingress nginx 官方提供 grafana 模板來做可視化監(jiān)控,基于官方提供的監(jiān)控指標,我們使用內(nèi)部的告警平臺配置了 ingress 相關(guān)的告警項,包括 ingress controller HTTP 請求成功率、響應(yīng)延時、CPU 使用率、內(nèi)存使用率、Pod 狀態(tài)異常、Pod 重啟、Reload 失敗等。基于這些監(jiān)控告警項,會第一時間獲知 ingress 集群的運行狀態(tài),并迅速排查和解決問題。
nginx 提供了默認的 upstream 請求重試機制,默認情況下,當 upstream 服務(wù)返回 error 或者超時,nginx 會自動重試異常請求,并且沒有重試次數(shù)限制。由于接入層 nginx 和 ingress nginx 本質(zhì)都是 nginx,兩層 nginx 都啟用了默認的重試機制,異常請求時會出現(xiàn)大量重試,最差情況下會導(dǎo)致集群網(wǎng)關(guān)雪崩。我們和接入層 nginx 一起解決了這個問題:接入層 nginx 必須使用 proxy_next_upstream_tries 嚴格限制重試次數(shù),ingress nginx 則使用 proxy-next-upstream="off"直接關(guān)閉默認的重試機制。
vivo AI 計算平臺 kubernetes 集群 ingress 網(wǎng)關(guān)目前承擔(dān)了人工智能 AI 業(yè)務(wù)的大部分流量,隨著業(yè)務(wù)不斷容器化部署,ingress 網(wǎng)關(guān)需要在功能豐富性、性能、穩(wěn)定性方面進一步提升。展望后續(xù)工作,我們計劃在以下方面著手,進一步完善 ingress 網(wǎng)關(guān)。
目前大多數(shù)業(yè)務(wù)共享 ingress 集群,如果某個業(yè)務(wù)出現(xiàn)流量激增暴漲 超過了 ingress 集群服務(wù)能力,會影響其他業(yè)務(wù)的可用性,雖然 ingress 網(wǎng)關(guān)配置了一系列監(jiān)控告警以及相應(yīng)的快速擴容方案,但仍然存在流量洪峰拖垮 ingress 集群的風(fēng)險。ingress nginx 提供了服務(wù)限流能力,但是只支持以客戶端 IP 維度做限流,不具備實際使用的可能性,我們希望能做到以業(yè)務(wù) ingress 維度做服務(wù)限流,提高服務(wù)限流能力的易用性,最大程度保護 ingress 集群避免流量洪峰的沖擊。
目前有個別業(yè)務(wù)希望直接暴露 GRPC 服務(wù)供其他服務(wù)調(diào)用,但是 ingress nginx 只支持 GRPCS(grpcbase tls-http2),這其中帶來了證書分發(fā)和管理的復(fù)雜性、加解密的性能損耗,而且內(nèi)網(wǎng)可信環(huán)境下 普通業(yè)務(wù)無需加密通信,因此需要支持 GRPC(grpc base plaintext http2(non-TLS)),社區(qū)也迫切希望具備這個能力,相關(guān)的 issue 和 PR 數(shù)不勝數(shù),但是均被項目創(chuàng)始人回絕了,主要是目前 ingress nginx 不能以 ingress 維護開啟 http2 特性 以及現(xiàn)有機制無法自動探測和分發(fā) HTTP1.x 和 HTTP2 流量。
ingress nginx 默認日志方案是標準的云原生方式,還不具備日志收集以及日志分析運營的能力。如果 ingress nginx 日志能對接公司內(nèi)部的日志中心(日志文件落盤并由 agent 程序收集至統(tǒng)一的日志中心),那么 ingress 集群的排錯易用性、服務(wù)質(zhì)量分析運營能力會大幅提升。鑒于 ingress 集群流量巨大、日志文件落盤的性能損耗、日志中心單服務(wù)的寫入限制,我們會謹慎推進這項工作,一切工作都需要在保證 ingress 集群的穩(wěn)定性前提之下有序開展。
- END -
?推薦閱讀? 使用 GitLab 實現(xiàn) CI/CD Kubernetes 兩年使用經(jīng)驗總結(jié) Kubernetes 的這些原理,你一定要了解 Kubernetes主流網(wǎng)絡(luò)方案:Flannel 網(wǎng)絡(luò)分析 Linux 運維必備的 40 個命令總結(jié) 在項目實踐中,進行了以下DevOps方案建設(shè) Kubernetes 企業(yè)落地核心技術(shù)方案?
點亮,服務(wù)器三年不宕機

