本文集合了小編在日常學(xué)習(xí)和生產(chǎn)實(shí)踐中遇到的使用Hbase中的各種問(wèn)題和優(yōu)化方法,分別從表設(shè)計(jì)、rowkey設(shè)計(jì)、內(nèi)存、讀寫、配置等各個(gè)領(lǐng)域?qū)base常用的調(diào)優(yōu)方式進(jìn)行了總結(jié),希望能對(duì)讀者有幫助。本文參考結(jié)合自己實(shí)際優(yōu)化經(jīng)驗(yàn),參考了大量官網(wǎng)和各個(gè)前輩的經(jīng)驗(yàn),調(diào)優(yōu)后生產(chǎn)環(huán)境中的Hbase集群支撐了約50萬(wàn)/s的讀和25萬(wàn)/s的寫流量洪峰。感謝各位的經(jīng)驗(yàn)和付出。
HBase簡(jiǎn)介
HBase是一個(gè)分布式的、面向列的開源數(shù)據(jù)庫(kù)存儲(chǔ)系統(tǒng),是對(duì)Google論文BigTable的實(shí)現(xiàn),具有高可靠性、高性能和可伸縮性,它可以處理分布在數(shù)千臺(tái)通用服務(wù)器上的PB級(jí)的海量數(shù)據(jù)。BigTable的底層是通過(guò)GFS(Google文件系統(tǒng))來(lái)存儲(chǔ)數(shù)據(jù),而HBase對(duì)應(yīng)的則是通過(guò)HDFS(Hadoop分布式文件系統(tǒng))來(lái)存儲(chǔ)數(shù)據(jù)的。
HBase不同于一般的關(guān)系型數(shù)據(jù)庫(kù),它是一個(gè)適合于非結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)的數(shù)據(jù)庫(kù)。HBase不限制存儲(chǔ)的數(shù)據(jù)的種類,允許動(dòng)態(tài)的、靈活的數(shù)據(jù)模型。HBase可以在一個(gè)服務(wù)器集群上運(yùn)行,并且能夠根據(jù)業(yè)務(wù)進(jìn)行橫向擴(kuò)展。
海量存儲(chǔ):HBase適合存儲(chǔ)PB級(jí)別的海量數(shù)據(jù),在PB級(jí)別的數(shù)據(jù)以及采用廉價(jià)PC存儲(chǔ)的情況下,能在幾十到百毫秒內(nèi)返回?cái)?shù)據(jù)。這與HBase的記憶擴(kuò)展性息息相關(guān)。正是因?yàn)镠Base的良好擴(kuò)展性,才為海量數(shù)據(jù)的存儲(chǔ)提供了便利。
列式存儲(chǔ):列式存儲(chǔ),HBase是根據(jù)列族來(lái)存儲(chǔ)數(shù)據(jù)的。列族下面可以有非常多的列,列族在創(chuàng)建表的時(shí)候就必須指定,而不用指定列。
極易擴(kuò)展:HBase的擴(kuò)展性主要體現(xiàn)在兩個(gè)方面,一個(gè)是基于上層處理能力(RegionServer)的擴(kuò)展,一個(gè)是基于存儲(chǔ)能力(HDFS)的擴(kuò)展。
高并發(fā):目前大部分使用HBase的架構(gòu),都是采用廉價(jià)PC,因此單個(gè)IO的延遲其實(shí)并不小,一般在幾十到上百ms之間。這里說(shuō)的高并發(fā),主要是在并發(fā)的情況下,HBase的單個(gè)IO延遲下降并不多。
稀疏:稀疏主要是針對(duì)HBase列的靈活性,在列族中,可以指定任意多的列,在列數(shù)據(jù)為空的情況下,是不會(huì)占用存儲(chǔ)空間。
從我們使用Hbase開始,開發(fā)和調(diào)優(yōu)將會(huì)一直伴隨在系統(tǒng)的整個(gè)生命周期。筆者將對(duì)自己熟悉和使用過(guò)的調(diào)優(yōu)方式進(jìn)行一一歸納和總結(jié)。
表的設(shè)計(jì)之預(yù)分區(qū)優(yōu)化
HBase表在剛剛被創(chuàng)建時(shí),只有1個(gè)分區(qū)(region),當(dāng)一個(gè)region過(guò)大(達(dá)到hbase.hregion.max.filesize屬性中定義的閾值,默認(rèn)10GB)時(shí)表將會(huì)進(jìn)行split,分裂為2個(gè)分區(qū)。表在進(jìn)行split的時(shí)候,會(huì)耗費(fèi)大量的資源,頻繁的分區(qū)對(duì)HBase的性能有巨大的影響。HBase提供了預(yù)分區(qū)功能,即用戶可以在創(chuàng)建表的時(shí)候?qū)Ρ戆凑找欢ǖ囊?guī)則分區(qū)。
如果業(yè)務(wù)要進(jìn)行預(yù)分區(qū),首先要明確rowkey的取值范圍或構(gòu)成邏輯,假設(shè)我們的rowkey組成為例:兩位隨機(jī)數(shù)+時(shí)間戳+客戶號(hào),兩位隨機(jī)數(shù)的范圍從00-99,于是我劃分了10個(gè)region來(lái)存儲(chǔ)數(shù)據(jù),每個(gè)region對(duì)應(yīng)的rowkey范圍如下:-10,10-20,20-30,30-40,40-50,50-60,60-70,70-80,80-90,90-。
表的設(shè)計(jì)之rowkey優(yōu)化
在HBase中,定位一條數(shù)據(jù)(即一個(gè)Cell)需要4個(gè)維度的限定:行鍵(RowKey)、列族(Column Family)、列限定符(Column Qualifier)、時(shí)間戳(Timestamp)。其中,RowKey是最容易出現(xiàn)問(wèn)題的。除了根據(jù)業(yè)務(wù)和查詢需求來(lái)設(shè)計(jì)之外,還需要注意以下三點(diǎn)。
打散RowKey
HBase中的行是按照RowKey字典序排序的。這對(duì)Scan操作非常友好,因?yàn)镽owKey相近的行總是存儲(chǔ)在相近的位置,順序讀的效率比隨機(jī)讀要高。但是,如果大量的讀寫操作總是集中在某個(gè)RowKey范圍,那么就會(huì)造成Region熱點(diǎn),拖累RegionServer的性能。因此,要適當(dāng)?shù)貙owKey打散。
加鹽(salting)+哈希(hashing)
這里的“加鹽”與密碼學(xué)中的“加鹽”不是一回事。它是指在RowKey的前面增加一些前綴。加鹽的前綴種類越多,RowKey就被打得越散。前綴不可以是隨機(jī)的,因?yàn)楸仨氁尶蛻舳四軌蛲暾刂貥?gòu)RowKey。我們一般會(huì)拿原RowKey或其一部分計(jì)算hash值,然后再對(duì)hash值做運(yùn)算作為前綴。
反轉(zhuǎn)固定格式的數(shù)值
以手機(jī)號(hào)為例,手機(jī)號(hào)的前綴變化比較少(如152、185等),但后半部分變化很多。如果將它反轉(zhuǎn)過(guò)來(lái),可以有效地避免熱點(diǎn)。不過(guò)其缺點(diǎn)就是失去了有序性。反轉(zhuǎn)時(shí)間 這個(gè)操作嚴(yán)格來(lái)講不算“打散”,但可以調(diào)整數(shù)據(jù)的時(shí)間排序。如果將時(shí)間按照字典序排列,最近產(chǎn)生的數(shù)據(jù)會(huì)排在舊數(shù)據(jù)后面。如果用一個(gè)大值減去時(shí)間(比如用99999999減去yyyyMMdd,或者Long.MAX_VALUE減去時(shí)間戳),最新的數(shù)據(jù)就可以排在前面了。
控制RowKey長(zhǎng)度
在HBase中,RowKey、列族、列名等都是以byte[]形式傳輸?shù)摹owKey的最大長(zhǎng)度限制為64KB,但在實(shí)際應(yīng)用中最多不會(huì)超過(guò)100B。設(shè)計(jì)短RowKey有以下兩方面考慮:
在HBase的底層存儲(chǔ)HFile中,RowKey是KeyValue結(jié)構(gòu)中的一個(gè)域。假設(shè)RowKey長(zhǎng)度100B,那么1000萬(wàn)條數(shù)據(jù)中,只算RowKey就占用掉將近1G空間,會(huì)影響HFile的存儲(chǔ)效率。
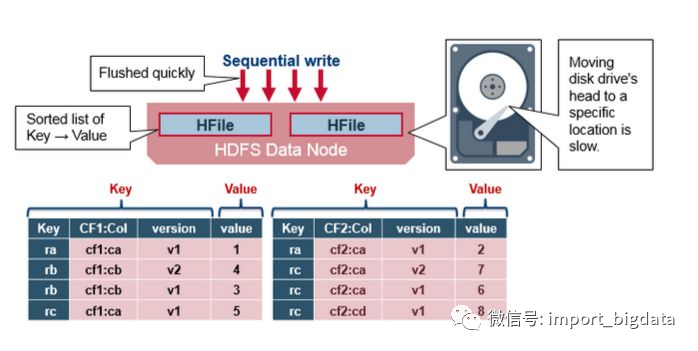
HBase中設(shè)計(jì)有MemStore和BlockCache,分別對(duì)應(yīng)列族/Store級(jí)別的寫入緩存,和RegionServer級(jí)別的讀取緩存。如果RowKey過(guò)長(zhǎng),緩存中存儲(chǔ)數(shù)據(jù)的密度就會(huì)降低,影響數(shù)據(jù)落地或查詢效率。
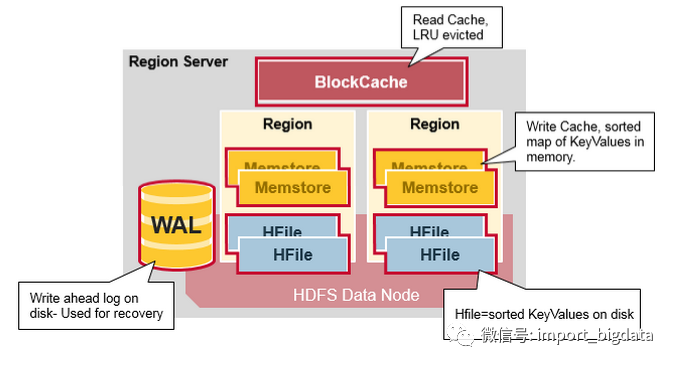
另外,我們目前使用的服務(wù)器操作系統(tǒng)都是64位系統(tǒng),內(nèi)存是按照8B對(duì)齊的,因此設(shè)計(jì)RowKey時(shí)一般做成8B的整數(shù)倍,如16B或者24B,可以提高尋址效率。同樣地,列族、列名的命名在保證可讀的情況下也應(yīng)盡量短。HBase官方不推薦使用3個(gè)以上列族,因此實(shí)際上列族命名幾乎都用一個(gè)字母,比如‘c’或‘f’。
保證RowKey唯一性
JVM調(diào)優(yōu)
這部分我們可以參考禪克大佬發(fā)表的一些關(guān)于Hbase 內(nèi)存設(shè)置的參數(shù)。
合理配置 JVM 內(nèi)存
首先涉及 HBase 服務(wù)的堆內(nèi)存設(shè)置。一般剛部署的 HBase 集群,默認(rèn)配置只給 Master 和 RegionServer 分配了 1G 的內(nèi)存,RegionServer 中 MemStore 默認(rèn)占 0.4 即 400MB 左右的空間,而一個(gè) MemStore 刷寫閾值默認(rèn) 128M,所以一個(gè) RegionServer 也就能正常管理 3 個(gè)Region,多了就可能會(huì)產(chǎn)生小文件了,另外也容易發(fā)生 Full GC。因此建議合理調(diào)整 Master 和 RegionServer 的內(nèi)存,比如:
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xms8g -Xmx8g"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xms32g -Xmx32g"
這里也要根據(jù)實(shí)際集群資源進(jìn)行配置,另外要牢記至少留 10% 的內(nèi)存給操作系統(tǒng)使用。
選擇合適的GC策略
另一個(gè)重要方面是 HBase JVM 的 GC 優(yōu)化,其實(shí) HBase 讀寫路徑上的很多設(shè)計(jì)都是圍繞 GC 優(yōu)化做的。選擇合適的 GC 策略非常重要,對(duì)于 HBase 而言通常有兩種可選 GC 方案:
CMS 避免不了 Full GC,而且 Full GC 場(chǎng)景下會(huì)通過(guò)一次串行的完整垃圾收集來(lái)回收碎片化的內(nèi)存,這個(gè)過(guò)程通常會(huì)比較長(zhǎng),應(yīng)用線程會(huì)發(fā)生長(zhǎng)時(shí)間的 STW 停頓,不響應(yīng)任何請(qǐng)求;而 G1 適合大內(nèi)存的場(chǎng)景,通過(guò)把堆內(nèi)存劃分為多個(gè) Region(不是 HBase 中的 Region),然后對(duì)各個(gè) Region 單獨(dú)進(jìn)行 GC,這樣就具有了并行整理內(nèi)存碎片的功能,可以最大限度的避免 Full GC 的到來(lái),提供更加合理的停頓時(shí)間。
由于 Master 只是做一些管理操作,實(shí)際處理讀寫請(qǐng)求和存儲(chǔ)數(shù)據(jù)的都是 RegionServer 節(jié)點(diǎn),所以一般內(nèi)存問(wèn)題都出在 RegionServer 上。
這里給的建議是,小堆(4G及以下)選擇 CMS,大堆(32G及以上)考慮用 G1,如果堆內(nèi)存介入 4~32G 之間,可自行測(cè)試下兩種方案。剩下來(lái)的就是 GC 參數(shù)調(diào)優(yōu)了。
開啟 MSLAB 功能
這是 HBase 自己實(shí)現(xiàn)了一套以 MemStore 為最小單元的內(nèi)存管理機(jī)制,稱為 MSLAB(MemStore-Local Allocation Buffer),主要作用是為了減少內(nèi)存碎片化,改善 Full GC 發(fā)生的情況。
MemStore 會(huì)在內(nèi)部維護(hù)一個(gè) 2M 大小的 Chunk 數(shù)組,當(dāng)寫入數(shù)據(jù)時(shí)會(huì)先申請(qǐng) 2M 的 Chunk,將實(shí)際數(shù)據(jù)寫入該 Chunk中,當(dāng)該 Chunk 滿了以后會(huì)再申請(qǐng)一個(gè)新的 Chunk。這樣 MemStore Flush 后會(huì)達(dá)到粗粒度化的內(nèi)存碎片效果,可以有效降低 Full GC 的觸發(fā)頻率。
HBase 默認(rèn)是開啟 MSLAB 功能的,和 MSLAB 相關(guān)的配置包括:
hbase.hregion.memstore.mslab.enabled:MSLAB 開關(guān),默認(rèn)為 true,即打開 MSLAB。
hbase.hregion.memstore.mslab.chunksize:每個(gè) Chunk 的大 小,默認(rèn)為 2MB,建議保持默認(rèn)值。
hbase.hregion.memstore.chunkpool.maxsize:內(nèi)部 Chunk Pool 功能,默認(rèn)為 0 ,即關(guān)閉 Chunk Pool 功能。設(shè)置為大于 0 的值才能開啟,取值范圍為 [0,1],表示 Chunk Pool 占整個(gè) MemStore 內(nèi)存大小的比例。
hbase.hregion.memstore.chunkpool.initialsize:表示初始化時(shí)申請(qǐng)多少個(gè) Chunk 放到 Chunk Pool 中,默認(rèn)為 0,即初始化時(shí)不申請(qǐng) Chuck,只在寫入數(shù)據(jù)時(shí)才申請(qǐng)。
hbase.hregion.memstore.mslab.max.allocation:表示能放入 MSLAB 的最大單元格大小,默認(rèn)為 256KB,超過(guò)該大小的數(shù)據(jù)將從 JVM 堆分配空間而不是 MSLAB。
出于性能優(yōu)化考慮,建議檢查相關(guān)配置,確保 MSLAB 處于開啟狀態(tài)。
考慮開啟 BucketCache
這塊涉及到讀緩存 BlockCache 的策略選擇。首先,BlockCache 是 RegionServer 級(jí)別的,一個(gè) RegionServer 只有一個(gè) BlockCache。BlockCache 的工作原理是讀請(qǐng)求會(huì)首先檢查 Block 是否存在于 BlockCache,存在就直接返回,如果不存在再去 HFile 和 MemStore 中獲取,返回?cái)?shù)據(jù)時(shí)把 Block 緩存到 BlockCache 中,后續(xù)同一請(qǐng)求或臨近查詢可以直接從 BlockCache 中獲取,避免過(guò)多的昂貴 IO 操作。BlockCache 默認(rèn)是開啟的。
目前 BlockCache 的實(shí)現(xiàn)方案有三種:
(1) LRUBlockCache 最早的 BlockCache 方案,也是 HBase 目前默認(rèn)的方案。LRU 是 Least Recently Used 的縮寫,稱為近期最少使用算法。LRUBlockCache 參考了 JVM 分代設(shè)計(jì)的思想,采用了緩存分層設(shè)計(jì)。
LRUBlockCache 將整個(gè) BlockCache 分為 single-access(單次讀取區(qū))、multi-access(多次讀取區(qū))和 in-memory 三部分,默認(rèn)分別占讀緩存的25%、50%、25%。其中設(shè)置 IN_MEMORY=true 的列族,Block 被讀取后才會(huì)直接放到 in-memory 區(qū),因此建議只給那些數(shù)據(jù)量少且訪問(wèn)頻繁的列族設(shè)置 IN_MEMORY 屬性。另外,HBase 元數(shù)據(jù)比如 meta 表、namespace 表也都緩存在 in-memory 區(qū)。
(2) SlabCache HBase 0.92 版本引入的一種方案,起初是為了避免 Full GC 而引入的一種堆外內(nèi)存方案,并與 LRUBlockCache 搭配使用,后來(lái)發(fā)現(xiàn)它對(duì) Full GC 的改善很小,以至于這個(gè)方案基本被棄用了。
(3) BucketCache HBase 0.96 版本引入的一種方案,它借鑒了 SlabCache 的設(shè)計(jì)思想,是一種非常高效的緩存方案。實(shí)際應(yīng)用中,HBase 將 BucketCache 和 LRUBlockCache 搭配使用,稱為組合模式(CombinedBlockCahce),具體地說(shuō)就是把不同類型的 Block 分別放到 LRUBlockCache 和 BucketCache 中。
HBase 會(huì)把 Index Block 和 Bloom Block 放到 LRUBlockCache 中,將 Data Block 放到 BucketCache 中,所以讀取數(shù)據(jù)會(huì)去 LRUBlockCache 查詢一下 Index Block,然后再去 BucketCache 中查詢真正的數(shù)據(jù)。
BucketCache 涉及的常用參數(shù)有:
hbase.bucketcache.ioengine:使用的存儲(chǔ)介質(zhì),可設(shè)置為 heap、offheap 或 file,其中 heap 表示空間從JVM堆中申請(qǐng),offheap 表示使用 DirectByteBuffer 技術(shù)實(shí)現(xiàn)堆外內(nèi)存管理,file 表示使用類似 SSD 等存儲(chǔ)介質(zhì)緩存數(shù)據(jù)。默認(rèn)值為空,即關(guān)閉 BucketCache,一般建議開啟 BucketCache。此外,HBase 2.x 不再支持 heap 選型。
hbase.bucketcache.combinedcache.enabled:是否打開 CombinedBlockCache 組合模式,默認(rèn)為 true。此外,HBase 2.x 不再支持該參數(shù)。
hbase.bucketcache.size:BucketCache 大小,取值有兩種,一種是[0,1]之間的浮點(diǎn)數(shù)值,表示占總內(nèi)存的百分比,另一種是大于1的值,表示占用內(nèi)存大小,單位 MB。
根據(jù)上面的分析,一般建議開啟 BucketCache,綜合考慮成本和性能,建議比較合理的介質(zhì)是:LRUBlockCache 使用內(nèi)存,BuckectCache 使用SSD,HFile 使用機(jī)械磁盤。
合理配置讀寫緩存比例
HBase 為了優(yōu)化性能,在讀寫路徑上分別設(shè)置了讀緩存和寫緩存,參數(shù)分別是 hfile.block.cache.size 與 hbase.regionserver.global.memstore.size,默認(rèn)值都是 0.4,表示讀寫緩存各占 RegionServer 堆內(nèi)存的 40%。
在一些場(chǎng)景下,我們可以適當(dāng)調(diào)整兩部分比例,比如寫多讀少的場(chǎng)景下我們可以適當(dāng)調(diào)大寫緩存,讓 HBase 更好的支持寫業(yè)務(wù),相反類似,總之兩個(gè)參數(shù)要配合調(diào)整。
讀優(yōu)化
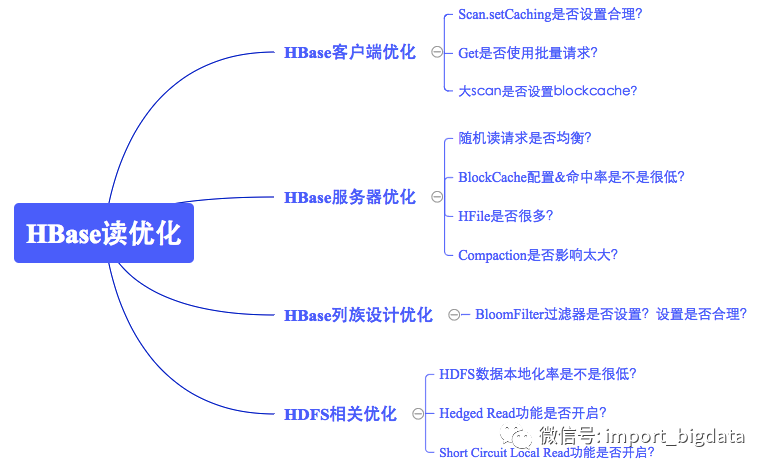
HBase客戶端優(yōu)化
和大多數(shù)系統(tǒng)一樣,客戶端作為業(yè)務(wù)讀寫的入口,姿勢(shì)使用不正確通常會(huì)導(dǎo)致本業(yè)務(wù)讀延遲較高實(shí)際上存在一些使用姿勢(shì)的推薦用法,這里一般需要關(guān)注四個(gè)問(wèn)題:
優(yōu)化原理:在解釋這個(gè)問(wèn)題之前,首先需要解釋什么是scan緩存,通常來(lái)講一次scan會(huì)返回大量數(shù)據(jù),因此客戶端發(fā)起一次scan請(qǐng)求,實(shí)際并不會(huì)一次就將所有數(shù)據(jù)加載到本地,而是分成多次RPC請(qǐng)求進(jìn)行加載,這樣設(shè)計(jì)一方面是因?yàn)榇罅繑?shù)據(jù)請(qǐng)求可能會(huì)導(dǎo)致網(wǎng)絡(luò)帶寬嚴(yán)重消耗進(jìn)而影響其他業(yè)務(wù),另一方面也有可能因?yàn)閿?shù)據(jù)量太大導(dǎo)致本地客戶端發(fā)生OOM。在這樣的設(shè)計(jì)體系下用戶會(huì)首先加載一部分?jǐn)?shù)據(jù)到本地,然后遍歷處理,再加載下一部分?jǐn)?shù)據(jù)到本地處理,如此往復(fù),直至所有數(shù)據(jù)都加載完成。數(shù)據(jù)加載到本地就存放在scan緩存中,默認(rèn)100條數(shù)據(jù)大小。
通常情況下,默認(rèn)的scan緩存設(shè)置就可以正常工作的。但是在一些大scan(一次scan可能需要查詢幾萬(wàn)甚至幾十萬(wàn)行數(shù)據(jù))來(lái)說(shuō),每次請(qǐng)求100條數(shù)據(jù)意味著一次scan需要幾百甚至幾千次RPC請(qǐng)求,這種交互的代價(jià)無(wú)疑是很大的。因此可以考慮將scan緩存設(shè)置增大,比如設(shè)為500或者1000就可能更加合適。筆者之前做過(guò)一次試驗(yàn),在一次scan掃描10w+條數(shù)據(jù)量的條件下,將scan緩存從100增加到1000,可以有效降低scan請(qǐng)求的總體延遲,延遲基本降低了25%左右。
優(yōu)化建議:大scan場(chǎng)景下將scan緩存從100增大到500或者1000,用以減少RPC次數(shù)
2. get請(qǐng)求是否可以使用批量請(qǐng)求?
優(yōu)化原理:HBase分別提供了單條get以及批量get的API接口,使用批量get接口可以減少客戶端到RegionServer之間的RPC連接數(shù),提高讀取性能。另外需要注意的是,批量get請(qǐng)求要么成功返回所有請(qǐng)求數(shù)據(jù),要么拋出異常。
優(yōu)化建議:使用批量get進(jìn)行讀取請(qǐng)求
3. 請(qǐng)求是否可以顯示指定列族或者列?
優(yōu)化原理:HBase是典型的列族數(shù)據(jù)庫(kù),意味著同一列族的數(shù)據(jù)存儲(chǔ)在一起,不同列族的數(shù)據(jù)分開存儲(chǔ)在不同的目錄下。如果一個(gè)表有多個(gè)列族,只是根據(jù)Rowkey而不指定列族進(jìn)行檢索的話不同列族的數(shù)據(jù)需要獨(dú)立進(jìn)行檢索,性能必然會(huì)比指定列族的查詢差很多,很多情況下甚至?xí)?倍~3倍的性能損失。
優(yōu)化建議:可以指定列族或者列進(jìn)行精確查找的盡量指定查找
4. 離線批量讀取請(qǐng)求是否設(shè)置禁止緩存?
優(yōu)化原理:通常離線批量讀取數(shù)據(jù)會(huì)進(jìn)行一次性全表掃描,一方面數(shù)據(jù)量很大,另一方面請(qǐng)求只會(huì)執(zhí)行一次。這種場(chǎng)景下如果使用scan默認(rèn)設(shè)置,就會(huì)將數(shù)據(jù)從HDFS加載出來(lái)之后放到緩存。可想而知,大量數(shù)據(jù)進(jìn)入緩存必將其他實(shí)時(shí)業(yè)務(wù)熱點(diǎn)數(shù)據(jù)擠出,其他業(yè)務(wù)不得不從HDFS加載,進(jìn)而會(huì)造成明顯的讀延遲毛刺
優(yōu)化建議:離線批量讀取請(qǐng)求設(shè)置禁用緩存,scan.setBlockCache(false)
HBase服務(wù)器端優(yōu)化
一般服務(wù)端端問(wèn)題一旦導(dǎo)致業(yè)務(wù)讀請(qǐng)求延遲較大的話,通常是集群級(jí)別的,即整個(gè)集群的業(yè)務(wù)都會(huì)反映讀延遲較大。可以從4個(gè)方面入手:
優(yōu)化原理:極端情況下假如所有的讀請(qǐng)求都落在一臺(tái)RegionServer的某幾個(gè)Region上,這一方面不能發(fā)揮整個(gè)集群的并發(fā)處理能力,另一方面勢(shì)必造成此臺(tái)RegionServer資源嚴(yán)重消耗(比如IO耗盡、handler耗盡等),落在該臺(tái)RegionServer上的其他業(yè)務(wù)會(huì)因此受到很大的波及。可見,讀請(qǐng)求不均衡不僅會(huì)造成本身業(yè)務(wù)性能很差,還會(huì)嚴(yán)重影響其他業(yè)務(wù)。當(dāng)然,寫請(qǐng)求不均衡也會(huì)造成類似的問(wèn)題,可見負(fù)載不均衡是HBase的大忌。
觀察確認(rèn):觀察所有RegionServer的讀請(qǐng)求QPS曲線,確認(rèn)是否存在讀請(qǐng)求不均衡現(xiàn)象
優(yōu)化建議:RowKey必須進(jìn)行散列化處理(比如MD5散列),同時(shí)建表必須進(jìn)行預(yù)分區(qū)處理
6. BlockCache是否設(shè)置合理?
優(yōu)化原理:BlockCache作為讀緩存,對(duì)于讀性能來(lái)說(shuō)至關(guān)重要。默認(rèn)情況下BlockCache和Memstore的配置相對(duì)比較均衡(各占40%),可以根據(jù)集群業(yè)務(wù)進(jìn)行修正,比如讀多寫少業(yè)務(wù)可以將BlockCache占比調(diào)大。另一方面,BlockCache的策略選擇也很重要,不同策略對(duì)讀性能來(lái)說(shuō)影響并不是很大,但是對(duì)GC的影響卻相當(dāng)顯著,尤其BucketCache的offheap模式下GC表現(xiàn)很優(yōu)越。另外,HBase 2.0對(duì)offheap的改造(HBASE-11425)將會(huì)使HBase的讀性能得到2~4倍的提升,同時(shí)GC表現(xiàn)會(huì)更好!
觀察確認(rèn):觀察所有RegionServer的緩存未命中率、配置文件相關(guān)配置項(xiàng)一級(jí)GC日志,確認(rèn)BlockCache是否可以優(yōu)化
優(yōu)化建議:JVM內(nèi)存配置量 < 20G,BlockCache策略選擇LRUBlockCache;否則選擇BucketCache策略的offheap模式;期待HBase 2.0的到來(lái)!
優(yōu)化原理:HBase讀取數(shù)據(jù)通常首先會(huì)到Memstore和BlockCache中檢索(讀取最近寫入數(shù)據(jù)&熱點(diǎn)數(shù)據(jù)),如果查找不到就會(huì)到文件中檢索。HBase的類LSM結(jié)構(gòu)會(huì)導(dǎo)致每個(gè)store包含多數(shù)HFile文件,文件越多,檢索所需的IO次數(shù)必然越多,讀取延遲也就越高。文件數(shù)量通常取決于Compaction的執(zhí)行策略,一般和兩個(gè)配置參數(shù)有關(guān):hbase.hstore.compactionThreshold和hbase.hstore.compaction.max.size,前者表示一個(gè)store中的文件數(shù)超過(guò)多少就應(yīng)該進(jìn)行合并,后者表示參數(shù)合并的文件大小最大是多少,超過(guò)此大小的文件不能參與合并。這兩個(gè)參數(shù)不能設(shè)置太’松’(前者不能設(shè)置太大,后者不能設(shè)置太小),導(dǎo)致Compaction合并文件的實(shí)際效果不明顯,進(jìn)而很多文件得不到合并。這樣就會(huì)導(dǎo)致HFile文件數(shù)變多。
觀察確認(rèn):觀察RegionServer級(jí)別以及Region級(jí)別的storefile數(shù),確認(rèn)HFile文件是否過(guò)多
優(yōu)化建議:hbase.hstore.compactionThreshold設(shè)置不能太大,默認(rèn)是3個(gè);設(shè)置需要根據(jù)Region大小確定,通常可以簡(jiǎn)單的認(rèn)為hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
8. Compaction是否消耗系統(tǒng)資源過(guò)多?
優(yōu)化原理:Compaction是將小文件合并為大文件,提高后續(xù)業(yè)務(wù)隨機(jī)讀性能,但是也會(huì)帶來(lái)IO放大以及帶寬消耗問(wèn)題(數(shù)據(jù)遠(yuǎn)程讀取以及三副本寫入都會(huì)消耗系統(tǒng)帶寬)。正常配置情況下Minor Compaction并不會(huì)帶來(lái)很大的系統(tǒng)資源消耗,除非因?yàn)榕渲貌缓侠韺?dǎo)致Minor Compaction太過(guò)頻繁,或者Region設(shè)置太大情況下發(fā)生Major Compaction。
觀察確認(rèn):觀察系統(tǒng)IO資源以及帶寬資源使用情況,再觀察Compaction隊(duì)列長(zhǎng)度,確認(rèn)是否由于Compaction導(dǎo)致系統(tǒng)資源消耗過(guò)多
(1)Minor Compaction設(shè)置:hbase.hstore.compactionThreshold設(shè)置不能太小,又不能設(shè)置太大,因此建議設(shè)置為5~6;hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
(2)Major Compaction設(shè)置:大Region讀延遲敏感業(yè)務(wù)( 100G以上)通常不建議開啟自動(dòng)Major Compaction,手動(dòng)低峰期觸發(fā)。小Region或者延遲不敏感業(yè)務(wù)可以開啟Major Compaction,但建議限制流量;
(3)期待更多的優(yōu)秀Compaction策略,類似于stripe-compaction盡早提供穩(wěn)定服務(wù)
HBase列族設(shè)計(jì)優(yōu)化
HBase列族設(shè)計(jì)對(duì)讀性能影響也至關(guān)重要,其特點(diǎn)是只影響單個(gè)業(yè)務(wù),并不會(huì)對(duì)整個(gè)集群產(chǎn)生太大影響。列族設(shè)計(jì)主要從兩個(gè)方面檢查:
9. Bloomfilter是否設(shè)置?是否設(shè)置合理?
優(yōu)化原理:Bloomfilter主要用來(lái)過(guò)濾不存在待檢索RowKey或者Row-Col的HFile文件,避免無(wú)用的IO操作。它會(huì)告訴你在這個(gè)HFile文件中是否可能存在待檢索的KV,如果不存在,就可以不用消耗IO打開文件進(jìn)行seek。很顯然,通過(guò)設(shè)置Bloomfilter可以提升隨機(jī)讀寫的性能。
Bloomfilter取值有兩個(gè),row以及rowcol,需要根據(jù)業(yè)務(wù)來(lái)確定具體使用哪種。如果業(yè)務(wù)大多數(shù)隨機(jī)查詢僅僅使用row作為查詢條件,Bloomfilter一定要設(shè)置為row,否則如果大多數(shù)隨機(jī)查詢使用row+cf作為查詢條件,Bloomfilter需要設(shè)置為rowcol。如果不確定業(yè)務(wù)查詢類型,設(shè)置為row。
優(yōu)化建議:任何業(yè)務(wù)都應(yīng)該設(shè)置Bloomfilter,通常設(shè)置為row就可以,除非確認(rèn)業(yè)務(wù)隨機(jī)查詢類型為row+cf,可以設(shè)置為rowcol
HDFS相關(guān)優(yōu)化
HDFS作為HBase最終數(shù)據(jù)存儲(chǔ)系統(tǒng),通常會(huì)使用三副本策略存儲(chǔ)HBase數(shù)據(jù)文件以及日志文件。從HDFS的角度望上層看,HBase即是它的客戶端,HBase通過(guò)調(diào)用它的客戶端進(jìn)行數(shù)據(jù)讀寫操作,因此HDFS的相關(guān)優(yōu)化也會(huì)影響HBase的讀寫性能。這里主要關(guān)注如下三個(gè)方面:
10. Short-Circuit Local Read功能是否開啟?
優(yōu)化原理:當(dāng)前HDFS讀取數(shù)據(jù)都需要經(jīng)過(guò)DataNode,客戶端會(huì)向DataNode發(fā)送讀取數(shù)據(jù)的請(qǐng)求,DataNode接受到請(qǐng)求之后從硬盤中將文件讀出來(lái),再通過(guò)TPC發(fā)送給客戶端。Short Circuit策略允許客戶端繞過(guò)DataNode直接讀取本地?cái)?shù)據(jù)。(具體原理參考此處)
優(yōu)化建議:開啟Short Circuit Local Read功能。
優(yōu)化原理:HBase數(shù)據(jù)在HDFS中一般都會(huì)存儲(chǔ)三份,而且優(yōu)先會(huì)通過(guò)Short-Circuit Local Read功能嘗試本地讀。但是在某些特殊情況下,有可能會(huì)出現(xiàn)因?yàn)榇疟P問(wèn)題或者網(wǎng)絡(luò)問(wèn)題引起的短時(shí)間本地讀取失敗,為了應(yīng)對(duì)這類問(wèn)題,社區(qū)開發(fā)者提出了補(bǔ)償重試機(jī)制 – Hedged Read。該機(jī)制基本工作原理為:客戶端發(fā)起一個(gè)本地讀,一旦一段時(shí)間之后還沒(méi)有返回,客戶端將會(huì)向其他DataNode發(fā)送相同數(shù)據(jù)的請(qǐng)求。哪一個(gè)請(qǐng)求先返回,另一個(gè)就會(huì)被丟棄。
優(yōu)化建議:開啟Hedged Read功能。
數(shù)據(jù)本地率:HDFS數(shù)據(jù)通常存儲(chǔ)三份,假如當(dāng)前RegionA處于Node1上,數(shù)據(jù)a寫入的時(shí)候三副本為(Node1,Node2,Node3),數(shù)據(jù)b寫入三副本是(Node1,Node4,Node5),數(shù)據(jù)c寫入三副本(Node1,Node3,Node5),可以看出來(lái)所有數(shù)據(jù)寫入本地Node1肯定會(huì)寫一份,數(shù)據(jù)都在本地可以讀到,因此數(shù)據(jù)本地率是100%。現(xiàn)在假設(shè)RegionA被遷移到了Node2上,只有數(shù)據(jù)a在該節(jié)點(diǎn)上,其他數(shù)據(jù)(b和c)讀取只能遠(yuǎn)程跨節(jié)點(diǎn)讀,本地率就為33%(假設(shè)a,b和c的數(shù)據(jù)大小相同)。
優(yōu)化原理:數(shù)據(jù)本地率太低很顯然會(huì)產(chǎn)生大量的跨網(wǎng)絡(luò)IO請(qǐng)求,必然會(huì)導(dǎo)致讀請(qǐng)求延遲較高,因此提高數(shù)據(jù)本地率可以有效優(yōu)化隨機(jī)讀性能。數(shù)據(jù)本地率低的原因一般是因?yàn)镽egion遷移(自動(dòng)balance開啟、RegionServer宕機(jī)遷移、手動(dòng)遷移等),因此一方面可以通過(guò)避免Region無(wú)故遷移來(lái)保持?jǐn)?shù)據(jù)本地率,另一方面如果數(shù)據(jù)本地率很低,也可以通過(guò)執(zhí)行major_compact提升數(shù)據(jù)本地率到100%。
優(yōu)化建議:避免Region無(wú)故遷移,比如關(guān)閉自動(dòng)balance、RS宕機(jī)及時(shí)拉起并遷回飄走的Region等;在業(yè)務(wù)低峰期執(zhí)行major_compact提升數(shù)據(jù)本地率
HBase讀性能優(yōu)化歸納
讀延遲較大無(wú)非三種常見的表象,單個(gè)業(yè)務(wù)慢、集群隨機(jī)讀慢以及某個(gè)業(yè)務(wù)隨機(jī)讀之后其他業(yè)務(wù)受到影響導(dǎo)致隨機(jī)讀延遲很大。了解完常見的可能導(dǎo)致讀延遲較大的一些問(wèn)題之后,我們將這些問(wèn)題進(jìn)行如下歸類,大家可以在看到現(xiàn)象之后在對(duì)應(yīng)的問(wèn)題列表中進(jìn)行具體定位:


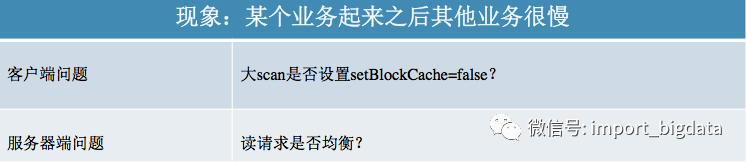
寫優(yōu)化
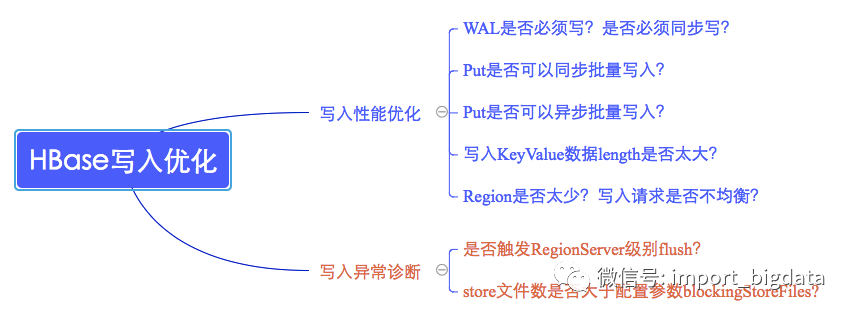
和讀相比,HBase寫數(shù)據(jù)流程倒是顯得很簡(jiǎn)單:數(shù)據(jù)先順序?qū)懭際Log,再寫入對(duì)應(yīng)的緩存Memstore,當(dāng)Memstore中數(shù)據(jù)大小達(dá)到一定閾值(128M)之后,系統(tǒng)會(huì)異步將Memstore中數(shù)據(jù)flush到HDFS形成小文件。HBase數(shù)據(jù)寫入通常會(huì)遇到兩類問(wèn)題,一類是寫性能較差,另一類是數(shù)據(jù)根本寫不進(jìn)去。這兩類問(wèn)題的切入點(diǎn)也不盡相同,如下圖所示:
優(yōu)化原理:數(shù)據(jù)寫入流程可以理解為一次順序?qū)慦AL+一次寫緩存,通常情況下寫緩存延遲很低,因此提升寫性能就只能從WAL入手。WAL機(jī)制一方面是為了確保數(shù)據(jù)即使寫入緩存丟失也可以恢復(fù),另一方面是為了集群之間異步復(fù)制。默認(rèn)WAL機(jī)制開啟且使用同步機(jī)制寫入WAL。首先考慮業(yè)務(wù)是否需要寫WAL,通常情況下大多數(shù)業(yè)務(wù)都會(huì)開啟WAL機(jī)制(默認(rèn)),但是對(duì)于部分業(yè)務(wù)可能并不特別關(guān)心異常情況下部分?jǐn)?shù)據(jù)的丟失,而更關(guān)心數(shù)據(jù)寫入吞吐量,比如某些推薦業(yè)務(wù),這類業(yè)務(wù)即使丟失一部分用戶行為數(shù)據(jù)可能對(duì)推薦結(jié)果并不構(gòu)成很大影響,但是對(duì)于寫入吞吐量要求很高,不能造成數(shù)據(jù)隊(duì)列阻塞。這種場(chǎng)景下可以考慮關(guān)閉WAL寫入,寫入吞吐量可以提升2x~3x。退而求其次,有些業(yè)務(wù)不能接受不寫WAL,但可以接受WAL異步寫入,也是可以考慮優(yōu)化的,通常也會(huì)帶來(lái)1x~2x的性能提升。
優(yōu)化推薦:根據(jù)業(yè)務(wù)關(guān)注點(diǎn)在WAL機(jī)制與寫入吞吐量之間做出選擇
其他注意點(diǎn):對(duì)于使用Increment操作的業(yè)務(wù),WAL可以設(shè)置關(guān)閉,也可以設(shè)置異步寫入,方法同Put類似。相信大多數(shù)Increment操作業(yè)務(wù)對(duì)WAL可能都不是那么敏感~
優(yōu)化原理:HBase分別提供了單條put以及批量put的API接口,使用批量put接口可以減少客戶端到RegionServer之間的RPC連接數(shù),提高寫入性能。另外需要注意的是,批量put請(qǐng)求要么全部成功返回,要么拋出異常。
優(yōu)化建議:使用批量put進(jìn)行寫入請(qǐng)求
優(yōu)化原理:業(yè)務(wù)如果可以接受異常情況下少量數(shù)據(jù)丟失的話,還可以使用異步批量提交的方式提交請(qǐng)求。提交分為兩階段執(zhí)行:用戶提交寫請(qǐng)求之后,數(shù)據(jù)會(huì)寫入客戶端緩存,并返回用戶寫入成功;當(dāng)客戶端緩存達(dá)到閾值(默認(rèn)2M)之后批量提交給RegionServer。需要注意的是,在某些情況下客戶端異常的情況下緩存數(shù)據(jù)有可能丟失。
優(yōu)化建議:在業(yè)務(wù)可以接受的情況下開啟異步批量提交
優(yōu)化原理:當(dāng)前集群中表的Region個(gè)數(shù)如果小于RegionServer個(gè)數(shù),即Num(Region of Table) < Num(RegionServer),可以考慮切分Region并盡可能分布到不同RegionServer來(lái)提高系統(tǒng)請(qǐng)求并發(fā)度,如果Num(Region of Table) > Num(RegionServer),再增加Region個(gè)數(shù)效果并不明顯。
優(yōu)化建議:在Num(Region of Table) < Num(RegionServer)的場(chǎng)景下切分部分請(qǐng)求負(fù)載高的Region并遷移到其他RegionServer;
優(yōu)化原理:另一個(gè)需要考慮的問(wèn)題是寫入請(qǐng)求是否均衡,如果不均衡,一方面會(huì)導(dǎo)致系統(tǒng)并發(fā)度較低,另一方面也有可能造成部分節(jié)點(diǎn)負(fù)載很高,進(jìn)而影響其他業(yè)務(wù)。分布式系統(tǒng)中特別害怕一個(gè)節(jié)點(diǎn)負(fù)載很高的情況,一個(gè)節(jié)點(diǎn)負(fù)載很高可能會(huì)拖慢整個(gè)集群,這是因?yàn)楹芏鄻I(yè)務(wù)會(huì)使用Mutli批量提交讀寫請(qǐng)求,一旦其中一部分請(qǐng)求落到該節(jié)點(diǎn)無(wú)法得到及時(shí)響應(yīng),就會(huì)導(dǎo)致整個(gè)批量請(qǐng)求超時(shí)。因此不怕節(jié)點(diǎn)宕掉,就怕節(jié)點(diǎn)奄奄一息!
優(yōu)化建議:檢查RowKey設(shè)計(jì)以及預(yù)分區(qū)策略,保證寫入請(qǐng)求均衡。
6. 寫入KeyValue數(shù)據(jù)是否太大?
KeyValue大小對(duì)寫入性能的影響巨大,一旦遇到寫入性能比較差的情況,需要考慮是否由于寫入KeyValue數(shù)據(jù)太大導(dǎo)致。KeyValue大小對(duì)寫入性能影響曲線圖如下:
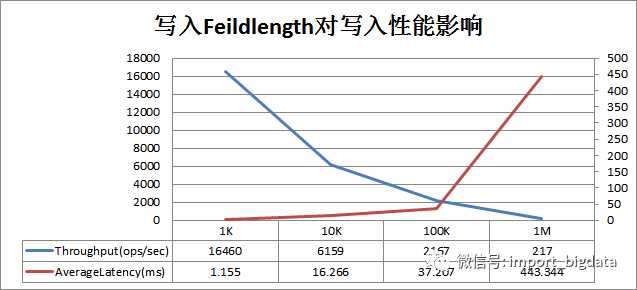
圖中橫坐標(biāo)是寫入的一行數(shù)據(jù)(每行數(shù)據(jù)10列)大小,左縱坐標(biāo)是寫入吞吐量,右坐標(biāo)是寫入平均延遲(ms)。可以看出隨著單行數(shù)據(jù)大小不斷變大,寫入吞吐量急劇下降,寫入延遲在100K之后急劇增大。
說(shuō)到這里,有必要和大家分享兩起在生產(chǎn)線環(huán)境因?yàn)闃I(yè)務(wù)KeyValue較大導(dǎo)致的嚴(yán)重問(wèn)題,一起是因?yàn)榇笞侄螛I(yè)務(wù)寫入導(dǎo)致其他業(yè)務(wù)吞吐量急劇下降,另一起是因?yàn)榇笞侄螛I(yè)務(wù)scan導(dǎo)致RegionServer宕機(jī)。
上述幾點(diǎn)主要針對(duì)寫性能優(yōu)化進(jìn)行了介紹,除此之外,在一些情況下還會(huì)出現(xiàn)寫異常,一旦發(fā)生需要考慮下面兩種情況(GC引起的不做介紹):Memstore設(shè)置是否會(huì)觸發(fā)Region級(jí)別或者RegionServer級(jí)別flush操作?
問(wèn)題解析:以RegionServer級(jí)別flush進(jìn)行解析,HBase設(shè)定一旦整個(gè)RegionServer上所有Memstore占用內(nèi)存大小總和大于配置文件中upperlimit時(shí),系統(tǒng)就會(huì)執(zhí)行RegionServer級(jí)別flush,flush算法會(huì)首先按照Region大小進(jìn)行排序,再按照該順序依次進(jìn)行flush,直至總Memstore大小低至lowerlimit。這種flush通常會(huì)block較長(zhǎng)時(shí)間,在日志中會(huì)發(fā)現(xiàn)“Memstore is above high water mark and block 7452 ms”,表示這次flush將會(huì)阻塞7s左右。
Region規(guī)模與Memstore總大小設(shè)置是否合理?如果RegionServer上Region較多,而Memstore總大小設(shè)置的很小(JVM設(shè)置較小或者upper.limit設(shè)置較小),就會(huì)觸發(fā)RegionServer級(jí)別flush。
列族是否設(shè)置過(guò)多,通常情況下表列族建議設(shè)置在1~3個(gè)之間,最好一個(gè)。如果設(shè)置過(guò)多,會(huì)導(dǎo)致一個(gè)Region中包含很多Memstore,導(dǎo)致更容易觸到高水位upperlimit。
Store中HFile數(shù)量是否大于配置參數(shù)blockingStoreFile?
問(wèn)題解析:對(duì)于數(shù)據(jù)寫入很快的集群,還需要特別關(guān)注一個(gè)參數(shù):hbase.hstore.blockingStoreFiles,此參數(shù)表示如果當(dāng)前hstore中文件數(shù)大于該值,系統(tǒng)將會(huì)強(qiáng)制執(zhí)行compaction操作進(jìn)行文件合并,合并的過(guò)程會(huì)阻塞整個(gè)hstore的寫入。通常情況下該場(chǎng)景發(fā)生在數(shù)據(jù)寫入很快的情況下,在日志中可以發(fā)現(xiàn)”Waited 3722ms on a compaction to clean up ‘too many store files“
問(wèn)題檢查點(diǎn):參數(shù)設(shè)置是否合理?hbase.hstore.compactionThreshold表示啟動(dòng)compaction的最低閾值,該值不能太大,否則會(huì)積累太多文件,一般建議設(shè)置為5~8左右。hbase.hstore.blockingStoreFiles默認(rèn)設(shè)置為7,可以適當(dāng)調(diào)大一些。
其他
最后我們講一講一些容易忽視的優(yōu)化點(diǎn):
使用壓縮
HBase支持大量的壓縮算法,可以從列簇級(jí)別上進(jìn)行壓縮。因?yàn)镃PU壓縮和解壓縮消耗的時(shí)間往往比從磁盤讀取和寫入數(shù)據(jù)要快得多,所以使用壓縮通常會(huì)帶來(lái)很可觀的性能提升

大家可以自行百度關(guān)于壓縮算法在HBase中的集成安裝,HBase包含一個(gè)能夠測(cè)試壓縮設(shè)置是否正常的工具,我們可以輸入:
./bin/hbase org.apache.hadoop.hbase.util.CompresstionTest
然后啟用檢查,因?yàn)榧词箿y(cè)試工具報(bào)告成功了,由于JNI需要先安裝好本地庫(kù),如果缺失這一步將會(huì)在添加新服務(wù)器的時(shí)候出現(xiàn)問(wèn)題,導(dǎo)致新的服務(wù)器使用本地庫(kù)打開含有壓縮列族的region失敗。
我們可以在服務(wù)器啟動(dòng)的時(shí)候檢查壓縮庫(kù)是否已經(jīng)正確安裝,如果沒(méi)有則不會(huì)啟動(dòng)服務(wù)器:
hbase.regionserver.codecs
snappy,lzo
這樣一來(lái)region服務(wù)器在啟動(dòng)的時(shí)候?qū)?huì)檢查Snappy和LZO壓縮庫(kù)是否已經(jīng)正確安裝
我們可以通過(guò)shell創(chuàng)建表的時(shí)候指定列族的壓縮格式:
create 'testtable',{NAME => 'colfam1',COMPRESSION => 'GZ'}
需要注意的是,如果用戶要更改一個(gè)已經(jīng)存在的表的壓縮格式,要先將該表disable才能修改之后再enable重新上線。并且更改后的region只有在刷寫存儲(chǔ)文件的時(shí)候才會(huì)使用新的壓縮格式,沒(méi)有刷寫之前保持原樣,用戶可以通過(guò)shell的major_compact 來(lái)強(qiáng)制格式重寫,但是此操作會(huì)占用大量資源。
使用掃描緩存
如果HBase作為一個(gè)MapReduce作業(yè)的而輸入源,最好將MapReduce作業(yè)的輸入掃描器實(shí)例的緩存用setCaching()設(shè)置為比1大的多的值。例如設(shè)置為500的時(shí)候則一次可以傳送500行數(shù)據(jù)到客戶端進(jìn)行處理。
限定掃描范圍
如果只處理少數(shù)列,則應(yīng)當(dāng)只有這些列被添加到Scan的輸入中,因?yàn)槿绻麤](méi)有做篩選,則會(huì)掃描其他的數(shù)據(jù)存儲(chǔ)文件。
關(guān)閉ResultScanner
這不會(huì)帶來(lái)性能提升,但是會(huì)避免一些性能問(wèn)題。所以一定要在try/catch中關(guān)閉ResultScanner。
參考文檔
https:https:https:https:https:https:
--end--
可私聊交流,也可進(jìn)資源豐富學(xué)習(xí)群
更文不易,點(diǎn)個(gè)“在看”支持一下??
