玩ElasticSearch,還得靠SQL

ES7.x版本的x-pack自帶ElasticSearch SQL,我們可以直接通過SQL REST API、SQL CLI等方式使用SQL查詢。
SQL REST API
在Kibana Console中輸入:
POST?/_sql?format=txt
{
??"query":?"SELECT?*?FROM?library?ORDER?BY?page_count?DESC?LIMIT?5"
}
將上述SQL替換為你自己的SQL語句,即可。返回格式如下:
????author??????|????????name????????|??page_count???|?release_date
-----------------+--------------------+---------------+------------------------
Peter?F.?Hamilton|Pandora's?Star??????|768????????????|2004-03-02T00:00:00.000Z
Vernor?Vinge?????|A?Fire?Upon?the?Deep|613????????????|1992-06-01T00:00:00.000Z
Frank?Herbert????|Dune????????????????|604????????????|1965-06-01T00:00:00.000Z
SQL CLI
elasticsearch-sql-cli是安裝ES時(shí)bin目錄的一個(gè)腳本文件,也可單獨(dú)下載。我們?cè)贓S目錄運(yùn)行
./bin/elasticsearch-sql-cli?https://some.server:9200
輸入sql即可查詢
sql>?SELECT?*?FROM?library?WHERE?page_count?>?500?ORDER?BY?page_count?DESC;
?????author??????|????????name????????|??page_count???|?release_date
-----------------+--------------------+---------------+---------------
Peter?F.?Hamilton|Pandora's?Star??????|768????????????|1078185600000
Vernor?Vinge?????|A?Fire?Upon?the?Deep|613????????????|707356800000
Frank?Herbert????|Dune????????????????|604????????????|-144720000000
SQL To DSL
在Kibana輸入:
POST?/_sql/translate
{
??"query":?"SELECT?*?FROM?library?ORDER?BY?page_count?DESC",
??"fetch_size":?10
}
即可得到轉(zhuǎn)化后的DSL query:
{
??"size":?10,
??"docvalue_fields":?[
????{
??????"field":?"release_date",
??????"format":?"epoch_millis"
????}
??],
??"_source":?{
????"includes":?[
??????"author",
??????"name",
??????"page_count"
????],
????"excludes":?[]
??},
??"sort":?[
????{
??????"page_count":?{
????????"order":?"desc",
????????"missing":?"_first",
????????"unmapped_type":?"short"
??????}
????}
??]
}
因?yàn)椴樵兿嚓P(guān)的語句已經(jīng)生成,我們只需要在這個(gè)基礎(chǔ)上適當(dāng)修改或不修改就可以愉快使用DSL了。
下面我們?cè)敿?xì)介紹下ES SQL 支持的SQL語句 和 如何避免錯(cuò)誤使用。
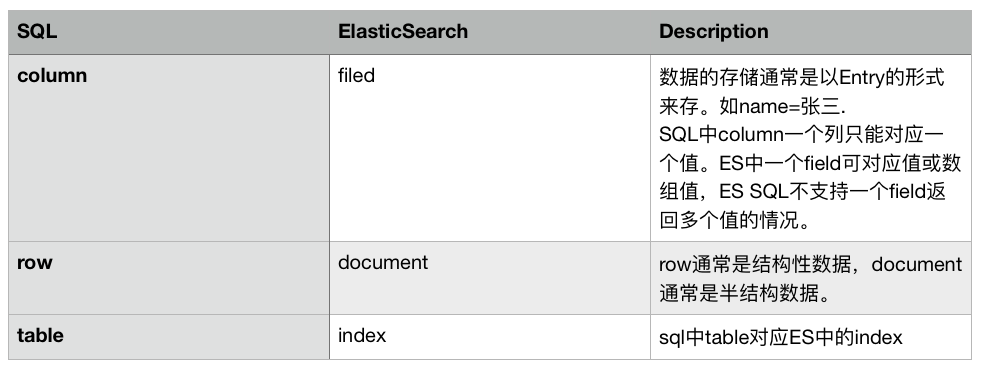
首先需要了解下ES SQL支持的SQL語句中,SQL術(shù)語和ES術(shù)語的對(duì)應(yīng)關(guān)系:
ES SQL的語法支持大多遵循ANSI SQL標(biāo)準(zhǔn),支持的SQL語句有DML查詢和部分DDL查詢。
DDL查詢?nèi)纾?/span>DESCRIBE table,SHOW COLUMNS IN table略顯雞肋,我們主要看下對(duì)SELECT,Function的DML查詢支持。
SELECT
語法結(jié)構(gòu)如下:
SELECT?[TOP?[?count?]?]?select_expr?[,?...]
[?FROM?table_name?]
[?WHERE?condition?]
[?GROUP?BY?grouping_element?[,?...]?]
[?HAVING?condition]
[?ORDER?BY?expression?[?ASC?|?DESC?]?[,?...]?]
[?LIMIT?[?count?]?]
[?PIVOT?(?aggregation_expr?FOR?column?IN?(?value?[?[?AS?]?alias?]?[,?...]?)?)?]
表示從0-N個(gè)表中獲取行數(shù)據(jù)。SQL的執(zhí)行順序?yàn)椋?/span>
獲取所有
FROM中的關(guān)鍵詞,確定表名。如果有
WHERE條件,過濾掉所有不符合的行。如果有
GROUP BY條件,則分組聚合;如果有HAVING條件,則過濾聚合的結(jié)果。上一步得到的結(jié)果經(jīng)過
select_expr運(yùn)算,確定具體返回的數(shù)據(jù)。如果有
ORDER BY條件,會(huì)對(duì)返回的數(shù)據(jù)排序。如果有
LIMITorTOP條件,會(huì)返回上一步結(jié)果的子集。
與常用的SQL有兩點(diǎn)不同,ES SQL 支持
TOP [ count ]和PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) )子句。TOP [ count ]:如SELECT TOP 2 first_name FROM emp表示最多返回兩條數(shù)據(jù),不可與LIMIT條件共用。PIVOT子句會(huì)對(duì)其聚合條件得到的結(jié)果進(jìn)行行轉(zhuǎn)列,進(jìn)一步運(yùn)算。這個(gè)我是沒用過,不做介紹。
FUNCTION
基于上面的SQL我們其實(shí)已經(jīng)能有過濾,聚合,排序,分頁功能的SQL了。但是我們需要進(jìn)一步了解ES SQL中FUNCTION的支持,才能寫出豐富的具有全文搜索,聚合,分組功能的SQL。
使用SHOW FUNCTIONS 可列舉出支持的函數(shù)名稱和所屬類型。
SHOW?FUNCTIONS;
??????name???????|?????type
-----------------+---------------
AVG??????????????|AGGREGATE
COUNT????????????|AGGREGATE
FIRST????????????|AGGREGATE
FIRST_VALUE??????|AGGREGATE
LAST?????????????|AGGREGATE
LAST_VALUE???????|AGGREGATE
MAX??????????????|AGGREGATE
MIN??????????????|AGGREGATE
SUM??????????????|AGGREGATE
........
我們主要看下聚合,分組,全文搜索相關(guān)的常用函數(shù)。
全文匹配函數(shù)
MATCH:相當(dāng)于DSL中的match and multi_match查詢。
MATCH(
????field_exp,???????--字段名稱
????constant_exp,???????--字段的匹配值
????[,?options])???????--可選項(xiàng)
使用舉例:
SELECT?author,?name?FROM?library?WHERE?MATCH(author,?'frank');
????author?????|???????name
---------------+-------------------
Frank?Herbert??|Dune
Frank?Herbert??|Dune?Messiah
SELECT?author,?name,?SCORE()?FROM?library?WHERE?MATCH('author^2,name^5',?'frank?dune');
????author?????|???????name????????|????SCORE()
---------------+-------------------+---------------
Frank?Herbert??|Dune???????????????|11.443176
Frank?Herbert??|Dune?Messiah???????|9.446629
QUERY:相當(dāng)于DSL中的 query_string 查詢。
QUERY(
????constant_exp??????--匹配值表達(dá)式
????[,?options])???????--可選項(xiàng)
使用舉例:
SELECT?author,?name,?page_count,?SCORE()?FROM?library?WHERE?QUERY('_exists_:"author"?AND?page_count:>200?AND?(name:/star.*/?OR?name:duna~)');
??????author??????|???????name????????|??page_count???|????SCORE()
------------------+-------------------+---------------+---------------
Frank?Herbert?????|Dune???????????????|604????????????|3.7164764
Frank?Herbert?????|Dune?Messiah???????|331????????????|3.4169943
SCORE():返回輸入數(shù)據(jù)和返回?cái)?shù)據(jù)的相關(guān)度relevance.
使用舉例:
SELECT?SCORE(),?*?FROM?library?WHERE?MATCH(name,?'dune')?ORDER?BY?SCORE()?DESC;
????SCORE()????|????author?????|???????name????????|??page_count???|????release_date
---------------+---------------+-------------------+---------------+--------------------
2.2886353??????|Frank?Herbert??|Dune???????????????|604????????????|1965-06-01T00:00:00Z
1.8893257??????|Frank?Herbert??|Dune?Messiah???????|331????????????|1969-10-15T00:00:00Z
聚合函數(shù)
AVG(numeric_field) :計(jì)算數(shù)字類型的字段的平均值。
SELECT?AVG(salary)?AS?avg?FROM?emp;
COUNT(expression):返回輸入數(shù)據(jù)的總數(shù),包括COUNT(COUNT(ALL field_name):返回輸入數(shù)據(jù)的總數(shù),不包括field_name對(duì)應(yīng)的值為null的數(shù)據(jù)。COUNT(DISTINCT field_name):返回輸入數(shù)據(jù)中field_name對(duì)應(yīng)的值不為null的總數(shù)。SUM(field_name):返回輸入數(shù)據(jù)中數(shù)字字段field_name對(duì)應(yīng)的值的總和。MIN(field_name):返回輸入數(shù)據(jù)中數(shù)字字段field_name對(duì)應(yīng)的值的最小值。MAX(field_name):返回輸入數(shù)據(jù)中數(shù)字字段field_name對(duì)應(yīng)的值的最大值。
分組函數(shù)
這里的分組函數(shù)是對(duì)應(yīng)DSL中的bucket分組。
HISTOGRAM:語法如下:
HISTOGRAM(
???????????numeric_exp,????--數(shù)字表達(dá)式,通常是一個(gè)field_name
???????????numeric_interval????--數(shù)字的區(qū)間值
)
HISTOGRAM(
???????????date_exp,??????--date/time表達(dá)式,通常是一個(gè)field_name
???????????date_time_interval??????--date/time的區(qū)間值
)
如下返回每年1月1號(hào)凌晨出生的數(shù)據(jù):
ELECT?HISTOGRAM(birth_date,?INTERVAL?1?YEAR)?AS?h,?COUNT(*)?AS?c?FROM?emp?GROUP?BY?h;
???????????h????????????|???????c
------------------------+---------------
null????????????????????|10
1952-01-01T00:00:00.000Z|8
1953-01-01T00:00:00.000Z|11
1954-01-01T00:00:00.000Z|8
1955-01-01T00:00:00.000Z|4
1956-01-01T00:00:00.000Z|5
1957-01-01T00:00:00.000Z|4
1958-01-01T00:00:00.000Z|7
1959-01-01T00:00:00.000Z|9
1960-01-01T00:00:00.000Z|8
1961-01-01T00:00:00.000Z|8
1962-01-01T00:00:00.000Z|6
1963-01-01T00:00:00.000Z|7
1964-01-01T00:00:00.000Z|4
1965-01-01T00:00:00.000Z|1
ES SQL局限性
因?yàn)镋S SQL和ES DSL在功能上并非完全匹配,官方文檔提到的SQL局限性有:
大的查詢可能拋ParsingException
在解析階段,極大的查詢會(huì)占用過多的內(nèi)存,在這種情況下,Elasticsearch SQL引擎將中止解析并拋出錯(cuò)誤。
nested類型字段的表示方法
SQL中不支持nested類型的字段,只能使用
[nested_field_name].[sub_field_name]
這種形式來引用內(nèi)嵌子字段。
使用舉例:
SELECT?dep.dep_name.keyword?FROM?test_emp?GROUP?BY?languages;
nested類型字段不能用在where 和 order by 的Scalar函數(shù)上
如以下SQL都是錯(cuò)誤的
SELECT?*?FROM?test_emp?WHERE?LENGTH(dep.dep_name.keyword)?>?5;
SELECT?*?FROM?test_emp?ORDER?BY?YEAR(dep.start_date);
不支持多個(gè)nested字段的同時(shí)查詢
如嵌套字段nested_A和nested_B無法同時(shí)使用。
nested內(nèi)層字段分頁限制
當(dāng)分頁查詢有nested字段時(shí),分頁結(jié)果可能不正確。這是因?yàn)椋篍S中的分頁查詢發(fā)生在Root nested document上,而不是它的內(nèi)層字段上。
keyword類型的字段不支持normalizer
不支持?jǐn)?shù)組類型的字段
這是因?yàn)樵赟QL中一個(gè)field只對(duì)應(yīng)一個(gè)值,這種情況下我們可以使用上面介紹的 SQL To DSL的API 轉(zhuǎn)化為DSL語句,用DSL查詢就好了。
聚合排序的限制
排序字段必須是聚合桶中的字段,ES SQL CLI突破了這種限制,但上限不能超過512行,否則在sorting階段會(huì)拋異常。推薦搭配
Limit子句使用,如:
SELECT?*?FROM?test?GROUP?BY?age?ORDER?BY?COUNT(*)?LIMIT?100;
聚合排序的排序條件不支持Scalar函數(shù)或者簡單的操作符運(yùn)算。聚合后的復(fù)雜字段(比如包含聚合函數(shù))也是不能用在排序條件上的。
以下是錯(cuò)誤例子:
SELECT?age,?ROUND(AVG(salary))?AS?avg?FROM?test?GROUP?BY?age?ORDER?BY?avg;
SELECT?age,?MAX(salary)?-?MIN(salary)?AS?diff?FROM?test?GROUP?BY?age?ORDER?BY?diff;
子查詢的限制
子查詢中包含GROUP BY or HAVING 或者比SELECT X
FROM (SELECT ...) WHERE [simple_condition]這種結(jié)構(gòu)復(fù)雜,都是可能執(zhí)行不成功的。
TIME 數(shù)據(jù)類型的字段不支持GROUP BY條件和HISTOGRAM函數(shù)
如以下查詢是錯(cuò)誤的:
SELECT?count(*)?FROM?test?GROUP?BY?CAST(date_created?AS?TIME);
SELECT?HISTOGRAM(CAST(birth_date?AS?TIME),?INTERVAL?'10'?MINUTES)?as?h,?COUNT(*)?FROM?t?GROUP?BY?h
但是將TIME類型的字段包裝為Scalar函數(shù)返回是支持GROUP BY的,如:
SELECT?count(*)?FROM?test?GROUP?BY?MINUTE((CAST(date_created?AS?TIME));
返回字段的限制
如果一個(gè)字段不在source中存儲(chǔ),是無法查詢到的。keyword, date, scaled_float, geo_point, geo_shape這些類型的字段不受這種限制,因?yàn)樗麄儾皇菑?/span>_source中返回,而是從docvalue_fields中返回。