
用Python寫幾行代碼,一分鐘搞定一天工作量,同事直呼:好家伙!

前幾天有一個讀者說最近要整理幾千份文件,頭都要整禿了,不知道能不能用Python解決,我們來看一下,你也可以思考一下。
由于涉及文件私密所以具體內容已做脫敏處理。
大概是這樣,一個文件夾下有多份會議通知信息(本文以 7 份文件為例)
每一份通知打開格式基本類似,如下所示??
現(xiàn)在需要將每份會議文檔中的 學習時間、學習內容、學習形式、主持人 四項關鍵信息提取出來,整理到 Excel 表格中: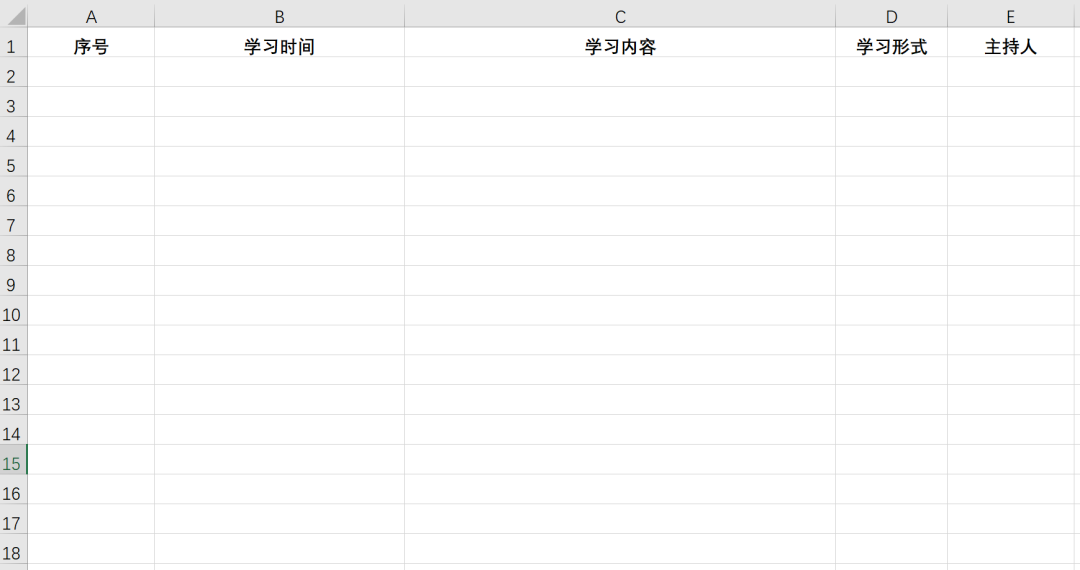
在他真實需求中,會議通知四年積累下來有快 1000 份(四年開了這么多次會也是很厲害...),用人力挨個打開文件并錄到 Excel 中工作量實在太大。
好家伙,這種重復的無聊工作, 不就是一份非常適合交給 Python 的自動化工作嗎?我不允許我的粉絲還不會!
下面我們來看看如何用Python解決這個問題,主要將涉及:
openpyxl寫入 Excel 文件python-docx讀取 Word 文件glob批量獲取文件路徑
為了簡化上面的需求,本文中需要獲取的會議通知文件一共 7 個,分別命名為 會議通知1.docx 會議通知2.docx... 會議通知7.docx,存放在 Notice 文件夾下。輸出的目標 Excel 文件命名為 Meeting_temp.xlsx
基本邏輯
寫代碼之前都先明確完整的問題需要分為幾個小步驟實現(xiàn)。從需求中我們大概可以將代碼分為以下幾步:
“”
獲取會議通知 Notice 文件夾下的所有文件; 解析每一份 Word 文件,獲取需要的四個信息,輸出到 Excel 中; 保存 Excel 文件
有了邏輯就有了寫代碼的思路了。第 1 步可以由 glob 庫完成,后面兩步就是操作 Word 的 python-docx 庫和操作 Excel 的 openpyxl 庫的交互協(xié)作了。
這兩個庫我們都有說過,如果你不熟悉,一定要先閱讀下面的文章!
代碼實現(xiàn)
首先導入需要的庫:
from?docx?import?Document
from?openpyxl?import?load_workbook
import?glob
將模板 Excel 讀取進程序:
path??=?r'C:\Users\xxx'?#?路徑為會議通知文件夾和?Excel?模板所在的位置,可按實際情況更改
workbook?=?load_workbook(path?+?r'\Meeting_temp.xlsx')
sheet?=?workbook.active
寫任何批處理的代碼之前都建議先寫一下單次操作的代碼,因此我們先完成對 會議通知 1.docx 文件的解析,確保無誤。現(xiàn)在對于文檔的結構和關鍵信息的位置尚不明確,可以先將 Word 以段落 Paragraph 為單位輸出觀察:
wordfile?=?Document(path?+?r'\Notice\會議通知?1.docx')
for?paragraph?in?wordfile.paragraphs:
????print(paragraph)

文件的文字排布脈絡比較清晰,基本是一句話對應一個段落,而需要的信息可以簡單通過判斷每句話(每段話)前幾個字而明確:
????for?paragraph?in?wordfile.paragraphs:
????????if?paragraph.text[0:5]?==?'學習時間:':
????????????study_time?=?paragraph.text[5:]
????????if?paragraph.text[0:4]?==?'主持人:':
????????????host?=?paragraph.text[4:]
????????if?paragraph.text[0:5]?==?'學習形式:':
????????????study_type?=?paragraph.text[5:]
對于學習內容的獲取比較特殊,不像其他三個信息,都在一句話中,且關鍵字就為前幾個字:
可以看到,“學習內容” 四個字和真正包含的內容分散在不同的句子中.這里簡單用一個策略:
“建立一個空列表存放,然后遍歷每一段判斷,如果一個字符為數(shù)字且第二個字符為中文頓號
”“、”就獲取存放到列表中。最后把列表中的元素重新組合成一個長字符串即可:
????content_lst?=?[]
????for?paragraph?in?wordfile.paragraphs:
????????if?paragraph.text[0:5]?==?'學習時間:':
????????????study_time?=?paragraph.text[5:]
????????if?paragraph.text[0:4]?==?'主持人:':
????????????host?=?paragraph.text[4:]
????????if?paragraph.text[0:5]?==?'學習形式:':
????????????study_type?=?paragraph.text[5:]
????????if?len(paragraph.text)?>=?2:
????????????if?paragraph.text[0].isdigit()?and?paragraph.text[1]?==?'、':
????????????????content_lst.append(paragraph.text)
????content?=?'?'.join(content_lst)
完成了解析 Word 文件之后,就需要把內容輸出的 Excel 文件中了。
簡單來說,就是將上面代碼獲取到的幾個元素組合成一個列表,通過 sheet.append(list) 的方法寫入 Excel 文件中:
number?=?0?#?全局中設置一個變量用于計數(shù),做為序號輸出
wordfile?=?Document(path?+?r'\Notice\會議通知?1.docx')
content_lst?=?[]
for?paragraph?in?wordfile.paragraphs:
????if?paragraph.text[0:5]?==?'學習時間:':
????????study_time?=?paragraph.text[5:]
????if?paragraph.text[0:4]?==?'主持人:':
????????host?=?paragraph.text[4:]
????if?paragraph.text[0:5]?==?'學習形式:':
????????study_type?=?paragraph.text[5:]
????if?len(paragraph.text)?>=?2:
????????if?paragraph.text[0].isdigit()?and?paragraph.text[1]?==?'、':
????????????content_lst.append(paragraph.text)
content?=?'?'.join(content_lst)
number?+=?1
sheet.append([number,?study_time,?content,?study_type,?host])
單個文件解析完,用 glob 改完獲取文件夾下全部文件,建立循環(huán)逐個解析就能完成本需求,當然最后記得保存 Excel 文件。
完整代碼如下??
from?docx?import?Document
from?openpyxl?import?load_workbook
import?glob
path??=?r'C:\Users\xxx'
workbook?=?load_workbook(path?+?r'\Meeting_temp.xlsx')
sheet?=?workbook.active
number?=?0
for?file?in?glob.glob(path?+?r'\Notice\*.docx'):
????wordfile?=?Document(file)
????content_lst?=?[]
????for?paragraph?in?wordfile.paragraphs:
????????if?paragraph.text[0:5]?==?'學習時間:':
????????????study_time?=?paragraph.text[5:]
????????if?paragraph.text[0:4]?==?'主持人:':
????????????host?=?paragraph.text[4:]
????????if?paragraph.text[0:5]?==?'學習形式:':
????????????study_type?=?paragraph.text[5:]
????????if?len(paragraph.text)?>=?2:
????????????if?paragraph.text[0].isdigit()?and?paragraph.text[1]?==?'、':
????????????????content_lst.append(paragraph.text)
????content?=?'?'.join(content_lst)
????number?+=?1
????sheet.append([number,?study_time,?content,?study_type,?host])
workbook.save(path?+?r'\Meeting_notice.xlsx')
核心也不過三十行代碼,總共不過三秒就搞定了!
戀習Python 關注戀習Python,Python都好練 好文章,我在看??