
億級流量實驗平臺設(shè)計實踐
關(guān)注公眾號:【蟲爸說說】, 回復(fù)[資料],免費獲取
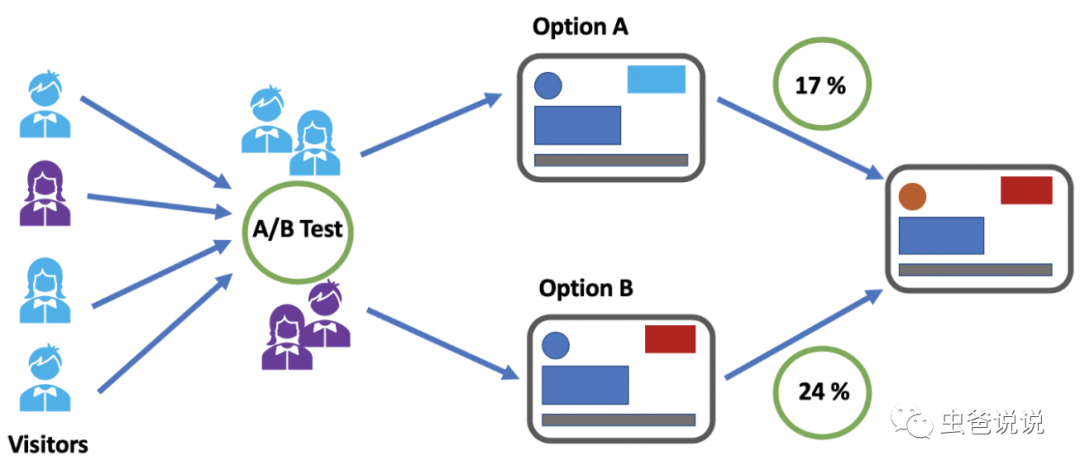
大家好,我是蟲爸。今天給大家分享一款億級流量實驗平臺。在互聯(lián)網(wǎng)行業(yè),要上線一個策略(CTR預(yù)估、CVR預(yù)估等),或者一個功能,如果貿(mào)然全量上線,那么如果新策略效果不佳,可能會造成不小的損失,要么丟失用戶,要么損失收入。
那么怎樣才能避免此問題發(fā)生呢?這就引入了實驗平臺,通過對流量打標(biāo)簽,然后分析實驗效果,從而再決定是否實驗推全還是下線。
一、概念
實驗平臺,從字面意思來看,就是一個用來做實驗的平臺。其 基本原理 就是把流量進(jìn)行分流,特定流量,匹配特定策略。不同批次的用戶,看到的不同的策略。然后通過曝光、點擊等數(shù)據(jù)進(jìn)行統(tǒng)計分析,得出實驗效果的好壞,從而決定是否推全該實驗。
換句話說,就是為同一個目標(biāo)制定兩個方案(比如兩個頁面),將產(chǎn)品的用戶流量根據(jù)特定策略分割成 A/B 兩組,一組實驗組,一組對照組,兩組實驗同時運行一段時間后分別統(tǒng)計兩組用戶的表現(xiàn),再將相關(guān)結(jié)果數(shù)據(jù)(比如 pv/uv、商機轉(zhuǎn)化率等)進(jìn)行對比,就可以科學(xué)地幫助決策。
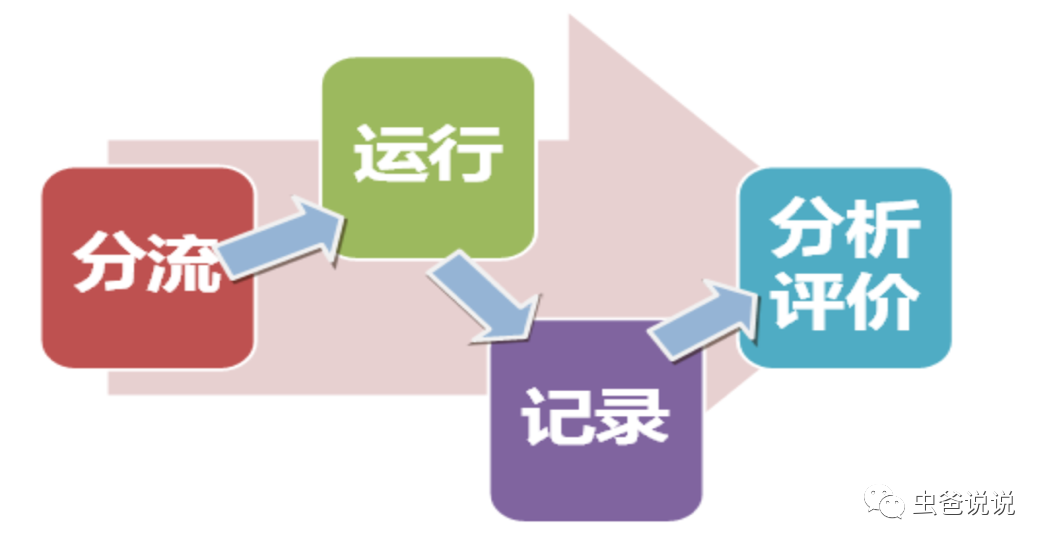
通過對流量進(jìn)行分流,運行實驗,統(tǒng)計實驗數(shù)據(jù),進(jìn)行數(shù)據(jù)分析,然后得出實驗效果。如下圖所示:
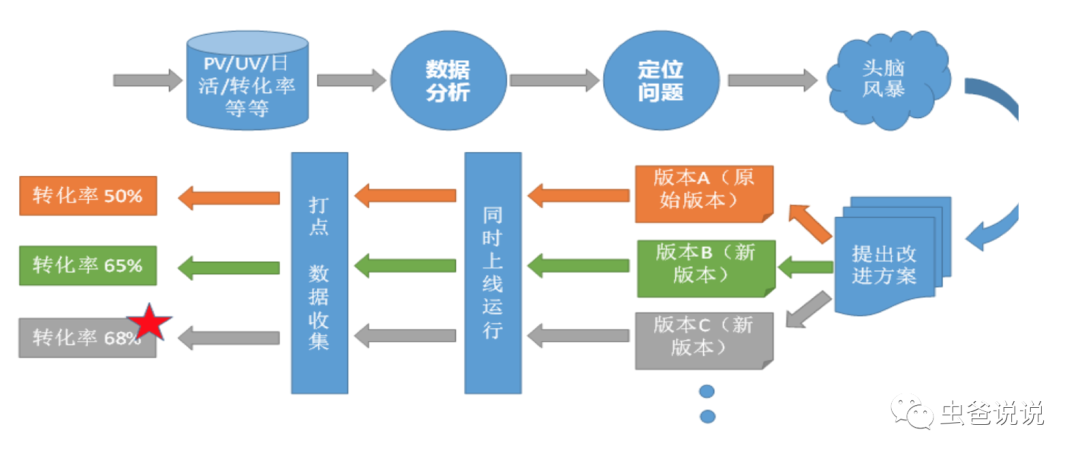
再根據(jù)實驗效果,進(jìn)行反向數(shù)據(jù)分析,定位出實驗效果不好的源,進(jìn)行頭腦風(fēng)暴,再次做實驗,從而最終達(dá)到理想的實驗?zāi)康摹H缦聢D所示:
二、分層實驗?zāi)P?/h2>
在進(jìn)行實驗平臺講解之前,先介紹下實驗平臺的理論基礎(chǔ),以便大家能夠更好的理解后面的內(nèi)容。
現(xiàn)在業(yè)界大部分實驗平臺,都基于谷歌2017年的一篇論文《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》,其模型架構(gòu)如下圖所示:

在該模型中,有幾個概念:
域(domain):劃分的一部分流量 層(layer):系統(tǒng)參數(shù)的一個子集 實驗(exp):在一個域上,對一個或者多個參數(shù)修改,都將影響效果 流量在每個層被打散(分配函數(shù)),層與層之間流量正交
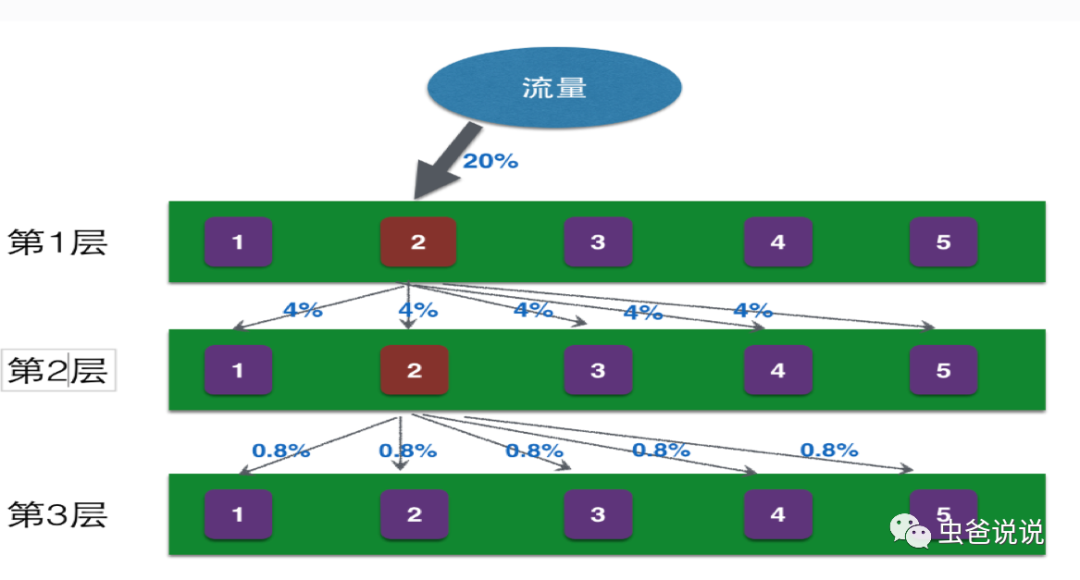
下圖【圖四】為筆者線上實驗的一個簡略圖,在該圖中,總共有三個實驗層,分別為CTR預(yù)估層,用戶畫像層和頻次策略層。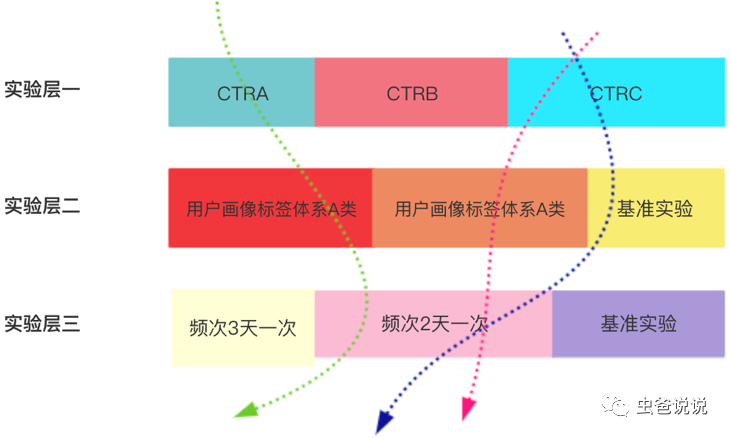
從圖四可以看到,流量在層之間穿梭,而一個流量只能命中一個層中的一個實驗,一個流量請求過程可能會命中多個層中的多個實驗(每層命中一個實驗)。
使用分層實驗?zāi)P停枰獫M足以下幾點:
相關(guān)聯(lián)的策略參數(shù)位于同一實驗層(即都是做CTR預(yù)估,那么CTR預(yù)估相關(guān)的實驗,就放在同一層,即CTR預(yù)估層,以方便做實驗對比) 相互獨立的策略參數(shù)分屬于不同的實驗層(如上圖中 ,CTR預(yù)估的實驗和頻次實驗是兩種性質(zhì)不同的實驗,因此要放在兩層來實現(xiàn),如果在一層的話,由于實驗性質(zhì)不同,難以比較實驗效果) 一個流量只能命中一個層中的一個實驗 層之間的流量正交,不會互相影響(即層與層之間的實驗不會互相影響,如【圖五】)
使用該分層模型作為實驗平臺理論基礎(chǔ)的好處有以下幾點:
可以作為一個獨立的部分,不與系統(tǒng)中的其他業(yè)務(wù)或者功能相互 影響 每一層流量都是100%的全量,可以避免流量切分過細(xì),保證實驗間的可對比性、客觀性 層與層之間,流量獨立正交,不會互相影響
三、功能特點
一個可用或者完善的實驗平臺,需要有以下幾個功能:
支持多實驗并發(fā)迭代 支持白名單體驗 提供便捷的管理工具 便捷的查看實驗效果分析數(shù)據(jù) 支持實驗的切流和關(guān)閉 保證線上實驗安全性 支持實驗推全 支持功能定制化
下面,我們將從幾個功能點出發(fā),詳細(xì)講述各個功能的原理。
支持多實驗并發(fā)迭代,指的是一個完善的實驗平臺,在功能上,需要支持多個實驗同時運行(包括同一層和不同層之間)。
支持白名單體驗:因為實驗分流有自己的策略,創(chuàng)建實驗的用戶不一定能夠命中這個實驗,而白名單的功能就是讓在白名單的用戶能夠每次都命中該實驗。
便捷的管理工具:這個指的是實驗后臺,一個實驗后臺需要能夠創(chuàng)建實驗,打開關(guān)閉實驗等
查看實驗效果分析數(shù)據(jù):判斷一個實驗效果的好壞,就是通過實驗標(biāo)簽分析實驗數(shù)據(jù),能夠很直觀的觀察到實驗效果,從進(jìn)行下一步實驗決策
實驗的切流和關(guān)閉:實驗的切流,指的是該實驗需要一定百分比的流量進(jìn)行實驗,而實驗關(guān)閉,則指的是停掉該實驗
支持線上安全性:實驗平臺,本身就是起錦上添花的作用,其只是用來打?qū)嶒灅?biāo)簽的,不可本末倒置,影響了線上業(yè)務(wù)的正常功能
支持實驗推全:一個實驗效果如果好的話,就需要將全部的流量都命中該實驗,而實驗推全就是達(dá)到此效果
支持功能定制:沒有一個實驗平臺能夠滿足不同公司,甚至同一個公司不同部門之間的業(yè)務(wù)需求,但是,為了盡可能的向這個目標(biāo)靠攏,實驗平臺需要盡可能的靈活,低耦合,能夠盡量的配置化。
四、架構(gòu)及模塊
實驗平臺必備的三個模塊,分別為:
管理后臺 實驗后臺 分流平臺
管理后臺主要是管理實驗的,包括創(chuàng)建和停止實驗等。
實驗后臺與管理后臺進(jìn)行數(shù)據(jù)上的交互,將管理后臺的消息轉(zhuǎn)換成特有的消息,進(jìn)行轉(zhuǎn)發(fā)和持久化。
分流平臺,其一接收實驗后臺的實驗消息建立內(nèi)部維度索引,其二接收線上流量,根據(jù)流量屬性,給流量打上對應(yīng)的標(biāo)簽。

上圖,是一個實驗平臺架構(gòu)圖,下面從創(chuàng)建實驗角度,和流量的角度進(jìn)行講解。
創(chuàng)建實驗角度:
1、在管理后臺創(chuàng)建對應(yīng)的實驗
2、管理后臺將創(chuàng)建的實驗信息發(fā)送給實驗后臺
3、實驗后臺將實驗首先發(fā)送至消息系統(tǒng)(kafka等),然后將實驗落地持久化(DB)
4、分流平臺消耗消息系統(tǒng)中的實驗消息,加載至內(nèi)存
流量角度:
1、 流量攜帶其基本屬性(用戶畫像,app信息等)請求分流平臺
2、 分流平臺根據(jù)流量屬性,進(jìn)行定制化匹配,然后使用分流算法,計算實驗標(biāo)簽
3、流量返回至調(diào)用方SDK后,SDK上報曝光、點擊等信息至數(shù)據(jù)總線(大數(shù)據(jù)集群)
4、數(shù)據(jù)計算服務(wù)分析大數(shù)據(jù)集群的數(shù)據(jù),計算對應(yīng)的指標(biāo)展示在管理后臺。
實驗平臺,從模塊劃分上 ,如下圖所示: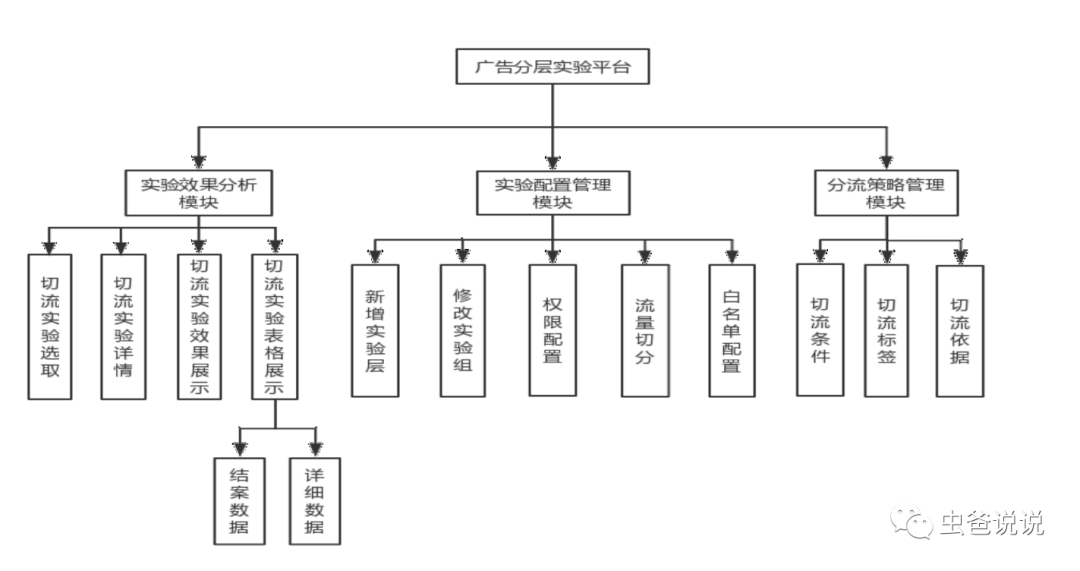
五、設(shè)計與實現(xiàn)
在具體介紹下文之前,我們先理解一個概念,以便能更方便的理解下述內(nèi)容。
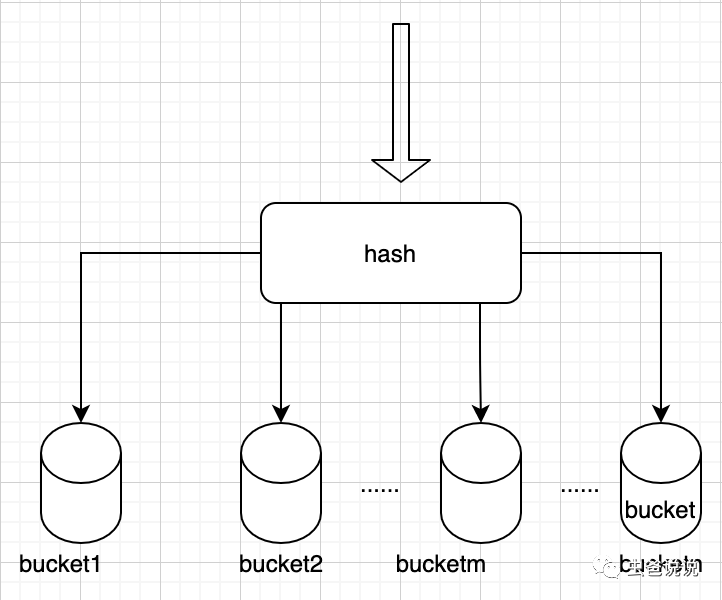
bucket即桶。實驗平臺最底層,將流量進(jìn)行hash之后,只能流入某一個桶里。
流量劃分
一般有以下幾種劃分方式:
完全隨機 用戶id哈希。 該流量劃分會使同一個用戶會一直命中同一實驗,從而保證了用戶體驗的一致性;而且也滿足對同一用戶具有累積效應(yīng)的策略的實驗需求。但存在的問題就是,對于一些工具類屬性,沒有用戶id一說,只有設(shè)備id比如idfa和imei這些標(biāo)記,但是隨著系統(tǒng)升級,這倆標(biāo)記很難再獲取到,所以就需要系統(tǒng)能夠生成用戶唯一id 用戶id + 日期作為一個整體進(jìn)行哈希 這是一種更為嚴(yán)格的保證流量均勻性的分流方式,可以保證流量劃分在跨時間維度上更為均勻。 會犧牲用戶請求跨時間區(qū)間的一致性 跟上面這種用戶id哈希存在同樣的問題 用戶id尾號進(jìn)行哈希 流量不均勻 也會存在用戶id所存在的問題
為了兼容上述幾種哈希劃分方式的優(yōu)點,而摒棄其缺點,我們引入了第四種流量劃分方式:
bucket_id = hash(uid + layer_id) % 1000
常見的哈希算法有md5,crc以及MurmurHash等。
MD5消息摘要算法(英語:MD5 Message-Digest Algorithm),一種被廣泛使用的密碼散列函數(shù),可以產(chǎn)生出一個128位(16字節(jié))的散列值(hash value),MD5算法將數(shù)據(jù)(如一段文字)運算變?yōu)榱硪还潭ㄩL度值,是散列算法的基礎(chǔ)原理。由美國密碼學(xué)家 Ronald Linn Rivest設(shè)計,于1992年公開并在 RFC 1321 中被加以規(guī)范。 CRC循環(huán)冗余校驗(Cyclic Redundancy Check)是一種根據(jù)網(wǎng)絡(luò)數(shù)據(jù)包或電腦文件等數(shù)據(jù),產(chǎn)生簡短固定位數(shù)校驗碼的一種散列函數(shù),由 W. Wesley Peterson 于1961年發(fā)表。生成的數(shù)字在傳輸或者存儲之前計算出來并且附加到數(shù)據(jù)后面,然后接收方進(jìn)行檢驗確定數(shù)據(jù)是否發(fā)生變化。由于本函數(shù)易于用二進(jìn)制的電腦硬件使用、容易進(jìn)行數(shù)學(xué)分析并且尤其善于檢測傳輸通道干擾引起的錯誤,因此獲得廣泛應(yīng)用。 MurmurHash 是一種非加密型哈希函數(shù),適用于一般的哈希檢索操作。由 Austin Appleby 在2008年發(fā)明,并出現(xiàn)了多個變種,與其它流行的哈希函數(shù)相比,對于規(guī)律性較強的鍵,MurmurHash的隨機分布特征表現(xiàn)更良好。
其中,第三種MurmurHash算法,已經(jīng)被很多開源項目使用,比如libstdc++ (4.6版)、Perl、nginx (不早于1.0.1版)、Rubinius、 libmemcached、maatkit、Hadoop以及redis等。而且經(jīng)過大量的測試,其流量分布更加均勻,所以筆者采用的是此種哈希算法。
白名單
白名單,在實驗平臺中算是比較重要的功能,其目的就是存在于白名單中的用戶優(yōu)先于流量分桶,命中某個實驗。
需要注意的一點是,假如白名單所在實驗和流量經(jīng)過哈希分桶之后的實驗是兩個不同的實驗,這就只能以白名單優(yōu)先級為最高,換句話說,如果白名單命中了某個實驗,那么在該層上,就不該再命中其他實驗。
管理后臺
用來管理實驗的,比如權(quán)限管理、層管理等,如下圖:
 在上圖中,管理后臺,主要有以下幾個模塊:
在上圖中,管理后臺,主要有以下幾個模塊:
實驗管理,顧名思義,管理現(xiàn)有實驗和創(chuàng)建新實驗 實驗列表:現(xiàn)有已經(jīng)創(chuàng)建的所有實驗 創(chuàng)建實驗:創(chuàng)建新實驗 基礎(chǔ)配置,一些配置管理信息都在此模塊中 實驗層:增刪改實驗層 其他:針對實驗做的一些定制化,比如增加廣告位定向、年齡定向等 系統(tǒng)管理,主要針對用戶及其分組 分組管理,管理用戶屬于某個分組 實驗平臺的用戶權(quán)限管理,比如普通權(quán)限或者管理員權(quán)限
需要注意的是,用戶管理這塊的權(quán)限非常重要,因為實驗平臺可能涉及到很核心的實驗,比如商業(yè)化中策略影響的實驗,所以用戶之間不能看到其他人創(chuàng)建的實驗,這層物理隔離非常重要。
分流平臺
分流評估 ,顧名思義,對流量進(jìn)行分離,有兩個功能:
承接實驗后臺的實驗消息,建立維度索引 接收線上流量,根據(jù)維度索引、白名單以及對用戶設(shè)備哈希分桶后,給流量打標(biāo)簽
分流平臺,是整個實驗平臺的核心模塊,一定要高性能,高可靠。
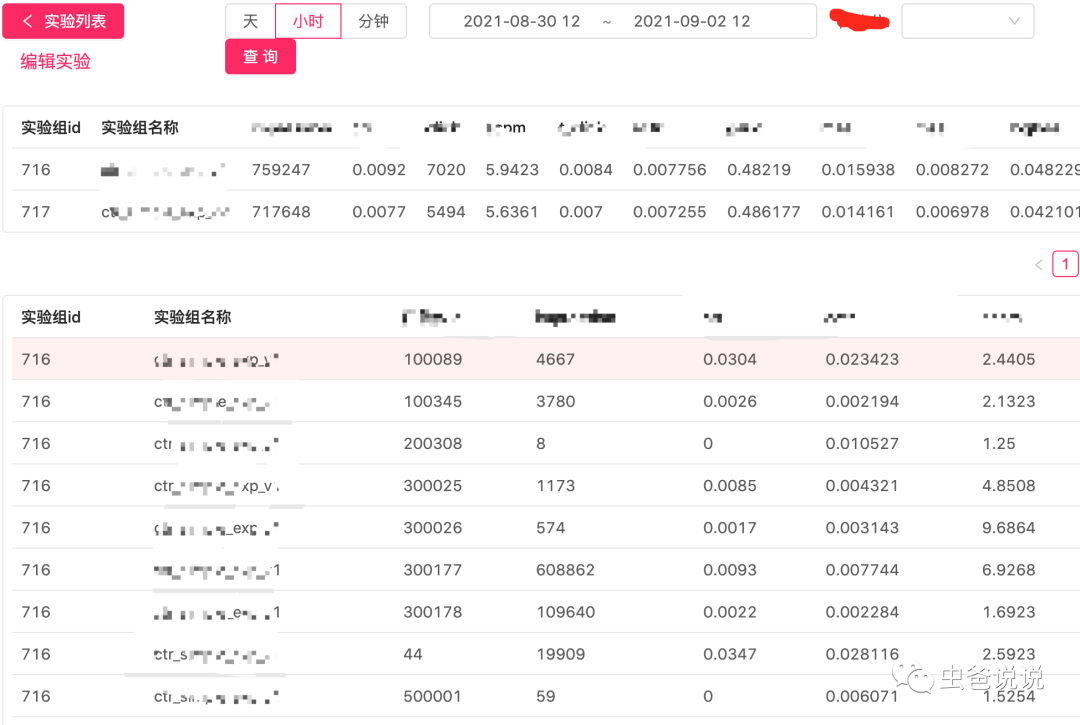
六、實驗效果
請求的實驗信息會以標(biāo)簽的形式上報給sdk,sdk在進(jìn)行曝光點擊的時候,會將這些信息上報,比如"123_456_789"格式。最終,這些會經(jīng)過廣告實時流系統(tǒng)進(jìn)行消費、數(shù)據(jù)清洗、實驗效果指標(biāo)計算等工作。由于廣告系統(tǒng)是多業(yè)務(wù)指標(biāo)系統(tǒng),包括售賣率,ECPM, CTR, ACPE,負(fù)反饋率、財務(wù)消耗計算等。廣告實時流系統(tǒng)還需要日志的關(guān)聯(lián)工作,比如關(guān)聯(lián)廣告互動日志,廣告負(fù)反饋日志。實時流的計算的結(jié)果,會落地到druid 系統(tǒng),方便實驗效果數(shù)據(jù)的快速檢索和二度加工。實驗效果實時指標(biāo)數(shù)據(jù)計算延遲控制在一定的范圍內(nèi)。
七、結(jié)語
最后需要提的是,實驗平臺在效果跟蹤決策方面是有一定的局限性的。實驗平臺可以進(jìn)行實驗效果的快速跟蹤,但是卻很難進(jìn)行實驗效果好壞的決策。比如:如果對比實驗效果指標(biāo)值全部提高或下降了,可以簡單認(rèn)為對比實驗的策略調(diào)整起正向作用或者反向作用;如果對比實驗的實驗效果指標(biāo)值部分提高了,部分下降了,就不太好認(rèn)定了。還有,實驗效果的短期效應(yīng)和長期效應(yīng)也可能是不一致,這將大大增加了實驗效果好壞的決策難度。
因此,實驗平臺是可以快速提升廣告業(yè)務(wù)策略迭代效率的工具,但是要想進(jìn)行實驗好壞評定的決策,還需要很長的路要走。
