
3000字入門數(shù)據(jù)湖(建議收藏)
一、數(shù)據(jù)湖的角色和定位
隨著移動(dòng)互聯(lián)網(wǎng),物聯(lián)網(wǎng)技術(shù)的發(fā)展,數(shù)據(jù)的應(yīng)用逐漸從 BI 報(bào)表可視化往機(jī)器學(xué)習(xí)、預(yù)測(cè)分析等方向發(fā)展,即 BI 到 AI 的轉(zhuǎn)變。
數(shù)據(jù)的使用者也從傳統(tǒng)的業(yè)務(wù)分析人員轉(zhuǎn)為數(shù)據(jù)科學(xué)家,算法工程師。此外對(duì)數(shù)據(jù)的實(shí)時(shí)性要求越來越高,也出現(xiàn)了越來越多的非結(jié)構(gòu)化的數(shù)據(jù)。
目前的數(shù)據(jù)倉(cāng)庫(kù)技術(shù)出現(xiàn)了一定的局限性,比如單一不變的 schema 和模型已經(jīng)無法滿足各類不同場(chǎng)景和領(lǐng)域的數(shù)據(jù)分析的要求,并且數(shù)據(jù)科學(xué)家更愿意自己去處理原始的數(shù)據(jù),而不是直接使用被處理過的數(shù)據(jù)。
比如對(duì)于數(shù)據(jù)缺失這種情況,數(shù)據(jù)科學(xué)家會(huì)嘗試各種不同的算法去彌補(bǔ)缺失數(shù)據(jù),針對(duì)不同的業(yè)務(wù)場(chǎng)景也會(huì)有不同的處理方式。
目前數(shù)據(jù)湖相關(guān)的技術(shù)是業(yè)界針對(duì)這些問題的一種解決方案。
下表展示了數(shù)據(jù)倉(cāng)庫(kù)和數(shù)據(jù)湖在各個(gè)維度上的特性:
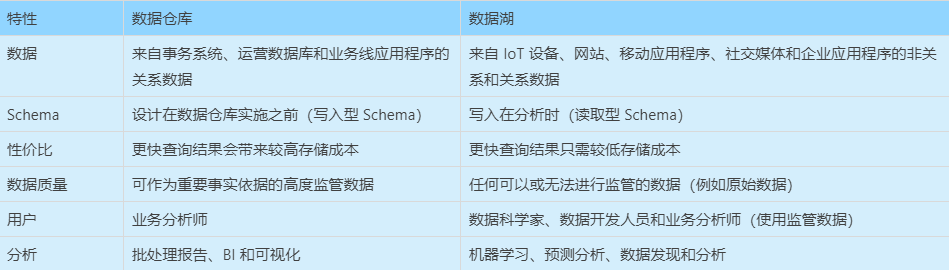
相比于數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)湖會(huì)保留最原始的數(shù)據(jù),并且是讀取時(shí)確定 Schema,這樣可以在業(yè)務(wù)發(fā)生變化時(shí)能靈活調(diào)整。
最原始的數(shù)據(jù)湖技術(shù)其實(shí)就是對(duì)象存儲(chǔ),比如 Amazon S3,Aliyun OSS,可以存儲(chǔ)任意形式的原始數(shù)據(jù),但是如果不對(duì)這些存儲(chǔ)的原始文件加以管理,就會(huì)使數(shù)據(jù)湖退化成數(shù)據(jù)沼澤(dataswamp)。
所以必須有相關(guān)的技術(shù)發(fā)展來解決這些問題。
我們都知道一個(gè)大數(shù)據(jù)處理系統(tǒng)分為:
分布式文件系統(tǒng):HDFS,S3 基于一定的文件格式將文件存儲(chǔ)在分布式文件系統(tǒng):Parquet,ORC, ARVO 用來組織文件的元數(shù)據(jù)系統(tǒng):Metastore 處理文件的計(jì)算引擎,包括流處理和批處理:SPARK,F(xiàn)LINK
簡(jiǎn)單的說,數(shù)據(jù)湖技術(shù)是計(jì)算引擎和底層存儲(chǔ)格式之間的一種數(shù)據(jù)組織格式,用來定義數(shù)據(jù)、元數(shù)據(jù)的組織方式。
目前并沒有針對(duì)數(shù)據(jù)湖的比較成熟的解決方案,幾個(gè)大廠在開發(fā)相關(guān)技術(shù)來解決內(nèi)部遇到的一些痛點(diǎn)后,開源了幾個(gè)項(xiàng)目,比較著名的有Databrics 的 Dalta Lake,Uber 開源的 Hudi,Netflix 開源的 Iceberg。
二、Delta Lake
傳統(tǒng)的 lambda 架構(gòu)需要同時(shí)維護(hù)批處理和流處理兩套系統(tǒng),資源消耗大,維護(hù)復(fù)雜。
基于 Hive 的數(shù)倉(cāng)或者傳統(tǒng)的文件存儲(chǔ)格式(比如 parquet / ORC),都存在一些難以解決的問題:
小文件問題; 并發(fā)讀寫問題; 有限的更新支持; 海量元數(shù)據(jù)(例如分區(qū))導(dǎo)致 metastore 不堪重負(fù)
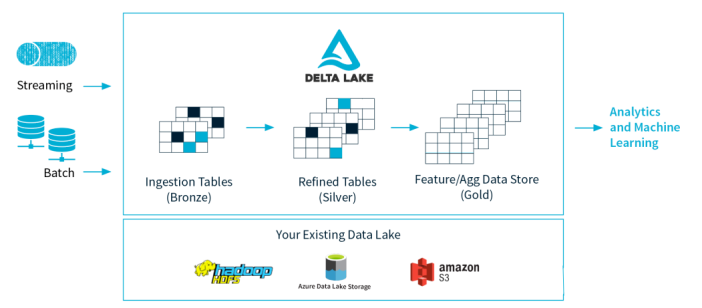
如上圖,Delta Lake 是 Spark 計(jì)算框架和存儲(chǔ)系統(tǒng)之間帶有 Schema 信息的存儲(chǔ)中間層。
它有一些重要的特性:
設(shè)計(jì)了基于 HDFS 存儲(chǔ)的元數(shù)據(jù)系統(tǒng),解決 metastore 不堪重負(fù)的問題; 支持更多種類的更新模式,比如 Merge / Update / Delete 等操作,配合流式寫入或者讀取的支持,讓實(shí)時(shí)數(shù)據(jù)湖變得水到渠成; 流批操作可以共享同一張表; 版本概念,可以隨時(shí)回溯,避免一次誤操作或者代碼邏輯而無法恢復(fù)的災(zāi)難性后果。
Delta Lake 是基于 Parquet 的存儲(chǔ)層,所有的數(shù)據(jù)都是使用 Parquet 來存儲(chǔ),能夠利用 parquet 原生高效的壓縮和編碼方案。
Delta Lake 在多并發(fā)寫入之間提供 ACID 事務(wù)保證。每次寫入都是一個(gè)事務(wù),并且在事務(wù)日志中記錄了寫入的序列順序。
事務(wù)日志跟蹤文件級(jí)別的寫入并使用樂觀并發(fā)控制,這非常適合數(shù)據(jù)湖,因?yàn)槎啻螌懭?修改相同的文件很少發(fā)生。在存在沖突的情況下,Delta Lake 會(huì)拋出并發(fā)修改異常以便用戶能夠處理它們并重試其作業(yè)。
Delta Lake 其實(shí)只是一個(gè) Lib 庫(kù),不是一個(gè) service,不需要單獨(dú)部署,而是直接依附于計(jì)算引擎的,但目前只支持 spark 引擎,使用過程中和 parquet 唯一的區(qū)別是把 format parquet 換成 delta 即可,可謂是部署和使用成本極低。
三、Apache Hudi
Hudi 是什么 一般來說,我們會(huì)將大量數(shù)據(jù)存儲(chǔ)到HDFS/S3,新數(shù)據(jù)增量寫入,而舊數(shù)據(jù)鮮有改動(dòng),特別是在經(jīng)過數(shù)據(jù)清洗,放入數(shù)據(jù)倉(cāng)庫(kù)的場(chǎng)景。
且在數(shù)據(jù)倉(cāng)庫(kù)如 hive中,對(duì)于update的支持非常有限,計(jì)算昂貴。另一方面,若是有僅對(duì)某段時(shí)間內(nèi)新增數(shù)據(jù)進(jìn)行分析的場(chǎng)景,則hive、presto、hbase等也未提供原生方式,而是需要根據(jù)時(shí)間戳進(jìn)行過濾分析。
Apache Hudi 代表 Hadoop Upserts anD Incrementals,能夠使HDFS數(shù)據(jù)集在分鐘級(jí)的時(shí)延內(nèi)支持變更,也支持下游系統(tǒng)對(duì)這個(gè)數(shù)據(jù)集的增量處理。
Hudi數(shù)據(jù)集通過自定義的 nputFormat 兼容當(dāng)前 Hadoop 生態(tài)系統(tǒng),包括 Apache Hive,Apache Parquet,Presto 和 Apache Spark,使得終端用戶可以無縫的對(duì)接。
如下圖,基于 Hudi 簡(jiǎn)化的服務(wù)架構(gòu),分鐘級(jí)延遲。
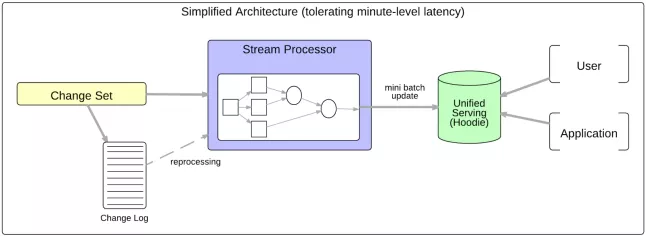
Hudi 存儲(chǔ)的架構(gòu)
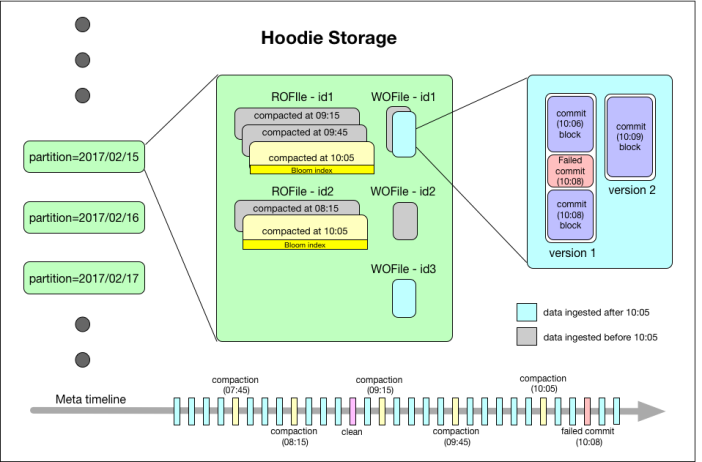
如上圖,最下面有一個(gè)時(shí)間軸,這是 Hudi 的核心。
Hudi 會(huì)維護(hù)一個(gè)時(shí)間軸,在每次執(zhí)行操作時(shí)(如寫入、刪除、合并等),均會(huì)帶有一個(gè)時(shí)間戳。
通過時(shí)間軸,可以實(shí)現(xiàn)在僅查詢某個(gè)時(shí)間點(diǎn)之后成功提交的數(shù)據(jù),或是僅查詢某個(gè)時(shí)間點(diǎn)之前的數(shù)據(jù)。
這樣可以避免掃描更大的時(shí)間范圍,并非常高效地只消費(fèi)更改過的文件(例如在某個(gè)時(shí)間點(diǎn)提交了更改操作后,僅 query 某個(gè)時(shí)間點(diǎn)之前的數(shù)據(jù),則仍可以 query 修改前的數(shù)據(jù))。
如上圖的左邊,Hudi 將數(shù)據(jù)集組織到與 Hive 表非常相似的基本路徑下的目錄結(jié)構(gòu)中。
數(shù)據(jù)集分為多個(gè)分區(qū),每個(gè)分區(qū)均由相對(duì)于基本路徑的分區(qū)路徑唯一標(biāo)識(shí)。
如上圖的中間部分,Hudi 以兩種不同的存儲(chǔ)格式存儲(chǔ)所有攝取的數(shù)據(jù)。
讀優(yōu)化的列存格式(ROFormat):僅使用列式文件(parquet)存儲(chǔ)數(shù)據(jù)。在寫入/更新數(shù)據(jù)時(shí),直接同步合并原文件,生成新版本的基文件(需要重寫整個(gè)列數(shù)據(jù)文件,即使只有一個(gè)字節(jié)的新數(shù)據(jù)被提交)。此存儲(chǔ)類型下,寫入數(shù)據(jù)非常昂貴,而讀取的成本沒有增加,所以適合頻繁讀的工作負(fù)載,因?yàn)閿?shù)據(jù)集的最新版本在列式文件中始終可用,以進(jìn)行高效的查詢。
寫優(yōu)化的行存格式(WOFormat):使用列式(parquet)與行式(avro)文件組合,進(jìn)行數(shù)據(jù)存儲(chǔ)。在更新記錄時(shí),更新到增量文件中(avro),然后進(jìn)行異步(或同步)的compaction,創(chuàng)建列式文件(parquet)的新版本。此存儲(chǔ)類型適合頻繁寫的工作負(fù)載,因?yàn)樾掠涗浭且詀ppending 的模式寫入增量文件中。但是在讀取數(shù)據(jù)集時(shí),需要將增量文件與舊文件進(jìn)行合并,生成列式文件。
四、Apache Iceberg
Iceberg 作為新興的數(shù)據(jù)湖框架之一,開創(chuàng)性的抽象出“表格式”table format)這一中間層,既獨(dú)立于上層的計(jì)算引擎(如Spark和Flink)和查詢引擎(如Hive和Presto),也和下層的文件格式(如Parquet,ORC和Avro)相互解耦。
此外 Iceberg 還提供了許多額外的能力:
ACID事務(wù); 時(shí)間旅行(time travel),以訪問之前版本的數(shù)據(jù); 完備的自定義類型、分區(qū)方式和操作的抽象; 列和分區(qū)方式可以進(jìn)化,而且進(jìn)化對(duì)用戶無感,即無需重新組織或變更數(shù)據(jù)文件; 隱式分區(qū),使SQL不用針對(duì)分區(qū)方式特殊優(yōu)化; 面向云存儲(chǔ)的優(yōu)化等;
Iceberg的架構(gòu)和實(shí)現(xiàn)并未綁定于某一特定引擎,它實(shí)現(xiàn)了通用的數(shù)據(jù)組織格式,利用此格式可以方便地與不同引擎(如Flink、Hive、Spark)對(duì)接。
所以 Iceberg 的架構(gòu)更加的優(yōu)雅,對(duì)于數(shù)據(jù)格式、類型系統(tǒng)有完備的定義和可進(jìn)化的設(shè)計(jì)。
但是 Iceberg 缺少行級(jí)更新、刪除能力,這兩大能力是現(xiàn)有數(shù)據(jù)組織最大的賣點(diǎn),社區(qū)仍然在優(yōu)化中。
五、總結(jié)
下表從各個(gè)維度,總結(jié)了三大數(shù)據(jù)湖框架支持的特性。
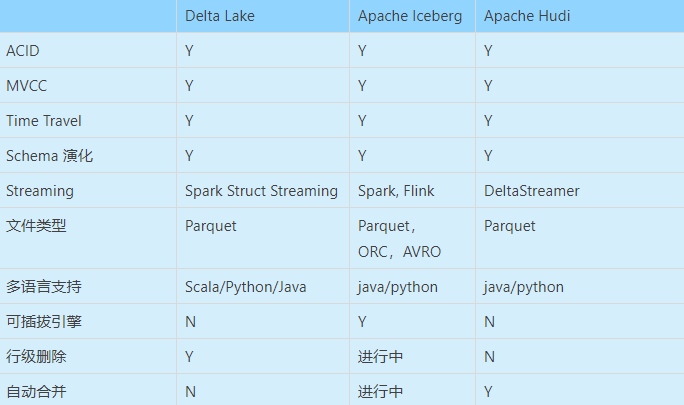
如果用一個(gè)比喻來說明delta、iceberg、hudi、三者差異的話,可以把三個(gè)項(xiàng)目比做建房子。
Delta的房子底座相對(duì)結(jié)實(shí),功能樓層也建得相對(duì)比較高,但這個(gè)房子其實(shí)可以說是databricks的,本質(zhì)上是為了更好地壯大Spark生態(tài),在delta上其他的計(jì)算引擎難以替換Spark的位置,尤其是寫入路徑層面。
Iceberg的建筑基礎(chǔ)非常扎實(shí),擴(kuò)展到新的計(jì)算引擎或者文件系統(tǒng)都非常的方便,但是現(xiàn)在功能樓層相對(duì)低一點(diǎn),目前最缺的功能就是upsert和compaction兩個(gè),Iceberg社區(qū)正在以最高優(yōu)先級(jí)推動(dòng)這兩個(gè)功能的實(shí)現(xiàn)。
Hudi的情況要相對(duì)不一樣,它的建筑基礎(chǔ)設(shè)計(jì)不如iceberg結(jié)實(shí),舉個(gè)例子,如果要接入Flink作為Sink的話,需要把整個(gè)房子從底向上翻一遍,把接口抽象出來,同時(shí)還要考慮不影響其他功能,當(dāng)然Hudi的功能樓層還是比較完善的,提供的upsert和compaction功能直接命中廣大群眾的痛點(diǎn)。
--end--
掃描下方二維碼 添加好友,備注【交流】 可私聊交流,也可進(jìn)資源豐富學(xué)習(xí)群