
數(shù)據(jù)倉庫體系建模實(shí)施及注意事項(xiàng)小總結(jié)
什么是數(shù)倉
從字面上來看,數(shù)據(jù)倉庫就是一個(gè)存放數(shù)據(jù)的倉庫,它里面存放了各種各樣的數(shù)據(jù),而這些數(shù)據(jù)需要按照一些結(jié)構(gòu)、規(guī)則來組織和存放。這里我們會(huì)遇到一個(gè)問題就是同樣是存放數(shù)據(jù)的倉庫,那數(shù)據(jù)庫和數(shù)據(jù)倉庫是一樣的嗎?
數(shù)據(jù)庫 VS 數(shù)據(jù)倉庫
數(shù)據(jù)庫就是我們常用的關(guān)系型數(shù)據(jù)庫(MySQL、Oracle、PostgreSQL...),還有什么非關(guān)系型數(shù)據(jù)庫,它主要存放業(yè)務(wù)數(shù)據(jù),那數(shù)據(jù)倉庫有有些什么數(shù)據(jù)呢?說到他們的區(qū)別,我們一般會(huì)提到OLTP和OLAP。
OLTP:on-line transaction processing,聯(lián)機(jī)事務(wù)處理,主要是業(yè)務(wù)數(shù)據(jù),需要考慮高并發(fā)、考慮事務(wù)
OLAP:On-Line Analytical Processing,聯(lián)機(jī)分析處理,重點(diǎn)主要是面向分析,會(huì)產(chǎn)生大量的查詢,一般很少涉及增刪改
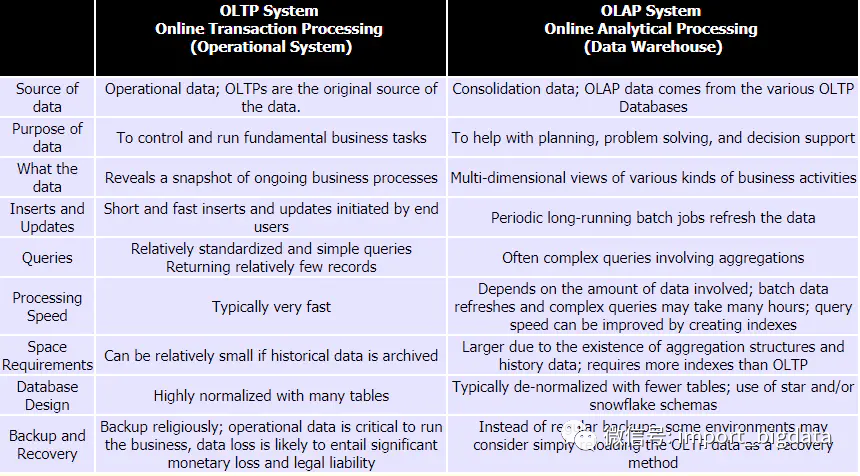
他們的區(qū)別,面試時(shí)也會(huì)提到,主要從幾個(gè)點(diǎn)談?wù)劸托小?/span>
數(shù)據(jù)倉庫其實(shí)是一套體系,他不是一門什么技術(shù),而是整合了很多已有的技術(shù),來更好地組織和管理數(shù)據(jù)。傳統(tǒng)數(shù)倉的話,主要是基于關(guān)系型數(shù)據(jù)庫,后面還有一些分布式的數(shù)據(jù)庫像Greenplum,還有很多公司會(huì)提供基于硬件的一整套解決方案。在傳統(tǒng)數(shù)倉開發(fā)時(shí),由于硬件的性能有限,所以有很多的要求,而隨著硬件價(jià)格的下降、云服務(wù)器的廣泛使用,還有大數(shù)據(jù)技術(shù)的成熟發(fā)展,數(shù)倉的很多場(chǎng)景都變了,有些規(guī)則都不需要去嚴(yán)格遵守了,這樣也可以剩下很多的成本。
再往前幾年,數(shù)倉這個(gè)東西是有點(diǎn)兒神秘的,感覺很高大上,而現(xiàn)在,起碼在互聯(lián)網(wǎng)公司來說,誰都知道數(shù)倉,誰都知道數(shù)據(jù)平臺(tái),誰都可以來說兩句,已經(jīng)大眾化了。記得以前面數(shù)倉的話,總有幾個(gè)必備的面試題:
什么是數(shù)倉?
數(shù)倉的幾個(gè)特點(diǎn)是什么?
什么是OLAP?什么是OLTP?區(qū)別是什么?
拉鏈表是什么?怎么實(shí)現(xiàn)拉鏈表?
同步又哪幾種方式?
為什么要做增量?怎么做增量?
什么是ETL?
就目前互聯(lián)網(wǎng)數(shù)倉這一崗位,感覺更加偏重業(yè)務(wù)+建模思想,面試不太好考察這些內(nèi)容的,去年招聘的時(shí)候,就是問些基本問題,聊聊以往主要的工作內(nèi)容,還會(huì)問問SQL題,真的想了解下建模的話,還是找本書借鑒性的看看,還是很有益處的。
傳統(tǒng)數(shù)倉與互聯(lián)網(wǎng)數(shù)倉
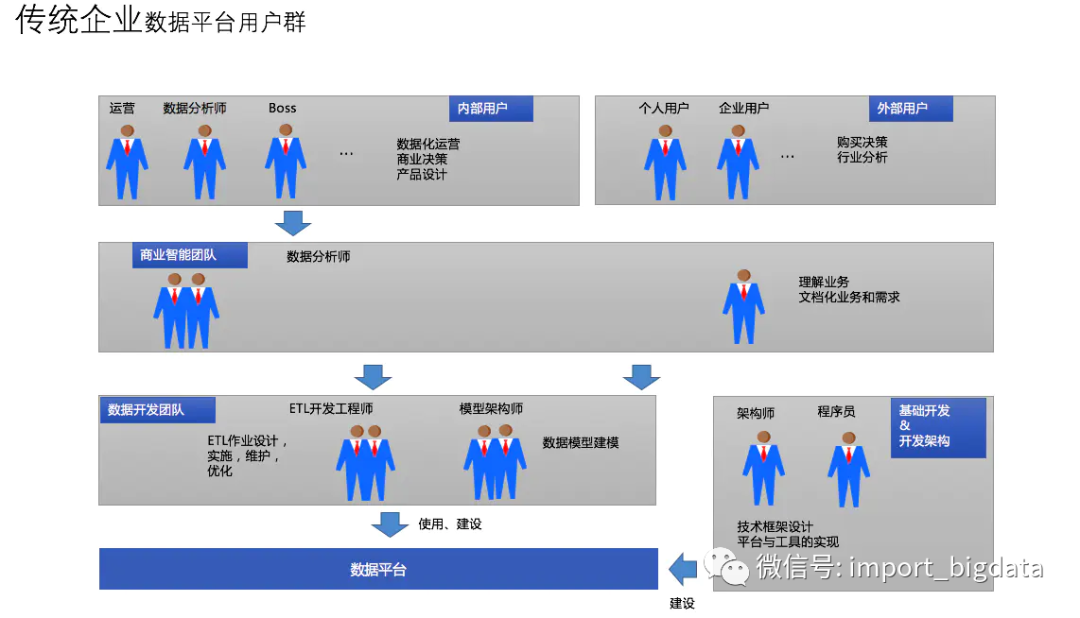
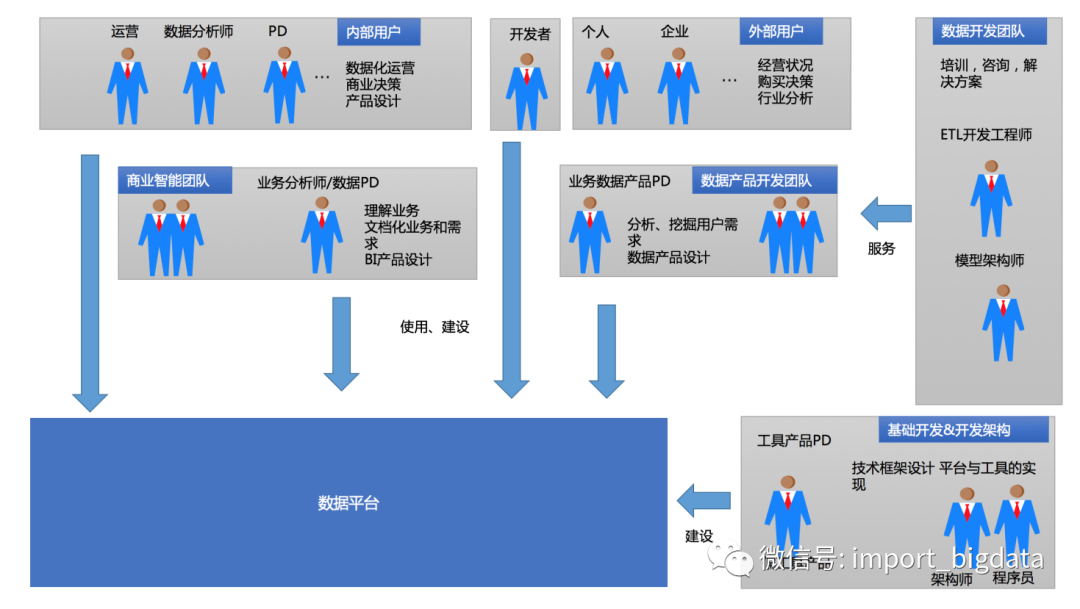
在傳統(tǒng)數(shù)據(jù)平臺(tái)要背后有一個(gè)完整數(shù)據(jù)倉庫團(tuán)隊(duì)去服務(wù)業(yè)務(wù)方,業(yè)務(wù)方嗷嗷待哺的等待被動(dòng)方式去滿足。中低層數(shù)據(jù)基本不會(huì)對(duì)業(yè)務(wù)方開放,所以不管數(shù)據(jù)模型采用何種建模方式,主要滿足當(dāng)時(shí)數(shù)據(jù)架構(gòu)規(guī)劃即可。
互聯(lián)網(wǎng)業(yè)務(wù)的快速發(fā)展使得大家已經(jīng)從經(jīng)營、分析的訴求重點(diǎn)轉(zhuǎn)為數(shù)據(jù)化的精細(xì)運(yùn)營上,如何做好精細(xì)化運(yùn)營問題上來,當(dāng)資源不夠時(shí)用戶就叫喊,甚至有的業(yè)務(wù)方會(huì)挽起袖子來自己參與到從數(shù)據(jù)整理、加工、分析階段。
此時(shí)呢,原有建設(shè)數(shù)據(jù)平臺(tái)的多個(gè)角色(數(shù)據(jù)開發(fā)、模型設(shè)計(jì))可能轉(zhuǎn)為對(duì)其它非專業(yè)使用數(shù)據(jù)方,做培訓(xùn)、咨詢與落地,寫更加適合當(dāng)前企業(yè)數(shù)據(jù)應(yīng)用的一些方案與開發(fā)些數(shù)據(jù)產(chǎn)品等。
在互聯(lián)網(wǎng)數(shù)據(jù)平臺(tái)由于數(shù)據(jù)平臺(tái)變?yōu)樽杂砷_放,大家使用數(shù)據(jù)的人也參與到數(shù)據(jù)的體系建設(shè)時(shí),基本會(huì)因?yàn)椴粚I(yè)性,導(dǎo)致數(shù)據(jù)質(zhì)量問題、重復(fù)對(duì)分?jǐn)?shù)據(jù)浪費(fèi)存儲(chǔ)與資源、口徑多樣化、編碼不統(tǒng)一、命名問題等等原因。數(shù)據(jù)質(zhì)量逐漸變成一個(gè)特別突出的問題。
數(shù)倉架構(gòu)
現(xiàn)在說數(shù)倉,更多的會(huì)和數(shù)據(jù)平臺(tái)或者基礎(chǔ)架構(gòu)搭上,已經(jīng)融合到整個(gè)基礎(chǔ)設(shè)施的搭建上。這里呢,我們不說Hadoop各種組件之間的配合,我們就簡(jiǎn)單說下數(shù)倉的分層架構(gòu)。
說到數(shù)倉建模,就得提下經(jīng)典的2套理論:
范式建模
Inmon提出的集線器的自上而下(EDW-DM)的數(shù)據(jù)倉庫架構(gòu)。
維度建模
Kimball提出的總線式的自下而上(DM-DW)的數(shù)據(jù)倉庫架構(gòu)。
數(shù)倉的建模或者分層,其實(shí)都是為了更好的去組織、管理、維護(hù)數(shù)據(jù),實(shí)際開發(fā)時(shí)會(huì)整合2種方式去使用,當(dāng)然,還有些其他的,像Data Vault模型、Anchor模型,暫時(shí)還沒有應(yīng)用過,就不說了。
維度建模,一般都會(huì)提到星型模型、雪花模型,星型模型做OLAP分析很方便。
數(shù)倉分層
簡(jiǎn)單點(diǎn)兒,直接ODS+DM就可以了,將所有數(shù)據(jù)同步過來,然后直接開發(fā)些應(yīng)用層的報(bào)表,這是最簡(jiǎn)單的了;當(dāng)DM層的內(nèi)容多了以后,想要重用,就會(huì)再拆分一個(gè)公共層出來,變成3層架構(gòu),最近看了本阿里的書,《大數(shù)據(jù)之路》,里面有很多數(shù)倉相關(guān)的內(nèi)容,很不錯(cuò),參考后,目前使用的分層模式如下:
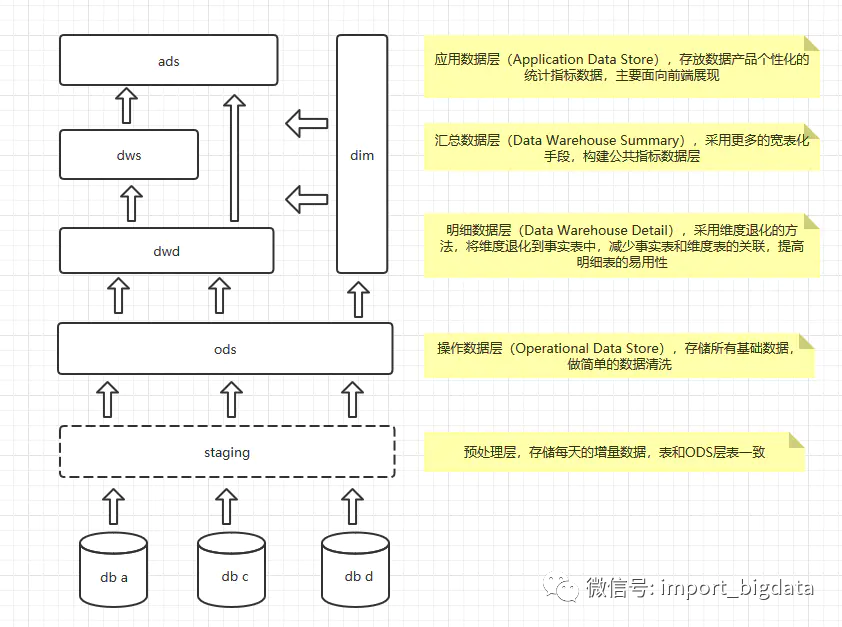
按照這種分層方式,我們的開發(fā)重心就在dwd層,就是明細(xì)數(shù)據(jù)層,這里主要是一些寬表,存儲(chǔ)的還是明細(xì)數(shù)據(jù);到了dws層,我們就會(huì)針對(duì)不同的維度,對(duì)數(shù)據(jù)進(jìn)行聚合了,按道理說,dws層算是集市層,這里一般按照主題進(jìn)行劃分,屬于維度建模的范疇;ads就是偏應(yīng)用層,各種報(bào)表的輸出了。
指標(biāo)字典
前面我們說過,數(shù)倉是一套體系,一個(gè)建設(shè)過程,它整合了很多的方法論,并不是一門新的技術(shù)。這里我們說說數(shù)倉中的指標(biāo)體系,指標(biāo)也不是數(shù)倉或者數(shù)據(jù)平臺(tái)中特有的, 很多場(chǎng)景都會(huì)有指標(biāo)這個(gè)概念。
這里我們說的指標(biāo),其實(shí)就是KPI(Key Performance Indicator),關(guān)鍵績效指標(biāo)。
企業(yè)關(guān)鍵績效指標(biāo)(KPI:Key Performance Indicator)是通過對(duì)組織內(nèi)部流程的輸入端、輸出端的關(guān)鍵參數(shù)進(jìn)行設(shè)置、取樣、計(jì)算、分析,衡量流程績效的一種目標(biāo)式量化管理指標(biāo),是把企業(yè)的戰(zhàn)略目標(biāo)分解為可操作的工作目標(biāo)的工具,是企業(yè)績效管理的基礎(chǔ)。KPI可以使部門主管明確部門的主要責(zé)任,并以此為基礎(chǔ),明確部門人員的業(yè)績衡量指標(biāo)。
數(shù)據(jù)平臺(tái)的作用是為分析、決策提供支持,來時(shí)刻關(guān)注企業(yè)的運(yùn)營情況的。那我們?cè)鯓觼砜垂镜倪\(yùn)營情況呢?就是看KPI,公司層面有公司最關(guān)注的KPI,比如:日活、GMV、訂單量等等;不同的部門又有不同的關(guān)注KPI,比如:新用戶數(shù)、復(fù)夠人數(shù)等等,有了KPI,我們就可以根據(jù)KPI來考察部門的表現(xiàn),也就是績效。這也是數(shù)字化轉(zhuǎn)型嘛,所有的管理、績效都數(shù)字化。
就數(shù)據(jù)平臺(tái)來說,指標(biāo)算是元數(shù)據(jù)的一種,指標(biāo)的維護(hù)和管理是有套路的,下面就簡(jiǎn)單分享下關(guān)于指標(biāo)的管理-指標(biāo)字典。
指標(biāo)字典
指標(biāo)字典,其實(shí)就是對(duì)指標(biāo)的管理,指標(biāo)多了以后,為了共享和統(tǒng)一修改和維護(hù),我們會(huì)在Excel中維護(hù)所有的指標(biāo)。當(dāng)然,Excel對(duì)于共享和版本控制也不是很方便,有條件的話,可以開發(fā)個(gè)簡(jiǎn)單的指標(biāo)管理系統(tǒng),再配合上血緣關(guān)系,就更方便追蹤數(shù)據(jù)流轉(zhuǎn)了。
指標(biāo)編碼
為了方便查找和管理,我們會(huì)對(duì)指標(biāo)定義一套編碼
指標(biāo)類型
基礎(chǔ)指標(biāo):不能再進(jìn)一步拆解的指標(biāo),可以直接計(jì)算出來的指標(biāo),如“訂單數(shù)”、“交易額” 衍生指標(biāo):在基礎(chǔ)指標(biāo)的基礎(chǔ)上,通過某個(gè)特殊維度計(jì)算出的指標(biāo),如“微信訂單數(shù)”、“支付寶訂單數(shù)” 計(jì)算指標(biāo):通過若干個(gè)基礎(chǔ)指標(biāo)計(jì)算得來的指標(biāo),在業(yè)務(wù)角度無法再拆解的指標(biāo),如“售罄率”、“復(fù)購率”
業(yè)務(wù)口徑
指標(biāo)最重要的就是,明確指標(biāo)的統(tǒng)計(jì)口徑,就是這個(gè)指標(biāo)是怎么算出來的,口徑統(tǒng)一了,才不會(huì)產(chǎn)生歧義
指標(biāo)模板
除了上面,我們說到的幾點(diǎn),還有一些基本的,像“指標(biāo)名稱”、計(jì)算公式,就組成了指標(biāo)的模板
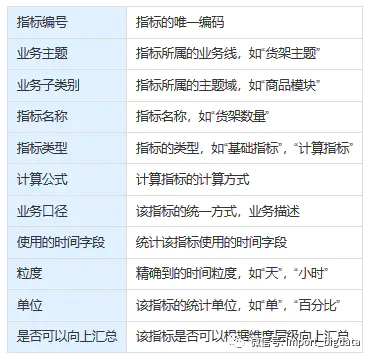
以前的話,我們還會(huì)有責(zé)任部門,就是說這個(gè)指標(biāo)是哪個(gè)部門負(fù)責(zé)維護(hù)的,這個(gè)KPI是哪個(gè)部門來關(guān)注和承擔(dān)。說到指標(biāo),就離不開維度,我們后面會(huì)說說維度的故事。
指標(biāo)的梳理和管理
一開始指標(biāo)的梳理是很麻煩的,因?yàn)橐y(tǒng)一一個(gè)口徑,需要和不同的部門去溝通協(xié)調(diào);還有可能會(huì)有各種各樣的指標(biāo)出現(xiàn),需要去判斷是否真的需要這個(gè)指標(biāo),是否可以用其他指標(biāo)來替代;指標(biāo)與指標(biāo)之間的關(guān)系也需要理清楚。
而且第一版指標(biāo)梳理好之后,需要進(jìn)行推廣和維護(hù),不斷地迭代,持續(xù)推動(dòng),讓公司所有部門都統(tǒng)一站在一個(gè)視角關(guān)注問題。
最重要的維度之日期維度
日期維度是我們最常用的維度,平臺(tái)初始,最先初始化的可能就是日期維度,這里我們就簡(jiǎn)單介紹下日期維度。
什么是日期維度
我們?nèi)粘I睿瑪?shù)據(jù)的產(chǎn)生都和日期有關(guān),每一分、每一秒都會(huì)產(chǎn)生數(shù)據(jù),數(shù)據(jù)分析也離不開日期。
日期維度就是一張固化的日歷,一年365天,每一天都有,我們打開電腦中的日歷:
這里面有的,我們都可以固化下來,像周幾、農(nóng)歷、年、月、日、節(jié)假日,我們都可以固化下來,方面我們分析的時(shí)候使用。
日期維度的結(jié)構(gòu)
日期維度可以盡可能多的包含日期詳細(xì)信息,這樣在分析的時(shí)候可以直接使用,還要結(jié)合公司的一些特殊情況,像一些特殊展示的日期格式。
基本的年季度月周日信息
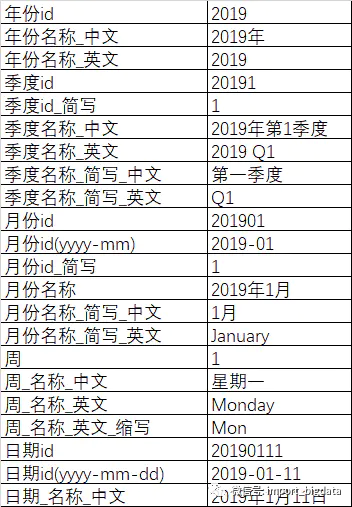
拓展信息
除了上面的基本的日期,平時(shí)用的還有有些拓展信息
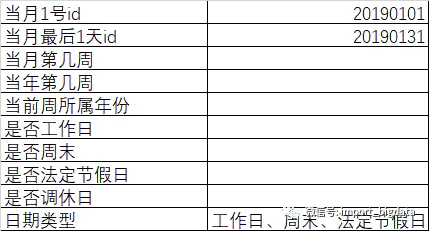
可能還有些農(nóng)歷信息、農(nóng)歷年份等,公司自定義周的開始日期、結(jié)束日期等,和日期相關(guān)的所有內(nèi)容都可以加進(jìn)來進(jìn)行維護(hù)。
維度初始化
數(shù)據(jù)初始化,我們可以使用Java、Python或者SQL,通過常用的日期函數(shù)基本可以滿足我們的數(shù)據(jù)需求,用SQL初始化,需要使用有循環(huán)控制語句的,如:MySQL、PG都行,Hive的話要結(jié)合Shell或者Python來使用。
一般不需要初始化太多年的數(shù)據(jù),只要覆蓋公司業(yè)務(wù)數(shù)據(jù)就好了,還有節(jié)假日信息每年都需要結(jié)合國務(wù)院發(fā)布的信息就行維護(hù)。
關(guān)于小時(shí)
平時(shí)我們還會(huì)分析小時(shí)數(shù)據(jù),一般不會(huì)把他放在日期表中,而是會(huì)單獨(dú)放在一張小時(shí)維度表里,需要的時(shí)候一起使用就行了。
命名規(guī)范
話說,沒有規(guī)矩不成方圓。在搭建數(shù)據(jù)平臺(tái)的時(shí)候,在數(shù)據(jù)組內(nèi)部,一定要先制定好各種規(guī)范,越早越好,并且不斷的監(jiān)督大家是否按照約定執(zhí)行。一旦讓大家自由發(fā)揮,后期想要統(tǒng)一或者重構(gòu),會(huì)浪費(fèi)很大的人力成本和時(shí)間成本,記住,這都是坑。
這里以我目前公司的一些經(jīng)驗(yàn),分享下。
關(guān)于項(xiàng)目
常規(guī)來說,數(shù)倉的建設(shè)是按照數(shù)倉分層模型開發(fā)的。也有會(huì)按照業(yè)務(wù)線來分層,在各自業(yè)務(wù)線下重新分層,單獨(dú)開發(fā)的。我這里使用的是阿里云的MaxCompute,這是阿里提供的數(shù)據(jù)平臺(tái),一整套開發(fā)環(huán)境,用起來還是很方便的,省去了自建平臺(tái)的麻煩。MaxCompute里面有一個(gè)項(xiàng)目的概念,一開始本來打算直接根據(jù)分層模型的設(shè)計(jì)來創(chuàng)建項(xiàng)目,但是由于某種原因,改成了按照業(yè)務(wù)線來創(chuàng)建項(xiàng)目。對(duì)于這個(gè)項(xiàng)目名,一定要想好,不管根據(jù)什么來設(shè)計(jì),都需要想清楚,想明白,定了以后就不要再改了,也沒法改。
關(guān)于詞根
我忘記是不是叫“詞根”了,先寫著,后面找本書確認(rèn)下。詞根屬于數(shù)倉建設(shè)中的規(guī)范,屬于元數(shù)據(jù)管理的范疇。哦,現(xiàn)在都把這個(gè)劃到數(shù)據(jù)治理的一部分。
正常來說,完整的數(shù)倉建設(shè)是包含數(shù)據(jù)治理的,只是現(xiàn)在談到數(shù)倉偏向于數(shù)據(jù)建模,而談到數(shù)據(jù)治理,更多的是關(guān)于數(shù)據(jù)規(guī)范、數(shù)據(jù)管理。
接著說我們的主角-詞根。
我們學(xué)習(xí)英語的時(shí)候應(yīng)該有了解過詞根這個(gè)東西,它就是最細(xì)粒度的最簡(jiǎn)單的一個(gè)詞語,我們主要用來規(guī)范中文和英文的映射關(guān)系。我們公司一部分業(yè)務(wù)是關(guān)于貨架的,英文名是:rack,rack就是一個(gè)詞根,那我們就在所有的表、字段等用到的地方都叫rack,不要叫成別的什么。這就是詞根的作用,用來統(tǒng)一命名,表達(dá)同一個(gè)含義。指標(biāo)體系中有很多“率”的指標(biāo),都可以拆解成XXX+率,率可以叫rate,那我們所有的指標(biāo)都叫做XXX+rate。詞根可以用來統(tǒng)一表名、字段名、主題域名等等。
表名
表名需要見名知意,通過表名就可以知道它是哪個(gè)業(yè)務(wù)域,干嘛用的,什么粒度的數(shù)據(jù)。
常規(guī)表
常規(guī)表是我們需要固化的表,是正式使用的表,是目前一段時(shí)間內(nèi)需要去維護(hù)去完善的表。規(guī)范:分層前綴[dwd|dws|ads|bi]業(yè)務(wù)域主題域XXX粒度 業(yè)務(wù)域、主題域我們都可以用詞根的方式枚舉清楚,不斷完善,粒度也是同樣的,主要的是時(shí)間粒度、日、月、年、周等,使用詞根定義好簡(jiǎn)稱。
中間表
中間表一般出現(xiàn)在Job中,是Job中臨時(shí)存儲(chǔ)的中間數(shù)據(jù)的表,中間表的作用域只限于當(dāng)前Job執(zhí)行過程中,Job一旦執(zhí)行完成,該中間表的使命就完成了,是可以刪除的(按照自己公司的場(chǎng)景自由選擇,以前公司會(huì)保留幾天的中間表數(shù)據(jù),用來排查問題)。規(guī)范:mid_tablename [0~9|dim] table_name是我們?nèi)蝿?wù)中目標(biāo)表的名字,通常來說一個(gè)任務(wù)只有一個(gè)目標(biāo)表。這里加上表名,是為了防止自由發(fā)揮的時(shí)候表名沖突,而末尾大家可以選擇自由發(fā)揮,起一些有意義的名字,或者簡(jiǎn)單粗暴,使用數(shù)字代替,各有優(yōu)劣吧,謹(jǐn)慎選擇。通常會(huì)遇到需要補(bǔ)全維度的表,這里我喜歡使用dim結(jié)尾。
中間表在創(chuàng)建時(shí),請(qǐng)加上 ,如果要保留歷史的中間表,可以加上日期或者時(shí)間戳
drop table if exists table_name;
create table_name as xxx;
臨時(shí)表
臨時(shí)表是臨時(shí)測(cè)試的表,是臨時(shí)使用一次的表,就是暫時(shí)保存下數(shù)據(jù)看看,后續(xù)一般不再使用的表,是可以隨時(shí)刪除的表。規(guī)范:tmp_xxx 只要加上tmp開頭即可,其他名字隨意, 注意tmp開頭的表不要用來實(shí)際使用,只是測(cè)試驗(yàn)證而已。
維度表
維度表是基于底層數(shù)據(jù),抽象出來的描述類的表。維度表可以自動(dòng)從底層表抽象出來,也可以手工來維護(hù)。規(guī)范:dim_xxx 維度表,統(tǒng)一以dim開頭,后面加上,對(duì)該指標(biāo)的描述,可以自由發(fā)揮。
手工表
手工表是手工維護(hù)的表,手工初始化一次之后,一般不會(huì)自動(dòng)改變,后面變更,也是手工來維護(hù)。一般來說,手工的數(shù)據(jù)粒度是偏細(xì)的,所以,暫時(shí)我們統(tǒng)一放在dwd層,后面如果有目標(biāo)值或者其他類型手工數(shù)據(jù),再根據(jù)實(shí)際情況分層。規(guī)范:dwd _ 業(yè)務(wù)域manual xxx 手工表,增加特殊的主題域,manual,表示手工維護(hù)表
指標(biāo)
指標(biāo)的命名也參考詞根,避免出現(xiàn)同一個(gè)指標(biāo),10個(gè)人有10個(gè)命名方法。
具體操作結(jié)合公司實(shí)際情況,規(guī)范及早制定。
數(shù)據(jù)治理
廣義數(shù)據(jù)倉庫的建設(shè)包含很多的解決方案,其中就包含數(shù)據(jù)治理,數(shù)據(jù)治理也是貫穿整個(gè)項(xiàng)目始終的,是一件長久的事情。現(xiàn)在很多人都把數(shù)據(jù)倉庫簡(jiǎn)單的理解成數(shù)據(jù)建模了。
數(shù)據(jù)治理包含很多的事情,我也沒做過,所以在網(wǎng)上找些資料分享下。
為什么要做數(shù)據(jù)治理
隨著數(shù)據(jù)量越來越大,數(shù)據(jù)成為一種資產(chǎn),我們需要更好地管理這些數(shù)據(jù),更好地體現(xiàn)數(shù)據(jù)的價(jià)值,這就需要數(shù)據(jù)治理。其實(shí)在搭建數(shù)據(jù)平臺(tái)的時(shí)候,我們遇到的一系列問題都可以通過數(shù)據(jù)治理來解決:
數(shù)據(jù)質(zhì)量越來越差,問題發(fā)現(xiàn)嚴(yán)重滯后
缺少數(shù)據(jù)標(biāo)準(zhǔn),各個(gè)部門標(biāo)準(zhǔn)不統(tǒng)一
數(shù)據(jù)變更對(duì)下游的影響不清晰,無法確認(rèn)影響范圍
數(shù)據(jù)治理(Data Governance),是一套持續(xù)改善管理機(jī)制,通常包括了數(shù)據(jù)架構(gòu)組織、數(shù)據(jù)模型、政策及體系制定、技術(shù)工具、數(shù)據(jù)標(biāo)準(zhǔn)、數(shù)據(jù)質(zhì)量、影響度分析、作業(yè)流程、監(jiān)督及考核流程等內(nèi)容。
簡(jiǎn)單來說就是有很多流程和標(biāo)準(zhǔn),像“元數(shù)據(jù)管理”、“主數(shù)據(jù)管理”、“數(shù)據(jù)質(zhì)量”都包含其中。
通過數(shù)據(jù)治理來解決我們使用數(shù)據(jù)的過程中遇到的問題。
這部分內(nèi)容你可以參考:《所謂數(shù)據(jù)治理》
關(guān)于增量
很多初學(xué)者或者沒有做個(gè)ETL這件事兒的同學(xué)對(duì)這個(gè)增量是有誤解的,尤其是在和業(yè)務(wù)開發(fā)同學(xué)對(duì)接的時(shí)候,他們對(duì)這個(gè)增量的理解也是有偏差的。
先來說說他們以為的增量是什么。他們以為“增量,就是按照時(shí)間增量去拿就好了,增量同步,你就把增量后的數(shù)據(jù)給我好了,不要總是全量同步。” 按道理說,這么做思路是對(duì)的,但是不嚴(yán)謹(jǐn),而且會(huì)出錯(cuò),下面我們就一步一步看看。
1.什么是增量
增量是相對(duì)于全量來說的,它們都是處于“同步數(shù)據(jù)”這個(gè)場(chǎng)景下的,比如說業(yè)務(wù)系統(tǒng)的數(shù)據(jù)同步到數(shù)倉,數(shù)倉的數(shù)據(jù)同步給業(yè)務(wù)系統(tǒng),都會(huì)使用同步的方式,這都是相對(duì)于我們開發(fā)來說的,從數(shù)據(jù)庫級(jí)也是可以同步的,這里我們就不介紹了。
全量同步,就是說把數(shù)據(jù)全部同步過去,100條就同步100條,1萬條就同步1萬條,1億條就同步1億條,大家也應(yīng)該會(huì)發(fā)現(xiàn)這種方式存在的問題,在數(shù)據(jù)量小的時(shí)候,全量同步簡(jiǎn)單方便易執(zhí)行,而當(dāng)數(shù)據(jù)量大了以后,尤其是歷史數(shù)據(jù)不會(huì)經(jīng)常變化的時(shí)候,全量同步就會(huì)浪費(fèi)大量的資源和時(shí)間,嚴(yán)重影響同步效率。
--全量同步一般先delete,然后insert
delete from tmp_a;
insert into tmp_a xxx;
-- 或者直接 insert overwrite
insert overwrite table tmp_a xxx;
SQL語法可能不太一樣,差不多就是這個(gè)意思,哈哈
記住一定要?jiǎng)h除或者覆蓋插入,不然數(shù)據(jù)可就越來越多了。
選擇增量同步的幾個(gè)場(chǎng)景:
數(shù)據(jù)量很大,而且歷史數(shù)據(jù)不會(huì)頻繁變化
只需要增量數(shù)據(jù)
使用增量同步,對(duì)表有一些要求,比如,需要有create_time,update_time字段 create_time表示記錄創(chuàng)建時(shí)間,update_time表示記錄更新時(shí)間,增量的話,只需要把變化的數(shù)據(jù)拿過來就行了(使用update_time),注意:這里還需要有一個(gè)主鍵,主鍵是用來覆蓋數(shù)據(jù)的。
這里和不同的業(yè)務(wù)場(chǎng)景有關(guān)系,有的記錄創(chuàng)建后不會(huì)再更新,類似于流水?dāng)?shù)據(jù),這種數(shù)據(jù)直接增量拿過來就好,可以不進(jìn)行刪除操作;但是有的數(shù)據(jù)是會(huì)更新的,當(dāng)已經(jīng)同步過來的數(shù)據(jù)發(fā)生了變化,數(shù)倉側(cè)也是需要同步發(fā)生變化的。
2. 怎么做增量
增量同步也是要做一次初始化的,初始化是全量來的。
假設(shè)我們有這樣一張表:
create table tmp_a(
id bigint,
create_time datetime,
update_time datetime
);
一般離線場(chǎng)景下,都會(huì)選擇在業(yè)務(wù)量最少的時(shí)候去做同步操作,而這個(gè)時(shí)間大部分都是在半夜凌晨的時(shí)候,所以大部分同步都是從0點(diǎn)以后開始,同步昨天的數(shù)據(jù),也就是常說的T+1了。
假設(shè)3月1號(hào)創(chuàng)建了如下4條記錄,數(shù)倉會(huì)在2號(hào)凌晨進(jìn)行同步

2號(hào)的時(shí)候,新增了1條記錄,并且有一條記錄更新了,按照增量規(guī)則,我們會(huì)拿到兩條記錄

拿到增量數(shù)據(jù)之后,我們需要將增量的數(shù)據(jù)合并到我們數(shù)倉的表中
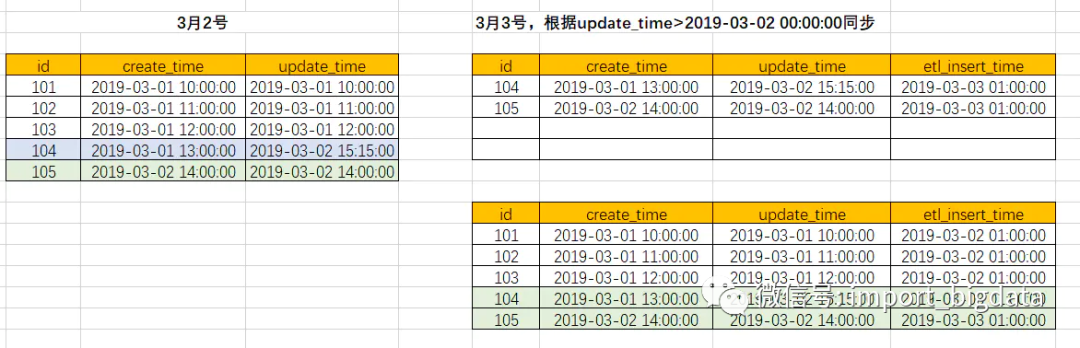
新增的數(shù)據(jù),可以直接插入,但是更新的數(shù)據(jù),我們需要把原紀(jì)錄更新掉,或者先刪除再插入,以前我們還會(huì)記錄一個(gè)數(shù)據(jù)插入的狀態(tài),如果是更新的,就記一個(gè)“update”,如果是插入的就記一個(gè)“insert”,到了這里,應(yīng)該知道為啥需要有主鍵了吧,如果沒有主鍵,你咋知道這條記錄到底變沒變過。
使用增量,一般需要兩套表,一套表用來存增量數(shù)據(jù),一套用來存完整的全量數(shù)據(jù)。
3. etl_insert_time
不管是增量還是全量,我都比較喜歡加一個(gè)時(shí)間戳字段,用來標(biāo)識(shí)記錄的插入時(shí)間,這個(gè)尤其是在對(duì)比增量數(shù)據(jù)的時(shí)候,排查數(shù)據(jù)問題很有用。
4. 我們公司的同步機(jī)制
我們呢,一創(chuàng)業(yè)公司,數(shù)據(jù)量不算多,使用的都是阿里云的工具,一開始為了方便,所有的數(shù)據(jù),都是全量來的,剛看了眼數(shù)據(jù)量又10幾T吧,其中很多是歷史數(shù)據(jù)。
雖然我們是全量來的,但是為了捕捉記錄數(shù)據(jù)的變化,用的是pt(分區(qū))的方式,每天都是一個(gè)全量快照,這也是現(xiàn)在存儲(chǔ)便宜的一種處理方法,簡(jiǎn)單粗暴。我剛來的時(shí)候,就提過搞成增量,被拒絕了,后來也沒有人來搞這個(gè),表太多了,修改起來成本太高。
5. 基于Hive的增量
Hive現(xiàn)在也算是標(biāo)配了,上面說的增量方案,可能還是基于關(guān)系型數(shù)據(jù)庫的,在Hive上,由于運(yùn)算能力更強(qiáng)大,可以不考慮數(shù)據(jù)量的問題,所以衍生出來幾種方案。主要原因還是Hive上對(duì)于delete操作的支持問題,盡量不要有delete。
排序(row_number)
我們依然每天獲取增量數(shù)據(jù),然后將增量數(shù)據(jù)插入到每個(gè)分區(qū)中,每個(gè)分區(qū)都是當(dāng)天的增量數(shù)據(jù),當(dāng)然數(shù)據(jù)變化的話,同一個(gè)主鍵的記錄會(huì)出現(xiàn)在多個(gè)分區(qū)中,所以如果我們要獲取最新的完整版數(shù)據(jù),可以使用row_number根據(jù)主鍵和時(shí)間排序,獲取最新版本的全量數(shù)據(jù)
full join
使用full join的方式,將增量數(shù)據(jù)和歷史全量數(shù)據(jù),進(jìn)行關(guān)聯(lián),然后取出最新完整版數(shù)據(jù)
left join + union all
這個(gè)和full join的方式類似,感覺這個(gè)更美觀嚴(yán)謹(jǐn)一些,以前在GP上面做增量也用的這種方式。
6. 拉鏈表
說到增量,也需要提一下拉鏈表,拉鏈表以前用的多一些,感覺在互聯(lián)網(wǎng)公司用的很少,基本都使用分區(qū)的方式處理掉了。拉鏈表其實(shí)就是記錄數(shù)據(jù)的每一次變化,處理起來稍微有點(diǎn)兒麻煩,這個(gè)以前好像寫過,等我找找貼過來。
上下游約定
由于數(shù)倉的特性和定位,它就需要強(qiáng)依賴上游的業(yè)務(wù)系統(tǒng),當(dāng)然也會(huì)有一些下游系統(tǒng),所以定好上下游的規(guī)范,變更的通知機(jī)制是非常有必要的。
感覺好像寫過上下游的事情,剛才沒找到,這里就再重新寫寫。
上游
這里說的主要是基于小公司,類似我目前所在的創(chuàng)業(yè)公司為例,像發(fā)展成熟的大公司,各種流程規(guī)定、容錯(cuò)監(jiān)控類的機(jī)制都很完善,對(duì)于這些場(chǎng)景,我說的可能就不適用了。
對(duì)于數(shù)倉來說,最重要的就是數(shù)據(jù)了,數(shù)倉中的數(shù)據(jù),主要來源是業(yè)務(wù)系統(tǒng),就是公司各種業(yè)務(wù)數(shù)據(jù),所以數(shù)倉需要不斷的將業(yè)務(wù)系統(tǒng)數(shù)據(jù)同步到自身平臺(tái)來,所以一旦上游業(yè)務(wù)系統(tǒng)發(fā)生變化,數(shù)倉也要同步變化,不然,這種同步操作很可能失敗。
表結(jié)構(gòu)變更
上游的表結(jié)構(gòu)經(jīng)常會(huì)發(fā)生變化,新增字段、修改字段、刪除字段(除非真的不用這個(gè)字段了,通常會(huì)選擇標(biāo)識(shí)為棄用)。表結(jié)構(gòu)最好要維護(hù)清楚,表名、字段名、字段類型、字段描述,都整理清楚,不使用的字段要么刪除,要么備注好,當(dāng)業(yè)務(wù)頻繁發(fā)生變化或者迭代優(yōu)化的時(shí)候,很容易出現(xiàn),我寫了半天的代碼,最后發(fā)現(xiàn)表用的不對(duì),字段用的不對(duì),這就尷尬了。
對(duì)于這種變化,人工處理的話,就是手動(dòng)在數(shù)倉對(duì)應(yīng)的表中增加、修改字段,然后修改同步任務(wù);這個(gè)最好可以搞成自動(dòng)化的,比如,自動(dòng)監(jiān)控上游表結(jié)構(gòu)的變更,變化后,自動(dòng)去修改數(shù)倉中的表結(jié)構(gòu),自動(dòng)修改同步任務(wù)。
枚舉值
業(yè)務(wù)系統(tǒng)中會(huì)有很多的常量,用來標(biāo)識(shí)一些狀態(tài)或者類型,這種值經(jīng)常會(huì)新增,數(shù)倉中會(huì)對(duì)這些值做些處理,比如轉(zhuǎn)換成維度,會(huì)翻譯成對(duì)應(yīng)的中文,而實(shí)際上這種映射關(guān)系,我們是不知道的,只有業(yè)務(wù)開發(fā)才知道,所以最好可以讓他們維護(hù)一張枚舉值表,我們?nèi)ネ竭@張表。
create_time & update_time
正常來說,create_time,當(dāng)這條記錄插入后,就不會(huì)再變了,但是某種情況下,哈哈,開發(fā)同學(xué)會(huì)去更新它;update_time,當(dāng)這條記錄變化后,這個(gè)時(shí)間也要變,有的開發(fā)同學(xué)不去更新它......
所以在做增量操作的時(shí)候,一定和開發(fā)說好這兩個(gè)字段的定義和使用場(chǎng)景。
is_delete & is_valid
有些場(chǎng)景下,我們需要?jiǎng)h除某些數(shù)據(jù),一般不會(huì)物理刪除,會(huì)通過一個(gè)字段來做邏輯刪除,請(qǐng)和開發(fā)同學(xué)溝通好,使用固定的一個(gè)字段,并確認(rèn)該字段雙方的理解是一致的,不然后面又很多坑。
下游
說完了上游,我們說說下游,對(duì)于數(shù)倉來說,一般的郵件、報(bào)表、可視化平臺(tái)都是下游,所以當(dāng)我們?cè)跀?shù)倉中進(jìn)行某些重構(gòu)、優(yōu)化操作的時(shí)候,也需要通知他們。
主要就是對(duì)數(shù)倉模型做好維護(hù),表的使用場(chǎng)景、字段描述等。
對(duì)上游的要求,自己也要做好,因?yàn)樽约阂彩巧嫌巍?/span>
任務(wù)注釋
這一篇說說注釋,注釋總是讓人又愛又恨。
沒有注釋,誰知道你這些代碼是用來干嘛的,從代碼角度來看,你想做的是A,而實(shí)際上需求確是B,具體干啥得靠猜;代碼有注釋,也不一定就可以高枕無憂,注釋可能是最初版的需求,改了幾版后,代碼早就變了,注釋沒有變,注釋和代碼不匹配,誰知道該以哪個(gè)為準(zhǔn)啊。
我們的數(shù)倉都是基于阿里云的,使用了它的DataWorks作為離線工具,所有的代碼都在這上面,所以這里簡(jiǎn)單介紹下,在阿里云上的任務(wù),幾點(diǎn)注釋規(guī)范。
-- @name p_dwd_rack_machine
-- @description 貨架寬表
-- @target rack.dwd_rack_machine
-- @source owo_ods.kylin__machine_release_his
-- @source owo_ods.kylin__machine_device_his
-- @author yuguiyang 2017-12-25
-- @modify
@name:任務(wù)的名字,我們的任務(wù)名一般都是以 p_目標(biāo)表名,后來阿里的DataWorks升級(jí)后,推薦是任務(wù)名和表名保持一致。
@description:任務(wù)描述,該任務(wù)的主要內(nèi)容 @target:目標(biāo)表名,一般一個(gè)任務(wù)只輸出一個(gè)目標(biāo)表
@source:來源表,就是任務(wù)中使用的底層表,這里也可以省略,從血緣關(guān)系中可以直接看到,而且很容易漏更新
@author:創(chuàng)建者,和創(chuàng)建日期, @modify:內(nèi)容變更記錄,變更人,變更日期,變更原因 ,這個(gè)從版本控制中也可以找到,但是這些這里更直觀一些。