ClickHouse 實踐 | ClickHouse 使用實踐與規(guī)范
導(dǎo)讀:
ClickHouse作為一款開源列式數(shù)據(jù)庫管理系統(tǒng)(DBMS)近年來備受關(guān)注,主要用于數(shù)據(jù)分析(OLAP)領(lǐng)域。作者根據(jù)以往經(jīng)驗和遇到的問題,總結(jié)出一些基本的開發(fā)和使用規(guī)范,以供使用者參考。
隨著公司業(yè)務(wù)數(shù)據(jù)量日益增長,數(shù)據(jù)處理場景日趨復(fù)雜,急需一種具有高可用性和高性能的數(shù)據(jù)庫來支持業(yè)務(wù)發(fā)展,ClickHouse是俄羅斯的搜索公司Yandex開源的MPP架構(gòu)的分析引擎,號稱比事務(wù)數(shù)據(jù)庫快100-1000倍,最大的特色是高性能的向量化執(zhí)行引擎,而且功能豐富、可靠性高。
在過去的一年中,杭研DBA團(tuán)隊已經(jīng)支撐網(wǎng)易集團(tuán)內(nèi)部多個事業(yè)部上線使用,集群規(guī)模共計十幾套,CPU近3000核,每日近千億數(shù)據(jù)入庫,千億級別表查詢可在秒級完成,大大提升了業(yè)務(wù)原有OLAP架構(gòu)的效能,覆蓋的業(yè)務(wù)場景包括:用戶行為日志分析,進(jìn)行PV、UV、留存、轉(zhuǎn)化漏斗和操作,包括游戲反外掛數(shù)據(jù)統(tǒng)計分析;用戶畫像,人群圈定和問卷投放;AB實驗數(shù)據(jù)的實時計算與分析;機(jī)器和業(yè)務(wù)日志的分析、監(jiān)控、查詢等。
ClickHouse應(yīng)用場景
1. 寫在前面
(1)如果你的業(yè)務(wù)預(yù)算或機(jī)器資源有限,強(qiáng)烈不推薦使用clickhouse,因為這套架構(gòu)成本比較高。
(2)最小集群部署所需機(jī)器:ck節(jié)點需要2臺256G內(nèi)存/40c cpu物理機(jī),磁盤使用SSD,加上3臺zookeeper和2臺chproxy應(yīng)用主機(jī)或者云主機(jī)。
(3)Clickhouse自帶了豐富的功能來應(yīng)對復(fù)雜的業(yè)務(wù)場景和大數(shù)據(jù)量,所以在使用期間需要運(yùn)維和開發(fā)側(cè)都投入人力對這些功能(表引擎類型)學(xué)習(xí)和掌握。
2. 業(yè)務(wù)在數(shù)據(jù)層的表現(xiàn)
(1)業(yè)務(wù)大多數(shù)是讀請求,存儲寬表,無大字段,較少的并發(fā)(單臺100-200qps左右)。
(2)數(shù)據(jù)批寫入(1000條以上,線上業(yè)務(wù)建議5w-10w),不修改或少修改已添加的數(shù)據(jù)。
(3)無事務(wù)要求,對數(shù)據(jù)一致性要求低。
(4)對于簡單查詢,允許延遲大約50毫秒,每一個查詢除了一個大表外都很小。
(5)處理單個查詢時需要高吞吐量(每個服務(wù)器每秒高達(dá)數(shù)十億行)。
3.具體業(yè)務(wù)場景
(1)用戶行為分析,精細(xì)化運(yùn)營分析:日活,留存率分析,路徑分析,有序漏斗轉(zhuǎn)化率分析,Session分析等;
(2)實時日志分析,監(jiān)控分析;
(3)實時數(shù)倉。
表引擎選擇
ClickHouse表引擎一共分為四個系列,分別是Log、MergeTree、Integration、Special。其中包含了兩種特殊的表引擎Replicated、Distributed,功能上與其他表引擎正交,目前業(yè)務(wù)上主要使用MergeTree系列,配合使用Mview和Distributed引擎。

ClickHouse 包含以下幾種常用的引擎類型:
MergeTree 引擎:該系列引擎是執(zhí)行高負(fù)載任務(wù)的最通用和最強(qiáng)大的表引擎,它們的特點是可以快速插入數(shù)據(jù)以及進(jìn)行后續(xù)的數(shù)據(jù)處理。該系列引擎還同時支持?jǐn)?shù)據(jù)復(fù)制(使用Replicated的引擎版本),分區(qū) (partition) 以及一些其它引擎不支持的額外功能。
Log 引擎:該系列引擎是具有最小功能的輕量級引擎。當(dāng)你需要快速寫入許多小表(最多約有100萬行)并在后續(xù)任務(wù)中整體讀取它們時使用該系列引擎是最有效的。
集成引擎:該系列引擎是與其它數(shù)據(jù)存儲以及處理系統(tǒng)集成的引擎,如 Kafka,MySQL 以及 HDFS 等,使用該系列引擎可以直接與其它系統(tǒng)進(jìn)行交互,但也會有一定的限制,如確有需要,可以嘗試一下。
特殊引擎:該系列引擎主要用于一些特定的功能,如 Distributed 用于分布式查詢,MaterializedView 用來聚合數(shù)據(jù),以及 Dictionary 用來查詢字典數(shù)據(jù)等。
在所有的表引擎中,最為核心的當(dāng)屬MergeTree系列表引擎,這些表引擎擁有最為強(qiáng)大的性能和最廣泛的使用場合。對于非MergeTree系列的其他引擎而言,主要用于特殊用途,場景相對有限。而MergeTree系列表引擎是官方主推的存儲引擎,支持幾乎所有ClickHouse核心功能,下面主要介紹MergeTree系列表引擎:
1. MergeTree表引擎
MergeTree在寫入一批數(shù)據(jù)時,數(shù)據(jù)總會以數(shù)據(jù)片段的形式寫入磁盤,且數(shù)據(jù)片段不可修改。為了避免片段過多,ClickHouse會通過后臺線程,定期合并這些數(shù)據(jù)片段,屬于相同分區(qū)的數(shù)據(jù)片段會被合成一個新的片段。這種數(shù)據(jù)片段往復(fù)合并的特點,也正是合并樹名稱的由來。
?MergeTree作為家族系列最基礎(chǔ)的表引擎,主要有以下特點:
存儲的數(shù)據(jù)按照主鍵排序:允許創(chuàng)建稀疏索引,從而加快數(shù)據(jù)查詢速度
支持分區(qū),可以通過PRIMARY KEY語句指定分區(qū)字段。
支持?jǐn)?shù)據(jù)副本
支持?jǐn)?shù)據(jù)采樣
?建表語法:
CREATE?TABLE?[IF?NOT?EXISTS]?[db.]table_name?[ON?CLUSTER?cluster](???name1?[type1]?[DEFAULT|MATERIALIZED|ALIAS?expr1]?[TTL?expr1],????name2?[type2]?[DEFAULT|MATERIALIZED|ALIAS?expr2]?[TTL?expr2],????...????INDEX?index_name1?expr1?TYPE?type1(...)?GRANULARITY?value1,????INDEX?index_name2?expr2?TYPE?type2(...)?GRANULARITY?value2)?ENGINE?=?MergeTree()ORDER?BY?expr[PARTITION?BY?expr][PRIMARY?KEY?expr][SAMPLE?BY?expr][TTL?expr?[DELETE|TO?DISK?'xxx'|TO?VOLUME?'xxx'],?...][SETTINGS name=value, ...]
ENGINE:ENGINE = MergeTree(),MergeTree引擎沒有參數(shù)
ORDER BY:排序字段。比如ORDER BY (Col1, Col2),值得注意的是,如果沒有指定主鍵,默認(rèn)情況下 sorting key(排序字段)即為主鍵。如果不需要排序,則可以使用ORDER BY tuple()語法,這樣的話,創(chuàng)建的表也就不包含主鍵。這種情況下,ClickHouse會按照插入的順序存儲數(shù)據(jù)。必選。
PARTITION BY:分區(qū)字段,強(qiáng)烈建議指定。
PRIMARY KEY:指定主鍵,如果排序字段與主鍵不一致,可以單獨指定主鍵字段。否則默認(rèn)主鍵是排序字段。可選。
SAMPLE BY:采樣字段,如果指定了該字段,那么主鍵中也必須包含該字段。比如SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。可選。
TTL:數(shù)據(jù)的存活時間。在MergeTree中,可以為某個列字段或整張表設(shè)置TTL。當(dāng)時間到達(dá)時,如果是列字段級別的TTL,則會刪除這一列的數(shù)據(jù);如果是表級別的TTL,則會刪除整張表的數(shù)據(jù)。大表強(qiáng)烈建議指定。
SETTINGS:額外的參數(shù)配置。一般設(shè)置index_granularity=8192 ,可選。
2. ReplicatedMergeTree表引
ReplicatedMergeTree使得以上 MergeTree 家族擁有副本機(jī)制,保證高可用,用于生產(chǎn)環(huán)境,對于大數(shù)據(jù)量的表來說不推薦使用,因為副本是基于zk做數(shù)據(jù)同步的,大數(shù)據(jù)量會對zk造成巨大壓力,成為整個ck整個集群瓶頸。業(yè)務(wù)可以根據(jù)數(shù)據(jù)重要程度在性能和數(shù)據(jù)副本之間做選擇。
建表示例:
CREATE?TABLE?[IF?NOT?EXISTS]?[db.]table_name?[ON?CLUSTER?cluster](`id`?Int64,?`ymd`?Int64)ENGINE?=?ReplicatedMergeTree('/clickhouse/tables/replicated/{shard}/test',?'{replica}')PARTITION?BY?ymdORDER BY id
/clickhouse/tables/ 這一部分指定的是在ZK上創(chuàng)建的路徑地址,可隨意變換只要記得即可
{shard} 指的是分片的標(biāo)志,同一個分片內(nèi)的所有機(jī)器應(yīng)該保持相同。建議使用使用的是集群名+分片名的配置也就是{layer}-{shard},這里的數(shù)據(jù)就是在macros中配置的屬性
test 建議使用表名稱
{replica} 參數(shù)建議在macros配置成機(jī)器的hostname,因為每臺機(jī)器的hostname都是不一樣的,因此就能確保每個表的識別符都是唯一的了
3. ReplacingMergeTree表引
上文提到MergeTree表引擎無法對相同主鍵的數(shù)據(jù)進(jìn)行去重,ClickHouse提供了ReplacingMergeTree引擎,可以針對相同主鍵的數(shù)據(jù)進(jìn)行去重,它能夠在合并分區(qū)時刪除重復(fù)的數(shù)據(jù)。值得注意的是,ReplacingMergeTree只是在一定程度上解決了數(shù)據(jù)重復(fù)問題,但是并不能完全保障數(shù)據(jù)不重復(fù)。
建表語法:
CREATE?TABLE?[IF?NOT?EXISTS]?[db.]table_name?[ON?CLUSTER?cluster](???name1?[type1]?[DEFAULT|MATERIALIZED|ALIAS?expr1],????name2?[type2]?[DEFAULT|MATERIALIZED|ALIAS?expr2],????...)?ENGINE?=?ReplacingMergeTree([ver])[PARTITION?BY?expr][ORDER?BY?expr][PRIMARY?KEY?expr][SAMPLE?BY?expr][SETTINGS name=value, ...]
[ver]:可選參數(shù),列的版本,可以是UInt、Date或者DateTime類型的字段作為版本號。該參數(shù)決定了數(shù)據(jù)去重的方式。
當(dāng)沒有指定[ver]參數(shù)時,保留最新的數(shù)據(jù);如果指定了具體的值,保留最大的版本數(shù)據(jù)。
注意點:
(1)去重規(guī)則
ReplacingMergeTree是支持對數(shù)據(jù)去重的,去除重復(fù)數(shù)據(jù)時,是以O(shè)RDERBY排序鍵為基準(zhǔn)的,而不是PRIMARY KEY。
(2)何時刪除重復(fù)數(shù)據(jù)
在執(zhí)行分區(qū)合并時,會觸發(fā)刪除重復(fù)數(shù)據(jù)。optimize的合并操作是在后臺執(zhí)行的,無法預(yù)測具體執(zhí)行時間點,除非是手動執(zhí)行。
(3)不同分區(qū)的重復(fù)數(shù)據(jù)不會被去重
ReplacingMergeTree是以分區(qū)為單位刪除重復(fù)數(shù)據(jù)的。只有在相同的數(shù)據(jù)分區(qū)內(nèi)重復(fù)的數(shù)據(jù)才可以被刪除,而不同數(shù)據(jù)分區(qū)之間的重復(fù)數(shù)據(jù)依然不能被剔除。
4. SummingMergeTree表引
該引擎繼承了MergeTree引擎,當(dāng)合并 SummingMergeTree 表的數(shù)據(jù)片段時,ClickHouse 會把所有具有相同主鍵的行合并為一行,該行包含了被合并的行中具有數(shù)值數(shù)據(jù)類型的列的匯總值,即如果存在重復(fù)的數(shù)據(jù),會對對這些重復(fù)的數(shù)據(jù)進(jìn)行合并成一條數(shù)據(jù),類似于group by的效果。
推薦將該引擎和 MergeTree 一起使用。例如,將完整的數(shù)據(jù)存儲在 MergeTree 表中,并且使用 SummingMergeTree 來存儲聚合數(shù)據(jù)。這種方法可以避免因為使用不正確的主鍵組合方式而丟失數(shù)據(jù)。
如果用戶只需要查詢數(shù)據(jù)的匯總結(jié)果,不關(guān)心明細(xì)數(shù)據(jù),并且數(shù)據(jù)的匯總條件是預(yù)先明確的,即GROUP BY的分組字段是確定的,可以使用該表引擎。
建表語法:
CREATE?TABLE?[IF?NOT?EXISTS]?[db.]table_name?[ON?CLUSTER?cluster](???name1?[type1]?[DEFAULT|MATERIALIZED|ALIAS?expr1],????name2?[type2]?[DEFAULT|MATERIALIZED|ALIAS?expr2],????????...)?ENGINE?=?SummingMergeTree([columns])?--?指定合并匯總字段[PARTITION?BY?expr][ORDER?BY?expr][SAMPLE?BY?expr][SETTINGS name=value, ...]
?注意點:
?要保證PRIMARY KEY expr指定的主鍵是ORDER BY expr 指定字段的前綴,比如
?-- 如下情況是允許的:
ORDER?BY?(A,B,C)PRIMARY KEY A
-- 如下情況會報錯:
DB::Exception:?Primary?key?must?be?a?prefix?of?the?sorting?keyORDER?BY?(A,B,C)PRIMARY?KEY?B
這種強(qiáng)制約束保障了即便在兩者定義不同的情況下,主鍵仍然是排序鍵的前綴,不會出現(xiàn)索引與數(shù)據(jù)順序混亂的問題。
總結(jié):
SummingMergeTree是根據(jù)什么對兩條數(shù)據(jù)進(jìn)行合并的用ORBER BY排序鍵作為聚合數(shù)據(jù)的條件Key。即如果排序key是相同的,則會合并成一條數(shù)據(jù),并對指定的合并字段進(jìn)行聚合。
僅對分區(qū)內(nèi)的相同排序key的數(shù)據(jù)行進(jìn)行合并以數(shù)據(jù)分區(qū)為單位來聚合數(shù)據(jù)。當(dāng)分區(qū)合并時,同一數(shù)據(jù)分區(qū)內(nèi)聚合Key相同的數(shù)據(jù)會被合并匯總,而不同分區(qū)之間的數(shù)據(jù)則不會被匯總。
如果沒有指定聚合字段,會怎么聚合如果沒有指定聚合字段,則會按照非主鍵的數(shù)值類型字段進(jìn)行聚合
對于非匯總字段的數(shù)據(jù),該保留哪一條如果兩行數(shù)據(jù)除了排序字段相同,其他的非聚合字段不相同,那么在聚合發(fā)生時,會保留最初的那條數(shù)據(jù),新插入的數(shù)據(jù)對應(yīng)的那個字段值會被舍棄。
5. Aggregatingmergetree表引
該表引擎繼承自MergeTree,可以使用 AggregatingMergeTree 表來做增量數(shù)據(jù)統(tǒng)計聚合。如果要按一組規(guī)則來合并減少行數(shù),則使用 AggregatingMergeTree 是合適的。
AggregatingMergeTree是通過預(yù)先定義的聚合函數(shù)計算數(shù)據(jù)并通過二進(jìn)制的格式存入表內(nèi)。與SummingMergeTree的區(qū)別在于:SummingMergeTree對非主鍵列進(jìn)行sum聚合,而AggregatingMergeTree則可以指定各種聚合函數(shù)。
建表語法:
CREATE?TABLE?[IF?NOT?EXISTS]?[db.]table_name?[ON?CLUSTER?cluster](????name1?[type1]?[DEFAULT|MATERIALIZED|ALIAS?expr1],?????????name2?[type2]?[DEFAULT|MATERIALIZED|ALIAS?expr2],?????????...)?ENGINE?=?AggregatingMergeTree()[PARTITION?BY?expr][ORDER?BY?expr][SAMPLE?BY?expr][SETTINGS name=value, ...]
?6. 其他特殊的表引
Distributed表引擎
Distributed表引擎是分布式表的代名詞,它自身不存儲任何數(shù)據(jù),數(shù)據(jù)都分散存儲在某一個分片上,能夠自動路由數(shù)據(jù)至集群中的各個節(jié)點,所以Distributed表引擎需要和其他數(shù)據(jù)表引擎一起協(xié)同工作。
所以,一張分布式表底層會對應(yīng)多個本地分片數(shù)據(jù)表,由具體的分片表存儲數(shù)據(jù),分布式表與本地分片數(shù)據(jù)表是一對多的關(guān)系。
Distributed表引擎的定義形式如下所示:
Distributed(cluster_name, database_name, table_name[, sharding_key])各個參數(shù)的含義分別如下:
cluster_name:集群名稱,與集群配置中的自定義名稱相對應(yīng)。
database_name:數(shù)據(jù)庫名稱
table_name:表名稱
sharding_key:可選的,用于分片的key值,在數(shù)據(jù)寫入的過程中,分布式表會依據(jù)分片key的規(guī)則,將數(shù)據(jù)分布到各個節(jié)點的本地表。
創(chuàng)建分布式表是讀時檢查的機(jī)制,也就是說對創(chuàng)建分布式表和本地表的順序并沒有強(qiáng)制要求。
同樣值得注意的是,在上面的語句中使用了ON CLUSTER分布式DDL,這意味著在集群的每個分片節(jié)點上,都會創(chuàng)建一張Distributed表,這樣便可以從其中任意一端發(fā)起對所有分片的讀、寫請求。
開發(fā)規(guī)范
?1. 查詢sql編寫規(guī)范
(1)當(dāng)多表聯(lián)查時,查詢的數(shù)據(jù)僅從其中一張表出時,可考慮使用IN操作而不是JOIN。
(2)多表查詢性能較差,多表Join時要滿足小表在右的原則,右表關(guān)聯(lián)時被加載到內(nèi)存中與左表進(jìn)行比較,ClickHouse中無論是Left Join 、Right Join還是Inner Join永遠(yuǎn)都是拿著右表中的每一條記錄到左表中查找該記錄是否存在,所以右表必須是小表。
(3)將一些需要關(guān)聯(lián)分析的業(yè)務(wù)創(chuàng)建成字典表進(jìn)行join操作,前提是字典表不宜太大,因為字典表會常駐內(nèi)存。
(4)禁?業(yè)務(wù)select *?,列存數(shù)據(jù),每減少一個字段會減少大量的數(shù)據(jù)掃描,提升查詢效率。
(5)建議使用 limit 限制返回數(shù)據(jù)條數(shù)使用limit返回指定的結(jié)果集數(shù)量,不會進(jìn)行向下掃描,大大提升了查詢效率。
(6)查詢時如果可以建議帶上分區(qū)鍵查詢,可以有效減少數(shù)據(jù)掃描量,提升查詢效率。
(7)CK的稀疏索引使得點查詢(即kv類型的查詢)性能不佳,千萬不要把它簡單當(dāng)做關(guān)系型數(shù)據(jù)庫進(jìn)行查詢。
(8)使用Global優(yōu)化分布式子查詢,避免出現(xiàn)查詢指數(shù)級放大。
(9)使用 uniqCombined 替代 distinctuniqCombined 對去重進(jìn)行了優(yōu)化,通過近似去重提升十倍查詢性能。
(10)盡量不去使用字符串類型,時間類型最終會轉(zhuǎn)換成數(shù)值類型進(jìn)行處理,數(shù)值類型在執(zhí)行效率和存儲上遠(yuǎn)好過字符串。
(11)ClickHouse的分布式表性能性價比不如物理表高,建表分區(qū)字段值不宜過多,防止數(shù)據(jù)導(dǎo)入過程磁盤可能會被打滿。
(12)不要在唯一列或大基數(shù)列上進(jìn)行分組或去重操作,基數(shù)太大會消耗過多的io和內(nèi)存。
(13)CPU一般在50%左右會出現(xiàn)查詢波動,達(dá)到70%會出現(xiàn)大范圍的查詢超時,CPU是最關(guān)鍵的指標(biāo),要非常關(guān)注。
?2. 數(shù)據(jù)寫入注意事項
(1)不適合高并發(fā)寫入,最好還是從異步化隊列寫入,batch insert 5w-10w 起步,盡量不要執(zhí)行單條或插入操作,會產(chǎn)生大量小分區(qū)文件,給后臺merge任務(wù)帶來巨大壓力。
(2)幾乎完全不支持update/delete,也不支持事務(wù)。
(3)建議表要指定分區(qū)鍵,尤其是數(shù)據(jù)量大的表,插入/查詢/合并都是以分區(qū)為單位,合理的分區(qū)可以提升整體性能。
(4)分區(qū)不建議太多,如果分區(qū)太多,會因需要打開的文件描述符過多導(dǎo)致查詢效率不佳。
(5)數(shù)據(jù)在寫入ClickHouse前預(yù)先的對數(shù)據(jù)進(jìn)行分組,避免一次插入的數(shù)據(jù)屬于多個分區(qū)。
(6)注意MerTree 主鍵允許存在重復(fù)數(shù)據(jù)(ReplacingMergeTree可以在分區(qū)內(nèi)去重)。
?3. 建表規(guī)范
(1)本地表命名格式:{tab_name}_local,分布式表命名格式:{tab_name}_shard 。
(2)物化視圖命名規(guī)范:{tabl_name_xxx}_mv 。
(3)盡量不要使用Nullable類型,該類型對性能有一定影響,且不能包含在索引中。
(4)合理設(shè)置分區(qū),所有本地表使用order by關(guān)鍵字指定分區(qū)字段,建議采用日期作為一級分區(qū)。默認(rèn) order by 字段作為主鍵。
(5)如果表中不是必須保留全量歷史數(shù)據(jù),建議指定TTL,可以免去手動過期歷史數(shù)據(jù)的麻煩。?
(6)所有復(fù)制引擎表建表指定 use_minimalistic_part_header_in_zookeeper=1。
??
?本地ReplicatedMergeTree表建表模板如下所示:
CREATE TABLE IF NOT EXISTS ads. ads_af_city_complaint_1d _local ON cluster ycdata_3shards_3replicas(`id`?UInt64?COMMENT?'序號',`order_id`?UInt64?COMMENT?'訂單號',`gross_weight`?UInt64??COMMENT?'權(quán)重',`create_time`?Date?COMMENT?'創(chuàng)建時間',`event`?String?COMMENT?'事件')ENGINE = ReplicatedMergeTree('/clickhouse/table/{shared}/ads_af_city_complaint_1d _local', '{replica}')PARTITION?BY?create_timeORDER?BY?idTTL create_time + toIntervalDay(90)SETTINGS?index_granularity?=?8192,?use_minimalistic_part_header_in_zookeeper?=?1;
解釋:
TTL 定義了數(shù)據(jù)保留策略為90天。
{shared},{replica}無需替換為一個具體值。
ycdata_3shards_3replicas為clickhouse是集群名稱。
集群架構(gòu)
?1. 常用架構(gòu)
為簡化業(yè)務(wù)使用方式,降低業(yè)務(wù)使用成本。對clickhouse集群的使用做一些約束,能夠提升交付速度,提高標(biāo)準(zhǔn)化程度,降低使用成本。
以4臺機(jī)器為例,集群模式固定為2分片2副本模式,若數(shù)據(jù)量較大4臺機(jī)器不夠時,可以增加2臺機(jī)器,集群模式未3分片每個分片2副本形式,另外需要3臺zookeeper和2臺chproxy應(yīng)用主機(jī)或者云主機(jī),兩臺chproxy使用NLB管理,程序直連NLB IP。
對于單表數(shù)據(jù)量超過100億數(shù)據(jù)的表不建議使用副本表,建議采用4分片0副本架構(gòu)。(具體架構(gòu)可以和DBA溝通后確定)
總體上講,一句話總結(jié):業(yè)務(wù)訪問統(tǒng)一入口,讀分布式表,寫本地表。
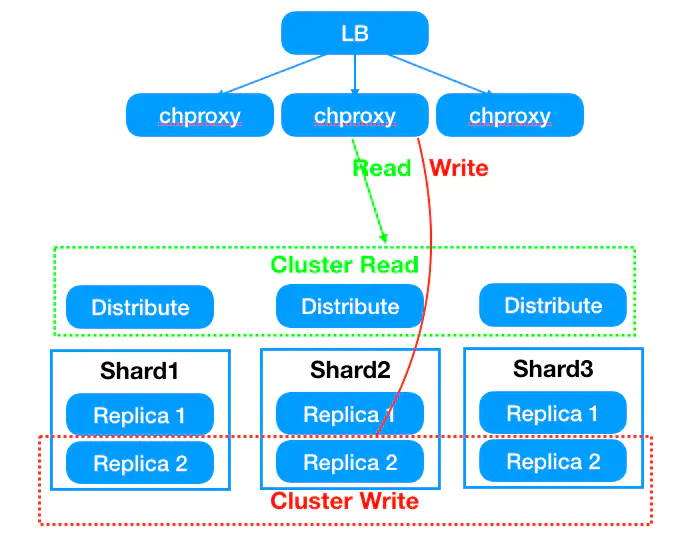
?優(yōu)勢:
?解決clickhouse集群高可用性,保證單機(jī)器宕機(jī)情況不影響集群可用性。
?解決寫入分布式表寫入效率低以及讀分布式表時熱點問題
?解決寫入本地表數(shù)據(jù)需要業(yè)務(wù)層路由的問題
?降低業(yè)務(wù)使用門檻,提升交付效率
限制:
(1)業(yè)務(wù)寫入本地表(以_local結(jié)尾),讀分布式表(以_shard結(jié)尾表)
業(yè)務(wù)表名為musci_bi_t1,則寫入musci_bi_t1_local 通過proxy代理輪詢寫入底層節(jié)點保證數(shù)據(jù)分布均衡;
讀musci_bi_t1_shard表,同樣可以通過proxy將shard表路由壓力分散到底層節(jié)點。
(2)業(yè)務(wù)寫入時需要批量寫入,需要業(yè)務(wù)去保證每批次數(shù)據(jù)量大小盡量一致,以保證數(shù)據(jù)盡量均勻分布。
(3)業(yè)務(wù)每批次寫入時都要重新獲取連接,禁止使用長連接否則無法使用負(fù)載均衡能力,會導(dǎo)致數(shù)據(jù)分布不均衡。
(4)不支持跨集群訪問
不同集群內(nèi)的分片以及副本數(shù)量不固定,可能會導(dǎo)致某些節(jié)點沒有l(wèi)ocal表,會使得寫入失敗;
統(tǒng)一集群名與database名,防止跨集群訪問。
問題:
因業(yè)務(wù)每批次寫入數(shù)據(jù)量的不同,會導(dǎo)致數(shù)據(jù)分布的不均勻。
運(yùn)維注意點:
對業(yè)務(wù)不透明,insert需要指定local結(jié)尾表,查詢需要查sharded表,需要與業(yè)務(wù)確認(rèn);
副本同步使用底層ReplicatedMergeTree引擎,提升副本同步性能以及數(shù)據(jù)一致性(需要手動創(chuàng)建底層表,保證主備關(guān)系正確);
使用on cluster 語法在每個節(jié)點中創(chuàng)建分布式表,提升建表效率。
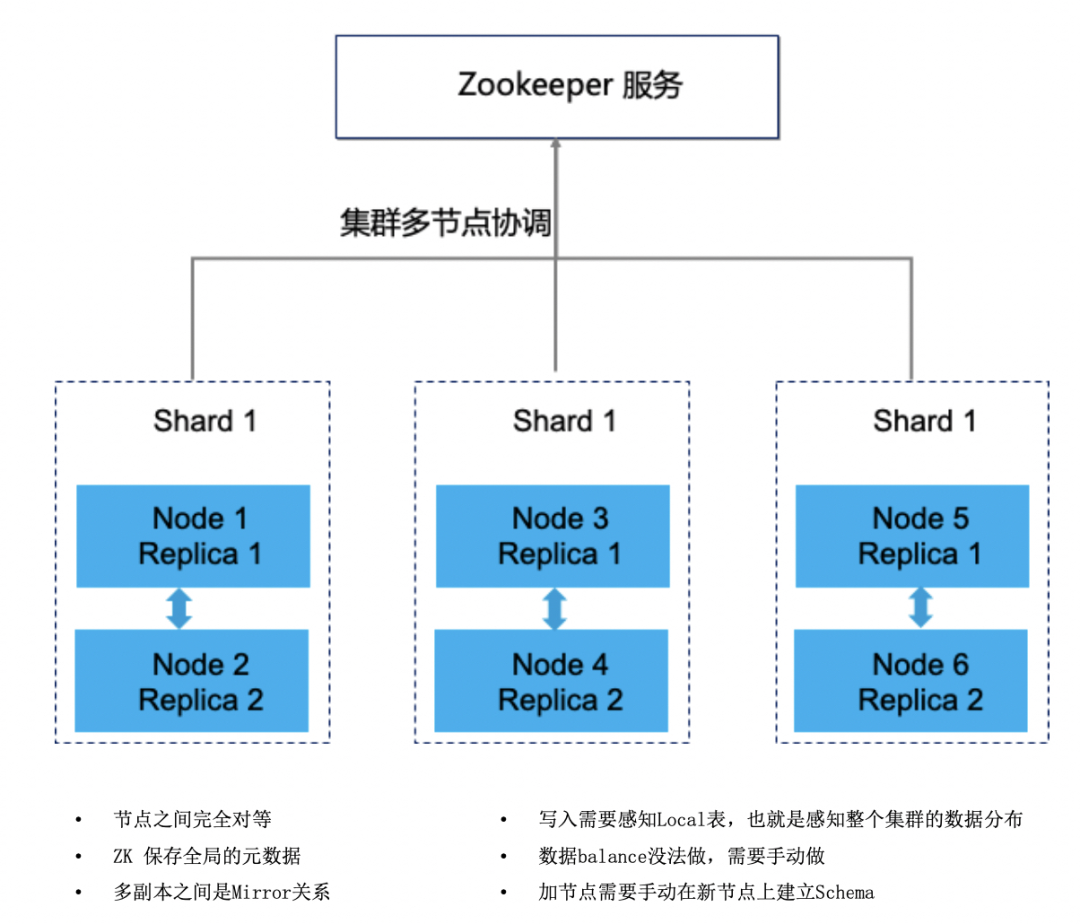
2. zookeeper的關(guān)鍵作用
ClickHouse中依賴Zookeeper解決的問題可以分為兩大類:分布式DDL執(zhí)行、ReplicatedMergeTree表主備節(jié)點之間的狀態(tài)同步。zk的性能會影響整個集群的性能表現(xiàn)。使用復(fù)制表之后,隨著數(shù)據(jù)量的增加,zookeeper可能成為集群瓶頸,zk集群建議機(jī)器配置如下:3臺32G/4c機(jī)器,萬兆網(wǎng)卡,磁盤80G-200G。
可以看作ck把zookeeper用成了目錄服務(wù),日志服務(wù)和協(xié)調(diào)服務(wù),當(dāng)znode達(dá)到幾百萬后,zk出現(xiàn)異常,常見是連接失敗,此時有些表會出現(xiàn)readonly模式。頭條對這個問題的處理方式是改寫源碼調(diào)整ck對zk的使用方式,為zk減重。
如果業(yè)務(wù)上單表數(shù)據(jù)量較大并且希望使用復(fù)制表,務(wù)必在建表時指定use_minimalistic_part_header_in_zookeeper參數(shù)為1,達(dá)到壓縮zk數(shù)據(jù)的目的。
3. chproxy
chproxy官方推薦的是專用于ClickHouse數(shù)據(jù)庫的HTTP代理和負(fù)載均衡器,使用go語言實現(xiàn),目前僅支持http協(xié)議。在Clickhouse集群中,每一臺機(jī)器都是單獨的實例,我們可以使用其中的一臺作為查詢機(jī)器。此時如何更好的完成負(fù)載均衡是我們所關(guān)注的,chproxy即是這么一個工具。
特性:
用戶路由和響應(yīng)緩存。
靈活的限制。
自動SSL證書續(xù)訂。
chroxy連接測試:
echo 'show databases;' | curl 'http://10.200.161.49:9009/?user=writeuser&password=xxxx' --data-binary @-關(guān)于chroxy參數(shù)配置可參照如下文檔:
https://github.com/ContentSquare/chproxy
?
客戶端工具選擇
1. DBeave
DBeaver是免費和開源(GPL)為開發(fā)人員和數(shù)據(jù)庫管理員通用數(shù)據(jù)庫工具。易用性是該項目的主要目標(biāo),是經(jīng)過精心設(shè)計和開發(fā)的數(shù)據(jù)庫管理工具。免費、跨平臺、基于開源框架和允許各種擴(kuò)展寫作(插件)。
2. Superse
Superset 是一款由 Airbnb 開源的“現(xiàn)代化的企業(yè)級 BI(商業(yè)智能) Web 應(yīng)用程序”,其通過創(chuàng)建和分享 dashboard,為數(shù)據(jù)分析提供了輕量級的數(shù)據(jù)查詢和可視化方案。
3. Tabi
功能和部署方式與Superset相似,可參考如下文檔:
https://github.com/smi2/tabix.ui/releases
可用性說明
根據(jù)選擇的集群架構(gòu)不同, clickhouse集群表現(xiàn)出的可用性也不同。
(1)數(shù)據(jù)的讀寫高可用就是依賴復(fù)制表引擎創(chuàng)建多副本機(jī)制保證。如果Clickhouse集群使用是多分片多副本架構(gòu),當(dāng)一個副本所在的機(jī)器宕機(jī)后,chproxy層會自動路由到可用的副本讀寫數(shù)據(jù);
(2)如果Clickhouse集群只用了sharding分片,沒有用到復(fù)制表作為數(shù)據(jù)副本,那么單臺機(jī)器宕機(jī)只會影響到單個數(shù)據(jù)分片的讀寫;
(3)當(dāng)zk集群不可用時,整個集群的寫入會都會受影響,不管有沒有使用復(fù)制表。
總結(jié):
數(shù)據(jù)可用性要求越高,意味著投入更多的資源,單臺機(jī)器的資源利用率越低,業(yè)務(wù)可根據(jù)數(shù)據(jù)重要程度靈活選擇,不過Clickhouse的定位是在線分析olap系統(tǒng),建議業(yè)務(wù)方將ck里的數(shù)據(jù)也定義為二級數(shù)據(jù),數(shù)據(jù)丟失后是可以再生成的,從而控制整體架構(gòu)的成本,提高單臺機(jī)器的資源利用率。同時強(qiáng)烈建議業(yè)務(wù)不要強(qiáng)依賴Clickhouse,要有一定的兜底和熔斷機(jī)制。
集群配置參數(shù)調(diào)優(yōu)
1. max_concurrent_querie
最大并發(fā)處理的請求數(shù)(包含select,insert等),默認(rèn)值100,推薦150(不夠再加),在我們的集群中出現(xiàn)過”max concurrent queries”的問題。
2. max_bytes_before_external_sor
當(dāng)order by已使用max_bytes_before_external_sort內(nèi)存就進(jìn)行溢寫磁盤(基于磁盤排序),如果不設(shè)置該值,那么當(dāng)內(nèi)存不夠時直接拋錯,設(shè)置了該值order by可以正常完成,但是速度相對內(nèi)存來說肯定要慢點(實測慢的非常多,無法接受)。
3. background_pool_size
后臺線程池的大小,merge線程就是在該線程池中執(zhí)行,當(dāng)然該線程池不僅僅是給merge線程用的,默認(rèn)值16,推薦32提升merge的速度(CPU允許的前提下)。
4. max_memory_usag
單個SQL在單臺機(jī)器最大內(nèi)存使用量,該值可以設(shè)置的比較大,這樣可以提升集群查詢的上限。
5. max_memory_usage_for_all_querie
單機(jī)最大的內(nèi)存使用量可以設(shè)置略小于機(jī)器的物理內(nèi)存(留一點內(nèi)操作系統(tǒng))。
?
6. max_bytes_before_external_group_b
在進(jìn)行g(shù)roup by的時候,內(nèi)存使用量已經(jīng)達(dá)到了max_bytes_before_external_group_by的時候就進(jìn)行寫磁盤(基于磁盤的group by相對于基于磁盤的order by性能損耗要好很多的),一般max_bytes_before_external_group_by設(shè)置為max_memory_usage / 2,原因是在clickhouse中聚合分兩個階段:
查詢并且建立中間數(shù)據(jù);
合并中間數(shù)據(jù) 寫磁盤在第一個階段,如果無須寫磁盤,clickhouse在第一個和第二個階段需要使用相同的內(nèi)存。
這些內(nèi)存參數(shù)強(qiáng)烈推薦配置上,增強(qiáng)集群的穩(wěn)定性避免在使用過程中出現(xiàn)莫名其妙的異常。
學(xué)習(xí)資料:
官網(wǎng)??
https://clickhouse.com/docs/en/engines/table-engines/integrations/
中文社區(qū)??
http://clickhouse.com.cn/
劉彥鵬,網(wǎng)易杭州研究院數(shù)據(jù)庫工程師。
最新的推文無法在第一時間看到?
以前的推文還需要復(fù)雜漫長的翻閱?
進(jìn)入“網(wǎng)易有數(shù)”公眾號介紹頁,點擊右上角
“設(shè)為星標(biāo)”!
置頂公眾號,從此消息不迷路