
簡單易懂 Flink 入門教程
最近公司要把Storm集群給下線啦,所以我們都得把Storm的任務(wù)都改成Flink。
于是最近入門了一把Flink,現(xiàn)在來分享一下Flink入門的相關(guān)知識。
不得不說,F(xiàn)link這兩年是真的火??這篇文章主要講講Flink入門時一些可能看不太懂的點(diǎn)又或是看官方介紹看不太懂的點(diǎn)(API我就不細(xì)說了,多用用應(yīng)該都能看懂)。
什么是Flink?
在Flink的官網(wǎng)上,可以把官方文檔語言設(shè)置為中文,于是我們可以看到官方是這樣介紹的:
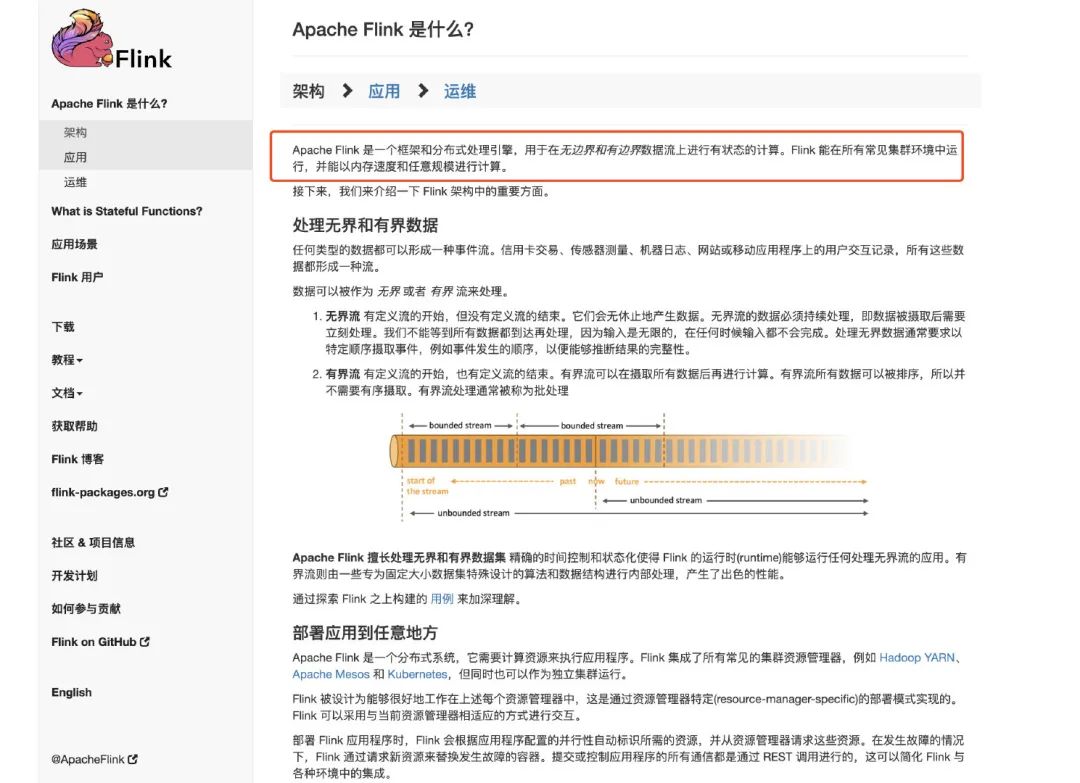
上面的圖我們每個字都能看得懂,但連起來就看不懂了。
不管怎么樣,我們可以了解到:Flink是一個分布式的計算處理引擎
分布式:「它的存儲或者計算交由多臺服務(wù)器上完成,最后匯總起來達(dá)到最終的效果」。
實(shí)時:處理速度是毫秒級或者秒級的
計算:可以簡單理解為對數(shù)據(jù)進(jìn)行處理,比如清洗數(shù)據(jù)(對數(shù)據(jù)進(jìn)行規(guī)整,取出有用的數(shù)據(jù))
基于官網(wǎng)的一句話介紹,我們就可以聯(lián)想出很多東西。
這篇文章可以帶你簡單認(rèn)識一下Flink的一些基礎(chǔ)概念,等你真正用到的時候就可以依據(jù)這篇文章來對Flink進(jìn)行入門,現(xiàn)在Storm都被很多人給拋棄掉了,那么Flink優(yōu)于Storm的地方有哪些呢?接下來我們一起來看看Flink吧。
什么是有邊界和無邊界?
Apache Flink 是一個框架和分布式處理引擎,用于在無邊界和有邊界數(shù)據(jù)流上進(jìn)行有狀態(tài)的計算。
官方其實(shí)也有介紹,但對初學(xué)者來說不太好理解,我來幼兒園化一下。
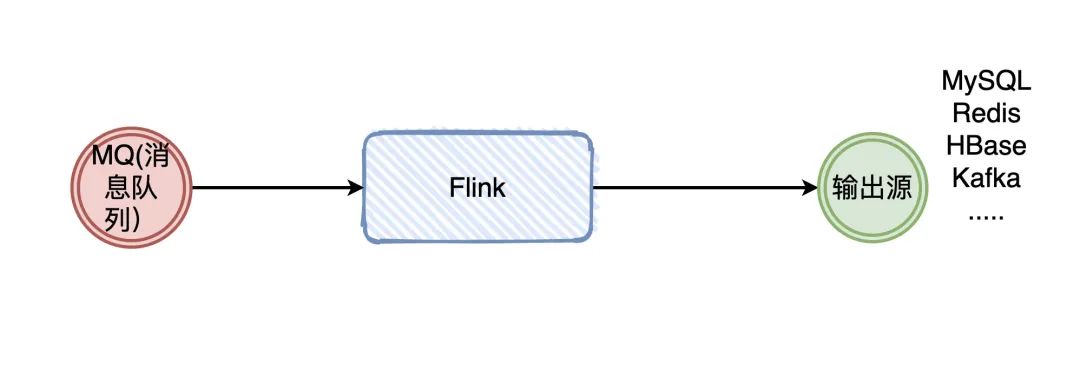
大家學(xué)到Flink了,消息隊列肯定有用過吧?那你們是怎么用消息隊列的呢?Producer生產(chǎn)數(shù)據(jù),發(fā)給Broker,Consumer消費(fèi),完事。
在消費(fèi)的時候,我們需要管什么Producer什么時候發(fā)消息嗎?不需要吧。反正來一條,我就處理一條,沒毛病吧。
這種沒有做任何處理的消息,默認(rèn)就是無邊界的。
那有邊界就很好理解了:無邊界的基礎(chǔ)上加上條件,那就是有邊界的。加什么條件呢?比如我要加個時間:我要消費(fèi)從8月8號到8月9號的數(shù)據(jù),那就是有邊界的。
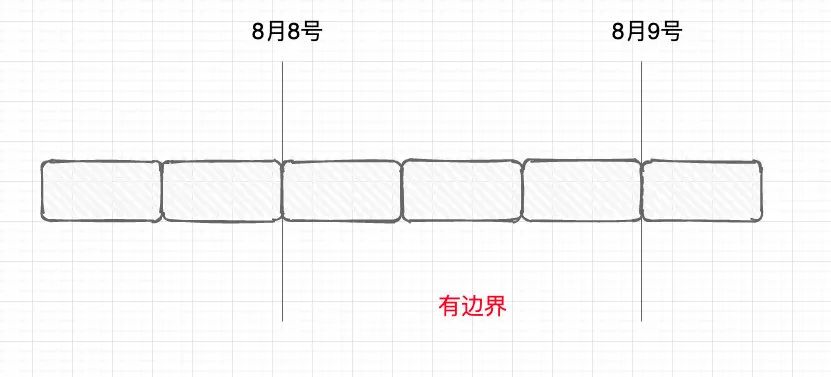
什么時候用無邊界,什么時候用有邊界?那也很好理解。我做數(shù)據(jù)清洗:來一條,我處理一條,這種無邊界的就好了。我要做數(shù)據(jù)統(tǒng)計:每個小時的pv(page view)是多少,那我就設(shè)置1小時的邊界,攢著一小時的數(shù)據(jù)來處理一次。
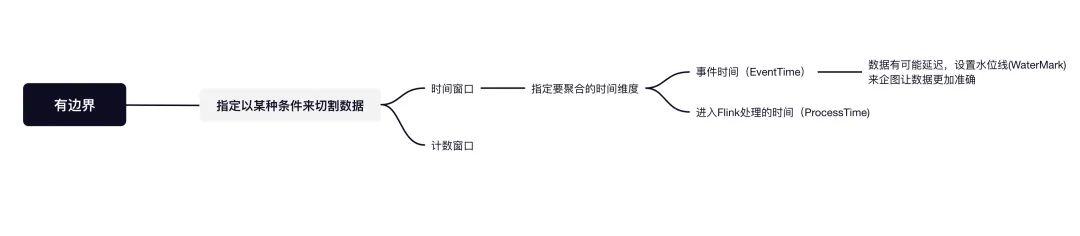
在Flink上,設(shè)置“邊界”這種操作叫做開窗口(Windows),窗口可簡單分為兩種類型:
時間窗口( TimeWindows):按照時間窗口進(jìn)行聚合,比如上面所講得攥著一個小時的數(shù)據(jù)處理一次。計數(shù)窗口( CountWindows):按照指定的條數(shù)來進(jìn)行聚合,比如每來了10條數(shù)據(jù)處理一次。
看著就非常人性化(媽媽再也不用擔(dān)心我需要聚合了)...
不僅如此,在Flink使用窗口聚合的時候,還考慮到了數(shù)據(jù)的準(zhǔn)確性問題。比如說:現(xiàn)在我在11:06分產(chǎn)生了5條數(shù)據(jù),在11:07分 產(chǎn)生了4條數(shù)據(jù),我現(xiàn)在是按每分鐘的維度來進(jìn)行聚合計算。
理論上來講:Flink應(yīng)該是在06分聚合了5條數(shù)據(jù),在07分聚合了4條數(shù)據(jù)。但是,可能由于網(wǎng)絡(luò)的延遲性等原因,導(dǎo)致06分的3條數(shù)據(jù)在07分時Flink才接收到。如果不做任何處理,那07分有可能處理了7條條數(shù)據(jù)。
某些需要準(zhǔn)確結(jié)果的場景來說,這就不太合理了。所以Flink可以給我們指定”時間語義“,不指定默認(rèn)是「數(shù)據(jù)到Flink的時間」Processing Time來進(jìn)行聚合處理,可以給我們指定聚合的時間以「事件發(fā)生的時間」Event Time來進(jìn)行處理。
事件發(fā)生的時間指的就是:日志真正記錄的時間
2020-11-22 00:00:02.552 INFO [http-nio-7001-exec-28] c.m.t.rye.admin.web.aop.LogAspect
雖然指定了聚合的時間為「事件發(fā)生的時間」Event Time,但還是沒解決數(shù)據(jù)亂序的問題(06分產(chǎn)生了5條數(shù)據(jù),實(shí)際上06分只收到了3條,而剩下的兩條在07分才收到,那此時怎么辦呢?在06分時該不該聚合,07分收到的兩條06分?jǐn)?shù)據(jù)怎么辦?)
Flink又可以給我們設(shè)置水位線(waterMarks),F(xiàn)link意思就是:存在網(wǎng)絡(luò)延遲等情況導(dǎo)致數(shù)據(jù)接收不是有序,這種情況我都能理解。你這樣吧,根據(jù)自身的情況,你可以設(shè)置一個「延遲時間」,等延遲的時間到了,我再聚合統(tǒng)一聚合。
比如說:現(xiàn)在我知道數(shù)據(jù)有可能會延遲一分鐘,那我將水位線waterMarks設(shè)置延遲一分鐘。
解讀:因為設(shè)置了「事件發(fā)生的時間」Event Time,所以Flink可以檢測到每一條記錄發(fā)生的時間,而設(shè)置了水位線waterMarks設(shè)置延遲一分鐘,等到Flink發(fā)現(xiàn)07分:59秒的數(shù)據(jù)來到了Flink,那就確信06分的數(shù)據(jù)都來了(因為設(shè)置了1分鐘延遲),此時才聚合06分的窗口數(shù)據(jù)。
什么叫做有狀態(tài)?
Apache Flink 是一個框架和分布式處理引擎,用于在無邊界和有邊界數(shù)據(jù)流上進(jìn)行有狀態(tài)的計算。
什么是有狀態(tài),什么是無狀態(tài)?
無狀態(tài)我們可以簡單認(rèn)為:每次的執(zhí)行都不依賴上一次或上N次的執(zhí)行結(jié)果,每次的執(zhí)行都是獨(dú)立的。
有狀態(tài)我們可以簡單認(rèn)為:執(zhí)行需要依賴上一次或上N次的執(zhí)行結(jié)果,某次的執(zhí)行需要依賴前面事件的處理結(jié)果。
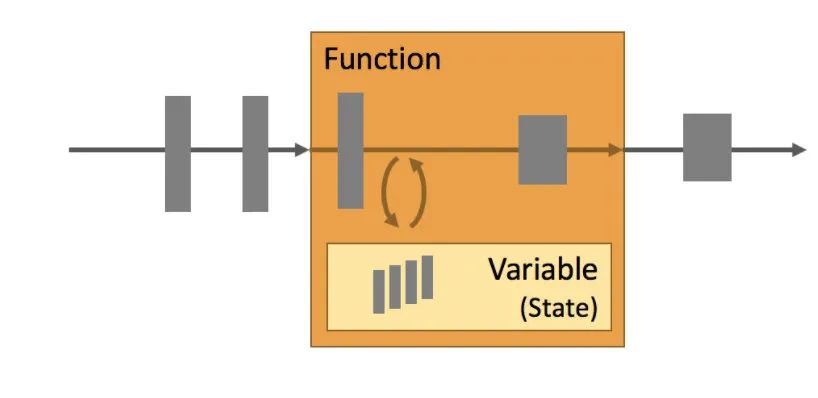
比如,我們現(xiàn)在要統(tǒng)計文章的閱讀PV(page view),現(xiàn)在只要有一個點(diǎn)擊了文章,在Kafka就會有一條消息。現(xiàn)在我要在流式處理平臺上進(jìn)行統(tǒng)計,那此時是有狀態(tài)的還是無狀態(tài)的?
假設(shè)我們要在Storm做,那我們可能將每次的處理結(jié)果放到一個“外部存儲”中,然后基于這個“外部存儲”進(jìn)行計算(這里我們不用Storm Trident),那此時Storm是無狀態(tài)的。
比如說:我存儲將每次得到的數(shù)據(jù)存儲到 Redis中,來一條數(shù)據(jù),我就先查一下Redis目前的值是多少,跟Redis的值和現(xiàn)在的值做一次累加就完事了。
假設(shè)要在Flink做,Flink本身就提供了這種功能給我們使用,我們可以依賴Flink的“存儲”,將每次的處理結(jié)果交由Flink管理,執(zhí)行計算的邏輯。
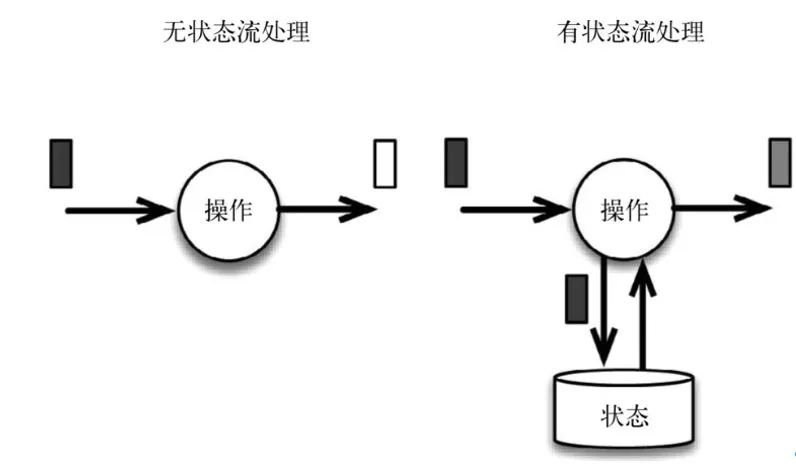
可以簡單的認(rèn)為:Flink本身就給我們提供了”存儲“的功能,而我們每次執(zhí)行是可以依賴Flink的”存儲”的,所以它是有狀態(tài)的。
那Flink是把這些有狀態(tài)的數(shù)據(jù)存儲在哪的呢?
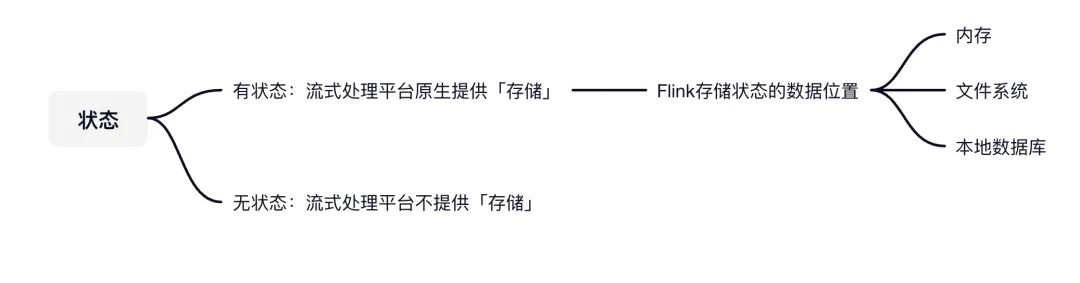
主要有三個地方:
內(nèi)存 文件系統(tǒng)(HDFS) 本地數(shù)據(jù)庫

如果假設(shè)Flink掛了,可能內(nèi)存的數(shù)據(jù)沒了,磁盤可能存儲了部分的數(shù)據(jù),那再重啟的時候(比如消息隊列會重新拉取),就不怕會丟了或多了數(shù)據(jù)嗎?
看到這里,你可能在會在別的地方看過Flink的另外一個比較出名的特性:精確一次性
(簡單來說就是:Flink遇到意外事件掛了以后,有什么機(jī)制來盡可能保證處理數(shù)據(jù)不重復(fù)和不丟失的呢)
什么是精確一次性(exactly once)?
眾所周知,流的語義性有三種:
精確一次性(exactly once):有且只有一條,不多不少 至少一次(at least once):最少會有一條,只多不少 最多一次(at most once):最多只有一條,可能會沒有
Flink實(shí)現(xiàn)了精確一次性,這個精確一次性是什么意思呢?
Flink的精確一次性指的是:狀態(tài)只持久化一次到最終的存儲介質(zhì)中(本地數(shù)據(jù)庫/HDFS...)
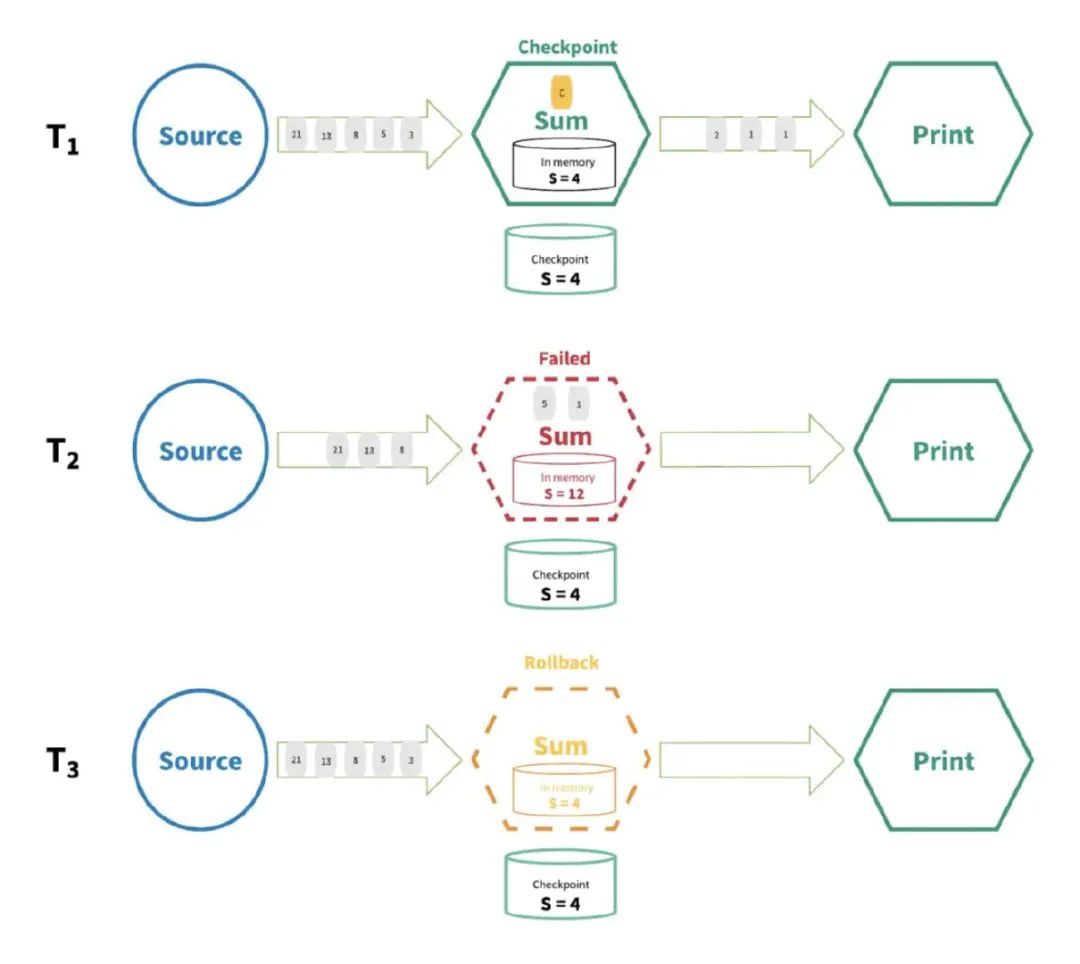
以上面的圖為例:Source數(shù)據(jù)流有以下數(shù)字21,13,8,5,3,2,1,1,然后在Flink需要做累加操作(求和)
現(xiàn)在處理完2,1,1了,所以累加的值是4,現(xiàn)在Flink把累積后的狀態(tài)4已經(jīng)存儲起來了(認(rèn)為前面2,1,1這幾個數(shù)字已經(jīng)完全處理過了)。
程序一直往下走,處理了5,3,現(xiàn)在累加的值是12,但現(xiàn)在Flink還沒來得及把12存儲到最終的介質(zhì),此時系統(tǒng)掛掉了。
Flink重啟后會重新把系統(tǒng)恢復(fù)到累加的值是4的狀態(tài),所以5,3得繼續(xù)計算一遍,程序繼續(xù)往下走。
看文章有的同學(xué)可能會認(rèn)為:精確一次性指的不是某一段代碼只會執(zhí)行一次,不會執(zhí)行多次或不執(zhí)行。這5和3這兩個數(shù),你不是重復(fù)計算了嗎?怎么就精確一次了?
顯然,代碼只執(zhí)行一次肯定是不可能的嘛。我們無法控制系統(tǒng)在哪一行代碼掛掉的,你要是在掛的時候,當(dāng)前方法還沒執(zhí)行完,你還是得重新執(zhí)行該方法的。
所以,狀態(tài)只持久化一次到最終的存儲介質(zhì)中(本地數(shù)據(jù)庫/HDFS),在Flink下就叫做exactly once(計算的數(shù)據(jù)可能會重復(fù)(無法避免),但狀態(tài)在存儲介質(zhì)上只會存儲一次)。
那么Flink是在多長時間存儲一次的呢?這個是我們自己手動配置的。

所謂的CheckPoint其實(shí)就是Flink會在指定的時間段上保存狀態(tài)的信息,假設(shè)Flink掛了可以將上一次狀態(tài)信息再撈出來,重放還沒保存的數(shù)據(jù)來執(zhí)行計算,最終實(shí)現(xiàn)exactly once。
那CheckPonit是怎么辦到的呢?想想我們在Kafka在業(yè)務(wù)上實(shí)現(xiàn)「至少一次」是怎么做的?我們從Kafka把數(shù)據(jù)拉下來,處理完業(yè)務(wù)了以后,手動提交offset (告訴Kafka我已經(jīng)處理完了)
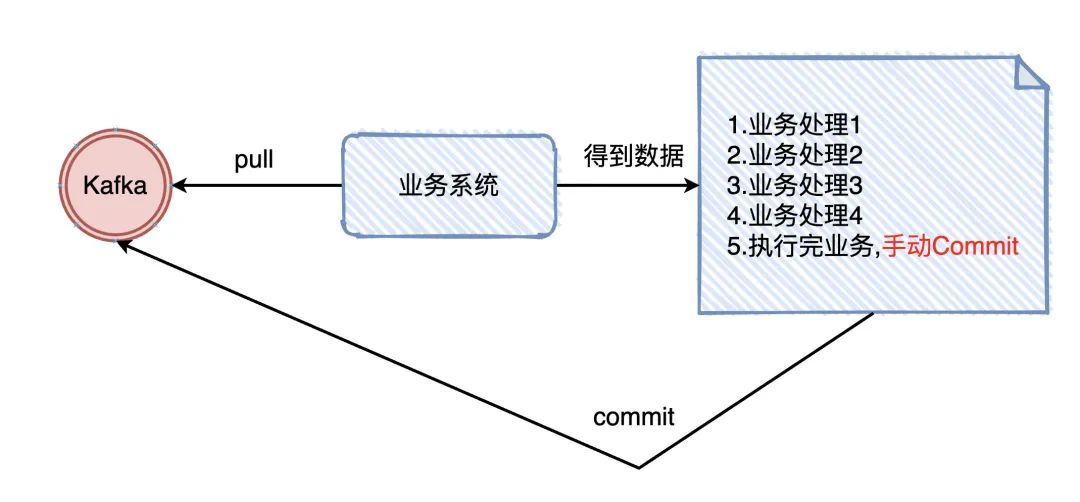
我們是做完了業(yè)務(wù)規(guī)則才將offset進(jìn)行commit的,checkponit其實(shí)也是一樣的(等拉下來該條數(shù)據(jù)所有的流程走完,才進(jìn)行真正的checkponit)。
問題又來了,那checkpoint是怎么知道拉下來的數(shù)據(jù)已經(jīng)走完了呢?Flink在流處理過程中插入了barrier,每個環(huán)節(jié)處理到barrier都會上報,等到sink都上報了barrier就說明這次checkpoint已經(jīng)走完了。
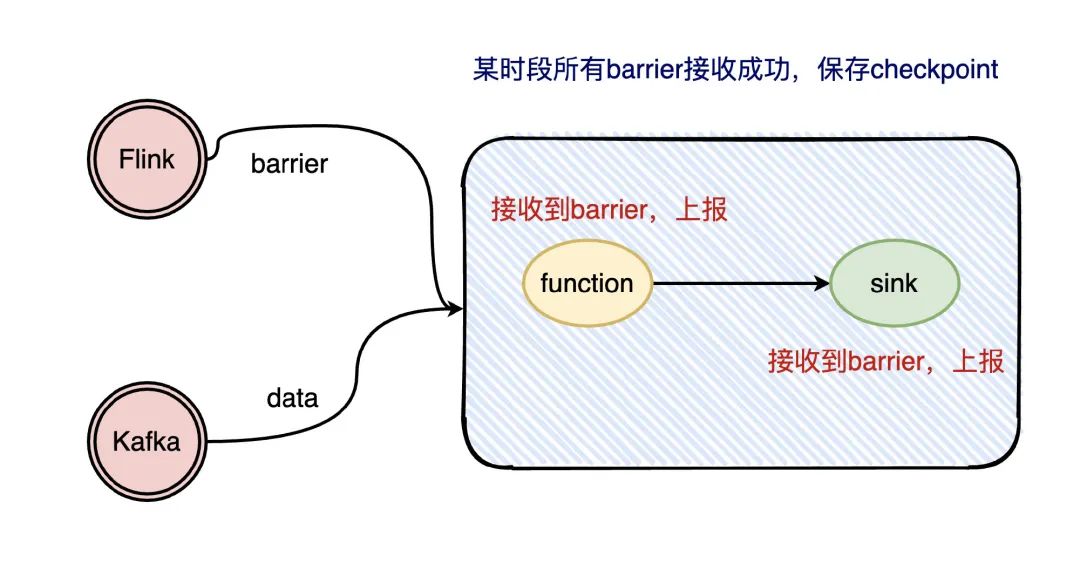
要注意的是,Flink實(shí)現(xiàn)的精確一次性只是保證內(nèi)部的狀態(tài)是精確一次的,如果想要端到端精確一次,需要端的支持
數(shù)據(jù)源需要可回放,發(fā)證故障可以重新讀取未確認(rèn)的數(shù)據(jù) Flink需要把數(shù)據(jù)存到磁盤介質(zhì)(不能用內(nèi)存),發(fā)生故障可以恢復(fù)發(fā)送源需要支持事務(wù)(從讀到寫需要事務(wù)的支持保證中途不失敗)
最后
這篇文章對Flink做了一次簡單的介紹,希望對大家在入門的時候有所幫助。后續(xù)打算會再寫一篇Flink文章對CheckPoint機(jī)制做更加深入的了解,有興趣的同學(xué)可以點(diǎn)個關(guān)注第一時間能接收到。