
JVM 面試必問(wèn)的 CMS,你懂了嗎?
前言
雖然 CMS 已經(jīng)是很古老的垃圾回收器了,大家現(xiàn)在動(dòng)不動(dòng)就G1、ZGC啥的,但是據(jù)我所了解,還是有很多公司的生產(chǎn)環(huán)境主要使用的 CMS,包括我自己呆過(guò)的幾家大廠也是。
因此在 JVM 面試中,CMS 也是問(wèn)的最多的,包括我自己現(xiàn)在面試別人時(shí),問(wèn)到 JVM 這一塊,我也喜歡從CMS開(kāi)始,逐漸深入。
不多廢話,今天我們就來(lái)盤(pán)他。
正文
1、什么是卡表(card table)?
試想一下,在進(jìn)行 YGC 時(shí),如何判斷是否存在老年代到新生代的引用?
一個(gè)簡(jiǎn)單的辦法是掃描整個(gè)老年代,但是這個(gè)代價(jià)太大了,因此 JVM 引入了卡表來(lái)解決這個(gè)問(wèn)題。
卡表又稱為卡片標(biāo)記(card marking),由 Paul R. Wilson 和 Thomas G. Moher 在1989年發(fā)表的論文里提出。
其原理為,在邏輯上將老年代空間分割為若干個(gè)固定大小的連續(xù)區(qū)域,分割出來(lái)的每一個(gè)個(gè)區(qū)域就稱為卡片(card)。另外,為每個(gè)卡片準(zhǔn)備一個(gè)與其對(duì)應(yīng)的標(biāo)記位,最簡(jiǎn)單的實(shí)現(xiàn)方案是由字節(jié)數(shù)組實(shí)現(xiàn),以卡的編號(hào)作為索引。每個(gè)卡的大小通常介于128~512字節(jié)之間,一般使用2的冪字節(jié)大小,例如HotSpot使用512字節(jié)。
當(dāng)卡片內(nèi)部發(fā)生引用變化時(shí)(指針寫(xiě)操作),寫(xiě)屏障會(huì)將該卡在卡表中對(duì)應(yīng)的字節(jié)標(biāo)記為臟(dirty)。
有了卡表后,在 YGC 時(shí),只需將卡表中被標(biāo)記為 dirty 的 card 也作為掃描范圍,就可以保障不掃描整個(gè)老年代也不會(huì)有遺漏了。
2、什么是 mod-union table?
通過(guò)上面對(duì) card table 的介紹,我們知道 card table 會(huì)記錄下老年代所有發(fā)生過(guò)引用變化對(duì)象所在的 card,而 CMS 在并發(fā)標(biāo)記等階段,也需要記錄下老年代發(fā)生引用變化的對(duì)象以便后續(xù)重新掃描,是否可以直接復(fù)用 card table?
答案是不行的,這是因?yàn)?/span>每次 YGC 過(guò)程中都涉及重置和重新掃描 card table,這樣是滿足了 YGC 的需求,但卻破壞了CMS的需求,CMS 需要的信息可能被 YGC 給重置掉了。為了避免丟失信息,于是在 card table 之外另外加了一個(gè) Bitmap 叫做 mod-union table。
在 CMS 并發(fā)標(biāo)記正在運(yùn)行的過(guò)程中,每當(dāng)發(fā)生一次 YGC,當(dāng) YGC 要重置 card table 里的某個(gè)記錄時(shí),就會(huì)更新 mod-union table 對(duì)應(yīng)的 bit,相當(dāng)于將 card table 里的信息轉(zhuǎn)移到了 mod-union table 里。
這樣,最后到 Final remark 的時(shí)候,card table 加 mod-union table 就足以記錄在并發(fā)標(biāo)記過(guò)程中老年代發(fā)生的所有引用變化了。
3、CMS 垃圾收集的過(guò)程?
CMS 垃圾收集的過(guò)程網(wǎng)上通常有兩個(gè)版本,4個(gè)步驟的和7個(gè)步驟的,兩個(gè)版本其實(shí)都是對(duì)的。
4個(gè)步驟應(yīng)該主要是跟隨周志明的說(shuō)法,而 CMS 的相關(guān)論文其實(shí)也是按4個(gè)步驟介紹。
7個(gè)步驟則應(yīng)該更多是從 CMS 的日志得出的說(shuō)法,而7個(gè)步驟里其實(shí)也包含了上述的4個(gè)步驟,可以理解為7個(gè)步驟是更細(xì)的說(shuō)法。
個(gè)人而言,我會(huì)更喜歡7個(gè)步驟的說(shuō)法,因此這邊介紹下7個(gè)步驟的過(guò)程。
1)初始標(biāo)記(Initial Mark)
STW(stop the world),遍歷 GC Roots,標(biāo)記 GC Root 直達(dá)的對(duì)象。
2)并發(fā)標(biāo)記(Concurrent Mark)
從初始標(biāo)記階段被標(biāo)記為存活的對(duì)象作為起點(diǎn),向下遍歷,找出所有存活的對(duì)象。
同時(shí),由于該階段是用戶線程和GC線程并發(fā)執(zhí)行,對(duì)象之間的引用關(guān)系在不斷發(fā)生變化,對(duì)于這些對(duì)象,都是需要進(jìn)行重新標(biāo)記的,否則就會(huì)出現(xiàn)錯(cuò)誤。為了提升重新標(biāo)記的效率,JVM 會(huì)使用寫(xiě)屏障(write barrier)將發(fā)生引用關(guān)系變化的對(duì)象所在的區(qū)域?qū)?yīng)的 card 標(biāo)記為 dirty,后續(xù)只需要掃描這些 dirty card 區(qū)域即可,避免掃描整個(gè)老年代。
3)并發(fā)預(yù)處理(Concurrent Preclean)
該階段存在的意義主要是為了盡可能降低 Final Remark 階段的耗時(shí),因?yàn)?nbsp;Final Remark 階段是 STW 的。
該階段主要做的事是將上一階段被標(biāo)記為 dirty 的 card 所對(duì)應(yīng)的區(qū)域進(jìn)行重新掃描標(biāo)記,處理并發(fā)階段發(fā)生引用變化的對(duì)象。
4)可中斷的并發(fā)預(yù)處理(Concurrent Abortable Preclean)
該階段和并發(fā)預(yù)處理做的事是基本一樣的,也是主要處理 dirty card。區(qū)別在于并發(fā)預(yù)處理只執(zhí)行一次,而本階段會(huì)一直循環(huán)執(zhí)行,直到觸發(fā)終止條件。
終止條件有以下幾個(gè):
循環(huán)次數(shù)超過(guò)閾值 CMSMaxAbortablePrecleanLoops,默認(rèn)是0,也就是沒(méi)有循環(huán)次數(shù)的限制。
處理時(shí)間達(dá)到了閾值 CMSMaxAbortablePrecleanTime,默認(rèn)是5秒。
Eden區(qū)的內(nèi)存使用率達(dá)到了閾值 CMSScheduleRemarkEdenPenetration,默認(rèn)為50%。
同時(shí)該階段有一個(gè)觸發(fā)前提:
Eden 區(qū)的內(nèi)存使用量大于參數(shù)CMSScheduleRemarkEdenSizeThreshold,默認(rèn)是2M。
5)最終標(biāo)記/重新標(biāo)記(Final Remark)
STW(stop the world),主要做兩件事:
遍歷 GCRoots,重新掃描標(biāo)記
遍歷被標(biāo)記為 dirty 的 card,重新掃描標(biāo)記
6)并發(fā)清理(Concurrent Sweep)
清理未使用的對(duì)象并回收它們占用的空間。
7)并發(fā)重置(Concurrent Reset)
重置 CMS 算法用于打標(biāo)的數(shù)據(jù)結(jié)構(gòu)(markBitMap),為下一次收集做準(zhǔn)備。
4、CMS存在的問(wèn)題
1)使用的標(biāo)記-清除算法,可能存在大量空間碎片。
調(diào)優(yōu):開(kāi)啟CMS壓縮,查看參數(shù)是否合理。
// 開(kāi)啟CMS壓縮,在FGC時(shí)執(zhí)行壓縮,默認(rèn)為true-XX:+UseCMSCompactAtFullCollection// 執(zhí)行幾次FGC才執(zhí)行壓縮,默認(rèn)為0-XX:CMSFullGCsBeforeCompaction=0
2)并發(fā)清理可能出現(xiàn)“Concurrent Mode Failure”失敗而導(dǎo)致另一次Full GC的產(chǎn)生
調(diào)優(yōu):可能是觸發(fā)GC的比例太高,適當(dāng)調(diào)低該值。
// CMS觸發(fā)GC的比例-XX:+UseCMSInitiatingOccupancyOnly-XX:+CMSInitiatingOccupancyFraction=70
3)對(duì)CPU資源非常敏感。在并發(fā)階段,會(huì)因?yàn)檎加昧艘徊糠志€程(或者說(shuō)CPU資源)而導(dǎo)致應(yīng)用程序變慢,總吞吐量會(huì)降低。CMS默認(rèn)啟動(dòng)的回收線程數(shù)是(CPU數(shù)量+3)/4。
調(diào)優(yōu):可能是并發(fā)線程數(shù)設(shè)置太高,適當(dāng)調(diào)低該值。
// CMS并發(fā)線程數(shù)-XX:ConcGCThreads=X
以上的調(diào)優(yōu)只是針對(duì)一些可能性較大的問(wèn)題給的建議,具體還是需要結(jié)合場(chǎng)景和完整的JVM參數(shù)去分析,各個(gè)參數(shù)可能都會(huì)影響到整體的GC效率。
5、Final Remark 階段為什么還需要遍歷 GCRoots?
這是因?yàn)?CMS 的寫(xiě)屏障(write barrier)并不是對(duì)所有會(huì)導(dǎo)致引用變化的字節(jié)碼生效,例如不支持 astore_X(把棧頂?shù)闹荡娴奖镜刈兞勘恚?/span>
至于為什么不為 astore_X 添加寫(xiě)屏障,R 大認(rèn)為是棧和年輕代屬于數(shù)據(jù)快速變化的區(qū)域,對(duì)于這些區(qū)域使用寫(xiě)屏障的收益比較差。
6、Final Remark 階段還需要遍歷 GC Roots,那之前的標(biāo)記工作不是白做了?
不是的。
在三色標(biāo)記法中(見(jiàn)下面介紹),如果掃描到被標(biāo)記為黑色的對(duì)象就會(huì)終止,而之前的并發(fā)標(biāo)記和預(yù)處理已經(jīng)完成了絕大部分對(duì)象的標(biāo)記,也就是此時(shí)大部分對(duì)象已經(jīng)是黑色了,因此 Final Remark 階段的工作其實(shí)會(huì)減少很多。簡(jiǎn)單來(lái)說(shuō)就是:遍歷的廣度不變,但是深度變淺了。
7、三色標(biāo)記算法?
三色標(biāo)記算法由 Edsger W. Dijkstra 等人在1978年提出,是一種增量式垃圾回收算法,增量式的意思是慢慢發(fā)生變化的意思,也就是 GC 和 mutator(應(yīng)用程序)一點(diǎn)點(diǎn)交替運(yùn)行的手法。
與其相反的則是停止型GC,也就是GC時(shí),mutator 完全停止,GC結(jié)束再恢復(fù)運(yùn)行。
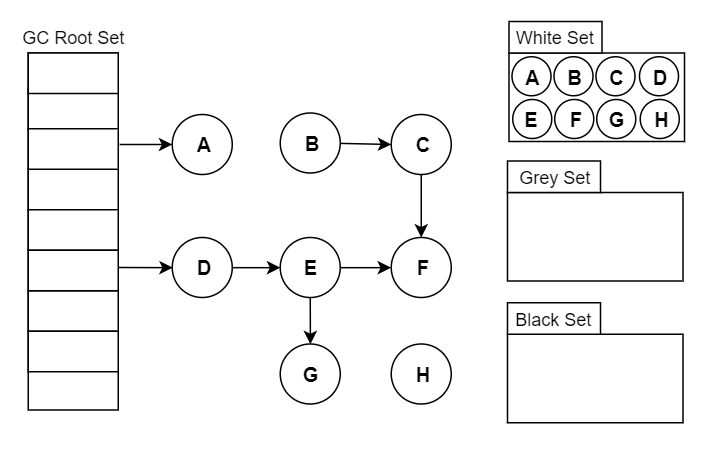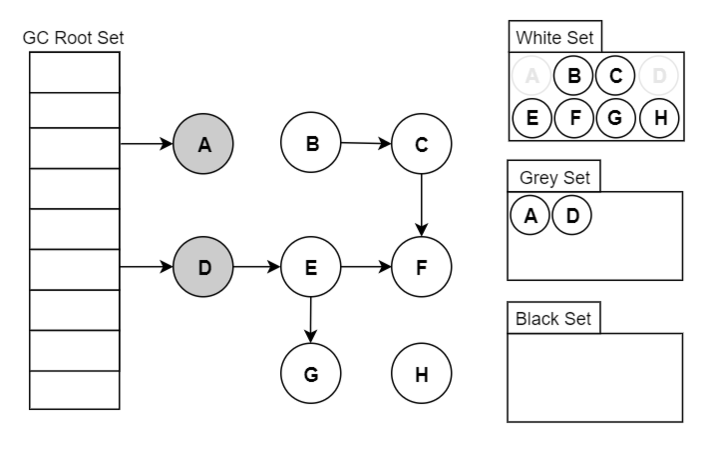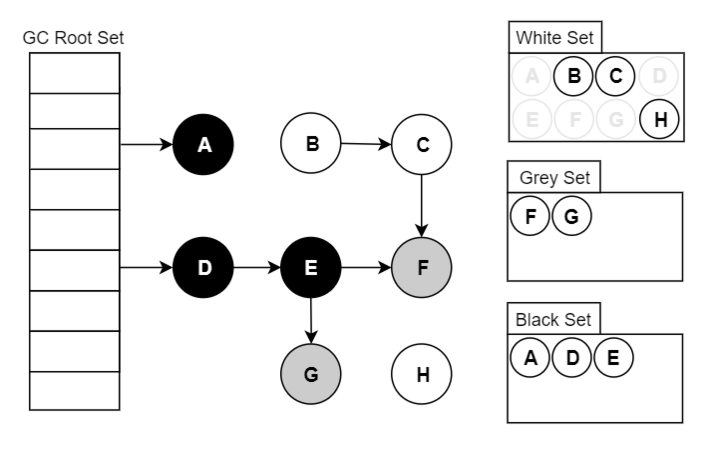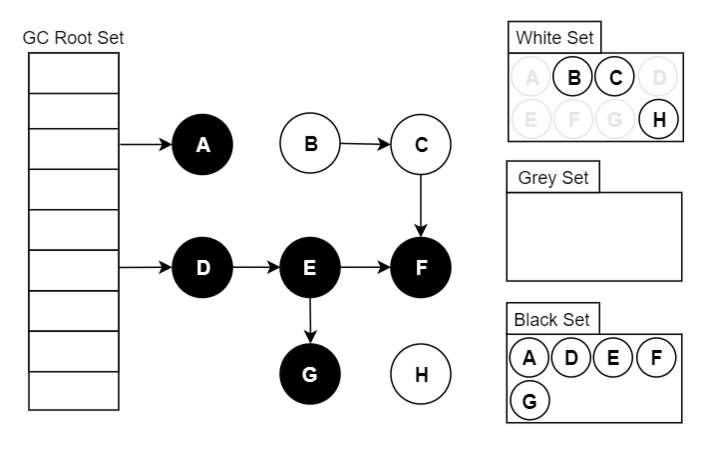
三色標(biāo)記算法顧名思義就是將 GC 中的對(duì)象分為三種顏色,這三種顏色和所包含的意思如下:
白色:還未搜索過(guò)的對(duì)象。在回收周期的開(kāi)始階段,所有對(duì)象都為白色,而在回收周期結(jié)束時(shí),所有白色對(duì)象均為不可達(dá)對(duì)象,也就是要回收的對(duì)象。
灰色:正在搜索的對(duì)象。已經(jīng)被搜索過(guò)的對(duì)象,但是該對(duì)象引用的對(duì)象還未被全部搜索完畢。
黑色:搜索完成的對(duì)象。本身及其引用的所有對(duì)象都被搜索過(guò),黑色對(duì)象不會(huì)指向白色對(duì)象,同時(shí)黑色對(duì)象不會(huì)被重新搜索,除非顏色發(fā)生變化。
我們以 GC 標(biāo)記-清除算法為例簡(jiǎn)單的說(shuō)明一下。
GC 開(kāi)始運(yùn)行前所有的對(duì)象都是白色。GC 一開(kāi)始運(yùn)行,所有從根能到達(dá)的對(duì)象都會(huì)被標(biāo)記為灰色,然后被放到棧里。GC 只是發(fā)現(xiàn)了這樣的對(duì)象,但還沒(méi)有搜索完它們,所以這些對(duì)象就成了灰色對(duì)象。
灰色對(duì)象會(huì)被依次從棧中取出,其子對(duì)象也會(huì)被涂成灰色。當(dāng)其所有的子對(duì)象都被涂成灰色時(shí),該對(duì)象就會(huì)被涂成黑色。當(dāng) GC 結(jié)束時(shí)已經(jīng)不存在灰色對(duì)象了,活動(dòng)對(duì)象全部為黑色,垃圾則為白色。
下面是一個(gè)三色標(biāo)記算法的示例動(dòng)圖,大家參考著理解。
明白了三色標(biāo)記算法后,再回過(guò)頭去看第5題,是不是頓時(shí)就明白了。
8、三色標(biāo)記算法存在的問(wèn)題?
三色標(biāo)記算法是增量式垃圾回收算法,mutator可能會(huì)隨時(shí)改變對(duì)象引用關(guān)系,因此在并發(fā)下會(huì)存在漏標(biāo)和錯(cuò)標(biāo)(多標(biāo))。
1)漏標(biāo)
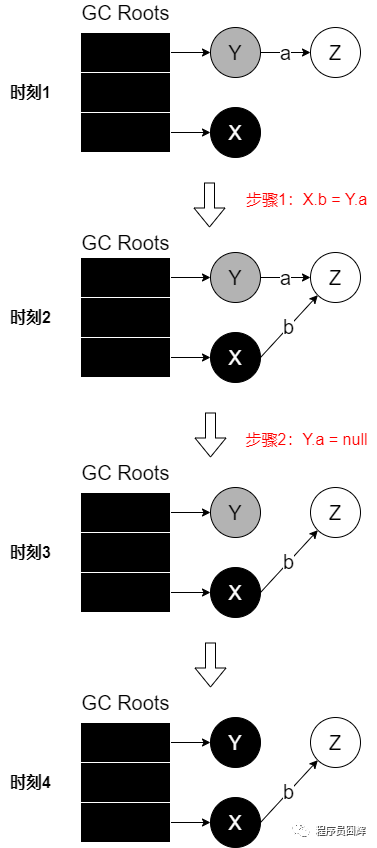
直接通過(guò)一個(gè)簡(jiǎn)單的例子來(lái)看:
假設(shè)當(dāng)GC線程執(zhí)行到時(shí)刻1時(shí),此時(shí)應(yīng)用線程先執(zhí)行了步驟1和2,也就是到了時(shí)刻3的場(chǎng)景,GC線程繼續(xù)執(zhí)行。
此時(shí)對(duì)象Z只被黑色對(duì)象X所引用,而黑色對(duì)象是不會(huì)被繼續(xù)掃描的,因此掃描結(jié)束后Z仍然是白色對(duì)象,也就是時(shí)刻4,此時(shí)白色對(duì)象Z則會(huì)被當(dāng)做垃圾而回收。
2)錯(cuò)標(biāo)(多標(biāo))
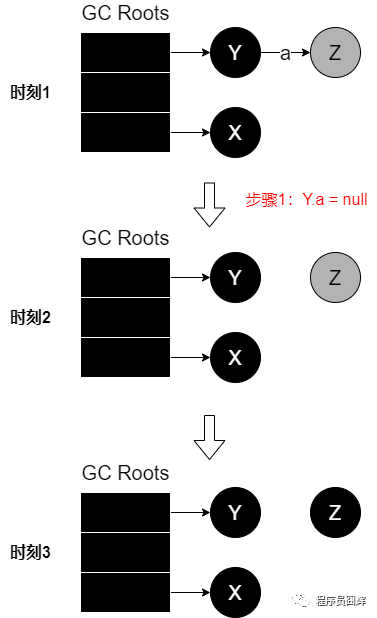
直接通過(guò)一個(gè)簡(jiǎn)單的例子來(lái)看:
假設(shè)當(dāng)GC線程執(zhí)行到時(shí)刻1時(shí),此時(shí)應(yīng)用線程先執(zhí)行了步驟1,也就是到了時(shí)刻2的場(chǎng)景,GC線程繼續(xù)執(zhí)行。
此時(shí)對(duì)象Z是灰色對(duì)象,GC線程對(duì)其進(jìn)行搜索,搜索結(jié)束后將其標(biāo)記為黑色,也就是時(shí)刻3,此時(shí)對(duì)象Z其實(shí)沒(méi)有到GC Roots的引用,理應(yīng)被回收,但是因?yàn)楸诲e(cuò)誤的標(biāo)記為黑色,而在本次GC中存活了下來(lái)。
錯(cuò)標(biāo)和漏標(biāo)都是三色標(biāo)記算法存在的問(wèn)題,但是兩者帶來(lái)的后果有本質(zhì)的不同。
錯(cuò)標(biāo)使得死亡的對(duì)象被當(dāng)做存活,導(dǎo)致出現(xiàn)浮動(dòng)垃圾,此時(shí)不影響程序的正確性,這些對(duì)象下次GC時(shí)回收就可以了。
漏標(biāo)使得存活的對(duì)象被當(dāng)做死亡,這個(gè)會(huì)導(dǎo)致程序出錯(cuò),帶來(lái)不可預(yù)知的后果,這個(gè)是不能接受的,因此漏標(biāo)是三色標(biāo)記算法需要解決的問(wèn)題。
通過(guò)實(shí)驗(yàn)追蹤,Wilson 發(fā)現(xiàn),只有當(dāng)以下兩個(gè)條件同時(shí)滿足時(shí)才會(huì)出現(xiàn)漏標(biāo)問(wèn)題:
1)將某一指向白色對(duì)象的引用寫(xiě)入黑色對(duì)象
2)從灰色對(duì)象出發(fā),最終到達(dá)該白色對(duì)象的所有路徑都被破壞
9、增量更新和起始快照
為了解決三色標(biāo)記算法的漏標(biāo)問(wèn)題,產(chǎn)生了兩種比較著名的解決方案:增量更新和起始快照,CMS 和 G1 就是采用了這兩種解決方案,CMS 使用的增量更新,G1使用的起始快照。
漏標(biāo)問(wèn)題的出現(xiàn)必須同時(shí)滿足上述的兩個(gè)條件,因此解決辦法只需破壞兩個(gè)條件之一即可。
1)增量更新(Incremental update)
使用寫(xiě)屏障(write barrier)攔截所有新插入的引用關(guān)系,將其記錄下來(lái),最后以這些引用關(guān)系的源頭作為根,重新掃描一遍即可解決漏標(biāo)問(wèn)題。
增量更新破壞的是條件1,當(dāng)插入黑色對(duì)象到白色對(duì)象的引用時(shí),寫(xiě)屏障會(huì)記錄下該引用,后續(xù)重新掃描。
以上面的漏標(biāo)為例,就是攔截步驟1:X.b=Y.a,記錄下X,然后重新掃描對(duì)象X。
2)起始快照(SATB,snapshot at the begin)
使用寫(xiě)屏障攔截所有刪除的引用關(guān)系,將其記錄下來(lái),然后將被刪除的引用關(guān)系所指向的對(duì)象會(huì)被當(dāng)作存活對(duì)象(非白色),重新掃描該對(duì)象。
SATB 抽象的說(shuō)就是在一次GC開(kāi)始時(shí)刻是存活的對(duì)象,則在本次GC中都會(huì)被當(dāng)做存活對(duì)象,此時(shí)的對(duì)象形成一個(gè)邏輯“快照”,這也是起始快照名字的由來(lái)。
起始快照破壞的是條件2,當(dāng)?shù)桨咨珜?duì)象的引用斷開(kāi)時(shí),寫(xiě)屏障會(huì)記錄下該引用,將該對(duì)象當(dāng)作存活對(duì)象,后續(xù)繼續(xù)掃描該對(duì)象的引用。
以上面的漏標(biāo)為例,就是攔截步驟2:Y.a=null,將Z作為存活對(duì)象,然后重新掃描對(duì)象Z。
10、CMS中的 Final Remark(重新標(biāo)記)階段?較慢,怎么分析和解決?
CMS 的整個(gè)垃圾回收過(guò)程中只有2個(gè)階段是 stop the world,一個(gè)是初始標(biāo)記,一個(gè)是重新標(biāo)記,初始標(biāo)記只標(biāo)記GC Roots直達(dá)的對(duì)象,因此一般不會(huì)耗時(shí)太久,而重新標(biāo)記出現(xiàn)耗時(shí)久的現(xiàn)象則比較多見(jiàn),通常如果CMS GC較慢,大多都是重新標(biāo)記階段較慢導(dǎo)致的。
Final Remark 階段比較慢,比較常見(jiàn)的原因是在并發(fā)處理階段引用關(guān)系變化很頻繁,導(dǎo)致 dirty card 很多、年輕代對(duì)象很多。
比較常見(jiàn)的做法可以在 Final Remark 階段前進(jìn)行一次 YGC,這樣年輕代的剩余待標(biāo)記對(duì)象會(huì)下降很多,被視為GC Root 的對(duì)象數(shù)量驟減, Final Remark 的工作量就少了很多。
// 在remark之前嘗試進(jìn)行清理,默認(rèn)值為false-XX:+CMSScavengeBeforeRemark
通常增加 -XX:+CMSScavengeBeforeRemark 都能解決問(wèn)題,但是如果優(yōu)化后還是耗時(shí)嚴(yán)重,則需要進(jìn)一步看具體是哪個(gè)小階段耗時(shí)嚴(yán)重。
Final Remark 具體包含了若干個(gè)小階段:weak refs processing、class unloading、scrub string table等,從日志里可以看出來(lái)每個(gè)小階段的耗時(shí),根據(jù)耗時(shí)的階段再進(jìn)行針對(duì)性的分析,可以查閱源碼或者查閱相關(guān)資料來(lái)幫助分析。
以比較常見(jiàn)的 weak refs processing 為例:
這邊的 weak refs 不是單指 WeakReference,而是包括了:SoftReference、WeakReference、FinalReference、PhantomReference、JNI Weak Reference,這邊應(yīng)該是除了強(qiáng)引用外的所有引用都被歸類為 weak 了。
因此,我們首先添加以下配置,打印出GC期間引用相關(guān)更詳細(xì)的日志。
// 打印GC的詳細(xì)信息-XX:+PrintGCDetails// 打印在GC期間處理引用對(duì)象的時(shí)間(僅在PrintGCDetails時(shí)啟用)-XX:+PrintReferenceGC
然后根據(jù)每個(gè)引用的耗時(shí),定位出耗時(shí)嚴(yán)重的引用類型,然后查看項(xiàng)目中是否存在對(duì)該引用類型不合理的使用。
另外一種比較簡(jiǎn)單粗暴的辦法是可以通過(guò)增加引用的并行處理來(lái)嘗試解決,通常會(huì)有不錯(cuò)的效果。
// 啟用并行引用處理,默認(rèn)值為false-XX:+ParallelRefProcEnabled
而如果是 scrub string table 階段耗時(shí),則可以分析項(xiàng)目中是否存在不合理的使用 interned string,其他的也類似。
我是囧輝,一個(gè)堅(jiān)持分享原創(chuàng)技術(shù)干貨的程序員。
推薦閱讀
最近我將面試:阿里、字節(jié)、美團(tuán)、快手、拼多多等大廠的高頻面試整理出來(lái),并按大廠的標(biāo)準(zhǔn)給出自己的解析。
群里有不少同學(xué)看完拿下了阿里、美團(tuán)等大廠 Offer,希望能助你一臂之力,早日拿下大廠 Offer。
獲取方式:關(guān)注公眾號(hào)回復(fù)【面試】即可領(lǐng)取,更多大廠面試真題解析 PDF 整理中。
