
異步編程指北!

導語?|?同步、異步,并發(fā)、并行、串行,這些名詞在我們的開發(fā)中會經(jīng)常遇到,這里對異步編程做一個詳細的歸納總結,希望可以對這方面的開發(fā)有一些幫助。
一、背景
業(yè)務中經(jīng)常會有這樣的場景:

一、幾個名詞的概念
多任務的時候,才會遇到的情況,如:同步、異步,并發(fā)、并行。
(一)理清它們的基本概念
并發(fā):多個任務在同一個時間段內(nèi)同時執(zhí)行,如果是單核心計算機,CPU會不斷地切換任務來完成并發(fā)操作。
并行:多任務在同一個時刻同時執(zhí)行,計算機需要有多核心,每個核心獨立執(zhí)行一個任務,多個任務同時執(zhí)行,不需要切換。
同步:多任務開始執(zhí)行,任務A、B、C全部執(zhí)行完成后才算是結束。
異步:多任務開始執(zhí)行,只需要主任務A執(zhí)行完成就算結束,主任務執(zhí)行的時候,可以同時執(zhí)行異步任務B、C,主任務A可以不需要等待異步任務B、C的結果。
并發(fā)、并行,是邏輯結構的設計模式。同步、異步,是邏輯調(diào)用方式。串行是同步的一種實現(xiàn),就是沒有并發(fā),所有任務一個一個執(zhí)行完成。并發(fā)、并行是異步的2種實現(xiàn)方式。
(二)舉一個例子
你的朋友在廣州,但是有2輛小汽車在深圳,需要你幫忙把這2輛小汽車送到廣州去。
同步的方式,你先開一輛小汽車到廣州,然后再坐火車回深圳,再開另外一輛小汽車去廣州。這是串行的方法,2輛車需要的時間也就更長了。
異步的方式,你開一輛小汽車從深圳去廣州,同時請一個代駕把另外一輛小汽車從深圳開去廣州。這也就是并行方法,兩個人兩輛車,可以同時行駛,速度很快。
并發(fā)的方式,你一個人,先開一輛車走500米,停車跑回來,再開另外一輛車前行1000米,停車再跑回來,循環(huán)從深圳往廣州開。并發(fā)的方式,你可以把2輛車一塊送到朋友手里,但是過程還是很辛苦的。
(三)思考問題
你找一家汽車托運公司,把2輛車一起托運到廣州。這種方式是同步、異步,并發(fā)、并行的哪種情況呢?
二、并發(fā)/并行執(zhí)行會遇到的問題
(一)問題1:并發(fā)的任務數(shù)量控制

假設:某個接口的并發(fā)請求會達到1萬的qps,所以對接口的性能、響應時長都要求很高。
接口內(nèi)部又有大量redis、mysql數(shù)據(jù)讀寫,程序中還有很多處理邏輯。如果接口內(nèi)的所有邏輯處理、數(shù)據(jù)調(diào)用都是串行化,那么單個請求耗時可能會超過100ms,為了性能優(yōu)化,就會把數(shù)據(jù)讀取的部分與邏輯計算的部分分開來考慮和實現(xiàn),能夠獨立的部分單獨剝離出來作為異步任務來執(zhí)行,這樣就把串行化的耗時優(yōu)化為并發(fā)執(zhí)行,充分利用多核計算機的性能,減少單個接口請求的耗時。
假設的數(shù)據(jù)具體化,如:這個接口的數(shù)據(jù)全部是可以獨立獲取(支持并發(fā)),需要讀取來自不同數(shù)據(jù)結構的redis共10個,讀取不同數(shù)據(jù)表的數(shù)據(jù)共10個。那么一次請求,數(shù)據(jù)獲取就會啟動10個redis讀取任務,10個mysql讀取任務。每秒鐘1萬接口請求,會有10萬個redis讀取任務和10萬個mysql讀取任務。這21萬的并發(fā)任務,在一秒鐘內(nèi)由16/32核的后端部署單機來完成,雖然在同一時刻的任務數(shù)量不一定會是21萬(速度快的話會少于21萬,如果處理速度慢,出現(xiàn)請求積壓擁堵,會超過21萬)。
這時候,會遇到的瓶頸。
內(nèi)存,如果每個任務需要500k內(nèi)存,那么210k*0.5M=210*0.5G=105G。
CPU,任務調(diào)度,像golang的協(xié)程可能開銷還小一些,如果是java的線程調(diào)度,操作系統(tǒng)會因為調(diào)度而空轉(zhuǎn)。
網(wǎng)絡,每次數(shù)據(jù)讀取5k,那么200k*5k=200*5M=1G。
端口,端口號最多能分配出來65536個,明顯不夠用了。
數(shù)據(jù)源,redis可以支持10萬qps的請求,但是mysql就難以支持10萬qps了。
上面可能出現(xiàn)的瓶頸中,通過計算機資源擴容可以解決大部分問題,比如:部署50個后端實例,每個實例只需要應對200的qps,壓力就小了很多。對于數(shù)據(jù)源,mysql可以有多個slave來支持只讀的請求。
但是,如果接口的并發(fā)量更大呢?或者某個/某些數(shù)據(jù)源讀取出現(xiàn)異常,需要重試,或者出現(xiàn)擁堵,接口響應變慢,任務數(shù)量也就會出現(xiàn)暴增,后端服務的各方面瓶頸又會隨之出現(xiàn)。
所以,我們需要特別注意和關心后端開啟的異步任務數(shù)量,要做好異常情況的防范,及時中斷掉擁堵/超時的任務,避免任務暴增導致整個服務不可用。
(二)思考問題
你要如何應對這類并發(fā)任務暴增的情況呢?如何提前預防?如何及時干預呢?
(三)問題2:共享數(shù)據(jù)的讀寫順序和依賴關系
共享數(shù)據(jù)的并發(fā)讀寫,是并發(fā)編程中的老大難問題,如:讀寫臟數(shù)據(jù),舊數(shù)據(jù)覆蓋新數(shù)據(jù)等等。
而數(shù)據(jù)的依賴關系,也就決定了任務的執(zhí)行先后順序。
為了避免共享數(shù)據(jù)的競爭讀寫,為了保證任務的先后關系,就需要用到鎖、隊列等手段,這時候,并發(fā)的過程又被部分的拉平為串行化執(zhí)行。
(四)舉個例子
https://www.ticketmaster.com/eastern-conf-semis-tbd-at-boston-boston-massachusetts/event/01005C6AA5531A90
NBA季后賽,去現(xiàn)場看球,要搶購球票,體育館最多容納1萬人(1萬張球票)。
體育館不同距離、不同位置的票,價格和優(yōu)惠都不相同。有單人位、有雙人位,也有3、4人位。你約著朋友共10個人去看球,要買票,要選位置。這時候搶票就會很尷尬,因為位置連著的可能會被別人搶走,同時買的票越多,與人沖突的概率就越大,會導致?lián)屍碧貏e困難。
同時,這個系統(tǒng)的開發(fā)也很頭大,搶購(秒殺)的并發(fā)非常大,預計在開始的一秒鐘會超過10萬人同時進來,再加上刷票的機器人,接口請求量可能瞬間達到100萬的QPS。
較簡單的實現(xiàn)方式,所有的請求都異步執(zhí)行,訂單全部進入消息隊列,下單馬上響應處理中,請等待。然后,后端程序再從消息隊列中串行化處理每一個訂單,把出現(xiàn)沖突的訂單直接報錯,這樣,估計1秒鐘可以處理1000個訂單,10秒鐘可以處理1萬個訂單。考慮訂單的沖突問題,1萬張球票的9000張可能在30秒內(nèi)賣出去,此時只處理了3萬個訂單,第一秒鐘進來的100萬訂單已經(jīng)在消息隊列中堆積,又有30秒鐘的新訂單進來,需要很久才可以把剩下的1000張球票賣出去啊。同理,下單的用戶需要等待太久才知道自己的訂單結果,這個過程輪詢的請求也會很多很多。
換一種方案,不使用隊列串行化處理訂單,直接并發(fā)的處理每一個訂單。那么處理流程中的數(shù)據(jù)都需要梳理清楚。
針對每一個用戶的請求加鎖,避免同一個用戶的重入;
每一個/組座位預生成一個key:0,默認0說明沒有下單;
預估平均每一個訂單包含2個/組座位,需要更新2個座位key;
下單的時候給座位key執(zhí)行INCR key數(shù)字遞增操作,只有返回1的訂單才是成功,其他都是失敗;
如果同一個訂單中的座位key有沖突的情況下,需要回滾成功key(INCR key=1)重置(SET key 0);
訂單成功/失敗,處理完成后,去掉用戶的請求鎖;
訂單數(shù)據(jù)入庫到mysql(消息隊列,避免mysql成為瓶頸);
綜上,需要用到1個鎖(2次操作),平均2個座位key(每個座位號1-2次操作),這里只有2個座位key可以并發(fā)更新。為了讓redis不成為數(shù)據(jù)讀寫的瓶頸(超過100w的QPS寫操作),不能使用單實例模式,而要使用redis集群,使用由10-20個redis實例組成的集群,來支持這么高的redis數(shù)據(jù)讀寫。
算上redis數(shù)據(jù)讀寫、參數(shù)、異常、邏輯處理,一個請求大概耗時10ms左右,單核至少可以支持100并發(fā),由于這里有大量IO處理,后端服務可以支持的并發(fā)可以更高些,預計單核200并發(fā),16核就可以支持3200并發(fā)。總共需要支持100萬并發(fā),預計需要312臺后端服務器。
這種方案比隊列的方案需要的服務器資源更多,但是用戶的等待時間很短,體驗就好很多。
(五)思考問題
實際情況會是怎樣呢?會有10萬人同時搶票嗎?會有100萬的超高并發(fā)嗎?訂票系統(tǒng)真的會準備300多臺服務器來應對搶票嗎?
三、狀態(tài)處理:忽略結果

(一)使用場景和案例
使用場景,主流程之外的異步任務,可能重要程度不高,或者處理的復雜度太高,有時候會忽略異步任務的處理結果。
案例1:異步的數(shù)據(jù)上報、數(shù)據(jù)存儲/計算/統(tǒng)計/分析。
案例2:模板化創(chuàng)建服務,有很多個任務,有前后關聯(lián)任務,也有相互獨立任務,有些執(zhí)行速度很慢,有些任務失敗后也可以手動重試來修復。
忽略結果的情況,就會遇到下面的問題。
(二)問題1:數(shù)據(jù)一致性
看下案例1的情況。
異步的日志上報,是否成功發(fā)送到服務端呢?
異步的指標數(shù)據(jù)上報,是否正確匯總統(tǒng)計和發(fā)送到服務端呢?
異步的任務,數(shù)據(jù)發(fā)送到消息隊列,是否被后端應用程序消費呢?
服務端是否正常存儲和處理完成呢?
如果因為網(wǎng)絡原因,因為并發(fā)量太大導致服務負載問題,因為程序bug的原因,導致數(shù)據(jù)沒能正確上報和處理,這時候的數(shù)據(jù)不一致、丟失的問題,就會難以及時排查和事后補發(fā)。
如果在本地完整記錄一份數(shù)據(jù),以備數(shù)據(jù)審查,又要考慮高并發(fā)高性能的瓶頸,畢竟本地日志讀寫性能受到磁盤速度的影響,性能會很差。
(三)問題2:功能可靠性
看下案例2的情況。
創(chuàng)建服務的過程中,有創(chuàng)建代碼倉庫、開啟日志采集和自定義鏡像中心,CI/CD等耗時很長的任務。這里開啟日志采集和自定義鏡像中心如果出現(xiàn)異常,對整個服務的運行沒有影響,而且開發(fā)者發(fā)現(xiàn)問題后也可以自己手動操作下,再次開啟日志采集和自定義鏡像功能。所以在模板化處理中,這些異步處理任務就沒有關注任務的狀態(tài)。
那么問題就很明顯,模板化創(chuàng)建服務的過程中,是不能保證全部功能都正常執(zhí)行完成的,會有部分功能可能有異常,而且也沒有提示和后續(xù)指引。
當然模板化創(chuàng)建服務的程序,也可以把全部任務的狀態(tài)都檢查結果,只是會增加一些處理的復雜度和難度。
(四)思考問題
實際開發(fā)中,有遇到類似上面的兩個案例嗎?你會如何處理呢?所有的異步任務,都會檢查狀態(tài)結果嗎?為什么呢?
四、狀態(tài)處理:結果返回
(一)使用場景和案例
大部分的異步任務對于狀態(tài)結果還是很關注的,比如:后續(xù)的處理邏輯或者任務依賴某個異步任務,或者異步任務非常重要,需要把結果返回給請求方。
案例1:模板化創(chuàng)建服務的過程中,需要異步創(chuàng)建服務的git代碼倉庫,還要給倉庫添加成員、webhook、初始化代碼等。整個過程全部串行化作為一個任務的話,耗時會比較長。可以把創(chuàng)建服務的git代碼倉庫作為一個異步任務,然后得到成功的結果后再異步的發(fā)起添加成員、加webhook、初始化代碼等任務。同時,這里的CI/CD有配置相關,有執(zhí)行相關,整個過程也很長,CD部署成功之后才可以開啟日志采集等配置,所以也需要關注CD部署的結果。
案例2:各種webhook、callback接口和方法,就是基于回調(diào)的方式,如:golang中的channel通知,工蜂中的代碼push等webhook,監(jiān)控告警中的callback等。
案例3:發(fā)布訂閱模式,如引入消息隊列服務,主程序把數(shù)據(jù)發(fā)送給消息隊列,異步任務訂閱相應的主題然后處理。處理完成后也可以把結果再發(fā)送給消息隊列,或者把結果發(fā)送給主調(diào)程序的接口,或者等待主調(diào)程序來查詢結果,當然也可能是上面的忽略結果的情況。
從上可以總結出來,對于異步任務的狀態(tài)處理,需要關注結果的話,有兩種主要的方法,分別是:輪詢查詢和等待回調(diào)。
(二)方法1:輪詢查詢
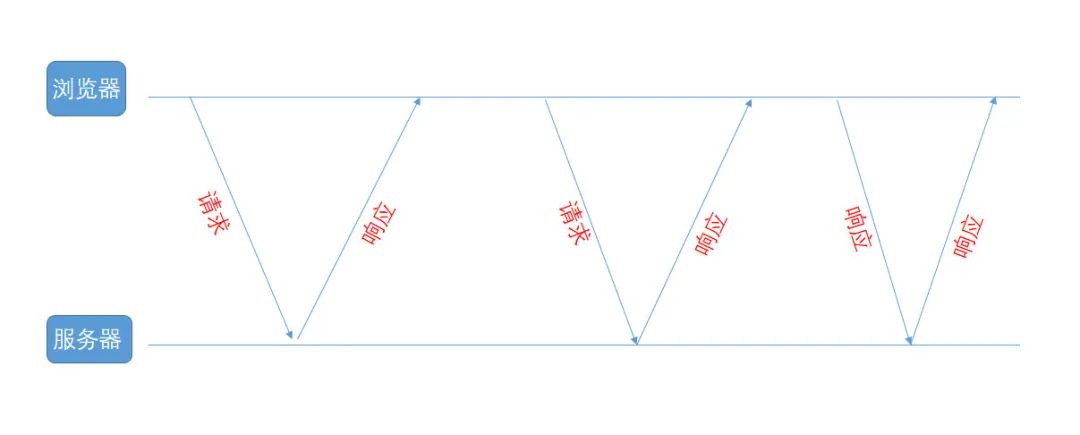
上面的案例1中,模板化創(chuàng)建服務的過程很慢,所以整個功能都是異步的,用戶大概要等待10s左右才知道最后的結果。所以,用戶在創(chuàng)建服務之后,瀏覽器會不斷輪詢服務端接口,看看創(chuàng)建服務的結果,各個步驟的處理結果,服務配置是否都成功完成了。
類似的功能實現(xiàn)應該有很多,比如:服務構建、部署、創(chuàng)建鏡像倉庫、搶購買票等,把任務執(zhí)行和任務結果通過異步的方式強制分離開,用戶可以等待,但是不用停留在當前任務中持續(xù)等待,而是可以去做別的事情,隨時回來關注下這個任務的處理結果就好了。大部分執(zhí)行時間很長的任務都會放到異步線程中執(zhí)行,用戶關注結果的話,就可以通過查詢的方式來獲取結果,程序自動來返回結果的話,就可以用到輪詢查詢了。
局限性1:頻率和實時性
輪詢的方式延時可能會比較高,因為跟定時器的間隔時間有關系。
局限性2:增加請求壓力
因為輪詢,要不斷地請求服務端,所以對后端的請求壓力也會比較大。
(三)方法2:通知回調(diào)

等待回調(diào)幾乎是實時的,處理有結果返回就馬上通過回調(diào)通知到主程序/用戶,那么效率和體驗上就會好很多。
但是這里也有一個前提要求,回調(diào)的時候,主程序必須還在運行,否則回調(diào)也就沒有了主體,也就無效了。所以要求主程序需要持續(xù)等待異步任務的回調(diào),不能過早的退出。
一般程序中使用異步任務,需要得到任務狀態(tài)的結果,使用等待回調(diào)的情況更多一些。
特別注意1:等待超時
等待的時間,一般不能是無限長,這樣容易造成某些異常情況下的任務爆炸,內(nèi)存泄露。所以需要對異步任務設置一個等待超時,過期后就要中斷任務了,也就不能通過回調(diào)來得到結果了,直接認為是任務異常了。
特別注意2:異常情況
當主程序在等待異步任務的回調(diào)時,如果異步任務自身有異常,無法成功執(zhí)行,也無法完成回調(diào)的操作,那么主程序也就無法得到想要的結果,也不知道任務狀態(tài)的結果是成功還是失敗,這時候也就會遇到上面等待超時的情況了。
特別注意3:回調(diào)地獄
使用nodejs異步編程的時候,所有的io操作都是異步回調(diào),于是就很容易陷入N層的回調(diào),代碼就會變得異常丑陋和難以維護。于是就出現(xiàn)了很多的異步編程框架/模式,像:Promise,Generator,async/await等。這里不做過多講解。
(四)思考問題
實際工作中,還有哪些地方需要處理異步任務的狀態(tài)結果返回呢?除了輪詢和回調(diào),還有其他的方法嗎?
五、異常處理
同步的程序,處理異常情況,在java中只需要一個try catch就可以捕獲到全部的異常。
(一)重點1:分別做異常處理
異步的程序,try catch只能捕獲到當前主程序的異常,主程序中的異步線程是無法被捕獲的。這時候,就需要針對異步線程中的異步任務也要單獨進行 try catch捕獲異常。
在golang中,開啟協(xié)程,還是需要在異步任務的defer方法中,加入一個recover(),以避免沒有處理的異常導致整個進程的panic。
(二)重點2:異常結果的記錄,查詢或者回調(diào)
當我們把異步任務中的異常情況都處理好了,不會導致異步線程把整個進程整奔潰了,那么還有問題,怎么把異常的結果返回給主進程。這就涉及到上面的狀態(tài)處理了。
如果可以忽略結果,那么只需要寫一下錯誤日志就好了。
如果需要處理狀態(tài),那就要記錄下異常信息或者通知回調(diào)給到主進程。
(三)思考問題
實際工作中,你會對所有的可能異常情況都做相應的處理嗎?異常結果,都是怎么處理的呢?
六、典型場景和思考
前面已經(jīng)講到一些案例,總結下來的典型場景有如下幾種:
訂閱發(fā)布模式,消息隊列;
慢請求,耗時長的任務;
高并發(fā)、高性能要求時的多任務處理;
不確定執(zhí)行的時間點,觸發(fā)器;
人腦(單核)不擅長異步思考,電腦(多核)卻更適合。
編程的時候,是人腦適配電腦,還是電腦服務人腦?
在大部分的編程中,大家都只需要考慮同步的方式來寫代碼邏輯。少部分時候,就要考慮使用異步的方式。而且,有很多的開發(fā)框架、類庫已經(jīng)把異步處理封裝,可以簡化異步任務的開發(fā)和調(diào)試工作。
所以,對于開發(fā)者來說,默認還是同步方式思考和開發(fā),當不得不使用異步的時候,才會考慮異步的方式。畢竟讓人腦適配電腦,這個過程還是有些困難的。
?作者簡介

王毅
騰訊應用開發(fā)工程師
騰訊應用開發(fā)工程師,有豐富的系統(tǒng)設計和開發(fā)經(jīng)驗,做過信息管理系統(tǒng)、社區(qū)、電商、搜索等系統(tǒng),現(xiàn)在參與奇點微服務云平臺的相關設計和開發(fā)工作。
?推薦閱讀
