
娓娓道來(lái)!那些BERT模型壓縮方法

本文約3000字,建議閱讀10+分鐘
本文主要介紹知識(shí)蒸餾、參數(shù)共享和參數(shù)矩陣近似方法。
作者?|?Chilia 哥倫比亞大學(xué)?nlp搜索推薦??? 整理?|?NewBeeNLP
基于Transformer的預(yù)訓(xùn)練模型的趨勢(shì)就是越來(lái)越大,雖然這些模型在效果上有很大的提升,但是巨大的參數(shù)量也對(duì)上線這些模型提出挑戰(zhàn)。
對(duì)于BERT的模型壓縮大體上可以分為 5 種(其他模型壓縮也是一樣):
知識(shí)蒸餾:將 teacher 的能力蒸餾到 student上,一般 student 會(huì)比 teacher 小。我們可以把一個(gè)大而深的網(wǎng)絡(luò)蒸餾到一個(gè)小的網(wǎng)絡(luò),也可以把集成的網(wǎng)絡(luò)蒸餾到一個(gè)小的網(wǎng)絡(luò)上。 參數(shù)共享:通過(guò)共享參數(shù),達(dá)到減少網(wǎng)絡(luò)參數(shù)的目的,如 ALBERT 共享了 Transformer 層; 參數(shù)矩陣近似:通過(guò)矩陣的低秩分解或其他方法達(dá)到降低矩陣參數(shù)的目的,例如ALBERT對(duì)embedding table做了低秩分解; 量化:比如將 float32 降到 float8。 模型剪枝:即移除對(duì)結(jié)果作用較小的組件,如減少 head 的數(shù)量和去除作用較少的層。
這篇文章中主要介紹知識(shí)蒸餾、參數(shù)共享和參數(shù)矩陣近似方法。

1. 使用知識(shí)蒸餾進(jìn)行壓縮
關(guān)于知識(shí)蒸餾的基礎(chǔ)知識(shí)見:模型壓縮 | 知識(shí)蒸餾經(jīng)典解讀。
具有代表性的論文:
1.1 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT屬于知識(shí)蒸餾中的logits蒸餾方法。
之前的很多工作都是從bert中蒸餾出一個(gè)"task-specific model", 即對(duì)某個(gè)具體的任務(wù)(如情感分類)蒸餾一個(gè)模型。DistilBERT不同的地方在于它是在預(yù)訓(xùn)練階段進(jìn)行蒸餾,蒸餾出來(lái)一個(gè)通用的模型,再在下游任務(wù)上微調(diào)。DistilBERT參數(shù)量是BERT的40%(可以在edge device上運(yùn)行),保留了97%的語(yǔ)言理解能力。
1.1.1 損失函數(shù)設(shè)計(jì)
預(yù)訓(xùn)練的損失函數(shù)由三部分構(gòu)成:
蒸餾損失:對(duì)Student和Teacher的logits都在高溫下做softmax,求二者的KL散度; 有監(jiān)督任務(wù)損失:在這個(gè)預(yù)訓(xùn)練問(wèn)題中就是Bert的MLM任務(wù)損失,注意此時(shí)Student模型的輸出是在溫度為1下做的softmax; cosine embedding loss: 把Student的Teacher的隱藏向量用余弦相似度做對(duì)齊。(感覺這個(gè)類似中間層蒸餾)
1.1.2 學(xué)生模型設(shè)計(jì)
student模型只使用BERT一半的層;使用teacher模型的參數(shù)進(jìn)行初始化。在訓(xùn)練過(guò)程中使用了動(dòng)態(tài)掩碼、大batchsize,然后沒有使用next sentence objective(和Roberta一樣)。訓(xùn)練數(shù)據(jù)和原始的Bert訓(xùn)練使用的一樣,但是因?yàn)槟P妥冃∷怨?jié)省了訓(xùn)練資源。
在GLUE(General Language Understanding Evaluation)數(shù)據(jù)集上進(jìn)行微調(diào),測(cè)試結(jié)果:
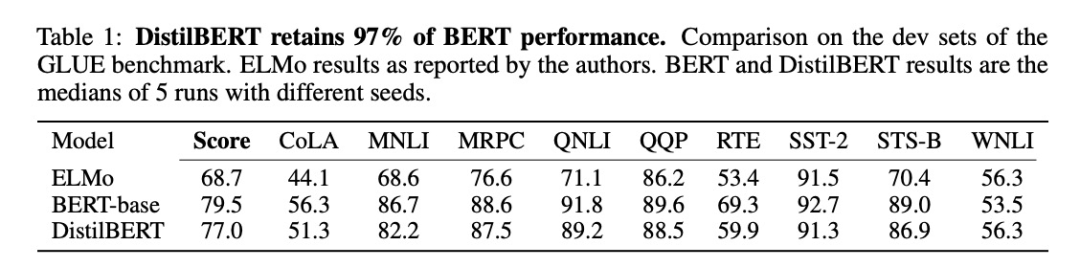
此外,作者還研究了兩階段蒸餾(跟下文TinyBERT很像),即在預(yù)訓(xùn)練階段蒸餾出一個(gè)通用模型之后,再用一個(gè)已經(jīng)在SQuAD模型上微調(diào)過(guò)的BERT模型作為Teacher,這樣微調(diào)的時(shí)候除了任務(wù)本身的loss,還加上了和Teacher輸出logits的KL散度loss。我理解這樣相當(dāng)于進(jìn)行l(wèi)abel smoothing,Student模型能夠?qū)W到更多的信息,因此表現(xiàn)會(huì)有一個(gè)提升:
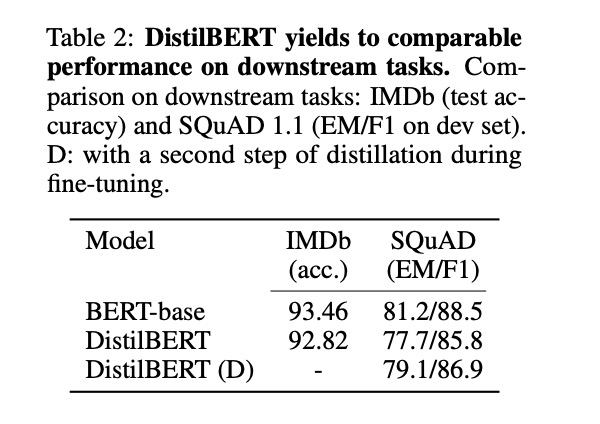 DistilBERT(D)就是兩階段蒸餾,表現(xiàn)優(yōu)于一階段蒸餾+微調(diào)
DistilBERT(D)就是兩階段蒸餾,表現(xiàn)優(yōu)于一階段蒸餾+微調(diào)
1.2 TinyBERT: Distilling BERT for Natural Language Understanding
TinyBERT是采用兩段式學(xué)習(xí)框架,分別在預(yù)訓(xùn)練和針對(duì)特定任務(wù)的具體學(xué)習(xí)階段執(zhí)行 transformer 蒸餾。這一框架確保 TinyBERT 可以獲取 teacher BERT的通用和針對(duì)特定任務(wù)的知識(shí)。
1.2.1 Transformer 蒸餾
假設(shè) student 模型有 M 個(gè) Transformer 層,teacher 模型有 N 個(gè) Transformer 層。n=g(m) 是 student 層到 teacher 層的映射函數(shù),這意味著 student 模型的第 m 層從 teacher 模型的第 n 層學(xué)習(xí)信息。把embedding層的蒸餾和預(yù)測(cè)層蒸餾也考慮進(jìn)來(lái),將embedding層看作第 0 層,預(yù)測(cè)層看作第 M+1 層,并且有映射:0 = g(0) 和 N + 1 = g(M + 1)。這樣,我們就已經(jīng)把Student的每一層和Teacher的層對(duì)應(yīng)了起來(lái)。文中嘗試了4層(??)和6層(??)這個(gè)對(duì)應(yīng)關(guān)系如下圖(a)所示:
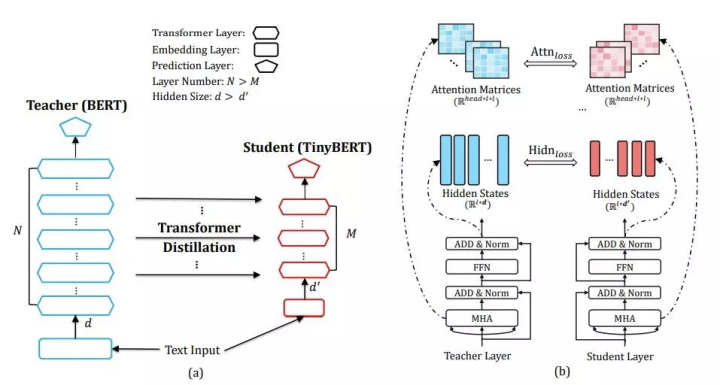
那么,學(xué)生對(duì)老師的蒸餾損失如下:

對(duì)于<學(xué)生第m層,老師第g(m)層>,需要用??計(jì)算二者的?差異?,那么這個(gè)差異如何來(lái)求呢?下面,我們來(lái)看四個(gè)損失函數(shù):
1)注意力損失?
BERT的注意力頭可以捕捉豐富的語(yǔ)言信息。基于注意力的蒸餾是為了鼓勵(lì)語(yǔ)言知識(shí)從 teacher BERT 遷移到 student TinyBERT 模型中。具體而言,student 網(wǎng)絡(luò)學(xué)習(xí)如何擬合 teacher 網(wǎng)絡(luò)中多頭注意力的矩陣,目標(biāo)函數(shù)定義如下:
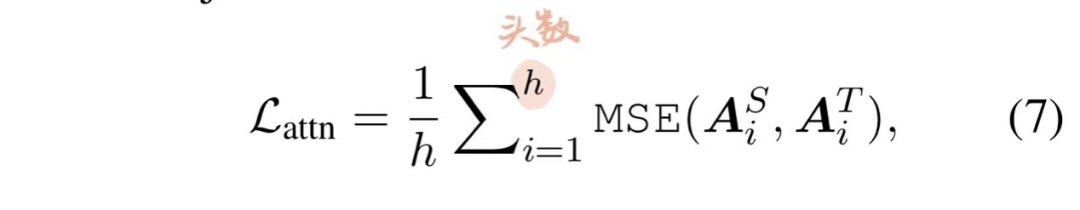
其實(shí)就是求Student的第i個(gè)注意力頭與Teacher的第i個(gè)注意力頭的MSE loss;一個(gè)細(xì)節(jié)是作者只使用了原始的attention矩陣A,而沒有使用經(jīng)過(guò)softmax之后的注意力矩陣,因?yàn)檫@樣更好收斂。
2)hidden損失?
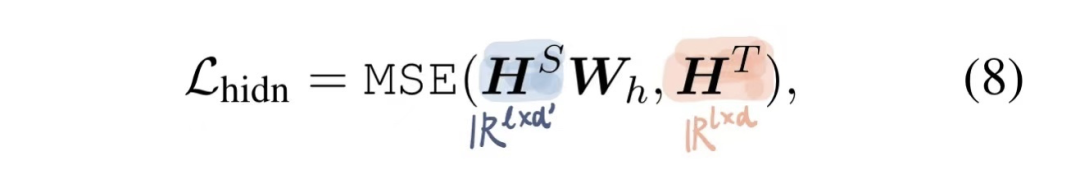
對(duì)每一個(gè)transformer層的輸出hidden state進(jìn)行蒸餾。由于Student的hidden size往往小于Teacher的hidden size,所以需要一個(gè)??做適配(這也是中間層蒸餾的思想)。這也是Tinybert和DistilBERT不同的地方 -- DistilBERT只是減少了層數(shù),而TinyBERT還縮減了hidden size。
3)Embedding層損失?
還是類似的方法做中間層蒸餾,用??適配:
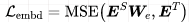
embedding size和hidden size大小一樣。
4)輸出層損失
這是logits蒸餾,在溫度t下求Student的Teacher輸出層的KL散度。
每一層的損失函數(shù)如下,即分embedding層、中間transformer層、輸出logits層來(lái)分類討論:
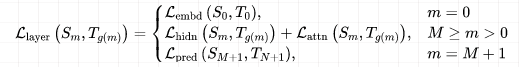
1.2.2 兩段式學(xué)習(xí)框架
BERT 的應(yīng)用通常包含兩個(gè)學(xué)習(xí)階段:預(yù)訓(xùn)練和微調(diào)。BERT 在預(yù)訓(xùn)練階段學(xué)到的知識(shí)非常重要,需要遷移到壓縮的模型中去。因此,Tinybert使用兩段式學(xué)習(xí)框架,包含通用蒸餾(general distillation)和特定于任務(wù)的蒸餾(task-specific distillation)。
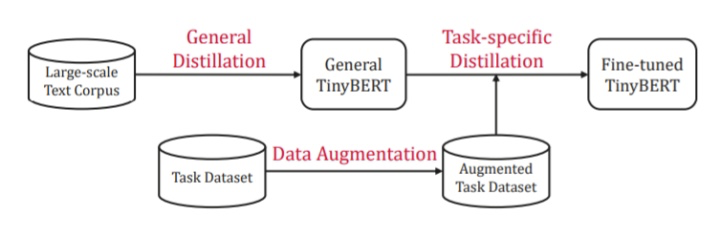
通用蒸餾(general distillation)
使用未經(jīng)過(guò)微調(diào)的預(yù)訓(xùn)練BERT作為 teacher 模型,利用大規(guī)模文本語(yǔ)料庫(kù)作為學(xué)習(xí)數(shù)據(jù),執(zhí)行上文所述的Transformer 蒸餾。這樣就得到了一個(gè)通用 TinyBERT。然而,由于隱藏/embedding層大小及層數(shù)顯著降低,通用 TinyBERT 的表現(xiàn)不如 BERT。
針對(duì)特定任務(wù)的蒸餾(task-specific distillation)
之前的研究表明,像BERT這樣的復(fù)雜模型在特定任務(wù)上有著參數(shù)冗余,所以是可以用小模型來(lái)得到相似的結(jié)果的。所以,在針對(duì)特定任務(wù)蒸餾時(shí),使用微調(diào)的 BERT用作 teacher 模型(這個(gè)和上文DistilBERT提到的方法類似,可以理解為label smoothing)。還用了數(shù)據(jù)增強(qiáng)方法來(lái)擴(kuò)展針對(duì)特定任務(wù)的訓(xùn)練集。
文中的數(shù)據(jù)增強(qiáng)方法就是:對(duì)于multiple-piece word(就是那些做word piece得到多個(gè)子詞的詞語(yǔ)),直接去找GloVe中和它最接近的K個(gè)詞語(yǔ)來(lái)替換;對(duì)于single-piece word(自己就是子詞的詞語(yǔ)),先把它MASK掉,然后讓預(yù)訓(xùn)練BERT試圖恢復(fù)之,取出BERT輸出的K個(gè)概率最大的詞語(yǔ)來(lái)替換。我理解其實(shí)這個(gè)屬于離散的數(shù)據(jù)增強(qiáng),根據(jù)SimCSE文章中的說(shuō)法,這種數(shù)據(jù)增強(qiáng)方法可能會(huì)引入一些噪聲??
上述兩個(gè)學(xué)習(xí)階段是相輔相成的:通用蒸餾為針對(duì)特定任務(wù)的蒸餾提供良好的初始化,而針對(duì)特定任務(wù)的蒸餾通過(guò)專注于學(xué)習(xí)針對(duì)特定任務(wù)的知識(shí)來(lái)進(jìn)一步提升 TinyBERT 的效果。
2. 參數(shù)共享 & 矩陣近似
這兩種方法就放在一起說(shuō)了,以ALBERT為例:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[1]
2.1 矩陣低秩分解**(對(duì)Embedding Table進(jìn)行分解)
ALBERT中使用和BERT大小相近的30K詞匯表。假如我們的embedding size和hidden size一樣,都是768,那么如果我們想增加了hidden size,就也需要相應(yīng)的增加embedding size,這會(huì)導(dǎo)致embedding table變得很大。
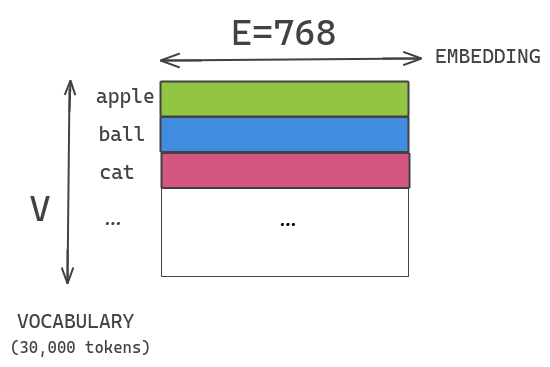
In BERT, ... the WordPiece embedding size E is tied with the hidden layer size H, i.e. E = H. This decision appears suboptimal for both modeling and practical reasons. -- ALBERT論文
ALBERT通過(guò)將大的詞匯表embedding矩陣分解成兩個(gè)小矩陣來(lái)解決這個(gè)問(wèn)題。這將隱藏層的大小與詞匯表嵌入的大小分開。
從模型的角度來(lái)講,因?yàn)閃ordPiece embedding只是要學(xué)習(xí)一些上下文無(wú)關(guān)的表示(context-independent representations), 而hidden layer是要學(xué)習(xí)上下文相關(guān)的表示(context-dependent representations). 而BERT類模型的強(qiáng)大之處就在于它能夠建模上下文相關(guān)的表示。所以,理應(yīng)有 H >> E. 從實(shí)用的角度來(lái)講,這允許我們在不顯著增加詞匯表embedding的參數(shù)大小的情況下增加隱藏的大小。
我們將one-hot encoding向量投影到 E=100 的低維嵌入空間,然后將這個(gè)嵌入空間投影到隱含層空間H=768。其實(shí)這也可以理解為:使用E = 100的embedding table,得到每個(gè)token的embedding之后再經(jīng)過(guò)一層全連接轉(zhuǎn)化為768維。這樣,模型參數(shù)量從原來(lái)的??降低為現(xiàn)在的??.
2.2 參數(shù)共享
ALBERT使用了跨層參數(shù)共享的概念。為了說(shuō)明這一點(diǎn),讓我們看一下12層的BERT-base模型的例子。我們只學(xué)習(xí)第一個(gè)塊的參數(shù),并在剩下的11個(gè)層中重用該塊,而不是為12個(gè)層中每個(gè)層都學(xué)習(xí)不同的參數(shù)。我們可以?只共享feed-forward層的參數(shù)/只共享注意力參數(shù)/共享所有的參數(shù)?。論文中的default方法是對(duì)所有參數(shù)都進(jìn)行了共享。
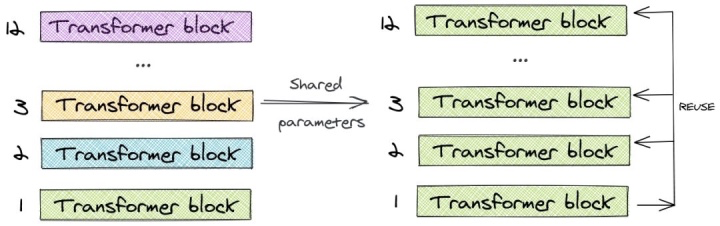
與BERT-base的1.1億個(gè)參數(shù)相比,相同層數(shù)和hidden size的ALBERT模型只有3100萬(wàn)個(gè)參數(shù)。當(dāng)hidden size為128時(shí),對(duì)精度的影響很小。精度的主要下降是由于feed-forward層的參數(shù)共享。共享注意力參數(shù)的影響是最小的。
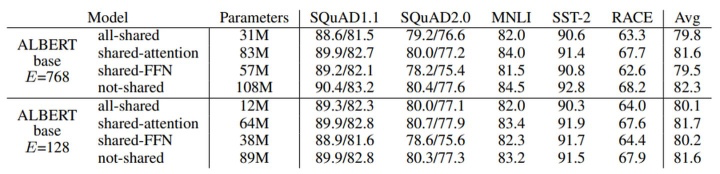
ALBERT的這些降低參數(shù)的做法也可以看作一種正則化,起到穩(wěn)定模型、增強(qiáng)泛化能力的作用。
由于進(jìn)行矩陣低秩分解、共享參數(shù)并不會(huì)對(duì)模型效果產(chǎn)生太大影響,那么就可以增加ALBERT的參數(shù)量,使其使用小于BERT-large的參數(shù)量、但達(dá)到更好的效果。