
當我們談論生信的時候我們在談什么
生物信息學習的正確姿勢
NGS系列文章包括NGS基礎、高顏值在線繪圖和分析、轉錄組分析?(Nature重磅綜述|關于RNA-seq你想知道的全在這)、ChIP-seq分析?(ChIP-seq基本分析流程)、單細胞測序分析?(重磅綜述:三萬字長文讀懂單細胞RNA測序分析的最佳實踐教程)、DNA甲基化分析、重測序分析、GEO數(shù)據(jù)挖掘(典型醫(yī)學設計實驗GEO數(shù)據(jù)分析 (step-by-step))、批次效應處理等內容。
作為進化研究的重要手段,生物信息學擔當了越來越重要的作用。作為一個極難進行實驗重復和驗證的學科,只能嘗試根據(jù)現(xiàn)有的東西推斷上百萬及千萬年前的歷史。同時,生物信息學依然受到很多的質疑,且不為很多生物研究者所理解。這也是由于其是新興的交叉學科(統(tǒng)計學,計算機科學與生物學)的特性所決定的。
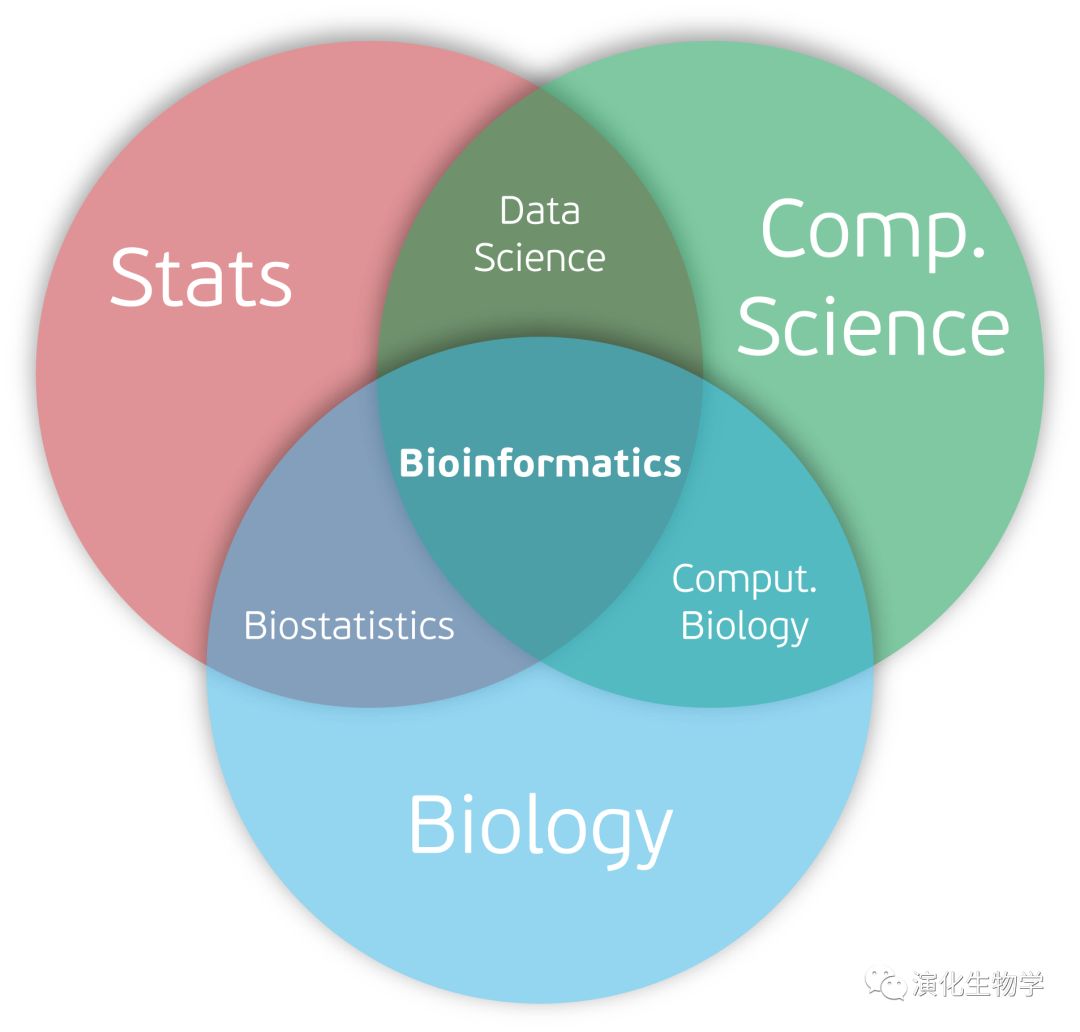
本片短文總結以下:我們應該如何認識生信,如何了解自己的定位,以及最關鍵,如何在茫茫生信海中找到出路。
@一些對生物信息學常見的誤解:
“你們搞分類的,搞分子的,搞生信的…”
雖然生物信息學聽起來確實有那么點點酷。可事實上,并不是進行生物信息分析工作的人,都喜歡被別人尊稱為“搞生信的”。例如,分類學工作也會借助一代、二代甚至三代測序提供的分子標記來進行系統(tǒng)發(fā)育樹的構建。

達爾文繪制的系統(tǒng)樹 現(xiàn)在該工作基本由計算機完成
純粹的濕實驗研究,亦可使用生物信息學手段輔助進行引物的構建,序列的預測,或者通過多組學的手段來縮小的基因篩選目標,以降低對應項目的時間成本。實際上,不論是“搞”什么,對應的都應該是一種方向的知識,而知識是用來達成目標,也就是解決生物學問題的。“搞分類”指對特定類群的系統(tǒng)以及形態(tài)特性的掌握、“搞分子”指關注更微觀層面、以及使用濕實驗手段的人群、而“搞生信”指的是工作在個人電腦或服務器上完成的生物分析。
對于生物學問題的解決,不同的能力可以共同使用,只是側重點稍有不同。所以我們平時理解的生物信息學,和其本身的含義不同,在解決具體的生物問題上,應該是作為一種工具。
“開局一篇測序報告,輸出全靠扯”
有的小伙伴認為,進行生物信息學相關生物學課題的研究,是很簡單的,博士幾年,什么實驗沒做,入學三個月就有數(shù)據(jù),直接分析就行了,太輕松了吧?事實并非如此,拿到數(shù)據(jù)之后,工作才剛剛開始:拋開都需要的文獻和解讀工作不談,拿到數(shù)據(jù)的第一步需要對數(shù)據(jù)進行質量的評估,這個過程就需要上機器了。一篇文章或者一個項目,會有很多個研究和分析的點,首先需要層層擊破。例如拿到一個物種的基因組數(shù)據(jù),在解答具體生物學問題前,一般需要檢測是否存在全基因組復制(WGD, Whole Genome Duplication)事件,計算自身同義替換率之前,需要找出同一次復制事件產生的基因對。但聚類后得到的家族成員少則幾個多則幾十,如何界定誰和誰是一對則需要設計分析方法。當然,這部分可以砸錢讓公司跑流程,但實際上不同物種差別很大,流程經(jīng)常會出現(xiàn)各種各樣看不出來的Bug,這方面也已經(jīng)有太多的實例。例如本身生活在特殊生境下,進化速率很快的物種,其Ks峰可能會受到稀釋,只能通過共線性區(qū)段的分析尋找蹤跡,這些工作公司可是無法幫你完成的。
拿到數(shù)據(jù)后 復雜的分析流程才剛剛開始
“除了測序費,基本無開銷”?
絕對不是!首先測序費本身就是很大的一筆經(jīng)費。雖然說測序費用越來越便宜,但這也代表著解決同一個生物學問題,使用同樣的經(jīng)費,能產出的數(shù)據(jù)越來越多,對結果的要求就越來越準確,雜志的同行審議也會越來越嚴格。其次是服務器集群,一個合格的具備生物信息分析能力的課題組,機器是不可少的。少則大幾萬十幾萬,多則上百萬不封頂,每年的電費也是以萬十萬計算的。即使租借,每個月也是一筆不小的開銷。另外,大部分自己有服務器集群的組,都需要有專人進行維護和管理,管理的人工費也不低。

以數(shù)據(jù)公開和接受為主的雜志越來越多 生物學問題也變得更為重要
最后還有,咖啡咖啡咖啡!!這部分的經(jīng)費很多課題組都會忽略,據(jù)我觀察,之前留過較頂級的生信課題組,咖啡的飲用和購買量是遠遠高于其他課題組的,一個是生信人,除了會把更多的時間花在電腦前靠喝咖啡緩解因出bug以后無處安放的雙手外,不要忘記,每個生信人都有著程序員的魂,因為工作地點不受限制,加班熬夜是家常便飯。

一天四杯膠囊咖啡是家常便飯
@生信人的分類:
根據(jù)一些年的經(jīng)驗,身邊做生信的人大致可以分為三類:
法師型選手
生物學出身,需要使用生信解決問題的人。常見于高校或研究機構的老師和學生。了解生物學基礎問題,但對生信分析手段的了解程度參差不齊:
初級生信學者,指自己的研究課題需要使用到生物信息學的手段,這類小伙伴的生物信息工作主要由其他熟悉生信的人或者生物公司完成,并需要將結果轉換為熟悉的生物學語言,方能完成論文及項目;
中級生信學者:自己能夠進行基本的分析,例如序列比對,系統(tǒng)發(fā)育樹的構建等等,并能使用一下在線工具和平臺完成基礎的分析,完善自己的論文工作,更為復雜的分析則由其他小伙伴或生物公司完成;
高級生信學者:在熟悉生物學基礎的情況下,了解大部分生信軟件的使用,并能夠構建基礎的流程,根據(jù)挖掘出來的生物學問題,進行生信分析策略的調整,這類小伙伴能夠和公司互補,以促進項目的完成。

?戰(zhàn)士型選手
計算機、統(tǒng)計、數(shù)學等專業(yè)背景,后轉入生物信息。隨后進行生物知識的補充,根據(jù)自己的發(fā)展目標可以分為兩類:
1)著重流程的構建和分析項目的完成,有基礎的生物學知識,不過多關注生物學問題。這類生信人常見于生物公司的技術人員。他們的目標是能夠高效的完成工作,他們和了解生物學問題的老師或同事一起可以釋放出強大的能量。
2)隨著對生信的接觸,開始熟悉生物學知識并開始產生濃厚興趣,對他們來說,這些生物學問題是他們應用所學知識的特定場景,力求根據(jù)場景的需要構建合適的流程。
大賢者
無所謂何種背景,左可入硅實驗,右可入濕實驗,看起來什么都懂,并能融匯貫通。對于這類人而言,生物學和計算機科學和其他學科一樣,對于他們都是一種知識,可以說是前兩種類型的綜合體。他們的目標是為了解決對應的項目或生物學問題,生物信息學只是和PCR,電泳一樣的普通實驗手法,為達到目標用一用就好了。大賢者成為了實驗室的PI,則絕對是沖鋒型的老板。
大魔導師
對算法問題近乎饑渴和瘋狂,著迷于方法學不可自拔,是生物信息學發(fā)展基礎的推動力之一。他們不關注大的生物學問題,僅在意特定軟件所解決的生物學場景,不斷的優(yōu)化算法,力求達到百密無一疏,以及高速運行的目標。大量魔導師混跡于一個叫做GitHub的網(wǎng)站,并經(jīng)常互相斗法以交流法術研發(fā)心得。

???
無欲無求,進行生信研究純粹是為了滿足自身的愛好和好奇心,和自己的課題目標不一定相關,經(jīng)常不小心做一些“支線任務”。但他們對生物學問題和計算機問題的銜接有自己獨到的見解,經(jīng)常做出一些騷操作。甚至會使用生物信息學手段來解決一些社會學問題。

@如何關愛身邊的生信小伙伴:
1. 看他整日坐在電腦前,不參加課題組其他的工作,千萬不要覺得他在偷懶。他可能正在非常煎熬的應對某個問題,甚至可以給他一點鼓勵,因為他真的會很擔心別人覺得他偷懶。
2 讓他幫忙之前先問清楚他可能需要的時間,是否會耽誤他手頭的工作。因為看似簡單的一項工作,他有時就要為此熬幾個晚上:例如“隨便跑個樹就行”或“隨便算個分子鐘就行”。正是因為他很在意你,所以會去閱讀很多文獻并改善流程才能完成這些“簡單的任務”,單純的下載數(shù)據(jù)也都會花費很多時間。
3 看到他在咖啡廳玩電腦,或者在辦公室看不到他人的時候,也不要覺得他是在偷懶。只要有一臺電腦和wifi,所有地方都是他的辦公室!

@生信汪末日自救指南:
面臨井噴一樣的數(shù)據(jù),應該如何生存?
1. 明確定位:了解自己打C位還是輔助,決定了裝備的選擇。而確定自己想達到的水平,是很重要的。時間有限,初學者往往在沒有任何基礎的情況下翻出一本厚厚的某版生物信息學一讀幾小時,離開后還是“abandon”。如果還有很多繁重的濕實驗需要進行,不如直接和生物公司的技術多多交流,必要的時候在一些在線平臺做一些分析,可能比從某些教材一開始的貝葉斯或者似然法的公式看起來要簡單許多,也更有成效。

2. 學會利用文獻資料:雖然說生物信息學發(fā)展很快,每天都有新的軟件和解決問題的流程出現(xiàn),但還有有很多套路的。了解自己的課題,找到同樣解決類似問題的文獻,以模仿其材料與方法部分進行生物信息分析的重復,這不僅僅知道別人解決這個問題都使用的軟件,也會了解不同軟件能夠完成什么工作,幫助作者論證什么問題。
《CELL》上的文章會把文章用到的軟件列舉出來
3. 程序語言學習要解決具體問題:生信選手到了進階的過程,都需要學習一些簡單的編程語言,例如perl、python和R。如果需要長時間進行生信工作,學習語言是很有必要的且節(jié)約時間的,簡單的掌握部分語句能夠幫助你修改文件格式,搭建簡單的流程,以及找到別人腳本中的錯誤。但時間有限的情況下,請直接以生信場景為基礎進行腳本的撰寫練習 (生信寶典的教程都是這樣面向生信的應用的)。這比完成教材后面一些計算時間,放100個小球取幾個的概率等問題要好的多,也容易記下來。例如使用perl編寫一個根據(jù)位置提取fasta中序列的腳本,簡單容易,還能夠很有成就感,學完后甚至可以直接使用。

4. 不要不舍得花錢:如果有想上手生信的決心,還是應該花點錢參加培訓或購買網(wǎng)絡課程,畢竟一個課題組購買到的資料都是可以共享學習的。雖然一些轉發(fā)或者付10塊錢拿到成噸的文件夾的資料,看似也非常有價值,但一般都已經(jīng)是一些上古資料,以及常見軟件的說明書(也可能是我運氣不好)。生信分析手法的更新是很快的,一定要日新月異,畢竟參加培訓班或網(wǎng)絡課程一步一步操作,比純粹看資料摸索更容易激活大腦。另外,導師或者課題組的PI也應該讓比較有潛力的學生或者課題組的人員參加生信的培訓,畢竟幾千塊的培訓,今后僅僅在測序報告上找到一個不妥的地方,可能就能夠省下幾千甚至上萬元。
今天就總結到這,希望對正在學習生物信息學,以及看到身邊有同學同事學習生物信息學的朋友有幫助。更新得再快的學科也會有自身的套路,快準狠的解決問題才是使用生信的不二之選。
教程合集
生信寶典-Linux教程.pdf (微信公眾號后臺回復?生信寶典福利第一波)
生信寶典Py3_course.pdf
生信寶典-R學習教程.pdf
系列教程
高顏值免費在線繪圖
往期精品
心得體會?TCGA數(shù)據(jù)庫?Linux?Python?
后臺回復“生信寶典福利第一波”獲取教程合集