
Flink 原理 | 深入解析 Flink 細(xì)粒度資源管理
摘要:本文整理自阿里巴巴高級開發(fā)工程師郭旸澤 (天凌) 在 Flink Forward Asia 2021 核心技術(shù)專場的演講。主要內(nèi)容包括:
細(xì)粒度資源管理與適用場景 Flink 資源調(diào)度框架 基于 SlotSharinGroup 的資源配置接口 動態(tài)資源切割機制 資源申請策略 總結(jié)與未來展望
一、細(xì)粒度資源管理與適用場景


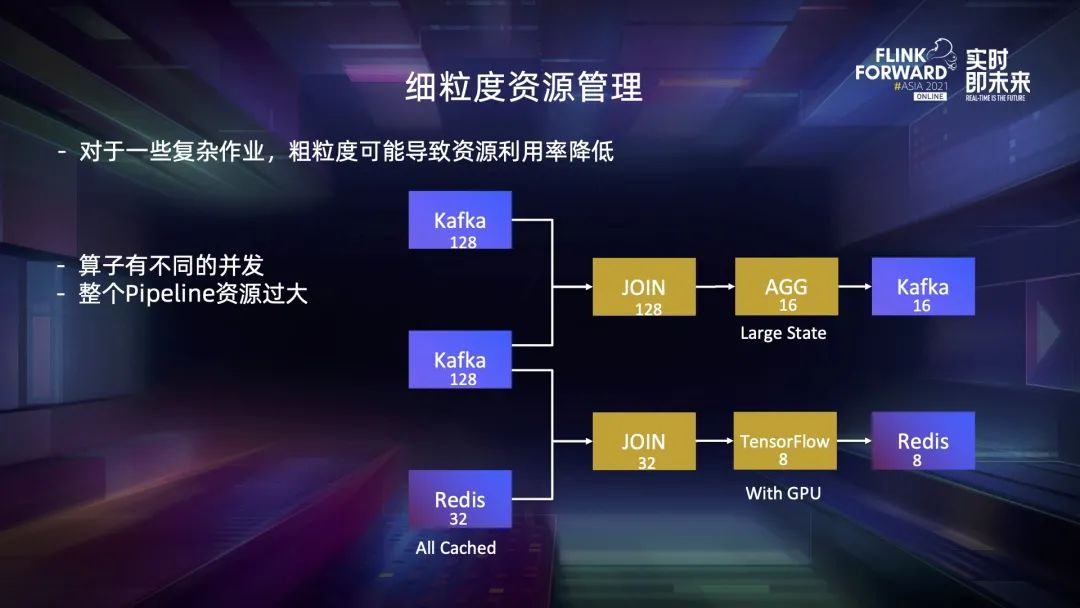
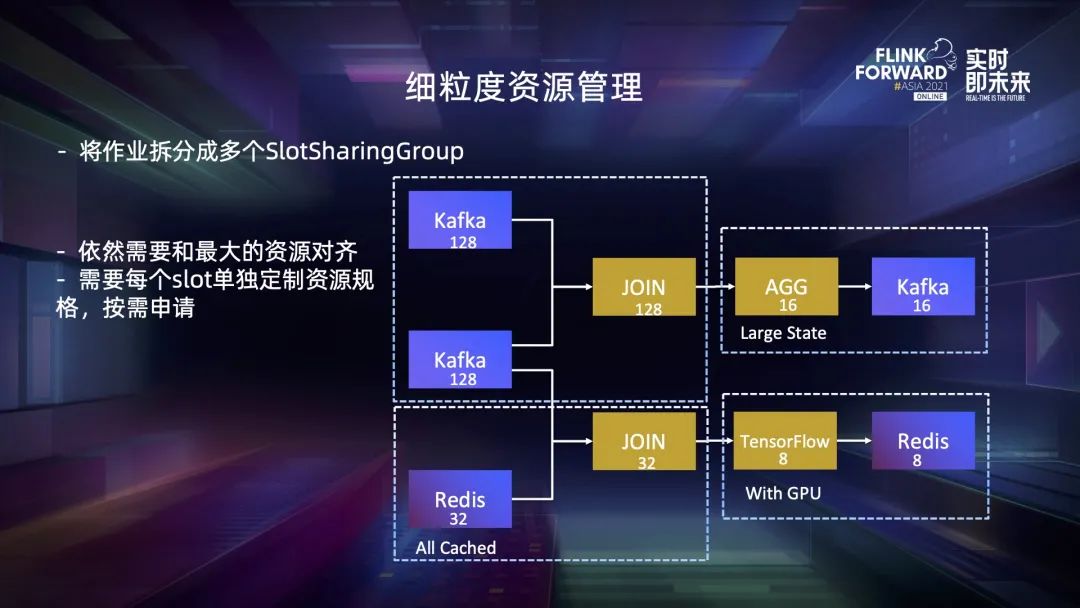

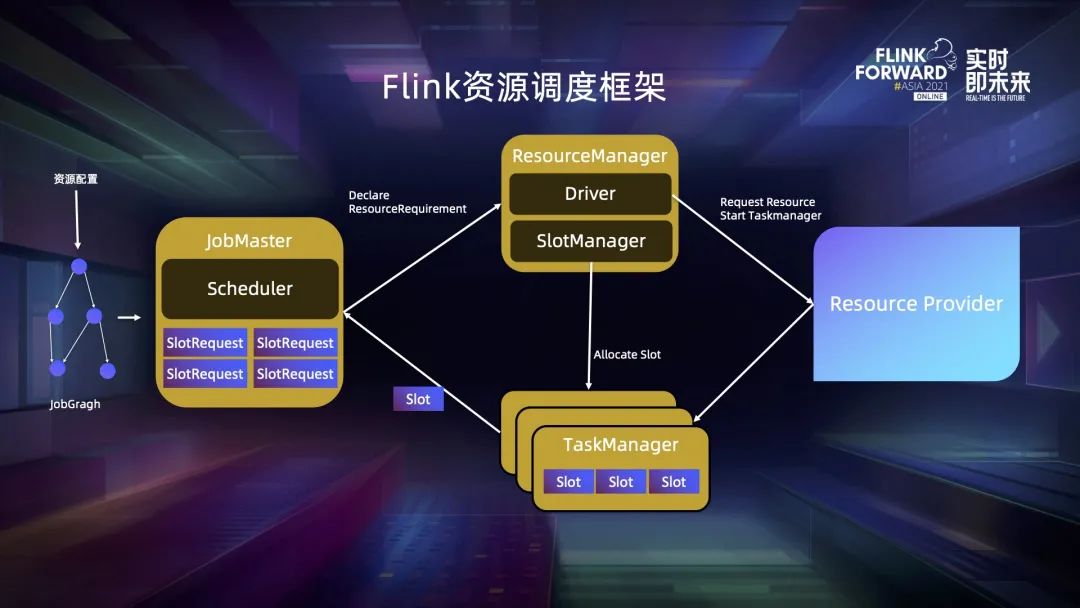
二、Flink 資源調(diào)度框架
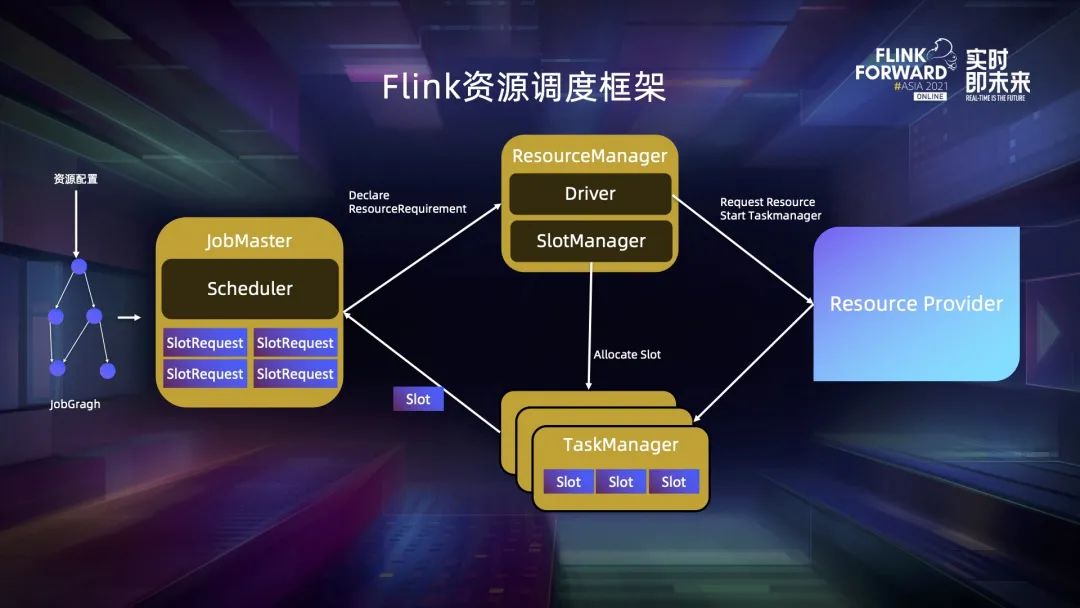
三、基于 SlotSharingGroup?的
資源配置接口



第一,使用戶的配置更靈活。我們將配置粒度的選擇權(quán)交給用戶,既可以配置算子的資源,也可以配置 task 資源,甚至配置子圖的資源,只需要將子圖放到一個 SSG 里然后配置它的資源即可。
第二,可以較為簡單地支持粗細(xì)粒度混合配置。所有配置的粒度都是 slot,不用擔(dān)心同一個 slot 中既包含粗粒度又包含細(xì)粒度的 task。對于粗粒度的 slot,可以簡單地按照 TM 默認(rèn)的規(guī)格計算它的資源大小,這個特性也使得細(xì)粒度資源管理的分配邏輯可以兼容粗粒度調(diào)度的,我們可以把粗粒度看作是細(xì)粒度的一種特例。
第三,它使得用戶可以利用不同算子之間的削峰填谷效應(yīng),有效減少偏差產(chǎn)生的影響。

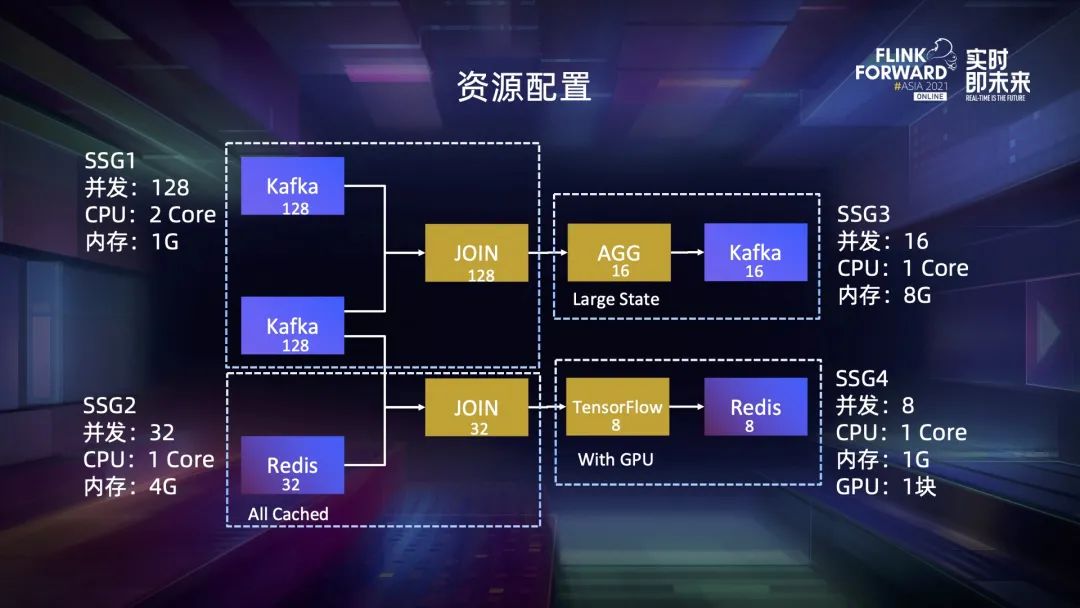
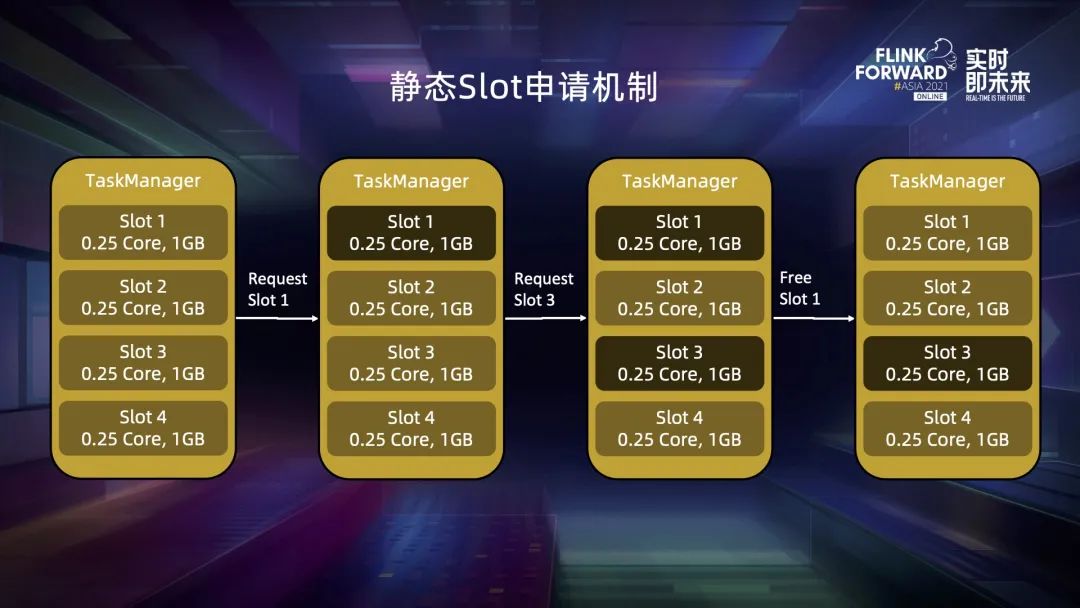
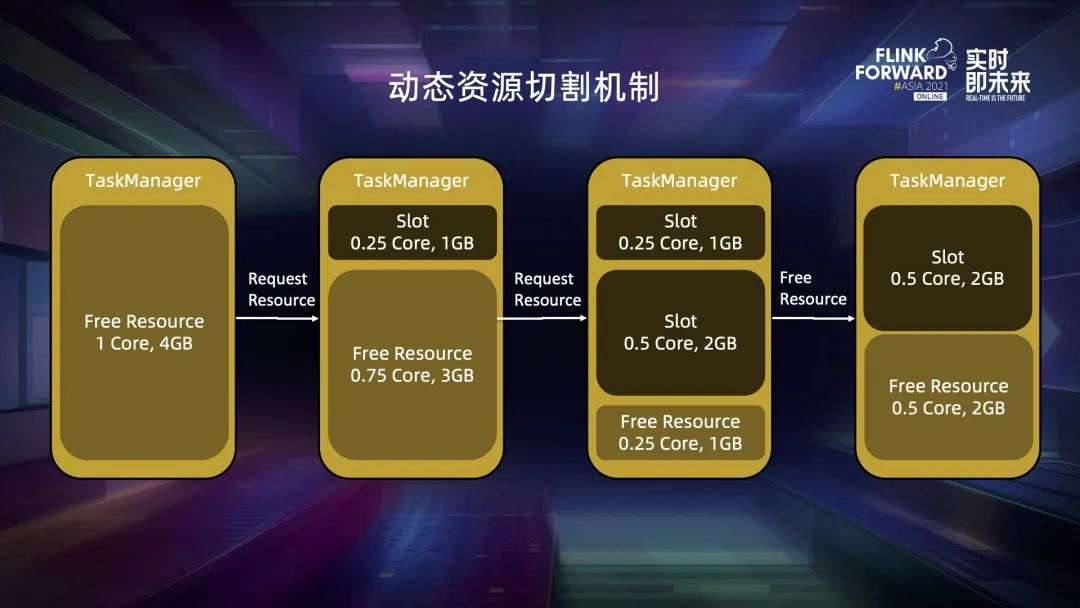
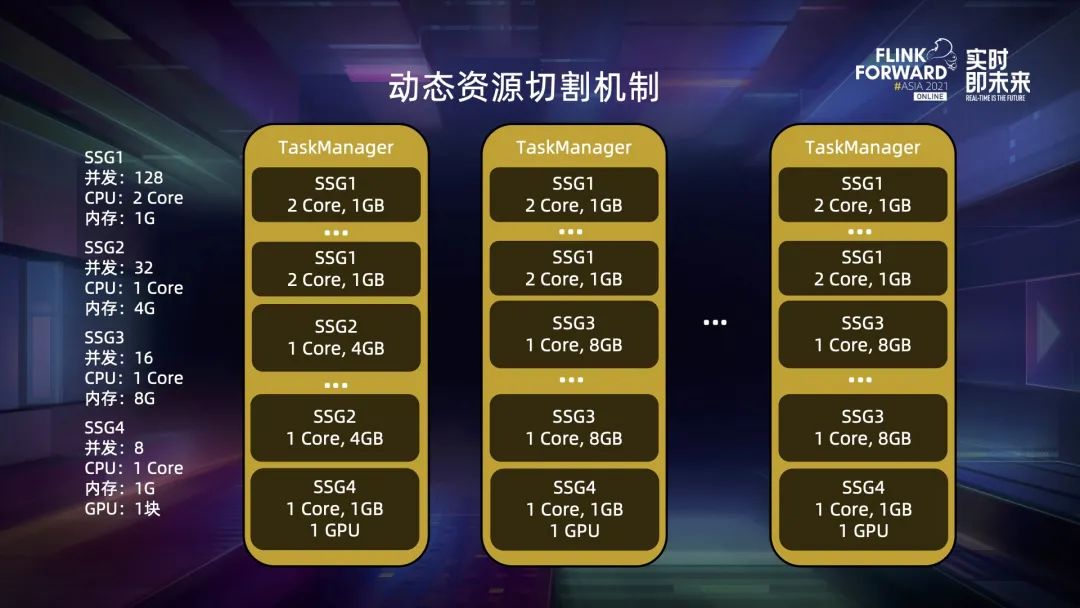
四、動態(tài)資源切割機制
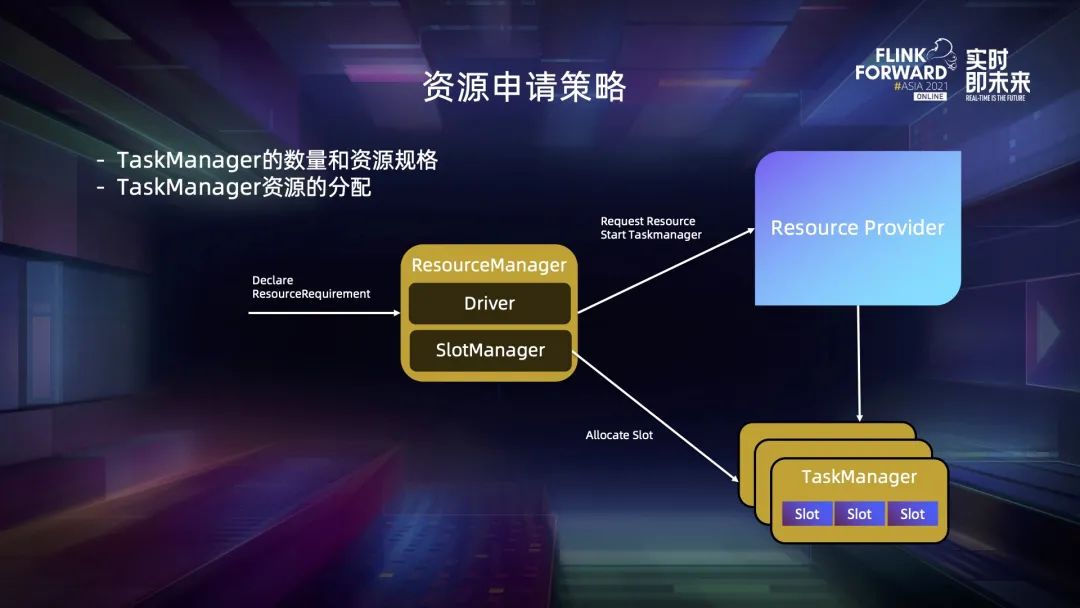
五、資源申請策略


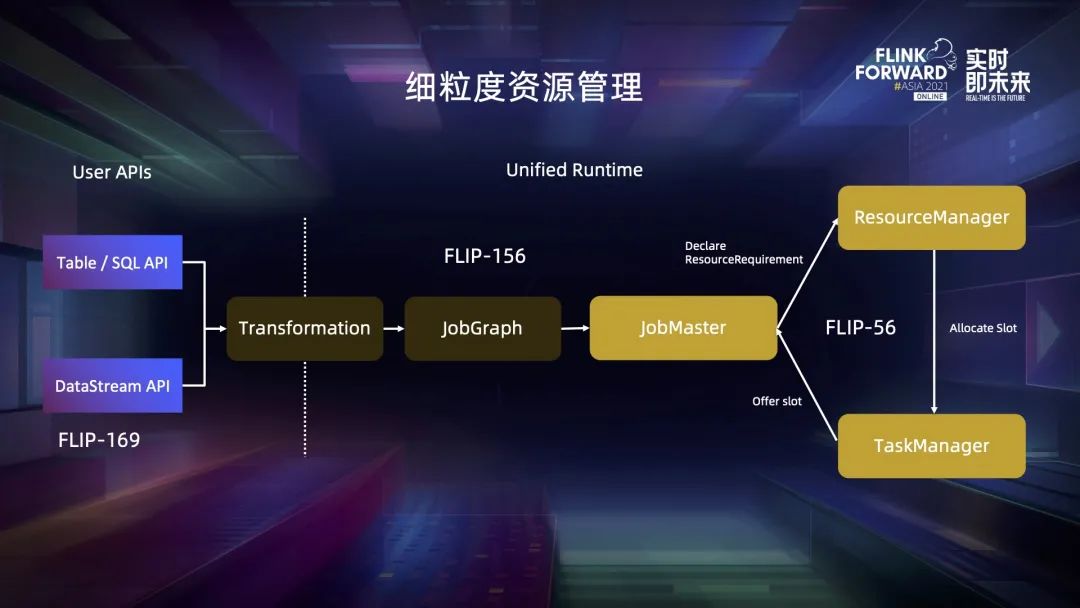
六、總結(jié)與未來展望

未來,我們的發(fā)展方向主要是以下幾個方面:
第一,定制更多的資源管理策略來滿足不同場景,比如 session 和 OLAP 等; 第二,目前我們是把擴展資源看作一個 TM 級別的資源,TM 上的每個 slot 都可以看到它的信息,之后我們會對它的 scope 進行進一步限制; 第三,目前細(xì)粒度資源管理可以支持粗細(xì)粒度混合配置,但是存在一些資源效率上的問題,比如粗粒度的 slot 請求可以被任意大小的 slot 滿足,未來我們會進一步優(yōu)化匹配邏輯,更好地支持混合配置; 第四,我們會考慮適配社區(qū)新提出的 Reactive Mode; 最后,對 WebUI 進行優(yōu)化,能夠展示 slot 的切分信息等。
往期精選




? ??戳我,查看原文視頻&演講PDF~
??戳我,查看原文視頻&演講PDF~
評論
圖片
表情