
來看看 MySQL 的這個(gè) BUG,坑了多少人....
來源:cloud.tencent.com/developer/article/1367681
問題描述
近期,線上有個(gè)重要Mysql客戶的表在從5.6升級到5.7后master上插入過程中出現(xiàn)"Duplicate key"的錯(cuò)誤,而且是在主備及RO實(shí)例上都出現(xiàn)。以其中一個(gè)表為例,遷移前通過“show create table” 命令查看的auto increment id為1758609, 遷移后變成了1758598,實(shí)際對遷移生成的新表的自增列用max求最大值為1758609。用戶采用的是Innodb引擎,而且據(jù)運(yùn)維同學(xué)介紹,之前碰到過類似問題,重啟即可恢復(fù)正常。
內(nèi)核問題排查
由于用戶反饋在5.6上訪問正常,切換到5.7后就報(bào)錯(cuò)。因此,首先得懷疑是5.7內(nèi)核出了問題,因此第一反應(yīng)是從官方bug list中搜索一下是否有類似問題存在,避免重復(fù)造車。經(jīng)過搜索,發(fā)現(xiàn)官方有1個(gè)類似的bug,這里簡單介紹一下該bug。
背景知識1:Innodb引擎中的auto increment 相關(guān)參數(shù)及數(shù)據(jù)結(jié)構(gòu)
主要參數(shù)包括:innodb_autoinc_lock_mode用于控制獲取自增值的加鎖方式,auto_increment_increment, auto_increment_offset用于控制自增列的遞增的間隔和起始偏移。
主要涉及的結(jié)構(gòu)體包括:數(shù)據(jù)字典結(jié)構(gòu)體,保存整個(gè)表的當(dāng)前auto increment值以及保護(hù)鎖;事務(wù)結(jié)構(gòu)體,保存事務(wù)內(nèi)部處理的行數(shù);handler結(jié)構(gòu)體,保存事務(wù)內(nèi)部多行的循環(huán)迭代信息。
這部分網(wǎng)上有篇文章介紹的比較好,具體參見:
https://www.cnblogs.com/zengkefu/p/5683258.html
背景知識2:mysql及Innodb引擎中對autoincrement訪問及修改的流程
(1) 數(shù)據(jù)字典結(jié)構(gòu)體(dict_table_t)換入換出時(shí)對autoincrement值的保存和恢復(fù)。換出時(shí)將autoincrement保存在全局的的映射表中,然后淘汰內(nèi)存中的dict_table_t。換入時(shí)通過查找全局映射表恢復(fù)到dict_table_t結(jié)構(gòu)體中。相關(guān)的函數(shù)為dict_table_add_to_cache及dict_table_remove_from_cache_low。
(2) row_import, table truncate過程更新autoincrement。
(3) handler首次open的時(shí)候,會查詢當(dāng)前表中最大自增列的值,并用最大列的值加1來初始化表的data_dict_t結(jié)構(gòu)體中的autoinc的值。
(4) insert流程。相關(guān)對autoinc修改的堆棧如下:
ha_innobase::write_row:write_row的第三步中調(diào)用handler句柄中的update_auto_increment函數(shù)更新auto?increment的值
????handler::update_auto_increment:?調(diào)用Innodb接口獲取一個(gè)自增值,并根據(jù)當(dāng)前的auto_increment相關(guān)變量的值調(diào)整獲取的自增值;同時(shí)設(shè)置當(dāng)前handler要處理的下一個(gè)自增列的值。
????????ha_innobase::get_auto_increment:獲取dict_tabel中的當(dāng)前auto?increment值,并根據(jù)全局參數(shù)更新下一個(gè)auto?increment的值到數(shù)據(jù)字典中
????????????ha_innobase::dict_table_autoinc_initialize:更新auto?increment的值,如果指定的值比當(dāng)前的值大,則更新。
????????handler::set_next_insert_id:設(shè)置當(dāng)前事務(wù)中下一個(gè)要處理的行的自增列的值。
(5) update_row。對于”INSERT INTO t (c1,c2) VALUES(x,y) ON DUPLICATE KEY UPDATE”語句,無論唯一索引列所指向的行是否存在,都需要推進(jìn)auto increment的值。
相關(guān)代碼如下:
????if?(error?==?DB_SUCCESS
????????&&?table->next_number_field
????????&&?new_row?==?table->record[0]
????????&&?thd_sql_command(m_user_thd)?==?SQLCOM_INSERT
????????&&?trx->duplicates)??{
????????ulonglong????auto_inc;
????????????????……
????????auto_inc?=?table->next_number_field->val_int();
????????auto_inc?=?innobase_next_autoinc(auto_inc,?1,?increment,?offset,?col_max_value);
????????????error?=?innobase_set_max_autoinc(auto_inc);
????????????????……
????}
從我們的實(shí)際業(yè)務(wù)流程來看,我們的錯(cuò)誤只可能涉及insert及update流程。
BUG 76872 / 88321: "InnoDB AUTO_INCREMENT produces same value twice"
(1) bug概述:當(dāng)autoinc_lock_mode大于0,且auto_increment_increment大于1時(shí),系統(tǒng)剛重啟后多線程同時(shí)對表進(jìn)行insert操作會產(chǎn)生“duplicate key”的錯(cuò)誤。
(2) 原因分析:重啟后innodb會把a(bǔ)utoincrement的值設(shè)置為max(id) + 1。此時(shí),首次插入時(shí),write_row流程會調(diào)用handler::update_auto_increment來設(shè)置autoinc相關(guān)的信息。首先通過ha_innobase::get_auto_increment獲取當(dāng)前的autoincrement的值(即max(id) + 1),并根據(jù)autoincrement相關(guān)參數(shù)修改下一個(gè)autoincrement的值為next_id。當(dāng)auto_increment_increment大于1時(shí),max(id) + 1 會不大于next_id。
handler::update_auto_increment獲取到引擎層返回的值后為了防止有可能某些引擎計(jì)算自增值時(shí)沒有考慮到當(dāng)前auto increment參數(shù),會重新根據(jù)參數(shù)計(jì)算一遍當(dāng)前行的自增值,由于Innodb內(nèi)部是考慮了全局參數(shù)的,因此handle層對Innodb返回的自增id算出的自增值也為next_id,即將會插入一條自增id為next_id的行。
handler層會在write_row結(jié)束的時(shí)候根據(jù)當(dāng)前行的值next_id設(shè)置下一個(gè)autoincrement值。如果在write_row尚未設(shè)置表的下一個(gè)autoincrement期間,有另外一個(gè)線程也在進(jìn)行插入流程,那么它獲取到的自增值將也是next_id。這樣就產(chǎn)生了重復(fù)。
(3) 解決辦法:引擎內(nèi)部獲取自增列時(shí)考慮全局autoincrement參數(shù),這樣重啟后第一個(gè)插入線程獲取的自增值就不是max(id) + 1,而是next_id,然后根據(jù)next_id設(shè)置下一個(gè)autoincrement的值。由于這個(gè)過程是加鎖保護(hù)的,其他線程再獲取autoincrement的時(shí)候就不會獲取到重復(fù)的值。
通過上述分析,這個(gè)bug僅在autoinc_lock_mode > 0 并且auto_increment_increment > 1的情況下會發(fā)生。實(shí)際線上業(yè)務(wù)對這兩個(gè)參數(shù)都設(shè)置為1,因此,可以排除這個(gè)bug造成線上問題的可能性。
現(xiàn)場分析及復(fù)現(xiàn)驗(yàn)證
既然官方bug未能解決我們的問題,那就得自食其力,從錯(cuò)誤現(xiàn)象開始分析了。
(1) 分析max id及autoincrement的規(guī)律
由于用戶的表設(shè)置了ON UPDATE CURRENT_TIMESTAMP列,因此可以把所有的出錯(cuò)的表的max id、autoincrement及最近更新的幾條記錄抓取出來,看看是否有什么規(guī)律。抓取的信息如下:
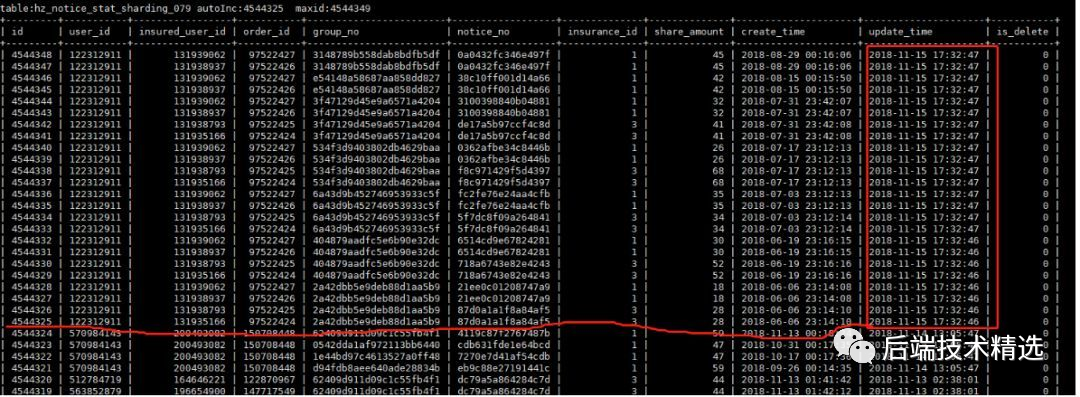
乍看起來,這個(gè)錯(cuò)誤還是很有規(guī)律的,update time這一列是最后插入或者修改的時(shí)間,結(jié)合auto increment及max id的值,現(xiàn)象很像是最后一批事務(wù)只更新了行的自增id,沒有更新auto increment的值。
聯(lián)想到【官方文檔】中對auto increment用法的介紹,update操作是可以只更新自增id但不觸發(fā)auto increment推進(jìn)的。按照這個(gè)思路,我嘗試復(fù)現(xiàn)了用戶的現(xiàn)場。復(fù)現(xiàn)方法如下:
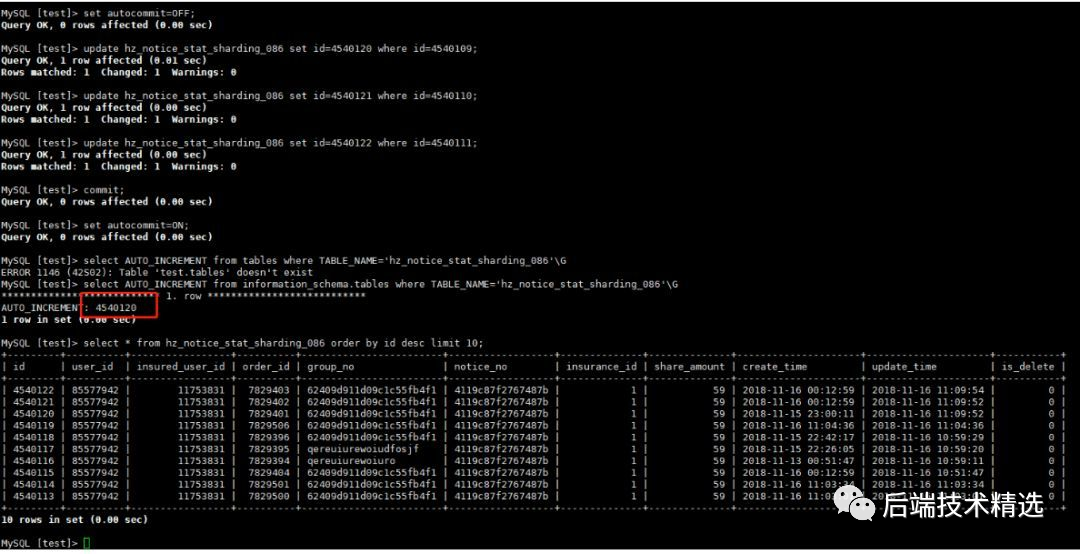
同時(shí)在binlog中,我們也看到有update自增列的操作。如圖:
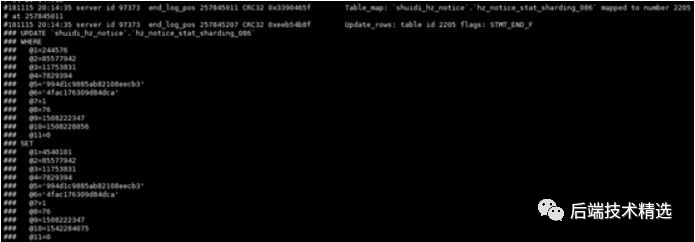
不過,由于binlog是ROW格式,我們也無法判斷這是內(nèi)核出問題導(dǎo)致了自增列的變化還是用戶自己更新所致。因此我們聯(lián)系了客戶進(jìn)行確認(rèn),結(jié)果用戶很確定沒有進(jìn)行更新自增列的操作。那么這些自增列到底是怎么來的呢?
(2) 分析用戶的表及sql語句
繼續(xù)分析,發(fā)現(xiàn)用戶總共有三種類型的表
hz_notice_stat_sharding,
hz_notice_group_stat_sharding,
hz_freeze_balance_sharding,
這三種表都有自增主鍵。但是前面兩種都出現(xiàn)了autoinc錯(cuò)誤,唯獨(dú)hz_freeze_balance_sharding表沒有出錯(cuò)。
難道是用戶對這兩種表的訪問方式不一樣?抓取用戶的sql語句,果然,前兩種表用的都是replace into操作,最后一種表用的是update操作。難道是replace into語句導(dǎo)致的問題?
搜索官方bug, 又發(fā)現(xiàn)了一個(gè)疑似bug。
bug #87861: “Replace into causes master/slave have different auto_increment offset values”
原因:
(1) Mysql對于replace into實(shí)際是通過delete + insert語句實(shí)現(xiàn),但是在ROW binlog格式下,會向binlog記錄update類型日志。Insert語句會同步更新autoincrement,update則不會。
(2) replace into在Master上按照delete+insert方式操作, autoincrement就是正常的。基于ROW格式復(fù)制到slave后,slave機(jī)上按照update操作回放,只更新行中自增鍵的值,不會更新autoincrement。因此在slave機(jī)上就會出現(xiàn)max(id)大于autoincrement的情況。此時(shí)在ROW模式下對于insert操作binlog記錄了所有的列的值,在slave上回放時(shí)并不會重新分配自增id,因此不會報(bào)錯(cuò)。但是如果slave切master,遇到Insert操作就會出現(xiàn)”Duplicate key”的錯(cuò)誤。
(3) 由于用戶是從5.6遷移到5.7,然后直接在5.7上進(jìn)行插入操作,相當(dāng)于是slave切主,因此會報(bào)錯(cuò)。
解決方案
業(yè)務(wù)側(cè)的可能解決方案:
binlog改為mixed或者statement格式
用Insert on duplicate key update代替replace into
內(nèi)核側(cè)可能解決方案:
在ROW格式下如果遇到replace into語句,則記錄statement格式的logevent,將原始語句記錄到binlog。
在ROW格式下將replace into語句的logevent記錄為一個(gè)delete event和一個(gè)insert event。
心得
(1) autoincrement的autoinc_lock_mode及auto_increment_increment這兩個(gè)參數(shù)變化容易導(dǎo)致出現(xiàn)重復(fù)的key,使用過程中要盡量避免動態(tài)的去修改。
(2) 在碰到線上的問題時(shí),首先應(yīng)該做好現(xiàn)場分析,明確故障發(fā)生的場景、用戶的SQL語句、故障發(fā)生的范圍等信息,同時(shí)要對涉及實(shí)例的配置信息、binlog甚至實(shí)例數(shù)據(jù)等做好備份以防過期丟失。只有這樣才能在找官方bug時(shí)精準(zhǔn)的匹配場景,如果官方?jīng)]有相關(guān)bug,也能通過已有線索獨(dú)立分析。

之前給大家發(fā)過四份Java面試寶典,這次新增了更全面的資料,相信在跳槽前準(zhǔn)備準(zhǔn)備,基本沒大問題。
《java基礎(chǔ):設(shè)計(jì)模式等》(初中級)
《JVM:整理BAT最新題庫》《并發(fā)編程》(中高級)
《分布式微服務(wù)架構(gòu)》《架構(gòu)|軟技能》(資深)
《一線互聯(lián)網(wǎng)公司面試指南》(資深)
分別適用于初中級,中高級,資深級工程師的面試復(fù)習(xí)。內(nèi)容包含java基礎(chǔ)、JVM、并發(fā)編程、分布式微服務(wù)、架構(gòu)|軟技能、算法等等。
學(xué)習(xí)視頻包含深入運(yùn)行時(shí)數(shù)據(jù)區(qū)、垃圾回收、詳解類裝載過程及類加載機(jī)制、手寫Spring-IOC容器、redis入門到高性能緩存組件等等
獲取方式:加小編微信即可領(lǐng)取,資料持續(xù)更新!
點(diǎn)贊是最大的支持?![]()