
Kafka架構(gòu)及基本原理簡析
300本計(jì)算機(jī)編程的經(jīng)典書籍下載
AI全套:Python3+TensorFlow打造人臉識(shí)別智能小程序
最新人工智能資料-Google工程師親授 Tensorflow-入門到進(jìn)階
黑馬頭條項(xiàng)目 - Java Springboot2.0(視頻、資料、代碼和講義)14天完整版
作者:老羊_肖恩,鏈接:https://www.jianshu.com/p/6237e5d59afd Kafka簡介
Kafka是一個(gè)由Scala和Java編寫的企業(yè)級(jí)的消息發(fā)布和訂閱系統(tǒng),最早是由Linkedin公司開發(fā),最終開源到Apache軟件基金會(huì)的項(xiàng)目。Kafka是一個(gè)分布式的,支持分區(qū)的,多副本的和多訂閱者的高吞吐量的消息系統(tǒng),被廣泛應(yīng)用在應(yīng)用解耦、異步處理、限流削峰和消息驅(qū)動(dòng)等場景。本文將針對(duì)Kafka的架構(gòu)和相關(guān)組件進(jìn)行簡單的介紹。在介紹Kafka的架構(gòu)之前,我們先了解一下Kafk的核心概念。
Kafka核心概念
在詳細(xì)介紹Kafka的架構(gòu)和基本組件之前,需要先了解一下Kafka的一些核心概念。 Producer:消息的生產(chǎn)者,負(fù)責(zé)往Kafka集群中發(fā)送消息; Consumer:消息的消費(fèi)者,主動(dòng)從Kafka集群中拉取消息。
Consumer Group:每個(gè)Consumer屬于一個(gè)特定的Consumer Group,新建Consumer的時(shí)候需要指定對(duì)應(yīng)的Consumer Group ID。
Broker:Kafka集群中的服務(wù)實(shí)例,也稱之為節(jié)點(diǎn),每個(gè)Kafka集群包含一個(gè)或者多個(gè)Broker(一個(gè)Broker就是一個(gè)服務(wù)器或節(jié)點(diǎn))。
Message:通過Kafka集群進(jìn)行傳遞的對(duì)象實(shí)體,存儲(chǔ)需要傳送的信息。
Topic:消息的類別,主要用于對(duì)消息進(jìn)行邏輯上的區(qū)分,每條發(fā)送到Kafka集群的消息都需要有一個(gè)指定的Topic,消費(fèi)者根據(jù)Topic對(duì)指定的消息進(jìn)行消費(fèi)。搜索公眾號(hào)互聯(lián)網(wǎng)架構(gòu)師復(fù)“2T”,送你一份驚喜禮包。Partition:消息的分區(qū),Partition是一個(gè)物理上的概念,相當(dāng)于一個(gè)文件夾,Kafka會(huì)為每個(gè)topic的每個(gè)分區(qū)創(chuàng)建一個(gè)文件夾,一個(gè)Topic的消息會(huì)存儲(chǔ)在一個(gè)或者多個(gè)Partition中。
Segment:一個(gè)partition當(dāng)中存在多個(gè)segment文件段(分段存儲(chǔ)),每個(gè)Segment分為兩部分,.log文件和 .index 文件,其中 .index 文件是索引文件,主要用于快速查詢.log 文件當(dāng)中數(shù)據(jù)的偏移量位置;
.log文件:存放Message的數(shù)據(jù)文件,在Kafka中把數(shù)據(jù)文件就叫做日志文件。一個(gè)分區(qū)下面默認(rèn)有n多個(gè).log文件(分段存儲(chǔ))。一個(gè).log文件大默認(rèn)1G,消息會(huì)不斷追加在.log文件中,當(dāng).log文件的大小超過1G的時(shí)候,會(huì)自動(dòng)新建一個(gè)新的.log文件。
.index文件:存放.log文件的索引數(shù)據(jù),每個(gè).index文件有一個(gè)對(duì)應(yīng)同名的.log文件。
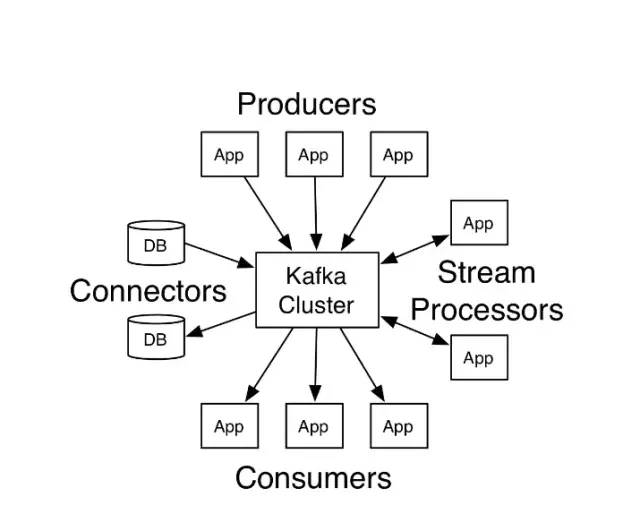
Kafka API
如上圖所示,Kafka主要包含四個(gè)主要的API組件: 1. Producer API
應(yīng)用程序通過Producer API向Kafka集群發(fā)送一個(gè)或多個(gè)Topic的消息。2. Consumer API
應(yīng)用程序通過Consumer API,向Kafka集群訂閱一個(gè)或多個(gè)Topic的消息,并處理這些Topic下接收到的消息。4. Connect API
允許應(yīng)用程序通過Connect API構(gòu)建和運(yùn)行可重用的生產(chǎn)者或者消費(fèi)者,能夠把kafka主題連接到現(xiàn)有的應(yīng)用程序或數(shù)據(jù)系統(tǒng)。Connect實(shí)際上就做了兩件事情:使用Source Connector從數(shù)據(jù)源(如:DB)中讀取數(shù)據(jù)寫入到Topic中,然后再通過Sink Connector讀取Topic中的數(shù)據(jù)輸出到另一端(如:DB),以實(shí)現(xiàn)消息數(shù)據(jù)在外部存儲(chǔ)和Kafka集群之間的傳輸。Kafka架構(gòu)
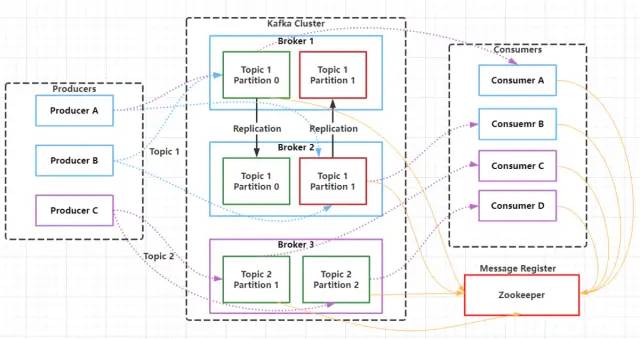
接下來我們將從Kafka的架構(gòu)出發(fā),重點(diǎn)介紹Kafka的主要組件及實(shí)現(xiàn)原理。Kafka支持消息持久化,消費(fèi)端是通過主動(dòng)拉取消息進(jìn)行消息消費(fèi)的,訂閱狀態(tài)和訂閱關(guān)系由客戶端負(fù)責(zé)維護(hù),消息消費(fèi)完后不會(huì)立刻刪除,會(huì)保留歷史消息,一般默認(rèn)保留7天,因此可以通過在支持多訂閱者時(shí),消息無需復(fù)制多分,只需要存儲(chǔ)一份就可以。下面將詳細(xì)介紹每個(gè)組件的實(shí)現(xiàn)原理。
1. Producer
Producer是Kafka中的消息生產(chǎn)者,主要用于生產(chǎn)帶有特定Topic的消息,生產(chǎn)者生產(chǎn)的消息通過Topic進(jìn)行歸類,保存在Kafka 集群的Broker上,具體的是保存在指定的partition 的目錄下,以Segment的方式(.log文件和.index文件)進(jìn)行存儲(chǔ)。搜索公眾號(hào)互聯(lián)網(wǎng)架構(gòu)師復(fù)“2T”,送你一份驚喜禮包。3. Topic
Kafka中的消息是根據(jù)Topic進(jìn)行分類的,Topic是支持多訂閱的,一個(gè)Topic可以有多個(gè)不同的訂閱消息的消費(fèi)者。Kafka集群Topic的數(shù)量沒有限制,同一個(gè)Topic的數(shù)據(jù)會(huì)被劃分在同一個(gè)目錄下,一個(gè)Topic可以包含1至多個(gè)分區(qū),所有分區(qū)的消息加在一起就是一個(gè)Topic的所有消息。4. Partition
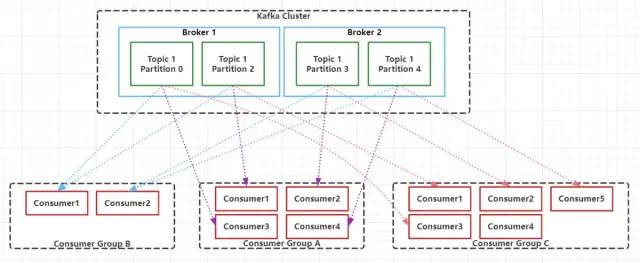
在Kafka中,為了提升消息的消費(fèi)速度,可以為每個(gè)Topic分配多個(gè)Partition,這也是就之前我們說到的,Kafka是支持多分區(qū)的。默認(rèn)情況下,一個(gè)Topic的消息只存放在一個(gè)分區(qū)中。Topic的所有分區(qū)的消息合并起來,就是一個(gè)Topic下的所有消息。每個(gè)分區(qū)都有一個(gè)從0開始的編號(hào),每個(gè)分區(qū)內(nèi)的數(shù)據(jù)都是有序的,但是不同分區(qū)直接的數(shù)據(jù)是不能保證有序的,因?yàn)椴煌姆謪^(qū)需要不同的Consumer去消費(fèi),每個(gè)Partition只能分配一個(gè)Consumer,但是一個(gè)Consumer可以同時(shí)一個(gè)Topic的多個(gè)Partition。在層級(jí)關(guān)系上來說Consumer好比是跟Topic對(duì)應(yīng)的,而Consumer就對(duì)應(yīng)于Topic下的Partition。Consumer Group中的Consumer數(shù)量和Topic下的Partition數(shù)量共同決定了消息消費(fèi)的并發(fā)量,且Partition數(shù)量決定了最終并發(fā)量,因?yàn)橐粋€(gè)Partition只能由一個(gè)Consumer進(jìn)行消費(fèi)。當(dāng)一個(gè)Consumer Group中Consumer數(shù)量超過訂閱的Topic下的Partition數(shù)量時(shí),Kafka會(huì)為每個(gè)Partition分配一個(gè)Consumer,多出來的Consumer會(huì)處于空閑狀態(tài)。當(dāng)Consumer Group中Consumer數(shù)量少于當(dāng)前定于的Topic中的Partition數(shù)量是,單個(gè)Consumer將承擔(dān)多個(gè)Partition的消費(fèi)工作。如上圖所示,Consumer Group B中的每個(gè)Consumer需要消費(fèi)兩個(gè)Partition中的數(shù)據(jù),而Consumer Group C中會(huì)多出來一個(gè)空閑的Consumer4。總結(jié)下來就是:同一個(gè)Topic下的Partition數(shù)量越多,同一時(shí)間可以有越多的Consumer進(jìn)行消費(fèi),消費(fèi)的速度就會(huì)越快,吞吐量就越高。同時(shí),Consumer Group中的Consumer數(shù)量需要控制為小于等于Partition數(shù)量,且最好是整數(shù)倍:如1,2,4等。 6. Segment
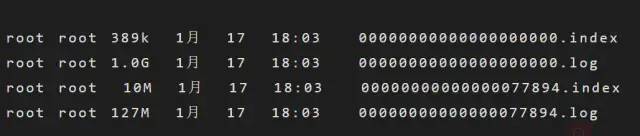
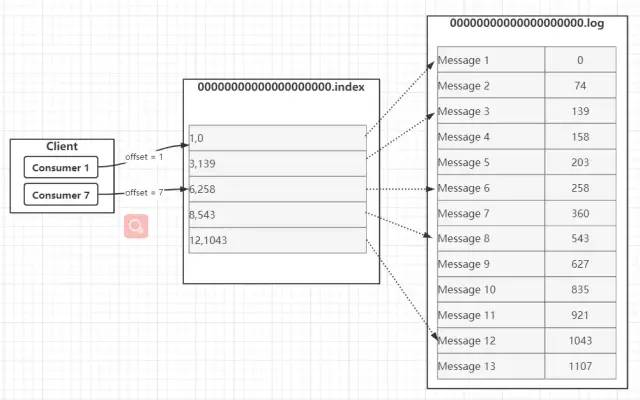
考慮到消息消費(fèi)的性能,Kafka中的消息在每個(gè)Partition中是以分段的形式進(jìn)行存儲(chǔ)的,即每1G消息新建一個(gè)Segment,每個(gè)Segment包含兩個(gè)文件:.log文件和.index文件。之前我們已經(jīng)說過,.log文件就是Kafka實(shí)際存儲(chǔ)Producer生產(chǎn)的消息,而.index文件采用稀疏索引的方式存儲(chǔ).log文件中對(duì)應(yīng)消息的邏輯編號(hào)和物理偏移地址(offset),以便于加快數(shù)據(jù)的查詢速度。.log文件和.index文件是一一對(duì)應(yīng),成對(duì)出現(xiàn)的。下圖展示了.log文件和.index文件在Partition中的存在方式。Kafka里面每一條消息都有自己的邏輯offset(相對(duì)偏移量)以及存在物理磁盤上面實(shí)際的物理地址便宜量Position,也就是說在Kafka中一條消息有兩個(gè)位置:offset(相對(duì)偏移量)和position(磁盤物理偏移地址)。在kafka的設(shè)計(jì)中,將消息的offset作為了Segment文件名的一部分。Segment文件命名規(guī)則為:Partition全局的第一個(gè)Segment從0開始,后續(xù)每個(gè)segment文件名為上一個(gè)Partition的最大offset(Message的offset,非實(shí)際物理地偏移地址,實(shí)際物理地址需映射到.log中,后面會(huì)詳細(xì)介紹在.log文件中查詢消息的原理)。數(shù)值最大為64位long大小,由20位數(shù)字表示,前置用0填充。 上圖展示了.index文件和.log文件直接的映射關(guān)系,通過上圖,我們可以簡單介紹一下Kafka在Segment中查找Message的過程: ??1.根據(jù)需要消費(fèi)的下一個(gè)消息的offset,這里假設(shè)是7,使用二分查找在Partition中查找到文件名小于(一定要小于,因?yàn)槲募幪?hào)等于當(dāng)前offset的文件里存的都是大于當(dāng)前offset的消息)當(dāng)前offset的最大編號(hào)的.index文件,這里自然是查找到了00000000000000000000.index。 ??2.在.index文件中,使用二分查找,找到offset小于或者等于指定offset(這里假設(shè)是7)的最大的offset,這里查到的是6,然后獲取到index文件中offset為6指向的Position(物理偏移地址)為258。 ??3.在.log文件中,從磁盤位置258開始順序掃描,直到找到offset為7的Message。 至此,我們就簡單介紹完了Segment的基本組件.index文件和.log文件的存儲(chǔ)和查詢?cè)怼5俏覀儠?huì)發(fā)現(xiàn)一個(gè)問題:.index文件中的offset并不是按順序連續(xù)存儲(chǔ)的,為什么Kafka要將索引文件設(shè)計(jì)成這種不連續(xù)的樣子?這種不連續(xù)的索引設(shè)計(jì)方式稱之為稀疏索引,Kafka中采用了稀疏索引的方式讀取索引,kafka每當(dāng).log中寫入了4k大小的數(shù)據(jù),就往.index里以追加的寫入一條索引記錄。使用稀疏索引主要有以下原因: ??(1)索引稀疏存儲(chǔ),可以大幅降低.index文件占用存儲(chǔ)空間大小。
??(2)稀疏索引文件較小,可以全部讀取到內(nèi)存中,可以避免讀取索引的時(shí)候進(jìn)行頻繁的IO磁盤操作,以便通過索引快速地定位到.log文件中的Message。搜索公眾號(hào)互聯(lián)網(wǎng)架構(gòu)師復(fù)“2T”,送你一份驚喜禮包。7. Message Message是實(shí)際發(fā)送和訂閱的信息是實(shí)際載體,Producer發(fā)送到Kafka集群中的每條消息,都被Kafka包裝成了一個(gè)Message對(duì)象,之后再存儲(chǔ)在磁盤中,而不是直接存儲(chǔ)的。Message在磁盤中的物理結(jié)構(gòu)如下所示。 On-disk?format?of?a?message
offset?????????:?8?bytes?
message?length?:?4?bytes?(value:?4?+?1?+?1?+?8(if?magic?value?>?0)?+?4?+?K?+?4?+?V)
crc????????????:?4?bytes
magic?value????:?1?byte
attributes?????:?1?byte
timestamp??????:?8?bytes?(Only?exists?when?magic?value?is?greater?than?zero)
key?length?????:?4?bytes
key????????????:?K?bytes
value?length???:?4?bytes
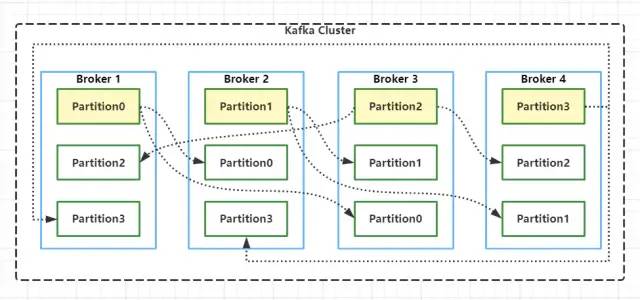
value??????????:?V?bytes其中 key和value存儲(chǔ)的是實(shí)際的Message內(nèi)容,長度不固定,而其他都是對(duì)Message內(nèi)容的統(tǒng)計(jì)和描述,長度固定。因此在查找實(shí)際Message過程中,磁盤指針會(huì)根據(jù)Message的offset和message length計(jì)算移動(dòng)位數(shù),以加速M(fèi)essage的查找過程。之所以可以這樣加速,因?yàn)镵afka的.log文件都是順序?qū)懙模疟P上寫數(shù)據(jù)時(shí),就是追加數(shù)據(jù),沒有隨機(jī)寫的操作。8.Partition Replicas 最后我們簡單聊一下Kafka中的Partition Replicas(分區(qū)副本)機(jī)制,0.8版本以前的Kafka是沒有副本機(jī)制的。創(chuàng)建Topic時(shí),可以為Topic指定分區(qū),也可以指定副本個(gè)數(shù)。kafka 中的分區(qū)副本如下圖所示: Kafka通過副本因子(replication-factor)控制消息副本保存在幾個(gè)Broker(服務(wù)器)上,一般情況下副本數(shù)等于Broker的個(gè)數(shù),且同一個(gè)副本因子不能放在同一個(gè)Broker中。副本因子是以分區(qū)為單位且區(qū)分角色;主副本稱之為Leader(任何時(shí)刻只有一個(gè)),從副本稱之為 Follower(可以有多個(gè)),處于同步狀態(tài)的副本叫做in-sync-replicas(ISR)。Leader負(fù)責(zé)讀寫數(shù)據(jù),F(xiàn)ollower不負(fù)責(zé)對(duì)外提供數(shù)據(jù)讀寫,只從Leader同步數(shù)據(jù),消費(fèi)者和生產(chǎn)者都是從leader讀寫數(shù)據(jù),不與follower交互,因此Kafka并不是讀寫分離的。同時(shí)使用Leader進(jìn)行讀寫的好處是,降低了數(shù)據(jù)同步帶來的數(shù)據(jù)讀取延遲,因?yàn)镕ollower只能從Leader同步完數(shù)據(jù)之后才能對(duì)外提供讀取服務(wù)。 如果一個(gè)分區(qū)有三個(gè)副本因子,就算其中一個(gè)掛掉,那么只會(huì)剩下的兩個(gè)中,選擇一個(gè)leader,如下圖所示。但不會(huì)在其他的broker中,另啟動(dòng)一個(gè)副本(因?yàn)樵诹硪慌_(tái)啟動(dòng)的話,必然存在數(shù)據(jù)拷貝和傳輸,會(huì)長時(shí)間占用網(wǎng)絡(luò)IO,Kafka是一個(gè)高吞吐量的消息系統(tǒng),這個(gè)情況不允許發(fā)生)。如果指定分區(qū)的所有副本都掛了,Consumer如果發(fā)送數(shù)據(jù)到指定分區(qū)的話,將寫入不成功。Consumer發(fā)送到指定Partition的消息,會(huì)首先寫入到Leader Partition中,寫完后還需要把消息寫入到ISR列表里面的其它分區(qū)副本中,寫完之后這個(gè)消息才能提交offset。 到這里,差不多把Kafka的架構(gòu)和基本原理簡單介紹完了。Kafka為了實(shí)現(xiàn)高吞吐量和容錯(cuò),還引入了很多優(yōu)秀的設(shè)計(jì)思路,如零拷貝,高并發(fā)網(wǎng)絡(luò)設(shè)計(jì),順序存儲(chǔ),以后有時(shí)間再說。
全棧架構(gòu)社區(qū)交流群

?「全棧架構(gòu)社區(qū)」建立了讀者架構(gòu)師交流群,大家可以添加小編微信進(jìn)行加群。歡迎有想法、樂于分享的朋友們一起交流學(xué)習(xí)。
看完本文有收獲?請(qǐng)轉(zhuǎn)發(fā)分享給更多人
Flutter 移動(dòng)應(yīng)用開發(fā)實(shí)戰(zhàn) 視頻(開發(fā)你自己的抖音APP) Java面試進(jìn)階訓(xùn)練營 第2季(分布式篇) Java高級(jí) - 分布式系統(tǒng)開發(fā)技術(shù)視頻
2019最新Python視頻:從入門到Swiper項(xiàng)目實(shí)戰(zhàn)
2019重磅高級(jí)資源:Java并發(fā)編程原理和實(shí)戰(zhàn)
最新黑馬大數(shù)據(jù)資源:深入解析docker容器化技術(shù)
最新Java后端實(shí)戰(zhàn)視頻:SSM框架在線商城系統(tǒng)
2019最新黑客技術(shù)之Windows網(wǎng)絡(luò)安全精講
2019最新Python實(shí)戰(zhàn)視頻:Python+Django項(xiàng)目實(shí)
黑馬 - Python數(shù)據(jù)結(jié)構(gòu)與算法系列課程