終究還是「卷」到了自家。
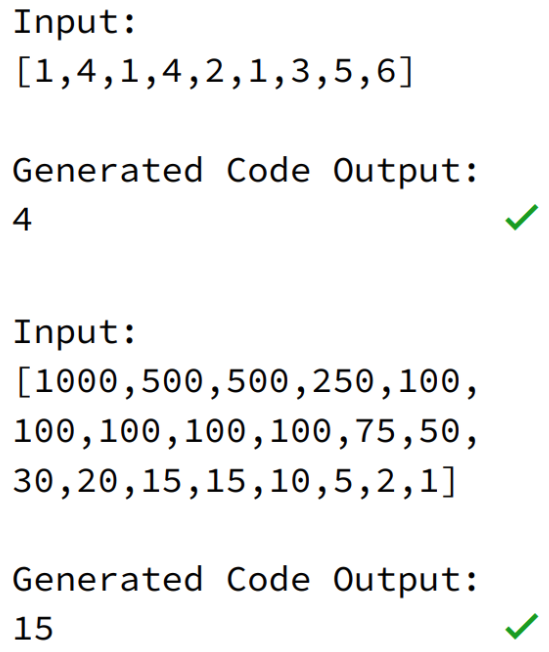
已知一個論文引用量序列,其中每個引用量都是非負整數(shù),請編寫一個輸出為 h_index 的同名函數(shù) h_index()。其中 h_index 指至多有 h 篇論文分別被引用了至少 h 次。
這段代碼雖然在細節(jié)上存在一些問題,卻能夠順利通過部分樣例測試。而它居然是 AI 寫的!隨著深度學(xué)習(xí)的興起,AI 讓許多行業(yè)實現(xiàn)了自動化,包括將 AI 用于編程。人們在編程時通常會使用大量的有意識和潛意識思維機制發(fā)現(xiàn)新問題并探索不同的解決方案,然而大多數(shù)機器學(xué)習(xí)算法都需要定義明確的問題和大量帶有注釋的數(shù)據(jù)才能夠開發(fā)出解決相同編程問題的模型,因此用 AI 編程并非易事。此外,準確地評估模型的代碼生成性能可能是很困難的,并且很少有既靈活又嚴格的方式來評估代碼生成的研究。基于此,來自 UC 伯克利等機構(gòu)的研究者提出了 APPS(Automated Programming Progress Standard),一個代碼生成基準,該基準測試能夠衡量模型的代碼生成能力,并檢查代碼是否符合問題要求。與公司評估候選軟件開發(fā)人員的方式類似,該研究通過檢查生成的代碼在測試用例上的結(jié)果來評估模型。基準測試包括 10000 個問題,包含單行代碼解決的簡單問題和具有大量代碼的復(fù)雜算法挑戰(zhàn)等多多種問題。上述 AI 生成代碼示例在 APPS 數(shù)據(jù)集中被視為「面試級別」的問題。對此,有網(wǎng)友說道:「如果我不能通過編碼面試,但我寫的算法通過了,那么會怎樣?」問題:已知兩個整數(shù) n 和 m。計算數(shù)組(a,b)對數(shù),使兩個數(shù)組的長度都等于 m;每個數(shù)組的元素都是 1 到 n 之間的整數(shù);對于任意索引 i 從 1 到 m,都有 a_i≤ b_i;數(shù)組 a 按非降序排列;數(shù)組 b 按非升序排序。結(jié)果可能很大,應(yīng)該打印它的 modulo10^9+7。輸入:唯一的行包含兩個整數(shù) n 和 m(1≤ n≤ 1000,1≤ m≤ 10)。輸出:打印一個整數(shù),滿足上述 modulo10^9+7 所述條件的數(shù)組 a 和 b 的數(shù)量。
根據(jù)問題描述,AI 自動生成代碼,盡管生成的代碼通過了 0 個測試用例,但第一眼看起來似乎是可行的:研究者在 GitHub 和訓(xùn)練集上對大型語言模型進行了微調(diào),并發(fā)現(xiàn)微調(diào)后語法錯誤率呈指數(shù)級下降。在 GPT-Neo 等模型上可以通過大約 15% 的入門問題測試用例。APPS 數(shù)據(jù)集包括從 Codeforces、Kattis 等不同的開放編碼網(wǎng)站收集的問題。APPS 基準試圖通過以不受限制的自然語言提出編碼問題并評估解決方案的正確性來反映人類程序員的評估方式。問題的難度范圍從入門到大學(xué)競賽水平,用來衡量編碼能力和解決問題的能力。APPS 總共包含 10000 個編碼問題,其中包括 131836 個用于檢查解決方案的測試用例和 232444 個由人類編寫的真實解決方案。里面的問題可能是很復(fù)雜,因為平均長度為 293.2 個詞。數(shù)據(jù)集被平均分為訓(xùn)練集和測試集,每部分都有 5000 個問題。在測試集中,每個問題都有多個測試用例,平均測試用例數(shù)為 21.2。每個測試用例都是針對相應(yīng)問題而專門設(shè)計的,能夠嚴格評估程序功能。為了創(chuàng)建 APPS 數(shù)據(jù)集,研究者手動處理了來自開放網(wǎng)站的問題,在這些網(wǎng)站中程序員可以相互分享問題,包括 Codewars、AtCoder、Kattis 和 Codeforces。為了提高數(shù)據(jù)集的質(zhì)量和一致性,研究者對每個問題源使用自定義 HTML 解析器。必要時,研究者使用 MathPix API 將圖像轉(zhuǎn)換為 LaTeX。此外研究者還使用具有 SVD 降維和余弦相似度的 tf-idf 特征執(zhí)行重復(fù)數(shù)據(jù)刪除。在數(shù)據(jù)分級上,數(shù)據(jù)集被分為三個難度。例如,Kattis 難度小于 3 的問題被歸類為「入門級難度」,難度在 3 到 5 之間的問題被歸類為「面試級難度」,難度大于 5 的問題被歸類為「競賽級難度」。入門級難度:大多數(shù)有 1-2 年經(jīng)驗的程序員不需要復(fù)雜的算法就可以解決這些問題,有 3639 個;
面試級難度:問題會涉及數(shù)據(jù)結(jié)構(gòu),比如樹或者圖,或需要修改常見的算法,有 5000 個;
競賽級難度:達到高中和大學(xué)編程比賽的水平,包括 USACO、IOI 和 ACM,有 1361 個。
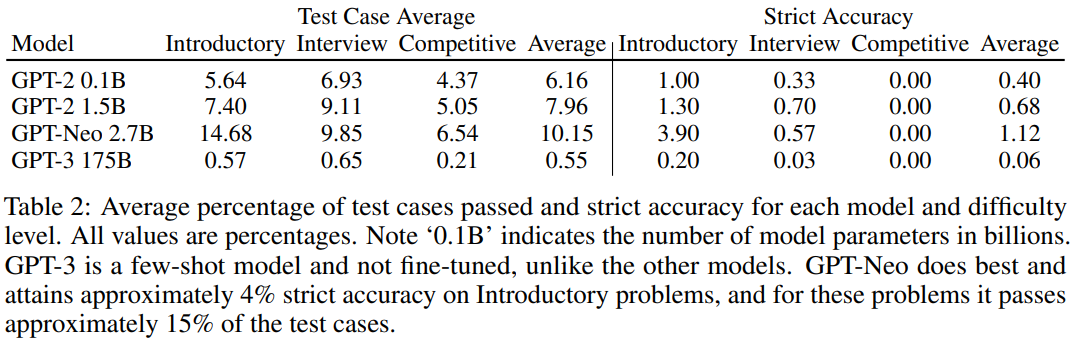
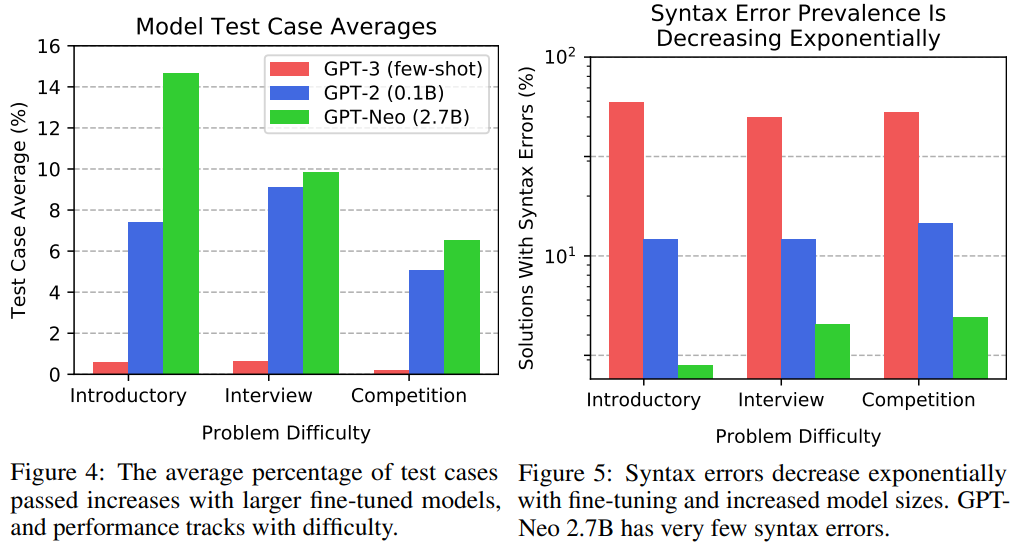
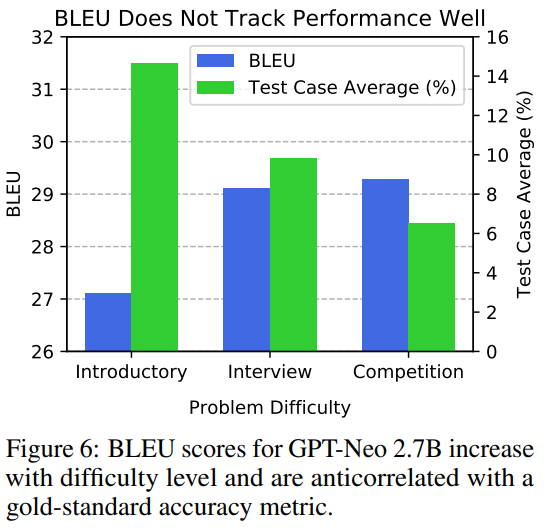
研究者使用 APPS 基準分析了各種 Transformer 模型。結(jié)果發(fā)現(xiàn),微調(diào)和增加模型尺寸可以提高準確率,而準確率隨著難度的增加而下降。此外,實驗發(fā)現(xiàn)語法錯誤正在減少,生成的代碼在質(zhì)量是合理的。模型采用 GPT-2、GPT-3、GPT-Neo。GPT 體系架構(gòu)特別適合于文本生成,因為它是自回歸的。為了全面評估模型的代碼生成能力,研究者使用了 APPS 提供的大量測試用例和實用的解決方案。測試用例允許自動評估,即使可能程序的空間組合起來可能很大。因此,與許多其他文本生成任務(wù)不同,不需要手動分析。將生成的代碼在測試用例上的性能匯總為兩個指標,即「測試用例平均值」和「嚴格準確性」。定性輸出分析。模型有時可以生成正確的或表面上合理的代碼。圖 2 顯示了通過所有測試用例的 GPT-2 1.5B 生成的代碼。當(dāng)模型沒有通過測試用例時,有時乍一看它們生成的代碼似乎仍然是合理的。例如,在圖 3 給出了 1.5B 參數(shù)模型生成與問題陳述相關(guān)的代碼,并進行了合理的嘗試來解決它。測試用例評估。表 2 顯示了主要結(jié)果。研究者觀察到,模型能夠生成通過一些測試用例的代碼,這意味著許多生成的程序都沒有語法錯誤,并且可以成功處理輸入測試用例以產(chǎn)生正確答案。請注意,對于入門性問題,GPT-Neo 通過了大約 15%的測試用例。研究者將圖 4 中的「測試用例平均」結(jié)果可視化。這演示了模型在代碼生成方面顯示出明顯的改進,并且現(xiàn)在開始對代碼生成產(chǎn)生吸引力。語法錯誤。研究者評估了語法錯誤的頻率,這些語法錯誤導(dǎo)致程序無法解釋,包括間距不一致,括號不平衡,冒號丟失等。如圖 5 所示,語法錯誤存在普遍性。雖然 GPT-3 針對入門問題生成的解決方案中大約有 59%存在語法錯誤,但 GPT-Neo 語法錯誤發(fā)生率約為 3%。請注意,Yasunaga 和 Liang(2020)等最近的工作創(chuàng)建了一個單獨的模型來修復(fù)源代碼以解決編譯問題,但是該研究的結(jié)果表明,由于語法錯誤頻率會自動降低,因此將來可能不需要這樣做。BLEU。為了評估 BLEU,研究者采用生成的解并針對給定問題用每個人工編寫的解計算其 BLEU,然后記錄最高的 BLEU 得分。在圖 6 中觀察到,即使模型在處理更棘手的問題上實際上表現(xiàn)較差,隨著問題來源變得越來越困難,BLEU 也會增加。此外,較差的模型可能具有相似或更高的 BLEU 得分。論文發(fā)布后,有網(wǎng)友表示他們使用相似的數(shù)據(jù)集訓(xùn)練模型解答 LeetCode 中的題目,其中最優(yōu)的模型是 GPT-2,準確率高達 80%。項目鏈接:https://github.com/gagan3012/project-code-pyAI 的編程能力日漸提升,新一輪「內(nèi)卷」又要開始了嗎?往期精彩:
TransUNet:基于 Transformer 和 CNN 的混合編碼網(wǎng)絡(luò)
SETR:基于視覺 Transformer 的語義分割模型
ViT:視覺Transformer backbone網(wǎng)絡(luò)ViT論文與代碼詳解
【原創(chuàng)首發(fā)】機器學(xué)習(xí)公式推導(dǎo)與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語義分割理論與實戰(zhàn)指南.pdf
求個在看