在上周介紹Iceberg原理的文章中,我有提到Iceberg的設(shè)計初衷是為了解決Hive數(shù)倉所遇到的問題,主要有4點:
沒有ACID保證
只能支持partition粒度的謂詞下推
確定掃描的文件需要使用文件系統(tǒng)的list操作
partition字段必須顯式出現(xiàn)在query里面
其中2和3都是直接影響query性能的問題,而Iceberg的主打賣點正是更快的查詢速度。作者Ryan Blue在DataWorks Summit上宣講Iceberg的ppt上就有列出Netflix在使用了Iceberg之后的性能提升情況Hive光是確定查詢計劃就要9.6分鐘,而Iceberg確定查詢計劃只要42秒首先,對于存儲層的數(shù)據(jù)湖系統(tǒng)(Delta,Hudi,Iceberg)來說,query在存儲層發(fā)生的事情粗略地可分為兩個階段:確定需要讀取的文件列表(planning階段)
讀取數(shù)據(jù)并傳遞給計算引擎(execution階段)
對于execution階段,相信比較符合直覺,是所有人都認可的存儲層需要做的事情。但是對于planning階段,或許有些朋友會有疑問:Spark等計算引擎需要產(chǎn)生執(zhí)行計劃,我還能理解,為什么存儲層也需要執(zhí)行計劃?其實存儲層的執(zhí)行計劃沒有計算層的那么復(fù)雜,但確實也有一些需要做計劃的事情,主要是以下2點:需要讀取哪些partition
每個partition下有哪些文件
這兩件事情的內(nèi)容一目了然,我就不再贅述了。講完了planning階段需要解決的問題,回到我們最初的主題,來講講Iceberg所做的優(yōu)化。其實Iceberg在這兩個階段都有做優(yōu)化,優(yōu)化機制總的來說主要有2種:- Partition Pruning(分區(qū)剪枝)
接下來就會講一講Iceberg是如何實現(xiàn)這兩個功能的。Partition Pruning(分區(qū)剪枝),主要針對的是planning階段中的第一個問題:需要讀取哪些partition。分區(qū)剪枝并不是一個新鮮事物。比如Hive就會根據(jù)查詢條件來決定是否使用分區(qū)查詢,以及具體查詢哪個或哪幾個分區(qū),其實就是一種分區(qū)剪枝。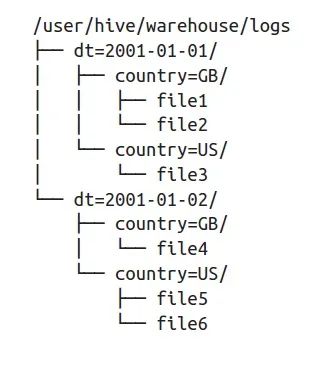
Hive會根據(jù)查詢條件確定讀取哪個分區(qū)
Iceberg沒有沿用Hive相對簡單的分區(qū)規(guī)則,而是自己實現(xiàn)了一套更為復(fù)雜的分區(qū)系統(tǒng)及分區(qū)剪枝算法,名為Hidden Partition。Iceberg選擇自己實現(xiàn),目的是為了克服Hive的分區(qū)功能在使用上的不方便以及容易出錯。在Iceberg里面,分區(qū)是存儲系統(tǒng)的一個實現(xiàn)細節(jié),用戶無需理解分區(qū)和文件系統(tǒng)的路徑是如何對應(yīng)的。(關(guān)于Hive的分區(qū)功能的問題,請見上一篇文章)接下來具體講一講Iceberg的分區(qū)剪枝算法。首先在Iceberg中我們用下面的CREATE語句來創(chuàng)建分區(qū)表
CREATE TABLE foobar (id bigint, data string) USING iceberg PARTITIONED BY (truncate(id, 3))
和Hive不同的是,Iceberg實現(xiàn)分區(qū)剪枝不是依賴文件所在的目錄,而是利用了Iceberg特有的manifest文件。上一篇文章中有提到,Iceberg每次寫入都會產(chǎn)生一個新的snapshot,而一個snapshot在文件系統(tǒng)上就對應(yīng)一個manifest文件。{ ... "snapshot_id": { "long": 4370069137697126000 }, "data_file": { "file_path": ".../table/data/id_trunc=0/00000-0-1c1865ee-a812-465c-87cb-7588478c2d8f-00001.parquet", "file_format": "PARQUET", "partition": { "id_trunc": { "long": 0 } }, ... }}{ ... "snapshot_id": { "long": 4370069137697126000 }, "data_file": { "file_path": ".../table/data/id_trunc=3/00001-1-b18c1240-86bb-48da-85e9-4a0e41a82b26-00001.parquet", "file_format": "PARQUET", "partition": { "id_trunc": { "long": 3 } }, ... }}
其中的data_file字段記錄的是這個snapshot里包含的數(shù)據(jù)文件的信息,注意到data_file字段里有一個字段是partition,里面記錄的就是這個data_file所在的partition信息。Iceberg正是使用這些元數(shù)據(jù)確定每個分區(qū)里包含哪些文件的。相比于Hive,Iceberg的這種partition實現(xiàn)方式有以下好處:直接定位到parquet文件,無需調(diào)用文件系統(tǒng)的list操作。
partition的存儲方式對用戶透明,用戶在修改partition定義時Iceberg可以自動地修改存儲布局而無需用戶操作。
講完了分區(qū)剪枝,接下來再講一講Predicate Pushdown(謂詞下推)。前幾篇文章中也有提到過,謂詞下推是計算引擎(Spark等)把查詢的過濾條件(where條件)下推到存儲層,在存儲層面就把一部分必然不滿足條件的數(shù)據(jù)過濾掉,從而減少存儲層返回給計算引擎的數(shù)據(jù)量。在講Iceberg如何實現(xiàn)謂詞下推之前,我先講一講Spark是如何實現(xiàn)謂詞下推的。Spark作為計算層的系統(tǒng),自己并不實現(xiàn)謂詞下推,而是交給文件格式的reader來解決。例如,對于parquet文件,Spark使用下面這個類讀取parquet文件/** * @param readSupport Object which helps reads files of the given type, e.g. Thrift, Avro. * @param filter for filtering individual records */ public ParquetRecordReader(ReadSupport readSupport, Filter filter) { internalReader = new InternalParquetRecordReader(readSupport, filter); }
注意ParquetRecordReader的第二個參數(shù)filter,就是parquet對計算引擎提供的接口,用于傳入過濾條件。而ParquetRecordReader從parquet文件中讀取數(shù)據(jù)后,會首先使用filter過濾掉不滿足的record,然后再交給計算引擎。
相比于Spark,Iceberg做得更多一些。Iceberg會在兩個層面實現(xiàn)謂詞下推:1. 在snapshot層面,過濾掉不滿足條件的data file2. 在data file層面,過濾掉不滿足條件的數(shù)據(jù)其中第一點是Iceberg特有的,也是利用了manifest文件里保存的元數(shù)據(jù)。Iceberg在manifest文件里記錄了每個字段的上界和下界。所以在planning階段,Iceberg就可以利用這個信息,過濾掉不滿足條件的文件,進一步減少文件的掃描量。{ ... "data_file": { "file_path": ".../table/data/id_trunc=0/00000-0-1c1865ee-a812-465c-87cb-7588478c2d8f-00001.parquet", ... "lower_bounds": { "array": [ { "key": 1, "value": 1 }, { "key": 2, "value": "a" } ] }, "upper_bounds": { "array": [ { "key": 1, "value": 2 }, { "key": 2, "value": "b" } ] }, ... }}
這個文件包含兩條數(shù)據(jù),(1, “a”)和(2, “b”)。可以看到上界和下界分別是1和2,a和b第二點則和Spark類似,也是在讀取文件時,過濾掉不滿足條件的數(shù)據(jù)。不過和Spark不同的是,Iceberg作為存儲層的系統(tǒng),使用的是parquet更偏底層的ParquetFileReader接口,自己實現(xiàn)了過濾邏輯。和Spark的ParquetRecordReader有什么不同呢?Iceberg的這種實現(xiàn)方式可以直接跳過整個row group,更進一步地減少io量,不過礙于篇幅,細節(jié)我就不展開講了。
以上就是Iceberg在優(yōu)化查詢性能方面所實現(xiàn)的優(yōu)化機制,本質(zhì)都是為了減少數(shù)據(jù)查詢量。可以看到manifest文件在Iceberg的優(yōu)化邏輯中起到非常關(guān)鍵的作用,正是因為Iceberg利用了云原生數(shù)據(jù)倉庫的文件大多不可變的特性,收集了非常多關(guān)于數(shù)據(jù)分布的元數(shù)據(jù)的關(guān)系。相信未來存儲層會在這方面有更多的發(fā)展,然后和計算引擎的結(jié)合更為緊密,從而進一步提高查詢的性能。最后你或許會問,既然Iceberg有這些query優(yōu)化機制,那Hudi有同樣的功能嗎?就我從Hudi的源代碼看來,現(xiàn)階段Hudi實現(xiàn)了一半。Hudi實現(xiàn)了分區(qū)剪枝功能,但是謂詞下推功能目前似乎還沒有實現(xiàn)。- Iceberg對減少數(shù)據(jù)查詢量提供了兩種優(yōu)化機制:分區(qū)剪枝和謂詞下推。
- Iceberg收集了關(guān)于數(shù)據(jù)分布的元數(shù)據(jù),并利用這些元數(shù)據(jù)實現(xiàn)更高效的數(shù)據(jù)裁剪,減少了數(shù)據(jù)的查詢量。


