
Flask + echarts 輕松搞定 日志可視化


最近,線上的業(yè)務系統不太穩(wěn)定,需要分析下訪問情況,能拿到的數據只有 nginx 服務器的訪問日志,不過難不倒我,用合適的工具,分分鐘做出圖形化展示,看看怎么做的吧
思路
nginx 訪問日志,記錄了每次客戶端請求,其中包括 ip、時間、使用的客戶端等信息
通過解析每行數據,提取這些信息,然后對信息進行整理,并做一些必要的統計
最后將統計數據展示出來,可以直觀地感知數據中蘊含的問題
基本思路就是這樣,不過知道和做到之間地距離還有很遠,為了達到目標,需要一些工具做支持
由于數據是 nginx 訪問日志,所有不需要爬取,從服務器上下載就好
整理處理過程,除了 python 本身一些功能外,還離不開 pandas 的支持
最后數據展示部分,用的是 Flask + echarts,從頭寫,確實很有挑戰(zhàn),不過今天我們利用 TurboWay 同學的框架 bigdata_practice,就能輕松搞定
閑話少敘,開始吧
數據處理
下載到 nginx 訪問日志,從 nginx 配置文件中可以查看日志存放地址,另外,本文源碼中有附帶示例日志文件,可下載使用
日志文件為文本文件,每行記錄一條訪問情況,例如:
124.64.19.27 - - [04/Sep/2020:03:21:12 +0800] "POST /api/hb.asp HTTP/1.1" 200 132 "http://erp.example.com/mainframe/main.html" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36" "-"
讀取文本文件的行,實現比較簡單,這里只對提取字段和通過 ip 確定省份做下說明
提取
提取字段的方法如下:
import?re
obj?=?re.compile(r'(?P.*?)-?-?\[(?P )
result?=?obj.match(line)
#?print(result.group("time"))
#?ip處理
ip?=?result.group("ip").split(",")[0].strip()?#?如果有兩個ip,取第一個ip
#?狀態(tài)碼處理
status?=?result.group("status")??#?狀態(tài)碼
#?時間處理
time?=?result.group("time").replace("?+0800",?"")?#?提取時間,并去掉時區(qū)信息
t?=?datetime.datetime.strptime(time,?"%d/%b/%Y:%H:%M:%S")??#?格式化
#?request處理
request?=?result.group("request")
a?=?request.split()[1].split("?")[0]??#?提取請求?url,去掉查詢參數
#?user_agent處理
ua?=?result.group("ua")
if?"Windows?NT"?in?ua:
????u?=?"windows"
elif?"iPad"?in?ua:
????u?=?"ipad"
elif?"Android"?in?ua:
????u?=?"android"
elif?"Macintosh"?in?ua:
????u?=?"mac"
elif?"iPhone"?in?ua:
????u?=?"iphone"
else:
????u?=?"其他設備"
#?refer處理
referer?=?result.group("referer")
代碼看著長,其實邏輯很簡單,核心是提取信息的正則表達式,利用了命名分組的方式,匹配后,可以通過命名來提取數據
對提取出的數據,需要處理一下,比如請求時間,采用的是類似 UTC 時間格式,需要去掉時區(qū),并轉換為 datatime 類型
另外就是的客戶端的處理,根據關鍵字,判斷客戶端類型
將提取的信息,存入一個 詞典 對象中,即每行對于一個 詞典 對象,最后將一個個對象追加到一個 列表 對象中,帶進一步處理
獲取用戶省份
為了后面對訪問者所在區(qū)域進行分析,需要對一些字段做處理,例如將 ip 轉換為省份信息
轉換主要利用的是百度的 ip 定位服務
百度的 ip 定位服務,通過認證,可以獲得每日 3 萬次的免費配額
通過提供的 api 可以獲取 ip 地址所在的省名稱
考慮到查詢效率和配額限制問題,最好對 ip 定位的結果做個緩存:
import?requests
import?os
ak?=?"444ddf895?...?a5ad334ee"?#?百度?ak?需申請
#?ip?定位方法
def?ip2province(ip):
????province?=?ipCache.get(ip,?None)
????if?province?is?None:
????????url?=?f"https://api.map.baidu.com/location/ip?ak={ak}&ip={ip}&coor=bd09ll"
????????try:
????????????province?=?json.loads(requests.get(url).text)['address'].split('|')[1]
????????????ipCache[ip]?=?province
????????????#?這里就需要寫入
????????????with?open("ip_cache.txt","a")?as?f:
????????????????f.write(ip?+?"\t"?+?province?+?"\n")
????????????return?province
????????except?Exception?as?e:
????????????return?"未知"
????else:
????????return?province
#?初始化緩存
ipCache?=?{}
if?os.path.exists("ip_cache.txt"):
????with?open("ip_cache.txt",?"r")?as?f:
????????data?=?f.readline()
????????while?data:
????????????ip,?province?=?data.strip().split("\t")
????????????ipCache[ip]?=?province
????????????data?=?f.readline()
首先需要申請一個百度 app key 合成請求,通過 requests ?get,得到響應,從中提取到 ip 對應的省份信息 對應地址緩存,將沒有緩存的結果存入 ipCache 詞典對象,并寫入 ip_cache.txt 文件,下次啟動時,用緩存文件中的內容初始化 ipCache 詞典對象 在每次需要獲取 ip 對應地址時,先檢查緩存,如果沒有才通過 api 獲取
數據分析
數據分析,就是對提取到的特征數據做統計加工,利用的是強大的 pandas
通過數據處理過程,我們可以得到處理好的 列表 對象,列表對象很容易創(chuàng)建為 pandas 的 DataFrame
接著,利用 pandas 的統計功能,將原始數據轉換為可以展示用的分析數據
最后將數據存入 Excel 文件
def?analyse(lst):
????df?=?pd.DataFrame(lst)??#?創(chuàng)建?DataFrame
????#?統計省份
????province_count_df?=?pd.value_counts(df['province']).reset_index().rename(columns={"index":?"province",?"province":?"count"})
????#?統計時段
????hour_count_df?=?pd.value_counts(df['hour']).reset_index().rename(columns={"index":?"hour",?"hour":?"count"}).sort_values(by='hour')
????#?統計客戶端
????ua_count_df?=?pd.value_counts(df['ua']).reset_index().rename(columns={"index":?"ua",?"ua":?"count"})
????#?數據存儲
????to_excel(province_count_df,?'data.xlsx',?sheet_name='省份')
????to_excel(hour_count_df,?'data.xlsx',?sheet_name='按時')
????to_excel(ua_count_df,?'data.xlsx',?sheet_name='客戶端')
def?to_excel(dataframe,?filepath,?sheet_name):
????if?os.path.exists(filepath):j
????????excelWriter?=?pd.ExcelWriter(filepath,?engine='openpyxl')
????????book?=?load_workbook(excelWriter.path)
????????excelWriter.book?=?book
????????dataframe.to_excel(excel_writer=excelWriter,sheet_name=sheet_name,index=None,?header=None)
????????excelWriter.close()
????else:
????????dataframe.to_excel(filepath,?sheet_name=sheet_name,?index=None,?header=None)
analyse方法,接受一個列表對象,即在數據整理部分得到的數據將數據創(chuàng)建為 DataFrame,利用 pandas 的 value_counts方法對對應字段數據進行統計,注意,value_counts會做去重處理,從而統計出每個值出現的個數因為 value_counts處理的結果,是一個 Series 對象,索引為不重復的值,所以在用 reset_index 方法處理一下,將索引轉換為一個正常列,并對列名做了替換,以便后續(xù)處理更方便由于 value_counts 后的結果是按統計數量從多到少排列的,對應按時間的統計有些奇怪,所以利用 sort_values方法,按時間列做了重新排序to_excel方法是為了將數據導出為 excel,可以支持導入不同 sheet,以便做數據展示
數據分析部分,可以從不同的角度對數據進行統計分析,最終將需要展示的數據存入 Excel,當然根據需要也可以存入其他數據庫
數據展示
從頭利用 Flask 和 echarts 做數據展示是可以的,不過需要處理更多的細節(jié)
如果利用一些框架,快速做展示,然后再做局部的個性化調整
這里用到的框架是 TurboWay 的 bigdata_practice,雖然功能比較單一,結構不太靈活,不過用來搭建一個可用的數據展示系統還是沒問題的,重要的是可以通過源碼學習構建思路的方法
bigdata_practice git 地址為:https://github.com/TurboWay/bigdata_practice.git
將其 clone 到本地
git?clone?https://github.com/TurboWay/bigdata_practice.git
然后按照依賴模塊,在 bigdata_practice 文件夾中,有個 requirements.txt,里面列了項目所依賴的庫和組件
關于如何構建 requirements.txt 文件,可參考 《部署 Flask 應用》
進入 bigdata_practice 文件夾,用 pip 安裝依賴:
pip?install?-r?requirements.txt
注意:最好使用虛擬環(huán)境安裝,如何創(chuàng)建虛擬環(huán)境,可參考這篇文章
安裝依賴之后,就可以啟動 Flask 服務了
python?app.py
?*?Serving?Flask?app?"app"?(lazy?loading)
?*?Environment:?production
???WARNING:?This?is?a?development?server.?Do?not?use?it?in?a?production?deployment.
???Use?a?production?WSGI?server?instead.
?*?Debug?mode:?on
?*?Restarting?with?stat
?*?Debugger?is?active!
?*?Debugger?PIN:?137-055-644
?*?Running?on?http://127.0.0.1:5000/?(Press?CTRL+C?to?quit)
如果一切正常,可以訪問 localhost:5000,查看數據展示效果
這里對項目中的需要定制的部分做下說明
在 ironman 目錄下,app.py 為 Flask 服務主代碼,其中定義了系統的訪問路徑,比如首頁、線圖、餅圖等,這里可以根據自己的需求添加或刪改
每個訪問路徑對應一個頁面模板,模板文件存放在,templates 文件夾下,如果需要調整菜單,需要對每個模板頁面中的菜單部分進行修改,以調整菜單項目以及被激活的菜單
data.py 定義了展示數據的讀取接口,相當于一個數據層,依賴于 nginx_log_data.py,將數據設置為,方便展示的結構,如果需要展示更多的圖形,需要根據展示效果,修改或添加新的數據接口
nginx_log_data.py 從 Excel 文件中讀取需要展示的數據,Excel 中的數據,就是 數據分析 部分得到的結果,這里利用 pandas 讀取 Excel 的功能,如果需要展示更多的分析數據,可以在這里添加數據讀取結果,另外通過調整 data.py 以及相應的頁面模板文件,將數據得以展示
這里,我們就 24小時訪問趨勢、客戶端占比以及用戶分布做了展示,效果如下:
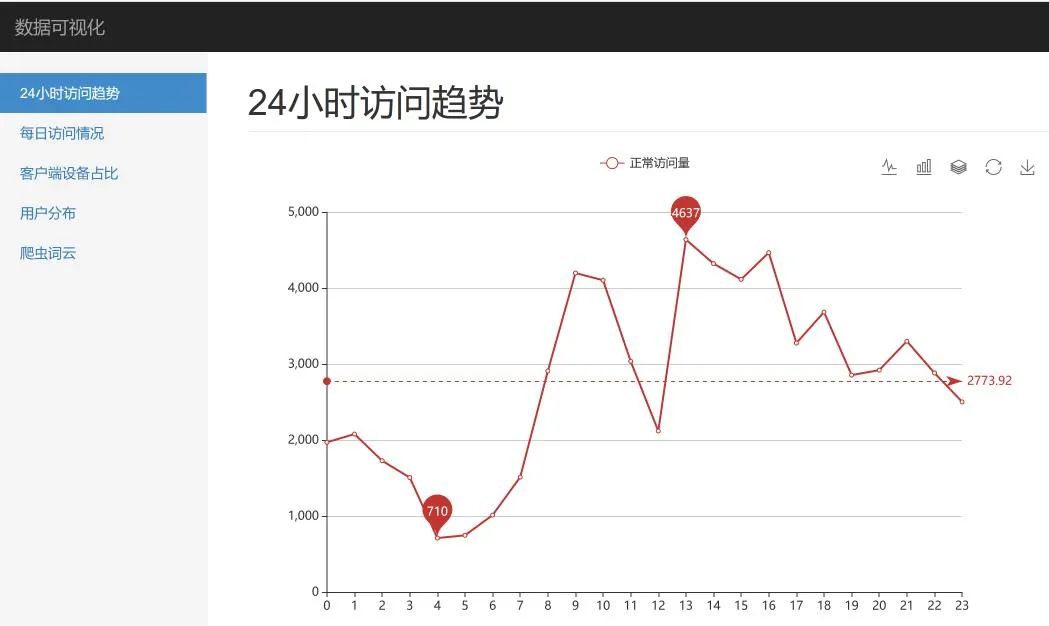
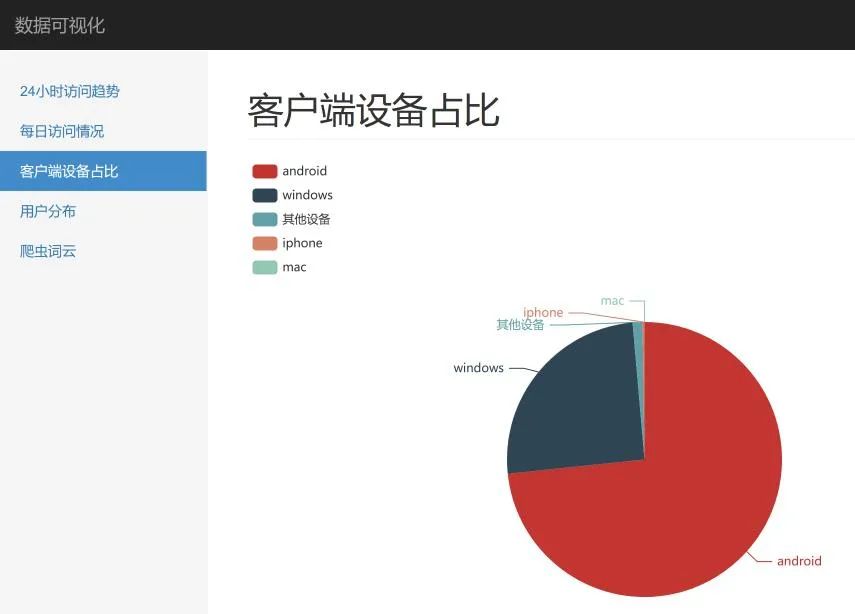
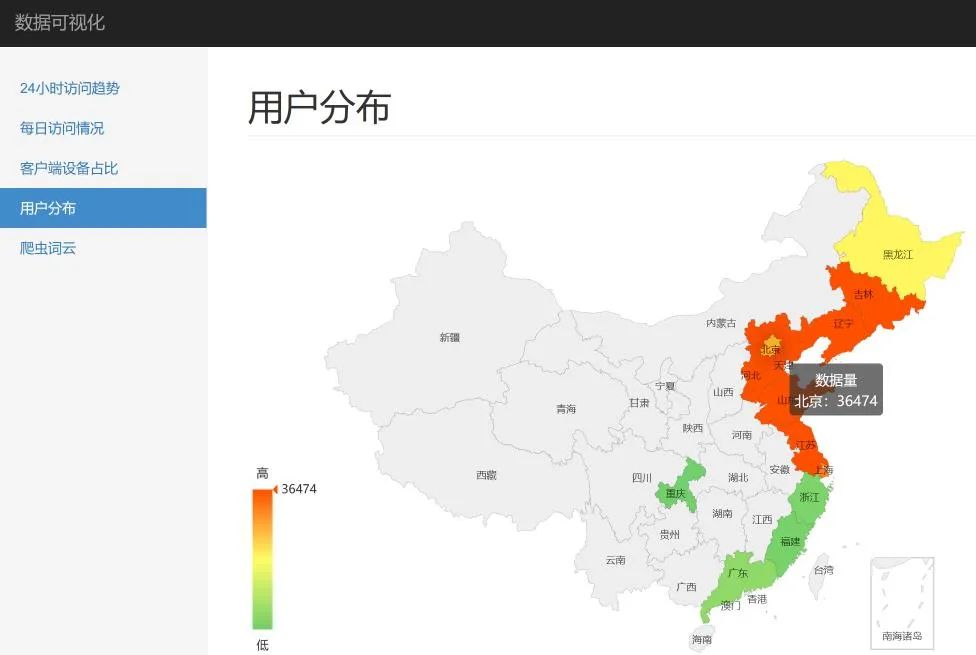
實踐
下載源碼后,先安裝項目依賴
pip?install?-r?requirements.txt
示例用的 nginx 訪問日志,在 nginx_access.zip 壓縮包里,先解壓到當前目錄
然后申請百度API,獲取到 ak,修改到 analyse\baidu_api.py 的 13 行
將命令行切換到代碼目錄下,否則可能出現文件找不到的錯誤
執(zhí)行數據分析腳本:
python?.\analyse\main.py
最后啟動 Flask 服務:
python?.\ironman\app.py
總結
今天利用 pandas、Flask、echarts 對 nginx 服務器的訪問日志做了簡單分析和展示,完成任務的同時,學習和實踐了如何通過一些簡單的工具和方法構造一個數據展示平臺的過程
文章主要說明了構建思路和需要注意的部分,具體細節(jié),請下載示例代碼,運行,同時歡迎交流探討
參考
https://www.cnblogs.com/ssgeek/p/12119657.html https://blog.csdn.net/whaoxysh/article/details/22295317 http://lbsyun.baidu.com/index.php?title=webapi/ip-api http://lbsyun.baidu.com/apiconsole/key https://blog.csdn.net/unsterbliche/article/details/80578606 https://github.com/TurboWay/bigdata_practice
